
|
|
Операции с нечеткими множествамиСтр 1 из 9Следующая ⇒ Понятие нечеткого множества Значения лингвистической переменной определяются через так называемые нечеткие множества (НМ), которые в свою очередь определены на некотором базовом наборе значений или базовой числовой шкале, имеющей размерность. Каждое значение ЛП определяется, как нечеткое множество (например, НМ «низкий рост»). Нечеткое множество определяется через некоторую базовую шкалу (универсальное множество U) и функцию принадлежности нечеткому множеству m(u), u Î U, принимающую значения на интервале [0, 1]: m(х) Î [0,1]. Нечеткое множество определяет субъективную степень уверенности эксперта в принадлежности конкретного значения базовой шкалы данному нечеткому множеству. Рассмотрим понятие «рост человека». В качестве универсального множества U можно использовать действительный интервал [0; 300], покрывающий любой возможный рост человека в см. Определим на этом универсальном множестве нечеткие множества «низкий рост» и «высокий рост». К людям с низким ростом принадлежат те, чей рост менее 150 см, а люди с ростом более 180 см однозначно относятся к высоким. В интервале от 150 см до 180 см рост человека можно отнести к низкому или высокому с той или иной степенью уверенности. Например, рост 170 см можно отнести к высокому с некоторой степенью принадлежности m1, а к низкому – со степенью принадлежности m2. В то время как рост в 140 см принадлежит нечеткому множеству «высокий рост» со степенью 0, а множеству «низкий рост» – со степенью 1. Таким образом, для задания НМ необходимо определить: 1. универсальное множество U, которое содержит все рассматриваемые элементы; 2. множество значений степени принадлежности элементов из U нечеткому множеству ([0,1]); 3. правило, определяющее состав нечеткого множества, т.е. правило, в соответствии с которым каждому элементу из множества U ставится в соответствие элемент из интервала [0,1]. Для дискретных универсальных множеств нечеткое множество представляет собой совокупность пар { ui, m(ui)}, ui Î U, m(ui) Î [0,1], i = 1, 2, …, n, где n – число элементов (мощность) множества U. Для непрерывных универсальных множеств правило представляет собой аналитически заданное отображение: m А: U ® [0,1]. Итак, нечетким множеством А универсального множества U называется отображение m А: U ® [0,1], которое ставит в соответствие каждому элементу u множества U степень его принадлежности нечеткому множеству А и называется функцией принадлежности нечеткого множества А: m А (u), u Î U. Для задания нечеткого множества достаточно указать его функцию принадлежности m А (u). Чтобы подчеркнуть дискретный или непрерывный характер нечеткого множества, используют соответственно записи со знаком суммы или интеграла: Нечеткое множество отличается от обычного множества набором возможных значений функции принадлежности. Если для обычного множества функция принадлежности принимает только два значения: 1 – если элемент принадлежит множеству, 0 – в противном случае, то функция принадлежности нечеткого множества принимает значения в интервале [0,1], т.е. элемент может принадлежать нечеткому множеству с некоторой степенью, меньшей 1. Кроме понятия нечеткого множества в нечеткой логике также определены еще несколько понятий и терминов. Носителем (основанием) А называется подмножество универсального множества a- уровнем нечеткого подмножества А универсального множества U называется такое подмножество Будем считать, что основание нечеткого множества является его нулевым уровнем: Высотой нечеткого множества А называется верхняя граница значений его функции принадлежности: равна 1, то оно называется нормальным, если меньше 1 – субнормальным. Субнормальное нечеткое множество можно нормировать: На рис. 7.2 приведены нечеткие множества, иллюстрирующие пример с ростом человека и данные выше определения.
