|
|
Алгоритм First-Come, First-Served (FCFS)Простейшим алгоритмом является алгоритм First Come First Served (FCFS) - первым пришел, первым обслужен. Все запросы организуются в очередь FIFO и обслуживаются в порядке поступления. Алгоритм прост в реализации, но может приводить к достаточно большим общим временам обслуживания запросов. Рассмотрим пример. Пусть у нас на диске из 100 цилиндров (от 0 до 99) есть следующая очередь запросов: 23, 67, 55, 14, 31, 7, 84, 10 и головки в начальный момент находятся на 63 цилиндре. Тогда положение головок будет меняться следующим образом: 63->23->67->55->14->31->7->84->10 и всего головки переместятся на 329 цилиндров. Неэффективность алгоритма хорошо иллюстрируется двумя последними перемещениями с 7 цилиндра через весь диск на 84 цилиндр и, затем опять через весь диск на цилиндр 10. Простая замена порядка двух последних перемещений (7->10->84) позволила бы существенно сократить общее время обслуживания запросов. Алгоритм Short Seek Time First (SSTF) Достаточно разумным является первоочередное обслуживание запросов, данные для которых лежат рядом с текущей позицией головок, а уж затем далеко отстоящих. Алгоритм Short Seek Time First (SSTF) - короткое время поиска первым - как раз и исходит из этой позиции. Для очередного обслуживания будем выбирать запрос, данные для которого лежат наиболее близко к текущему положению магнитных головок. Естественно, что при наличии равноудаленных запросов, решение о выборе между ними может приниматься из различных соображений, например по алгоритму FCFS. Для предыдущего примера алгоритм даст следующую последовательность положений головок: 63->67->55->31->23->14->10->7->84 и всего головки переместятся на 141 цилиндр. Однако недостатком данного алгоритма является то, что он может приводить к длительному откладыванию выполнения какого-либо запроса. Необходимо заметить, что запросы в очереди могут появляться в любой момент времени. Если все запросы, кроме одного, постоянного группируются в области с большими номерами цилиндров, то этот один запрос может находиться в очереди неопределенно долго. Алгоритмы сканирования (SCAN, C-SCAN, LOOK, C-LOOK) В простейшем из алгоритмов сканирования – SCAN – головки постоянно перемещаются от одного края диска до его другого края, по ходу дела обслуживая все встречающиеся запросы. По достижении другого края направление движения меняется, и все повторяется снова. Пусть в предыдущем примере в начальный момент времени головки двигаются в направлении уменьшения номеров цилиндров. Тогда мы и получим порядок обслуживания запросов, подсмотренный в конце предыдущего раздела. Последовательность перемещения головок выглядит следующим образом: 63->55->31->23->14->10->7->0->67->84 и всего головки переместятся на 147 цилиндров. Если известно, что был обслужен последний попутный запрос в направлении движения головок, то можно не доходить до края диска, а сразу изменить направление движения на обратное: 63->55->31->23->14->10->7->67->84 и всего головки переместятся на 133 цилиндра. Полученная модификация алгоритма SCAN получила название LOOK. Допустим, что к моменту изменения направления движения головки в алгоритме SCAN, т.е. когда головка достигла одного из краев диска, у этого края накопилось большое количество новых запросов, на обслуживание которых будет потрачено достаточно большое время (не забываем, что надо не только перемещать головку, но еще и передавать прочитанные данные!). Тогда запросы, относящиеся к другому краю диска и поступившие раньше, будут ждать обслуживания несправедливо долгое время. Для сокращения времени ожидания запросов применяется другая модификация алгоритма SCAN – циклическое сканирование. Когда головка достигает одного из краев диска, она без чтения попутных запросов (иногда существенно быстрее, чем при выполнении обычного поиска цилиндра) перемещается на другой край, откуда вновь начинает свое движение. Для этого алгоритма, получившего название C-SCAN, последовательность перемещений будет выглядеть так: 63->55->31->23->14->10->7->0->99->84->67 По аналогии с алгоритмом LOOK для алгоритма SCAN можно предложить и алгоритм C-LOOK для алгоритма C-SCAN: 63->55->31->23->14->10->7->84->67 9. Файловая система Все компьютерные приложения нуждаются в хранении и обновлении информации. Возможности оперативной памяти для хранения информации ограничены. Во-первых, оперативная память обычно теряет свое содержимое после отключения питания, а во-вторых, объем обрабатываемых данных зачастую превышает ее возможности. Кроме того, информацию желательно иметь в виде, независимом от процессов. Поэтому принято хранить данные на внешних носителях (обычно это диски) в единицах, называемых файлами. В большинстве компьютерных систем предусмотрены устройства внешней (вторичной) памяти, большой емкости, на которых можно хранить огромные объемы данных. Однако характеристики доступа к таким устройствам существенно отличаются от характеристик доступа к основной памяти. Чтобы повысить эффективность использования этих устройств, был разработан ряд специфичных для них структур данных и алгоритмов. До использования дисков каждая прикладная программа сама решала проблемы именования данных и структуризации данных во внешней памяти. Это затрудняло поддержание на внешнем носителе нескольких архивов долговременно хранимой информации. Важным историческим шагом явился переход к использованию централизованных систем управления файлами. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в адреса внешней памяти и обеспечение доступа к данным. Понятие «файловая система». Основная идея использования внешней памяти состоит в следующем. ОС делит ее на блоки фиксированного размера, например, 4096 байт. С точки зрения пользователя каждый файл состоит из набора индивидуальных элементов, называемых записями (например, характеристика какого-нибудь объекта). Каждый файл хранится в виде определенной последовательности блоков (не обязательно смежных); каждый блок хранит целое число записей. В некоторых ОС (MS-DOS) адреса блоков, содержащих данные файла, могут быть организованы в связный список и вынесены в отдельную таблицу в памяти. В других ОС (Unix), адреса блоков данных файла хранятся в отдельном блоке внешней памяти (так называемом индексе или индексном узле). Этот прием называется индексацией и является наиболее распространенным для приложений, требующих произвольного доступа к записям файлов. Индекс файла состоит из списка элементов, каждый из которых содержит номер блока в файле и указание о местоположении данного блока. В современных ОС файлы обычно представляют собой неструктурированную последовательность байтов (длина записи равна 1) и считывание очередного байта осуществляется с так называемой текущей позиции, которая характеризуется смещением от начала файла. Зная размер блока, легко вычислить номер блока, содержащего текущую позицию. Адрес же нужного блока диска можно затем извлечь из индекса файла. Базовой операцией, выполняемой по отношению к файлу, является чтение блока с диска и перенос его в буфер, находящийся в основной памяти. Файловая система позволяет при помощи системы справочников (каталогов, директорий) связать уникальное имя файла с блоками вторичной памяти, содержащими данные файла. Иерархическая структура каталогов, используемая для управления файлами, является другим примером индексной структуры. В этом случае каталоги или папки играют роль индексов, каждый из которых содержит ссылки на свои подкаталоги. С этой точки зрения вся файловая система компьютера представляет собой большой индексированный файл. Важный аспект организации файловой системы - учет стоимости операций взаимодействия с вторичной памятью. Процесс считывания блока диска состоит из позиционирования считывающей головки над дорожкой, содержащей требуемый блок, ожидания, пока требуемый блок сделает оборот и окажется под головкой и собственно считывания блока. Для этого требуется значительное время (десятки миллисекунд). В современных компьютерах обращение к диску примерно в 100000 медленнее, чем обращение к памяти. Таким образом, критерием вычислительной сложности алгоритмов, работающих с внешней памятью, является количество обращений к диску. Функции файловых систем Файлы управляются ОС. То, как они структурированы, поименованы, используются, защищены, реализованы – одна из главных тем проектирования ОС. Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную работу с данными, хранящимися во внешней памяти, и обеспечить пользователю и прикладным процессам удобный интерфейс при работе с этими данными. В широком смысле понятие «файловая система» включает: · совокупность всех файлов на диске, · наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске, · комплекс системных программных средств, реализующих управление файлами, в частности: создание, уничтожение, чтение, запись, именование, поиск и другие операции над файлами. Основные функции файловой системы: 1. Идентификация файлов. Связывание имени файла с выделенным ему пространством внешней памяти 2. Распределение внешней памяти между файлами. Для работы с конкретным файлом не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того, чтобы загрузить документ в редактор с жесткого диска нам не требуется знать на какой стороне какого магнитного диска и на каком цилиндре и в каком секторе находится требуемый документ 3. Обеспечение надежности и отказоустойчивости. Стоимость информации может во много раз превышать стоимость компьютера 4. Обеспечение защиты от НСД. 5. Обеспечение совместного доступа к файлам, не требуя от пользователя специальных усилий по обеспечению синхронизации доступа 6. Обеспечение высокой производительности. С точки зрения ОС файл - поименованный набор связанной информации, записанной во вторичную память. С точки зрения пользователя файл - минимальная величина внешней памяти, то есть данные, записанные на диск должны быть в составе какого-нибудь файла. Имена файлов Файлы - абстрактные объекты. Они предоставляют пользователям возможность сохранять информацию, скрывая от него детали того, как и где она хранится и то, как диски в действительности работают. Одна из наиболее важных характеристик любого абстрактного механизма - способ именования объектов, которыми он управляет. Когда процесс создает файл, он дает файлу имя. После завершения процесса файл продолжает существовать и через свое имя может быть доступен другим процессам. Многие ОС поддерживают имена из двух частей (имя+расширение), например progr.c(файл, содержащий текст программы на языке Си) или autoexec.bat (файл, содержащий команды интерпретатора командного языка). Тип расширения файла позволяет ОС организовать работу с ним различных прикладных программ в соответствии с заранее оговоренными соглашениями. Пользователи (или процессы) дают файлам символьные имена, при этом учитываются накладываемые ОС ограничения, как на используемые в имени символы, так и на длину имени. Например, в ОС Unix учитывается регистр при вводе имени файла (case sensitive), а в MS-DOS - нет. В популярной файловой системе FAT длина имен ограничивается известной схемой 8.3 (8 символов - собственно имя, 3 символа - расширение имени), а в ОС UNIX System V имя не может содержать более 14 символов. Однако пользователю гораздо удобнее работать с длинными именами, поскольку они позволяют дать файлу действительно мнемоническое название, по которому даже через достаточно большой промежуток времени можно будет вспомнить, что содержит этот файл. Поэтому современные файловые системы, как правило, поддерживают длинные символьные имена файлов. Так, в соответствии со стандартом POSIX, в ОС UNIX допускаются имена длиной до 255 символов, та же самая длина устанавливается для имен файлов и в ОС Windows NT для файловой системы NTFS. При переходе к длинным именам возникает проблема совместимости с ранее созданными приложениями, использующими короткие имена. Чтобы приложения могли обращаться к файлам в соответствии с принятыми ранее соглашениями, файловая система должна уметь предоставлять эквивалентные короткие имена (псевдонимы) файлам, имеющим длинные имена. Таким образом, одной из важных задач становится проблема генерации соответствующих коротких имен. Длинные имена поддерживаются не только новыми файловыми системами, но и новыми версиями хорошо известных файловых систем. Например, в ОС Windows 95 используется файловая система VFAT, представляющая собой существенно измененный вариант FAT. Среди многих других усовершенствований одним из главных достоинств VFAT является поддержка длинных имен. Кроме проблемы генерации эквивалентных коротких имен, при реализации нового варианта FAT важной задачей была задача хранения длинных имен при условии, что принципиально метод хранения и структура данных на диске не должны были измениться. Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл однозначно идентифицируется так называемым составным именем, представляющем собой последовательность символьных имен каталогов. В некоторых системах одному и тому же файлу не может быть дано несколько разных имен, а в других такое ограничение отсутствует. В последнем случае операционная система присваивает файлу дополнительно уникальное имя, так, чтобы можно было установить взаимно-однозначное соответствие между файлом и его уникальным именем. Уникальное имя представляет собой числовой идентификатор и используется программами операционной системы. Примером такого уникального имени файла является номер индексного дескриптора в системе UNIX. Типы файлов Файлы бывают разных типов: обычные (регулярные) файлы, специальные файлы, файлы- каталоги. Обычные файлы в свою очередь подразделяются на текстовые и двоичные. Текстовые файлы состоят из строк символов, представленных в ASCII-коде. Это могут быть документы, исходные тексты программ и т.п. Текстовые файлы можно прочитать на экране и распечатать на принтере. Двоичные файлы не используют ASCII-коды, они часто имеют сложную внутреннюю структуру, например, объектный код программы или архивный файл. Все операционные системы должны уметь распознавать хотя бы один тип файлов - их собственные исполняемые файлы. Обычно прикладные программы, работающие с файлами, распознают тип файла по его имени в соответствии с общепринятыми соглашениями. Например, файлы с расширениями.cрр,.pas,.txt - ASCII файлы, файлы с расширениями.exe - выполнимые, файлы с расширениями.obj,.zip - бинарные и т.д. Специальные файлы - это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю выполнять операции ввода-вывода, используя обычные команды записи в файл или чтения из файла. Эти команды обрабатываются вначале программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются ОС в команды управления соответствующим устройством. Специальные файлы, так же как и устройства ввода-вывода, делятся на блок-ориентированные и байт-ориентированные. Количество файлов на компьютере может быть большим. Отдельные системы хранят тысячи файлов, занимающие сотни гигабайтом диска. Эффективное управление этими данными подразумевает наличие в них четкой логической структуры. Все современные файловые системы поддерживают многоуровневое именование файлов за счет поддержания во внешней памяти дополнительных файлов со специальной структурой – каталогов (или директорий). Каталог - это, с одной стороны, группа файлов, объединенных пользователем исходя из некоторых соображений (например, файлы, содержащие программы игр, или файлы, составляющие один программный пакет). С другой стороны - это файл, содержащий системную информацию о группе файлов, его составляющих. Каждый каталог содержит список каталогов и/или файлов, содержащихся в данном каталоге. Каталоги имеют один и тот же внутренний формат, где каждому файлу соответствует одна запись в файле директории. Помимо имени ОС часто связывают с каждым файлом и другую информацию, например дату модификации, размер и т.д. Эти другие характеристики файлов называются атрибутами. В разных файловых системах могут использоваться в качестве атрибутов разные характеристики, например: · информация о разрешенном доступе, · пароль для доступа к файлу, · владелец файла, · создатель файла, · признак "только для чтения", · признак "скрытый файл", · признак "системный файл", · признак "архивный файл", · признак "двоичный/символьный", · признак "временный" (удалить после завершения процесса), · признак блокировки, · длина записи, · указатель на ключевое поле в записи, · длина ключа, · времена создания, последнего доступа и последнего изменения, · текущий размер файла, · максимальный размер файла. Эта информация обычно хранится в структуре директорий или других структурах, обеспечивающих доступ к данным файла. Запись в директории имеет определенный для данной ОС формат, который зачастую неизвестен пользователю. Поэтому блоки данных файла-директории заполняются не через операции записи, а при помощи специальных системных вызовов (например, создание файла). Для доступа к файлу ОС использует путь (pathname), указанный пользователем. Запись в директории связывает имя файла или имя поддиректории с блоками данных на диске. В зависимости от системы эта ссылка может быть дисковым адресом целого файла (непрерывное расположение), номером первого блока (связанный список), или номером индексного узла. Во всех случаях главная функция системы директорий - трансформировать символьное имя файла в информацию, необходимую, чтобы найти данные. Отдельная проблема способ хранения атрибутов файла. Каталоги могут непосредственно содержать значения характеристик файлов, как это сделано в файловой системе MS-DOS (рис.36), или ссылаться на таблицы, содержащие эти характеристики, как это реализовано в ОС UNIX (рис. 37).
