
|
|
Линейная разделимость и персептронная представляемость ⇐ ПредыдущаяСтр 9 из 9 Каждый нейрон персептрона является формальным пороговым элементом, принимающим единичные значения в случае, если суммарный взвешенный вход больше некоторого порогового значения:
Таким образом, при заданных значениях весов и порогов, нейрон имеет определенное значение выходной активности для каждого возможного вектора входов. Множество входных векторов, при которых нейрон активен (y =1), отделено от множества векторов, на которых нейрон пассивен (y =0) гиперплоскостью, уравнение которой имеет вид:
Следовательно, нейрон способен отделить (иметь различный выход) только такие два множества векторов входов, для которых имеется гиперплоскость, отсекающая одно множество от другого. Такие множества называют линейно разделимыми. Проиллюстрируем это понятие на примере. Пусть имеется нейрон, для которого входной вектор содержит только две булевые компоненты На рис 10.9 представлена одна из ситуаций, когда этого сделать нельзя вследствие линейной неразделимости множеств белых и черных точек.
Рис. 10.9. Белые точки не могут быть отделены одной прямой от черных. Требуемые выходы нейрона для этого рисунка определяются таблицей, которая задает логическую функцию “исключающее или”:
Линейная неразделимость множеств аргументов, отвечающих различным значениям функции означает, что функция “исключающее или”, широко использующаяся в логических устройствах, не может быть представлена формальным нейроном. Итак, однослойный персептрон крайне ограничен в своих возможностях точно представить наперед заданную логическую функцию. Позднее, в начале 70-х годов, это ограничение было преодолено путем введения нескольких слоев нейронов, однако критическое отношение к классическому персептрону сильно заморозило общий круг интереса и научных исследований в области искусственных нейронных сетей. Многослойный персептрон Выше было показано, что существуют ограничения на возможности однослойных сетей, в частности требование линейной разделимости классов. Особенности строения биологических сетей подталкивают исследователя к использованию более сложных, и в частности, иерархических архитектур. Идея относительно проста – на низших уровнях иерархии классы преобразуются таким образом, чтобы сформировать линейно разделимые множества, которые в свою очередь будут успешно распознаваться нейронами на следующих (высших) уровнях иерархии. Рассмотрим иерархическую сетевую структуру, в которой связанные между собой нейроны (узлы сети) объединены в несколько слоев (рис. 10.10). Межнейронные связи сети устроены таким образом, что каждый нейрон на данном уровне иерархии принимает и обрабатывает сигналы от каждого нейрона более низкого уровня. Таким образом, в данной сети имеется выделенное направление распространения нейроимпульсов – от входного слоя через один (или несколько) скрытых слоев к выходному слою нейронов. Нейросеть такой топологии будем называть многослойным персептроном или просто персептроном.
Рис.10.10. Структура многослойного персептрона с пятью входами, тремя нейронами в скрытом слое, и одним нейроном выходного слоя. Персептрон представляет собой сеть, состоящую из нескольких последовательно соединенных слоев формальных нейронов. На низшем уровне иерархии находится входной слой, задачей которого является только прием и распространение по сети входной информации. Далее имеются один или несколько скрытых слоев. Каждый нейрон в скрытом слое имеет несколько входов, соединенных с выходами нейронов предыдущего слоя или непосредственно со входами x 1,..., x n, и один выход. Нейрон характеризуется уникальным вектором весовых коэффициентов w. Веса всех нейронов слоя формируют матрицу, которую мы будем обозначать V или W. Функция нейрона состоит в вычислении взвешенной суммы его входов с дальнейшим нелинейным преобразованием ее в выходной сигнал:
Выходы нейронов последнего, выходного, слоя описывают результат классификации Y = Y (X). Особенности работы персептрона состоят в следующем. Каждый нейрон суммирует поступающие к нему сигналы от нейронов предыдущего уровня иерархии с определенными весами и формирует выходной сигнал (переходит в возбужденное состояние), если полученная сумма выше порогового значения. Персептрон переводит входной образ, определяющий степени возбуждения нейронов самого нижнего уровня иерахии, в выходной образ, определяемый нейронами самого верхнего уровня. Число последних, обычно, сравнительно невелико. Выход нейрона на верхнем уровне говорит о принадлежности входного образа к той или иной категории. Легко заметить, что порог нейрона может быть сделан эквивалентным дополнительному весу, соединенному с фиктивным входом, равным -1. Действительно, выбирая W 0 = θ, x 0 = -1 и начиная суммирование с нуля, можно рассматривать нейрон с нулевым порогом и одним дополнительным входом:
Дополнительные входы нейронов, соответствующие порогам, изображены на рис. 10.10 темными квадратиками. С учетом этого, все формулы суммирования по входам начинаются с нулевого индекса. Традиционно используется аналоговая логика, при которой допустимые состояния связей определяются произвольными действительными числами, а выходы нейронов – действительными числами между 0 и 1. Опишем классический вариант многослойной сети с аналоговыми синапсами и сигмоидальной активационной функцией нейронов, определяемой формулой (10.1). Для обучения многослойной сети в 1986 г. был предложен алгоритм обратного распространения ошибок (error back propagation). Многочисленные публикации о промышленных применениях многослойных сетей с этим алгоритмом обучения подтвердили его принципиальную работоспособность на практике. Для обучения многослойного персептрона нельзя применить уже известное δ - правило Розенблатта, т.к. для применения метода Розенблатта необходимо знать не только текущие выходы нейронов y, но и требуемые правильные значения Y. В случае многослойной сети эти правильные значения имеются только для нейронов выходного слоя. Требуемые значения выходов для нейронов скрытых слоев неизвестны, что и ограничивает применение δ - правила. Основная идея обратного распространения состоит в том, как получить оценку ошибки для нейронов скрытых слоев. Заметим, что известные ошибки, делаемые нейронами выходного слоя, возникают вследствие неизвестных ошибок нейронов скрытых слоев. Чем больше значение синаптической связи между нейроном скрытого слоя и выходным нейроном, тем сильнее ошибка первого влияет на ошибку второго. Следовательно, оценку ошибки элементов скрытых слоев можно получить, как взвешенную сумму ошибок последующих слоев. При обучении информация распространяется от низших слоев иерархии к высшим, а оценки ошибок, делаемых сетью, – в обратном направлении, что и отражено в названии метода. Перейдем к подробному рассмотрению этого алгоритма. Для упрощения обозначений ограничимся ситуацией, когда сеть имеет только один скрытый слой. Матрицу весовых коэффициентов от входов к скрытому слою обозначим W, а матрицу весов, соединяющих скрытый и выходной слой – V. Для индексов примем следующие обозначения: входы будем нумеровать только индексом i, элементы скрытого слоя – индексом j, а выходы, соответственно, – индексом k. Пусть сеть обучается на выборке Общая структура алгоритма имеет следующий вид. Шаг 0. Начальные значения весов всех нейронов всех слоев V (t =0) и W (t =0) полагаются случайными числами. Шаг 1.Сети предъявляется входной образ скрытый слой
выходной слой
Здесь f (x) - сигмоидальная функция, определяемая по формуле (10.1) Шаг 2. Функционал квадратичной ошибки сети для данного входного образа имеет вид: Данный функционал подлежит минимизации. Классический градиентный метод оптимизации состоит в итерационном уточнении аргумента согласно формуле:
Функция ошибки в явном виде не содержит зависимости от веса Vjk, поэтому воспользуемся формулами неявного дифференцирования сложной функции:
Здесь учтено полезное свойство сигмоидальной функции f (x): ее производная выражается только через само значение функции, Шаг 3. На этом шаге выполняется подстройка весов скрытого слоя. Градиентный метод дает:
Вычисления производных выполняются по тем же формулам, за исключением некоторого усложнения формулы для ошибки
При вычислении Шаг 4. Шаги 1-3 повторяются для всех обучающих векторов. Обучение завершается по достижении малой полной ошибки или максимально допустимого числа итераций, как и в методе обучения Розенблатта. Таким образом, обучение сводится к решению задачи оптимизации функционала ошибки градиентным методом. Суть обратного распространения ошибки состоит в том, что для ее оценки для нейронов скрытых слоев можно принять взвешенную сумму ошибок последующего слоя. Параметр h имеет смысл темпа обучения и выбирается достаточно малым для сходимости метода. О сходимости необходимо сделать несколько дополнительных замечаний. Во-первых, практика показывает, что сходимость метода обратного распространения весьма медленная. Невысокий темп сходимости является “генетической болезнью” всех градиентных методов, так как локальное направление градиента отнюдь не совпадает с направлением к минимуму. Во-вторых, подстройка весов выполняется независимо для каждой пары образов обучающей выборки. При этом улучшение функционирования на некоторой заданной паре может, вообще говоря, приводить к ухудшению работы на предыдущих образах. В этом смысле, нет достоверных (кроме весьма обширной практики применения метода) гарантий сходимости. Исследования показывают, что для представления произвольного функционального отображения, задаваемого обучающей выборкой, достаточно всего два слоя нейронов. Однако на практике, в случае сложных функций, использование более чем одного скрытого слоя может давать экономию полного числа нейронов.   Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|