Рис. 7.2 Примеры нечетких множеств Оба нечетких множества имеют высоту 1, т.е. являются нормальными. Основанием НМ «высокий рост» является интервал [150; 300], а НМ «низкий рост» – [0; 180] соответственно. Для последнего приведен также пример a-уровня. Для обоих нечетких множеств аналитические выражения их функций принадлежности имеют следующий вид:
  
1,
Теперь можно точно определить степень принадлежности того или иного значения нечеткому множеству. Например, рост 170 см можно отнести к высокому со степенью принадлежности 2/3, а к низкому – со степенью принадлежности 1/3. ( Функцию принадлежности нечеткого множества не следует путать с вероятностью, носящей объективный характер и подчиняющейся другим математическим зависимостям. Рис. 7.3 Операции с нечеткими множествами Степенью a нечеткого множества А называется нечеткое множество Концентрированием нечеткого множества А называется нечеткое множество Расширением нечеткого множества А называется нечеткое множетво Операции концентрирования и расширения широко используются при работе с лингвистическими переменными. Перечисленные специальные операции с нечеткими множествами проиллюстрированы на рис. 7.4.
Содержанием этапа 4 является обработка результатов опроса экспертов и построение функций принадлежности термов ЛП. Лекция. Нечеткие вычисления Понятие нечеткого числа Одной из областей применение нечеткой логики является выполнение арифметических операций с нечеткими множествами. Для снижения трудоемкости таких операций используется специальный тип нечетких множеств – нечеткие числа. Нечетким числом (НЧ) называется нечеткая переменная, имеющая следующие свойства: Другими словами, нечеткое число– именованное нечеткое множество, для которого универсальное множество U представляет собой интервал действительной оси R. В реальных задачах используются кусочно-линейные нечеткие числа.Для упрощения арифметических операций кусочно-линейные функции принадлежности дополнительно аппроксимируют, чтобы получить специальный вид нечетких чисел – параметрические нечеткие числа или нечеткие числа (L – R)–типа, которые характеризуются компактностью представления и просто- той реализации арифметических операций.
0,
 , ,
где Нечеткое параметрическое число обозначается (a, b, c, d) LR. Таким образом, нечеткое число (L – R)–типа описывается шестью параметрами: четырьмя числами, обозначающими его границы, и двумя функциями, определяющими форму его функции принадлежности.
Рис.7.8 Параметрические нечеткие числа Нечеткое числоназывается унимодальным, если оно имеет только одну точку, в которой функция принадлежности равна единице, т.е. его параметры b и c равны, в противном случае нечеткое число называется толерантным (см. рис. 7.8). Унимодальные нечеткие числа обозначаются пятью параметрами (a, b, d) LR. В качестве LR –функций наиболее часто используют линейные зависимости, задаваемые следующими соотношениями:
LR – функции также могут задаваться квадратичными, экспоненциальными и другими зависимостями. В случае использования линейных функций унимодальные и толерантные нечеткие числа называют соответственно треугольными и трапециевидными и обозначают (a, b, d) и (a, b, c, d). Для нечетких чисел особым образом определяется понятие знака и нулевого значения. Нечеткое число А называется положительным, если его основание лежит в положительной действительной полуоси
Нечеткое число А называется отрицательным, если его основание лежит в отрицательной действительной полуоси
Для параметрических нечетких чисел знак определяется значениями параметров: положительное нечеткое число, если a > 0; отрицательное, если d < 0; нечеткий ноль, если Рис. 7.9 Сравнение НЧ с непересекающимися основаниями Однако в большинстве случаев основания нечетких чисел пересекаются, поэтому их сравнение происходит следующим образом. Для каждого из сравниваемых нечетких чисел M и N вычисляют специальные меры Н (М), Н (N), которые затем сравнивают:
Вычисление меры Н выполняется двумя способами: - поиск точки максимума; - поиск центра тяжести. В случае поиска максимума величина Н является точкой на действительной оси, которая соответствует максимальному значению функции принадлежности (рис. 7.10). Используются три разновидности максимума: наибольший из максимумов (LOM), наименьший из максимумов (SOM) и центр максимумов (MOM).
Рис. 7.10 Сравнение по максимуму функций принадлежности Центр тяжести нечеткого числа
Физическим аналогом этой формулы является нахождение центра тяжести плоской фигуры, ограниченной осями координат и графиком функции принадлежности нечеткого множества. Сравнение нечетких чисел более предпочтительно выполнять на основе поиска центра тяжести. Еще одной важной операцией с нечеткими множествами, в том числе нечеткими числами, является определение меры сходства. Обычно данную операцию применяют для этого, чтобы определить какое из двух нечетких множеств больше похоже на третье. Прикладное значение такой операции заключается в следующем. При задании параметров некоторой системы могут использоваться лингвистические переменные, тогда значениями параметров являются нечеткие множества. Обработка и анализ параметров требует выполнения над ними некоторых преобразований, в результате которых также получаются нечеткие множества. Но представлять их в качестве результата нецелесообразно. Результат лучше представить с помощью лингвистических переменных. Чтобы выяснить, на какой из термов лингвистической переменной больше похож результат, и применяется процедура вычисления меры сходства. Терм, для которого она окажется максимальной, считается результатом. Указанная процедура получила название лингвистической аппроксимации и служит средством обратного преобразования количественных данных в качественные. Мера сходства для совпадающих нечетких множеств должна быть равна 1, а для непересекающихся – 0. Общая формула для вычисления меры сходства двух нечетких множеств M и N имеет следующий вид:
где
Данное выражение интерпретируется как отношение площадей функций принадлежности пересечения и объединения рассматриваемых нечетких множеств (рис. 7.11).
Рис. 7.11 Графическое представление меры сходства НМ Алгоритмы нечеткого вывода Рассмотрим наиболее часто используемые модификации алгоритма нечеткого вывода, полагая, для простоты, что база знаний включает два нечетких правила вида: П1: если x есть A 1 и y есть B 1 то z есть C 1, П2: если x есть A 2 и y есть B 2 то z есть C 2, где x, y – имена входных переменных; z – имя переменной вывода; A 1, A 2, B 1, B 2, C 1, C 2 – некоторые заданные функции принадлежности. Необходимо определить четкое значение z 0 на основе указанных правил вывода и четких значений x 0, y 0. Алгоритм Мамдани Данный алгоритм соответствует рассмотренному примеру и рис. 7.15. Математически он может быть описан следующим образом. 1. Нечеткость: определяются степени истинности для предпосылок каждого правила: A 1(x 0), A 2(x 0), B 1(y 0), B 2(y 0). 2. Нечеткий вывод: определяются уровни «отсечения» для предпосылок каждого из правил с использованием операции МИНИМУМ:
где через «
3. Композиция: с использованием операции МАКСИМУМ (max, далее обозначаемой как «
4. Приведение к четкости: для нахождения z 0 вычисляется центр тяжести Алгоритм Цукамото Исходные посылки – как у предыдущего алгоритма, но в данном случае предполагается, что функции C 1 (z) и C 2 (z) являются монотонными. Алгоритм включает следующие шаги: 1. Первый этап такой же, как в алгоритме Мамдани. 2. На втором этапе сначала определяются (как в алгоритме Мамдани) уровни «отсечения» 3. Определяется четкое значение переменной вывода как взвешенное среднее z1 и z2:
В случае n нечетких множеств используется следующая формула:
Пример. Пусть имеем Степени истинности предпосылок правил определяются следующим образом:
и значения
При этом четкое значение переменной вывода
Алгоритм Сугено Алгоритм Сугено использует набор нечетких правил следующего вида: П1: если x есть A 1 и y есть B 1 то П2: если x есть A 2 и y есть B 2 то Алгоритм включает следующие шаги. 1. Первый шаг такой же, как в алгоритме Мамдани. 2. На втором шаге вычисляются 3. На третьем шаге определяется четкое значение переменной вывода по формуле:
Алгоритм Ларсена В этом алгоритме нечеткий вывод выполняется с использованием операции ПРОИЗВЕДЕНИЯ. Алгоритм включает следующие шаги. 1. Первый этап такой же, как в алгоритме Мамдани. 2. На втором этапе сначала определяются (как в алгоритме Мамдани) уровни «отсечения» 3. Вычисляется обобщенное нечеткое подмножество с функцией принадлежно- сти В случае n правил Выполняется приведение к четкости методом центра тяжести.
Лекция. Основные направления исследований в области искусственного интеллекта Основные направления исследований в области искусственного интеллекта следующие: 1. Разработка ИИС или систем, основанных на знаниях. Целью построения таких систем является применение знаний высококвалифицированных специалистов - экспертов для решения сложных практических задач. При этом используются знания, накопленные экспертами в виде конкретных правил решения тех или иных задач. В таких системах воспроизводится человеческий способ анализа неструктурированных и слабоструктурированных проблем. В рамках данного направления разрабатываются модели представления, извлечения и структурирования знаний, изучаются проблемы создания баз знаний, являющихся ядром систем, основанных на знаниях. Разработка естественно-языковых интерфейсов и машинный перевод. Системы машинного перевода предназначены для повышения доступности информации и оперативности перевода больших объемов научно-технических текстов. В основе таких систем лежит база знаний в определенной предметной области и сложные модели, обеспечивающие трансляцию «исходный язык оригинала – язык смысла – язык перевода». В этих системах осуществляется анализ и синтез естественно-языковых сообщений. 1 Данное направление охватывает разработку методов и систем, обеспечивающих общение человека с компьютером на естественном языке. 3. Генерация и распознавание речи. Системы речевого сообщения создаются для ускорения ввода информации в ЭВМ, разгрузки зрения и рук пользователя, для реализации речевого общения на значительном расстоянии. 4. Обработка визуальной информации. В этом направлении решаются задачи обработки, анализа и синтеза изображений. Задача обработки изображения связана с трансформированием графических образов в новые изображения. Задача анализа состоит в преобразовании исходного изображения в данные другого типа, например в текстовые описания. При синтезе изображений на вход системы поступает алгоритм построения изображения, а выходными данными являются графические объекты (системы машинной графики). 5. Обучение и самообучение. Эта область включает модели, методы и алгоритмы, ориентированные на автоматическое накопление и формирование знаний с использованием процедур анализа и обобщения данных. 6. Распознавание образов. Решение этой задачи состоит в отнесении объектов к классам, которые описываются совокупностями определенных значений признаков. 7. Игры и машинное творчество. Это направление охватывает сочинение компьютерной музыки, стихов, изобретение новых объектов, создание интеллектуальных компьютерных игр. 8. Программное обеспечение систем искусственного интеллекта. Это инструментальные средства для разработки интеллектуальных систем. Такие средства включают: специальные языки программирования, ориентированные на обработку символьной информации (LISP, SMALLTALK, РЕФАЛ); языки логического программирования (PROLOG); языки представления знаний (OPS 5, KRL, FRL); интегрированные программные среды для создания интеллектуальных систем (КЕ, ARTS, GURU); оболочки экспертных систем (BUILD, EMYCIN, ЭКСПЕРТ), позволяющие создавать прикладные экспертные системы (ЭС), не прибегая к программированию. 9. Интеллектуальные роботы. Для создания автономных интеллектуальных роботов необходимо решить проблемы в области интерпретации знаний, машинного зрения, адекватного хранения и обработки трёхмерной визуальной информации.
Лекция. Классификация ИИС Для интеллектуальных информационных систем характерны следующие признаки: - развитые коммуникативные способности; - умение решать сложные плохо формализуемые задачи; - способность к самообучению; - адаптивность. Коммуникативные способности определяют способ взаимодействия пользователя с системой. Решение сложных плохо формализуемых задач требует построения оригинальных алгоритмов решения в зависимости от конкретной ситуации, характеризующейся неопределенностью и динамичностью данных и знаний. Способность к самообучению – умение системы автоматически извлекать знания из накопленного опыта и применять их для решения задач. Адаптивность – способность системы к развитию в соответствии с изменениями области знаний. Каждому из перечисленных признаков соответствует свой класс интеллектуальных систем. Различные системы могут обладать одним или несколькими признаками интеллектуальности с разной степенью проявления.
Рис. 1 Классификация интеллектуальных информационных систем Системы с интеллектуальным интерфейсом Системы с интеллектуальным интерфейсом делят на три разновидности. Интеллектуальные базы данных позволяют в отличие от традиционных БД выполнять выборку информации, не присутствующей в явном виде, а выводи- мой из совокупности хранимых данных. Естественно-языковой интерфейс применяется для доступа к интеллектуальным базам данных, голосового ввода команд в системах управления, в системах машинного перевода с иностранных языков. Для реализации естественно-языкового интерфейса необходимо решить проблемы морфологического, синтаксического и семантического анализа, а также задачу синтеза высказываний на естественном языке. При морфологическом анализе осуществляется распознавание слов. В результате синтаксического анализа определяется структура предложения. Семантический анализ обеспечивает установление смысла синтаксических конструкций. Синтез высказываний заключается в преобразовании цифрового представления информации в представление на естественном языке. Системы когнитивной графики ориентированы на общение с пользователем посредством графических образов, которые генерируются в соответствии с изменением параметров моделируемых или наблюдаемых процессов. Когнитивная графика позволяет в наглядном виде представить множество параметров, характеризующих изучаемое явление; применяется в системах мониторинга и оперативного управления, в обучающих и тренажерных системах. Экспертные системы Экспертные системы (ЭС) предназначены для решения трудных прикладных задач, требующих привлечения знаний и опыта экспертов, т.е. для решения неформализованных проблем, к которым относят задачи, обладающие одной (или несколькими) из следующих характеристик: - задача не может быть представлена в числовой форме; - исходные данные и знания предметной области обладают неточностью, неоднозначностью, противоречивостью; - не существует однозначного алгоритма решения задачи; - алгоритм решения существует, но его нельзя использовать из-за большой размерности пространства решений и ограничений на ресурсы времени и памяти. Одним из важных свойств ЭС является способность объяснить ход своих рассуждений понятным для пользователя образом. ЭС применяются в разных предметных областях – в бизнесе, производстве, медицине, проектировании и системах управления. ЭС является инструментом, усиливающим интеллектуальные способности эксперта. Экспертная система может выступать в роли: - консультанта для непрофессиональных пользователей; - ассистента эксперта – человека в процессе анализа вариантов решений; - партнера эксперта в процессе решения задач, требующих привлечения знаний из разных предметных областей. Выделяют четыре класса экспертных систем. Классифицирующие ЭС решают задачи распознавания ситуаций. Основным методом решения является дедуктивный логический вывод. Доопределяющие ЭС используются для решения задач с не полностью определенными данными и знаниями. В качестве методов обработки неопределенных знаний используются вероятностный подход, коэффициенты уверенности, нечеткая логика. Трансформирующие ЭС относятся к синтезирующим динамическим экспертным системам. В таких системах используются следующие способы обработки знаний: - генерация и проверка гипотез; - логика предположений и умолчаний, когда по неполным данным формируются представления об объектах определенного класса, которые затем адаптируются к условиям конкретных ситуаций; - использование метазнаний (более общих закономерностей) для устранения неопределенностей ситуаций. Мультиагентные системы – это динамические ЭС, основанные на объединении нескольких различных источников знаний. Эти источники обмениваются между собой получаемыми результатами в ходе решения задач. Системы данного класса имеют следующие возможности: - реализация альтернативных рассуждений на основе использования различных источников знаний и механизма устранения противоречий; - распределенное решение задач, декомпозируемых на параллельно решаемые подзадачи с самостоятельными источниками знаний; - применение различных стратегий вывода заключений в зависимости от типа решаемой задачи; - обработка больших массивов информации из баз данных. Самообучающиеся системы Самообучающиеся системы основаны на методах автоматической классификации ситуаций из реальной практики