Рис. 36. Вариант записи в директории MS-DOS
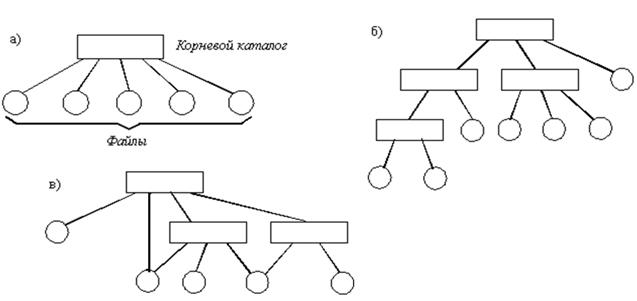
Рис. 37. Вариант записи в директории Unix Когда система открывает файл, она ищет имя файла в директории. Затем извлекаются атрибуты и адреса блоков файла на диске или непосредственно из записи в директории или из структуры, на которую запись в директории указывает. Эта информация помещается в системную таблицу в главной памяти. Все последующие ссылки на этот файл используют эту информацию. Число директорий зависит от системы. В ранних ОС имелась только одна корневая директория, затем появились директории для пользователей (по одной директории на пользователя). В современных ОС используется произвольная структура дерева директорий. Каталоги могут образовывать иерархическую структуру за счет того, что каталог более низкого уровня может входить в каталог более высокого уровня (рис. 38). Иерархия каталогов может быть деревом или сетью.
Рис. 38. Логическая организация файловой системы Каталоги образуют дерево, если файлу разрешено входить только в один каталог, и сеть - если файл может входить сразу в несколько каталогов. В MS-DOS каталоги образуют древовидную структуру, а в UNIX'е - сетевую. Как и любой другой файл, каталог имеет символьное имя и однозначно идентифицируется составным именем, содержащим цепочку символьных имен всех каталогов, через которые проходит путь от корня до данного каталога. Поиск в директории Итак, директория - есть файл, имеющий специальный формат, состоящий из записей фиксированной длины, где каждая запись соответствует одному из обычных файлов или директорий, входящих в состав данной директории. Как правило, список файлов в директории оказывается не упорядоченным по именам файлов. Поэтому правильный выбор алгоритма поиска имени файла в директории имеет большое влияние на эффективность и надежность файловых систем. Линейный поиск Совокупность записей о файлах в директории является линейным списком символьных имен файлов. Существует несколько стратегий просмотра такого списка. Простейшей из них является линейный поиск. Директория просматривается с самого начала, пока не встретится нужное имя файла. Хотя это наименее эффективный способ поиска, оказывается, что в большинстве случаев он работает с приемлемой производительностью. Например, авторы Unix утверждали, что вполне достаточно линейного поиска. По-видимому, это связано с тем, что на фоне относительно медленного доступа к диску, некоторые задержки, возникающие в процессе сканирования списка несущественны. Метод прост, но требует временных затрат. Для создания нового файла вначале нужно просканировать директорию на наличие такого же имени. Затем, имя нового файла вставляется в конец директории (если, разумеется, файл с таким же именем в директории не существует, в противном случае нужно информировать пользователя). Для удаления файла нужно также выполнить поиск его имени в списке и пометить запись как неиспользуемую. Реальный недостаток данного метода - линейный поиск файла. Информация о структуре директории используется часто, и плохая реализация будет замечена пользователями. Можно свести поиск к бинарному, если отсортировать список файлов. Однако это усложнит создание и удаление файлов, так как требуется перемещения большого объема информации. Хеш таблица Хеширование - другой способ, который может быть использован для размещения и последующего поиска имени файла в директории. В данном методе имена файлов также хранятся в каталоге в виде линейного списка, но дополнительно используются хеш таблица. Хеш таблица, точнее построенная на ее основе хеш-функция позволяет по имени файла получить указатель на имя файла в списке. Таким образом, можно существенно уменьшить время поиска. В результате хеширования могут возникать коллизии, то есть ситуации, когда функция хеширования, примененная к разным именам файлов, дает один и тот же результат. Обычно имена таких файлов объединяют в связные списки, предполагая в дальнейшем осуществление в них последовательного поиска нужного имени файла. Выбор хорошего алгоритма хеширования позволяет свести к минимуму число коллизий. Однако всегда есть вероятность неблагоприятного исхода, когда непропорционально большому числу имен файлов функция хеширования ставит в соответствие один и тот же результат. В этом случае преимущество использования этой схемы по сравнению с последовательным поиском практически утрачиваются. Другие методы поиска Помимо описанных методов поиска имени файла в директории существуют и другие. В качестве примера можно привести организацию поиска в каталогах файловой системы NTFS при помощи, так называемого B-дерева, которое стало стандартным способом организации индексов в системах баз данных.   Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|