
|
|
Схема шкал измерения по КумбсуОтношений
Интервальная
Упорядоченно-упорядоченная
Упорядоченно-частично Частично упорядоченно-
Упорядоченно- Частично упорядоченно- Номинально- номинальная частично упорядоченная упорядоченная
Частично упорядоченно- Номинально-частично номинальная упорядоченная
Номинально-номинальная
Главная проблема измерения состоит в том, чтобы показать, что данная эмпирическая область выявляет ту же самую структуру, как и некоторая арифметическая система числа, а если идентифицирована общая структура, то говорить, что арифметическая система изоморфна эмпирической области. После того, как изоморфизм установлен, вопросы в отношении эмпирической области могут быть отнесены к арифметической системе и к расчетам, произведенным в ней, а затем результаты переведены обратно и интерпретированы. П. Суппес и Дж. Зиннес дали определение этого изоморфизма, используя понятие системы с отношениями[104]. Следуя им, система с отношениями есть конечная последовательность <S; R1, …, Rn>, где S — не пустое множество элементов, называемое областью системы, а R1, R2, …, Rn суть отношения в S. Две системы с отношениями <S; R> и <T; Q> называются изоморфными, если существует функция f, одно-однозначно отображающая S в T, такая, что для всех x и y в S имеет место xRy, если и только если в T имеет место f(x)Qf(x). Если отображения не является необходимо одно-однозначным, то говорят, что системы гомоморфны или (T; Q) является гомоморфным отображением (S; R). Гомоморфные системы с отношениями используются Суппесом и Зиннесом в качестве основы для формального определения и классификации шкал измерения. Предположим, что U= (S; R) — эмпирическая система с отношениями, а U – гомоморфное отображение в систему V= (T; Q), в которой T — некоторое множество действительных чисел. В таком случае упорядоченная тройка (U, V, f) называется шкалой. Типы шкал получаются посредством преобразования g = φ (f) таким путем, что (U, V, f) является также шкалой. Кортеж (U, V, g) может быть: 1) шкалой отношений, если
2) интервальной шкалой, если
3) ординарной шкалой, если
4) номинальной шкалой, если Сейчас идет весьма плодотворная работа по определению строгой формально-логической характеристики шкал. В какой-то мере осуществляется синтез подходов Кемпбелла и Сти-
венса-Кумбса. В какой-то мере это реализуется в работе Суппеса и 3иннеса: они подразделяют измерения в социальных науках на первичные и производные, как это сделал Кемпбелл в отношении измерения в физических науках. Вместе с тем они развивают идею Стивенса о различии шкал измерений, как первичных, так и производных. Система с отношениями есть A = <A, R1, …, Rn>, где А область системы с отношениями, R1,..., Rn — отношения в А. Числовая система - система с отношениями <А, R1,..., Rn>, у которой область А есть подмножество действительных чисел. В случае, если А — все множество действительных чисел, то имеет место полная числовая система с отношениями. Эмпирическая система с отношениями - система, в которой областью являются эмпирические объекты. Пусть А - эмпирическая система с отношениями, R — полная числовая система с отношениями, f — функция, гомоморфно отображающая А в подсистему R, т.е. первичное числовое представление для эмпирической системы А. Шкалой называется упорядоченная тройка <А, R, f>. В зависимости от свойства f определяются свойства измерения. Первичные измерения на множестве A относятся к эмпирической системе A. И шкала <A, R, f> — первичная шкала измерения. Если B = <B, f1, …, fn> — производная система измерения, то тройка <В, R, g > —производная шкала, где R -представляющее отношение, g —производное числовое представление. Имеет широкое распространение точка зрения известного специалиста по теории измерения У. Торгерсоyа, который не относит номинальную шкалу к проблеме измерения, а рассматривает ее как просто реализацию классификации. С измерением он связывает процесс, для которого важны три элемента: порядок, начало отсчета и единица измерения. В зависимости от наличия или отсутствия этих элементов возникают те или новые шкалы измерения. Важно отметить, что порядок присущ, по Торгерсону, любому измерению[105]. Иногда переменные, представляющие измерения на одном уровне, трактуются как если бы они были измерены по другой шкале, что приводит или к потере информации, которой мы обладаем, или к оперированию с информацией, которой мы не обладаем. Так, величина роста человека – относительная пере-
менная, но при ранжировании людей по росту мы отказываемся от части информации и удовлетворяемся ординальной шкалой. С одной стороны, балл экзаменующегося представляет собой ординальную переменную, так как, например, мы не можем сказать, что умственные способности индивида, получившего балл, например 4, в два раза больше способности индивида, получившего балл 2, или что индивид, знания которого оценены баллом 5, настолько отличается от индивида с баллом 4, как индивид с баллом 4 — от индивида с баллом 3, т.е. балл не является ни интервальной, ни относительной переменной. Однако к баллам экзаменующихся применяются все операции математической статистики, т.е. рассматривают их как интервальную переменную. Все социологические и социально-психологические измерения пока проводятся по номинальной и ординальной шкале, т.е. все измерения сводятся лишь к классификации и упорядочению (ранжированию) социологических объектов, явлений и характеристик и делаются только робкие шаги в переходе к более развитым шкалам. Все социологические и социально-психологические измерения переменных типа «отношение к труду» пока проводятся по номинальной и ординарной шкале, т.е. все измерения сводятся лишь к классификации и упорядочению (ранжированию) социальных объектов, явлений и характеристик, и делаются только робкие попытки перехода к более развитым шкалам, главным образом в двух направлениях[106]: во-первых, выра6атываются и уточняются общие принципы теории социального измерения; во-вторых, развиваются н отрабатываются методы измерения в социологии. Некоторыми учеными была предпринята попытка дать сравнительный анализ понятий естественнонаучного и социологического измерения в том его понимании, какое мы встречаем у польских социологов, исходящих из концепции измерения, сформулированной известным польским логиком Айдукевичем. Оба эти подхода представляются как частные случаи некоторой общей теории. Наша цель состоит в том, чтобы показать, что теория измерений по Айдукевичу может быть сведена к теории измерения по Суппесу и 3иннесу, которая рассматривается, как более общая теоретическая концепция измерений[107].
Во втором круге работ по измерению также можно выделить несколько направлений. Прежде всего следует выделить работу по сравнительной оценке известных шкал измерения Терстона, Ликерта, Гуттмана[108]. Советскими учеными проводятся эксперименты по сравнению методов ранжирования. Рассматриваются оценки — средний ранг, средняя пятибалльная оценка и средняя позиция в номинальной шкале и с помощью различных статистических критериев выявляется наибольшая устойчивость среди этих четырех методов оценки[109]. Строятся шкалы на базе альтернативной постановки вопроса, которая приводит к определенной типологии ответов, и эти шкалы выражаются посредством агрегативных индексов[110]. Для оценки результатов шкалирования и проверки индексов на надежность (релиабильность) весьма успешно применяется так называемая информационная статистика[111]. Предпринята попытка, в какой-то мере близкая к закону сравнительного суждения Терстона, получить интервальную шкалу для качественных, упорядоченных, неаддитивных признаков при некоторых ограничениях на функцию распределения[112]. Заслуживают внимания исследования проблематики производного измерения-системы правил получения интегральной характеристики сложного качества на основании нескольких оценок компонент. Выделяют две стороны процесса — сложный признак (объект) и системы признаков – индикаторов, дающих информацию. Объекты (сложный признак) рассматриваются по ранжированным (градуцированным) группам в зависимости от степени связанности признаков-индикаторов — близости на главной диагонали матрицы сопряженности[113]. В настоящее время все большее внимание советских социологов привлекает латентно-структурный анализ Лазарсфельда[114]. В работах советских социологов можно обнаружить но-
вые моменты. Так, вместо решения расчетного уравнения Лазарсфельда предлагается осуществить классификацию посредством алгоритма распознавания образов[115]. Затем решается бейесова задача определения вероятностей отнесения к классу, которые могут служить основанием для определения расстояния между классами и тем самым для реализации шкалы. Большое число работ связано с решением задач измерения в связи с исследованием специфических социальных проблем – критериев оптимальности, измерения информативности, измерения социальных установок[116], оценки привлекательности профессии[117]. Но эти работы в сущности уже смыкаются с работами по применению математических методов при анализе первичной социальной информации и моделирования.
Глава вторая Основные понятия математической статистики И измерение связи
Фундаментальным понятием математической статистики является понятие группы, или совокупности, которое обычно определяется как генеральная совокупность. Генеральная совокупность — это совокупность, множество элементов, обладающих каким-то одним или многими признаками[118]. Признак является переменной величиной для каждого элемента генеральной совокупности и называется вариантой. Количественная варианта может быть прерывной (дискретной н непрерывной. Если дана генеральная совокупность N лиц, которые изучаются, например, по своему доходу, то в этом случае варианта (доход) является непрерывной величиной, которая может в определенных пределах принимать любые значения. Если же эти N лиц изучаются по их семейному положению, например, какова величина семьи, в которой живет данный индивид, то в этом случае варианта является величиной прерывной, поскольку она может принимать только целочисленные значения 1, 2, 3... и т.д. Рассмотрим случай прерывной варианты. Предположим, что дана генеральная совокупность объема N, каждый элемент которой характеризуется прерывной вариантой Х. Как можно охарактеризовать эту генеральную совокупность по данному признаку (варианте)?
Самый естественный и простой путь — сгруппировать члены генеральной совокупности по всем возможным значениям признака. Сначала группируем элементы генеральной совокупности, имеющие наименьшее значение варианты, а именно значение X1. Затем члены, имеющие значения X2, X3 … и т.д. Наконец, отбираем члены, имеющие наибольшее значение варианты — Xk. Количество членов генеральной совокупности в каждой группе, соответствующей определенному значению варианты, называется частотой варианты X и обозначается через ni.
В результате мы получаем два ряда чисел, которые можно расположить один под другим таким образом: X1 X2 … Xi … Xk nx n1 n2 … ni … nk Получилась таблица, которая дает частотное распределение варианты X в генеральной совокупности. Очевидно, что Иногда частотное распределение представляют графически: на оси X откладывают значение варианты, на оси Y — частоту. Полученные точки соединяют ломаной, которая называется полигоном распределения (рис. 1). Ломаную принято соединять с осью X в смежных точках оси X, в которых, полагают, частоты равны 0 (в данном случае в точках X0 и Xk+1). В том случае, если варианта – непрерывная величина, дело несколько усложняется: нельзя непосредственно сгруппировать элементы генеральной совокупности по значениям варианты, поскольку может оказаться, что каждый член имеет свое, отличное от других значение варианты. Тогда поступают следующим образом. Предположим, что все значения варианты находятся на отрезке [a, b]. Этот отрезок разбивают на n равных
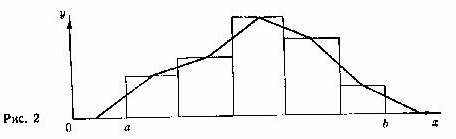
частей, которые называют разрядами, интервалами, классами или класс-интервалами. Отбирают члены генеральной совокупности, варианты которых попадают в первый класс-интервал, затем элементы, попавшие во второй класс-интервал, и т.д. вплоть до последнего n-ro класс-интервала. Число элементов генеральной совокупности, попавших в определенный класс-интервал, называется частотой этого класс-интервала. Очевидно, что класс-интервал определяется по формуле Dx= Выбор n зависит от многих причин и должен быть таким, чтобы класс-интервал был не очень малым (чтобы класс-интервалов было не слишком много) и не очень большим (чтобы не исчезла специфика изменения варианты). Существует ряд приближенных формул для определения не- обходимого Dх, а также ряд допущений в отношении значений варианты на границах класс-интервалов, за которыми мы отсылаем к соответствующей литературе[119]. Частотное распределение (в случае непрерывной варианты) будет иметь следующий вид: Класс-интервалы I II III… Частоты В класс-интервалы кроме первого и последнего включаются варианты по своему значению больше нижней грани и равные верхней грани или меньше ее и условно принимается, что члены генеральной совокупности, попавшие в данный класс-интер- вал, имеют одинаковую варианту, равную середине данного класс-интервала. Частотное распределение в случае непрерывной варианты также может быть изображено графически. На оси Х прямоугольной системы координат отмечаются точки а и b нижней и верхней грани изменения варианты. Определяется класс-интервал. На интервале (а, b) откладываются выбранные класс-интервалы. На каждом класс-интервале как на основании строится прямоугольник с высотой, пропорциональной частоте этого класс-интервала. Верхние основания всех построенных таким образом прямоугольников образуют некоторую ступенчатую линию, называемую гистограммой, ко-
торая и является графическим изображением данного частот- ного распределения (рис. 2). Если соединим середины верхних оснований прямоугольни- ков гистограммы, то получим полигон данного распределения. Тем самым генеральную совокупность непрерывной варианты можно представлять двумя видами графиков — полигоном и гистограммой, а прерывной варианты — только одним видом —
полигоном. Площадь всей гистограммы пропорциональна объе- му генеральной совокупности. Иногда вместо частоты применяют относительную частоту, равную отношению частоты к объему генеральной совокупности. Если мы исследуем данную генеральную совокупностЬ по варианте Х, то прежде всего мы получаем частотное распределение, которое может быть представлено в виде таблицы или графика. Полученное в процессе исследования частотное распределение называется эмпирическим распределе- нием. Возьмем эмпирический полигон какой-либо непрерывной варианты. При достаточно большом объеме генеральной совокупности N будем одновременно увеличивать число и, следовательно, одновременно уменьшать величину класс-интервалов. У полигона будет увеличиваться число все уменьшающихся звеньев, и если продолжать этот процесс до бесконечности, то в пределе полигон перейдет в некоторую гладкую кривую, которая называется кривой распределения. Каждый полигон эмпирического распределения является некоторым приближением определенной кривой распределения (рис. 3). Эта кривая распределения, являющаяся предельным случаем полигона данного эмпирического распределения, называется по установившейся терминологии функцией плотности распре- деления и обозначается f (х). Интеграл от нее по области
изменения варианты называется функцией распределения и обозначается
Иногда f(x) и F(x) называют дифференциальным и интегральным законами распределения соответственно. Возьмем какие-то эмпирические гистограмму и полигон и соответствующую им кривую распределения (рис. 4).
Гистограмма и полигон в пределе стремятся к кривой распределения f(x). По определению гистограммы, частота значений варианты Х равна площади прямоугольников, построенных на класс-интервалах. Частота события по частотному определению вероятности при бесконечном увеличении числа испытаний стремится к вероятности события[120]. Следовательно, для кривой распределения площадь под ней между значениями х, и х, это вероятность того, что варианта
примет значения между
Частотные распределения обычно характеризуются двумя типами параметров: I — параметры положения или средние; II — параметры или меры рассеивания. Наибольшее значение имеют три вида средних: средняя арифметическая, медиана и мода. Средняя арифметическая (М) для прерывной варианты reнеральной совокупности объема N определяется выражением
или
где k — яисло различных значений:варианты Х, а варианты. Для непрерывной варианты Х, изменяющейся в интервале {а, b} генеральной совокупности объема N,
где f(х) — функция плотности распределения. Иначе говоря, средняя арифметическая есть абсцисса центра тяжести площади фигуры, образованной кривой распределения и осью абсцисс. Медиана (Me) — это такое значение варианты, когда половина генеральной совокупности имеет значения меньше его, половина — больше. Геометрически медиана означает абсциссу прямой, которая делит пополам площадь под кривой распределения. Мода (Md) — значение варианты, соответствующее наибольшей частоте (вероятности). Графически мода — это значение абсциссы самой высокой точки кривой распределения (рис. 5). Для симметричного распределения средняя арифметическая медиана и мода совпадают.
В качестве меры рассеивания наиболее распространены понятия дисперсии и квадратного корня из дисперсии, который называется стандартом или средним квадратическим отклонением. Дисперсия есть средний квадрат отклонения варианты от ее среднего арифметического; она обозначается
стандарт
На рис.6 кривая I характеризуется малой дисперсией; кривая II — большой дисперсией.
Наибольшее значение для социологических исследований имеют три теоретических закона распределения. 1) Нормальное распределение, или распределение Гаусса (для непрерывной варианты):
2) Биноминальное распределение, или распределение Бернулли (для прерывной варианты). Если при каждом испытании вероятность осуществления события есть р, неосуществления — q=1 — р, то вероятность того, что при и испытаниях это событие осуществится т раз, равна
3) Распределение Пуассона, или закон малых чисел, представляет собой предельный случай биноминального распределения: когда
Это распределение имеет место в случае большого числа испытаний маловероятных событий.
Статистический вывод
Статистика имеет дело с большим числом предметов и явлений, которые образуют генеральную совокупность. Однако исследователь обычно имеет дело с ограниченной частью генеральной совокупности, называемой выборочной совокупностью, или просто выборкой, по изучению которой он делает определенные выводы о генеральной совокупности[122]. Каковы же математические основания этих выводов? Если F (х) — интегральная функция распределения генеральной совокупности, определяющая вероятность того, что х<Х, и если
Характеристики распределения генеральной совокупности принято называть параметрами Статистическую выборку можно производить многократно, используя множество способов, и всякий раз будут получаться новые значения оценок параметров.
Следовательно, каждый параметр имеет выборочное распределение оценок. В этой связи вводится понятие точности оценки
и надежности (или доверительной вероятности) у как вероятности того, что При исследовании генеральной совокупности, подчиняющейся нормальному закону, находят оценки параметров а и Результат, полученный в выборке (обычно это среднеарифметическое или дисперсия), еще мало о чем говорит. Необходимо определить точность ( Точность оценки рассчитывается при определенных предположениях о распределении в генеральной совокупности. Может случиться, что генеральная совокупность отклоняется от предполагаемого теоретического распределения и, следовательно, расхождение эмпирического и теоретического распределения обусловлено не случайностью выборки, а тем, что данная генеральная совокупность характеризуется другим теоретическим распределением. Всякое предположение о распределении генеральной совокупности называется статистической гипотезой. Встает проблема проверки статистической гипотезы. Гипотеза может касаться общего вопроса соответствия выборочного эмпирического и теоретического распределения. Она может относиться и к сопоставлению тех или иных параметров, например средних или дисперсий. Обычно, следуя идее Дж.Неймана и Э.Пирсона, принимается начальная, или нулевая, гипотеза об отсутствии различия, которая обозначается В каждом отдельном случае определяется характеристика (критерий), по которой идет проверка. Если проверяется какой- либо параметр, а выборочное распределение его при данной гипотезе хорошо известно, то устанавливается предел вероятности, или уровень значимости. Значения характеристики, вероятности которых меньше уровня значимости, образуют так называемую критическую область, а значения, вероятности которых больше уровня значимости — область допустимых значений. Пусть дано выборочное распределение некоторой характеристики и (рис. 7). Возможны два типа ошибок — так называемые ошибки первого и второго рода. Ошибка первого рода состоит в отбрасыва-
нии нулевой гипотезы Уровень значимости При проверке гипотез приходится находить разумное соотношение уровня значимости и мощности критерия. Нельзя сделать
как угодно малыми одновременно и Кривая А связана с гипотезой Площадь справа от Значение
Если уменьшать Когда нулевая гипотеза неверна, то тем самым верна какая-то другая, альтернативная гипотеза 1) критерий отвергает 2) критерий отвергает 3) критерий допускает 4) критерий допускает Во втором и третьем случаях проверка гипотезы приводит к правильному выводу. Первый случай обусловливает ошибку первого рода, четвертый случай — второго рода. Площадь слева от Таковы некоторые положения о статистическом выводе. Использование математического аппарата статистического вывода имеет исключительно большое значение для социологии, так как, во-первых, социолог практически может проанализировать всю генеральную совокупность, а во-вторых, элементы генеральной совокупности в социологии гораздо более сложны и специфичны, чем в других областях науки. Если ставится задача установить по выборке закон распределения, то используется так называемый критерий
Измерение связи
Из школьного курса математики известно понятие функциональной связи, когда каждому значению независимой перемен- ной (аргумента х) ставится определенное значение зависимой переменной (функции у):
Функция может быть однозначной и многозначной. Так, дли- на окружности есть однозначная функция радиуса: 1=2
ратный корень из действительного числа — двузначная функция этого числа: у= На графике, в случае однозначной функции, каждой паре значений х и у соответствует точка плоскости. Множество этих точек на плоскости представляет собой графическое изображение функциональной связи, или график функции у=1(х). Однако в природе существуют не только функциональные связи такого рода. Рассмотрим обычную игру в карты. При сдаче игрок получает некоторое множество карт. При следующей — другое множество карт и т.д. При каждой сдаче получается новая комбинация. Налицо — связь между сдачей и комбинацией карт игрока. В этом случае с изменением одной переменной происходит изменение распределения другой переменной. Связь этих переменных называется статистической. Если оказывается, что с изменением одной переменной изменяется среднее значение другой, то говорят, что между этими переменными существует корреляционная связь. Например, требуется определить зависимость между ростом жены и мужа. Для примера рассмотрим 100 супружеских пар. На плоскости дана прямоугольная система координат, по оси х откладывается рост мужа, по оси у — рост жены. Точкой на плоскости отмечается каждая супружеская пара. Полученное графическое изображение называется корреляционным полем (рис. 9).
В нашем случае должно быть 100 точек, которые как-то заполняют плоскость этого корреляционного поля. Для каждого класс-интервала х отбираем все соответствующие ему точки. Находим их среднее значение
роста мужа от одного класс-интервала к другому. Эта линия называется эмпирической линией регрессии. Если рассмотреть 100 других пар, то получится несколько иная эмпирическая линия регрессии. Если уменьшить величину класс-интервала, то линия покажет увеличение числа звеньев, сохранив в целом контур. Можно убедиться, что все эмпирические линии регрессии каких-либо двух переменных всегда лежат около некоторой плавной линии, называемой теоретической линией регрессии, или просто линией регрессии[126]. Ее уравнение называется уравнением регрессии. Если мы рассматриваем изменение среднего у от х, то получится уравнение регрессии у на х:
Если рассматриваем изменение среднего
При
Как найти коэффициенты уравнений регрессии? Предположим, что дано и объектов, характеризующихся двумя переменными: Линия ACDF — эмпирическая линия регрессии Коэффициенты теоретической линии регрессии находят по методу наименьших квадратов: ищут эту линию при том условии, чтобы сумма квадратов расстояний эмпирической линии регрессии   Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|






 где
где  >0;
>0; , где β>0;
, где β>0; - монотонная функция;
- монотонная функция;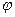 — перестановка.
— перестановка.
 .
.
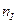

 …
…



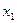 и
и  [121]. Это можно записать таким образом:
[121]. Это можно записать таким образом: .
.

 — значения
— значения
 .
.


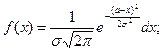
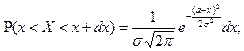

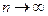 , a
, a  , то, обозначая np=a, имеем
, то, обозначая np=a, имеем

 (х) — эмпирическая функция распределения выборки, то по теореме Бернулли при бесконечном увеличении объема выборки эмпирическое распределение по вероятности стремится к распределению теоретическому:
(х) — эмпирическая функция распределения выборки, то по теореме Бернулли при бесконечном увеличении объема выборки эмпирическое распределение по вероятности стремится к распределению теоретическому: .
. , а характеристики выборочного распределения — оценками параметров
, а характеристики выборочного распределения — оценками параметров  .
.
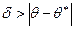
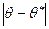 <
<  , а именно
, а именно 
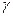 ) этой оценки. Без этого результат выборки не имеет смысла, поскольку оценка пара- метра является случайной величиной.
) этой оценки. Без этого результат выборки не имеет смысла, поскольку оценка пара- метра является случайной величиной. [123].
[123]. . С уменьшением
. С уменьшением 
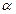 , и
, и  . Здесь следует учитывать сложившуюся ситуацию. Это можно представить графически (рис. 8).
. Здесь следует учитывать сложившуюся ситуацию. Это можно представить графически (рис. 8). ;
;  — значение критерия, соответствующее уровню значимости
— значение критерия, соответствующее уровню значимости  соответствует генеральной характеристике. Точка
соответствует генеральной характеристике. Точка  оказывается меньше уровня значимости
оказывается меньше уровня значимости  . Возможны такие случаи:
. Возможны такие случаи: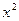 . При сравнении двух выборочных средних используется t-критерий, при сравнении двух выборочных дисперсий — F-критерий[125].
. При сравнении двух выборочных средних используется t-критерий, при сравнении двух выборочных дисперсий — F-критерий[125].
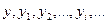
 . Квад-
. Квад-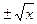 . Обратные тригонометрические функции угла дают простейший пример многозначных функций.
. Обратные тригонометрические функции угла дают простейший пример многозначных функций.
 . Эту точку наносим на график, обозначая ее крестиком, чтобы выделить среди прочих. Соединяем ломаной все отмеченные крестиком точки. Полученная линия показывает изменение среднего значения роста жены с изменением
. Эту точку наносим на график, обозначая ее крестиком, чтобы выделить среди прочих. Соединяем ломаной все отмеченные крестиком точки. Полученная линия показывает изменение среднего значения роста жены с изменением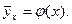
 от
от  , то уравнение регрессии
, то уравнение регрессии  на
на 
 говорят о линейной регрессии
говорят о линейной регрессии  . Аналогично можно ввести уравнение регрессии х на у:
. Аналогично можно ввести уравнение регрессии х на у: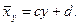
 и
и  . Для простоты полагаем, что средние
. Для простоты полагаем, что средние  .
. , коэффициенты котороro
, коэффициенты котороro  и
и 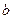 неизвестны и их надо найти.
неизвестны и их надо найти.