или на методах обучения на примерах. Примеры реальных ситуаций составляют так называемую обучающую выборку. Элементы обучающей выборки описываются множеством классификационных признаков. Используются стратегии обучения «с учителем» и «без учителя». При обучении «с учителем» для каждого примера задаются значения признаков, показывающие его принадлежность к определенному классу ситуаций. При обучении «без учителя» система сама выделяет классы ситуаций по степени близости значений классификационных признаков. Самообучающиеся системы, построенные на этих принципах, имеют следующие недостатки: - относительно низкую адекватность баз знаний реальным проблемам из-за неполноты и/или зашумленности обучающей выборки; - низкую степень объяснимости полученных результатов; - поверхностное описание предметной области и узкую направленность применения из-за ограничений размерности пространства признаков. Индуктивные системы позволяют обобщать примеры на основе принципа индукции «от частного к общему». Обобщение сводится к классификации примеров по значимым признакам. Нейронные сети представляют собой группу алгоритмов, обладающих способностью обучаться на примерах. Нейронные сети используются при решении задач обработки сигналов и изображений, распознавания образов, прогнозирования. Нейронная сеть – это кибернетическая модель нервной системы, представляющая собой совокупность сравнительно простых элементов - нейронов. Способ соединения нейронов зависит от типа сети. Чтобы ее построить нейронную сеть для решения какой-либо конкретной задачи, следует выбрать способ соединения нейронов друг с другом и подобрать значения параметров межнейронных соединений. В системах, основанных на прецедентах, база знаний содержит описания конкретных ситуаций (прецеденты). Прецеденты описываются множеством признаков. Поиск решения осуществляется на основе аналогий и включает сопоставление информации о текущей проблеме со значениями признаков прецедентов из базы знаний, выбор прецедента, наиболее близкого к рассматриваемой проблеме, адаптацию выбранного прецедента к текущей проблеме, проверку корректности полученного решения и занесение информации о полученном решении в базу знаний. Информационные хранилища представляют собой хранилища информации, регулярно извлекаемой из оперативных баз данных. В отличие от оперативных баз данных, где данные постоянно меняются и присутствуют только в последней версии, хранилище данных – это предметно-ориентированное, привязанное ко времени, неизменяемое собрание данных, применяемых для поддержки процессов принятия управленческих решений. Технологии обработки информации в хранилище ориентированы на поиск закономерностей и отношений, скрытых в совокупности данных. Эти закономерности могут использоваться для оптимизации деятельности предприятия. Для извлечения информации из хранилищ данных используются специальные методы анализа данных, основанные на применении математической статистики, нейронных сетей, построении деревьев решений и др. Представление в виде теорем Многие задачи, особенно задачи логического типа, могут быть сформулированы как теоремы, подлежащие доказательству. При таком представлении задаются посылки, т.е. множество известных истинных утверждений (аксиом). Затем формулируется теорема, доказательство которой дает решение исходной задачи. Поиск решения выполняется следующим образом: комбинируя по-разному две аксиомы или более, выводятся утверждения, которые можно получить из посылок. Затем проверяется, не содержит ли полученное множество утверждений теорему или ее отрицание. Если содержит, то теорема доказана или соответственно отвергнута. Если теорема или ее отрицание не содержится, то полученное множество утверждений добавляется к посылкам и процедура повторяется. Такой метод поиска решения (доказательства) фактически является методом полного перебора. На практике применение этого метода ограничено, так как при полном переборе может потребоваться чрезмерно большой объем памяти и большое время решения. Рис. 8.3 Граф состояний задачи о выборе маршрута Поиск решений имеет итеративный характер, причем число итераций и вершин, раскрытых до нахождения целевой вершины, существенно зависит от порядка раскрытия вершин. Порядок раскрытия вершин называют стратегией поиска. Выделяют два основных типа стратегий поиска: «слепой» перебор и упорядоченный перебор вершин – кандидатов на раскрытие. Слепой перебор характеризуется тем, что расположение целевых вершин или их близость не влияют на порядок раскрытия. Существует несколько алгоритмов слепого перебора. Рассмотрим три наиболее типичных: алгоритм полного перебора, алгоритм равных цен, алгоритм перебора в глубину. Алгоритм полного перебора Вершины раскрываются в том порядке, в котором они были порождены. Первой раскрывается начальная вершина. Проверяется среди порожденных вершин наличие целевой. Если есть, поиск заканчивается. Если нет, то раскрывается первая из порожденных вершин и проверяется наличие целевых вершин. Затем раскрывается вторая из порожденных вершин и т.д. Для записи алгоритмов поиска в пространстве состояний введем понятия списков открытых (ОТК) и закрытых (ЗКР) вершин. Список закрытых вершин – это список, где размещаются идентификаторы раскрытых вершин и идентификатор вершины, которую предстоит раскрыть в данный момент. Вершины из списка ЗКР, кроме последней, раскрывать нельзя. Список открытых вершин – это список, где размещаются идентификаторы вершин, которые могут и должны быть раскрыты. Стратегии поиска различаются правилами размещения вершин в списке ОТК и выбора очередной вершины для раскрытия. Алгоритм полного перебора включает следующие шаги. 1. Поместить начальную вершину в список ОТК. 2. Если список ОТК пуст, выдать сообщение о неудаче поиска, иначе перейти к следующему шагу. 3. Взять первую вершину из списка ОТК и перенести ее в список ЗКР, присвоить вершине идентификатор  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Что вызывает тренды на фондовых и товарных рынках Объяснение теории грузового поезда Первые 17 лет моих рыночных исследований сводились к попыткам вычислить, когда этот... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 ;
;  .
. , такое что
, такое что  > 0.
> 0.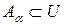 , для которого верно:
, для которого верно:  .
. .
. . Если высота нечеткого множества
. Если высота нечеткого множества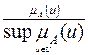 .
.



 или
или 
 или u > 300
или u > 300


 ,
,  ). Таким образом, человек с таким ростом будет считаться скорее высоким, чем низким.
). Таким образом, человек с таким ростом будет считаться скорее высоким, чем низким. с функцией принадлежности
с функцией принадлежности  .
. .
. .
.

 ;
; 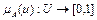 .
. Нечеткое число А называется нечетким числом (L – R)– типа, если его функция принадлежности имеет следующий вид (рис. 7.8):
Нечеткое число А называется нечетким числом (L – R)– типа, если его функция принадлежности имеет следующий вид (рис. 7.8):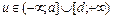


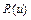 ,
, 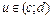
 – параметры нечеткого числа; L (x), R (x) – некоторые функции.
– параметры нечеткого числа; L (x), R (x) – некоторые функции.
 ,
,  .
. или
или и
и  .
.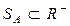 или
или .
. .
. .
.
 вычисляется по формуле:
вычисляется по формуле: . (7.4)
. (7.4) ,
,
 – функции принадлежности нечетких множеств M и N;
– функции принадлежности нечетких множеств M и N;
 – основания нечетких множеств M и N.
– основания нечетких множеств M и N.
 ,
,  ,
, » обозначена операция взятия минимума (min), затем вычисляются «усеченные» функции принадлежности
» обозначена операция взятия минимума (min), затем вычисляются «усеченные» функции принадлежности ,
,  .
. ») производится объединение найденных усеченных функций, в результате определяется итоговое нечеткое подмножество для переменной вывода с функцией принадлежности:
») производится объединение найденных усеченных функций, в результате определяется итоговое нечеткое подмножество для переменной вывода с функцией принадлежности:
 .
. и
и  , затем в результате решения уравнений
, затем в результате решения уравнений  ,
,  вычисляются четкие значения (z 1 и z2) для каждого из исходных правил.
вычисляются четкие значения (z 1 и z2) для каждого из исходных правил.
 .
. ,
,  ,
,  ,
,  .
. ,
,
 и
и  вычисляются в результате решения уравнений
вычисляются в результате решения уравнений ,
,  .
. .
. ,
, .
. ,
,  .
. .
. ,
,  .
. .
. .
. На рис 1 приведена классификация ИИС на основе указанных признаков.
На рис 1 приведена классификация ИИС на основе указанных признаков.