 , определяющие плоскость. На данной плоскости возможные значения векторов отвечают вершинам единичного квадрата. В каждой вершине определено требуемое значение выхода нейрона 1 (на рис. 10.9 белая точка) или 0 (черная точка). Требуется определить, существует ли такой набор весов и порогов нейрона, при котором этот нейрон сможет отделить точки разного цвета?
, определяющие плоскость. На данной плоскости возможные значения векторов отвечают вершинам единичного квадрата. В каждой вершине определено требуемое значение выхода нейрона 1 (на рис. 10.9 белая точка) или 0 (черная точка). Требуется определить, существует ли такой набор весов и порогов нейрона, при котором этот нейрон сможет отделить точки разного цвета?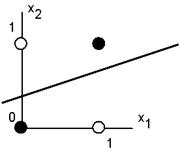

 (10.1)
(10.1)
 ,
,  . Выходы нейронов будем обозначать малыми буквами y с соответствующим индексом, а суммарные взвешенные входы нейронов – малыми буквами x.
. Выходы нейронов будем обозначать малыми буквами y с соответствующим индексом, а суммарные взвешенные входы нейронов – малыми буквами x. и формируется выходной образ
и формируется выходной образ  . При этом нейроны последовательно от слоя к слою функционируют по следующим формулам:
. При этом нейроны последовательно от слоя к слою функционируют по следующим формулам:








 . Таким образом, все необходимые величины для подстройки весов выходного слоя V получены.
. Таким образом, все необходимые величины для подстройки весов выходного слоя V получены.
 :
:
