
|
|
Структура задач процесса моделированияСтр 1 из 27Следующая ⇒ Системный анализ и проект Конспект - черновой (лекторский) вариант, в некоторых разделах носит характер иллюстративной поддержки Существуют две очень близкие то чки зрения на то, что есть СА – Первая - это механизм раскрытия неопределенностей и формализации решения любой проблемы – эта точка зрения работает, как источник новых научных направлений, выросших из системного анализа - таких как "Исследование операций", "Теория графов", "Сеттевое планирование" и прочее, прочее, прочее. Вторая – это более общий вгляд, обобщение проблемы (задачи) моделирования. Как следствие - понадобилась формализация этого более общего вгляда на моделирование – как на процесс исследования объекта и всех связанных с этим исследованием идей, проблем, вопросов, - что-бы 1.- структурировать последовательность решения задач при моделировании 2.-выделить общие механизмы в различных задачах моделирования и 3.- разработать специальные подходы в особо интересных для практики задачах Результат структуризации вопросов связанных с моделированием может быть представлен, как упорядоченный перечень задач, процедур которые стоят между неформальной постановкой проблемы и окончательным математическим ее решением. Сказанное можно итожить в виде таблицы задач, связанных с моделированием, таким образом: Структура задач процесса моделирования наиб просто - это задачи Анализа - и - Синтеза: Анализ-Синтез = = Декомпозиция Объекта - ПричинноСледственный Анализ - Синтез Модели - Анализ Модели таблица 1
Содержание каждого раздела таблицы мы рассм позже - сейчас общая х-ка 1-вый раздел - это вопросы декомпозиции (умозрительного расчленения) анализа и исследования объекта и его струкуры непосредственно имея дело с объектом и в результате чего мы должны получить 1. - моделеобразующие гипотезы об объекте и приближенное укрупненное представление о его структуре 2. - определится с структурными кирпичиками изучаемой системы (переменные состояния, управления,если оно имеется, шумами в системе) 3. Получить возможные характеристики и наборы экспериментальных данных которые мы в дисциплине "Статистическое моделирование" считаем заранее предоставленными в виде таблиц или матриц ОБЪЕКТ-СВОЙСТВА. Однако после решения задач 1-го раздела еще невозможно приступать к собственно моделированию. Мы об этом говорили ранее, когда отмечали недостатки методологии статистического моделирования, которое моделирует лишь исходя из факта силы связи но никак не анализирует направления связи между предполагаемыми входными и выходными переменными. Предварительный причинно-следстенный анализ даст ответ какие переменные имеют право оказатся в правых частях моделируемых соотношений типа у=f(x) Итак 2-й раздел посвящен решению вопросов ПСА - методам определения направления ПСС - составление матриц ПСС и сравнение их в классах МОДЕЛИРОВАНИЕ Современное моделирование (в том числе аналитическое) принято отслеживать от группы ученых связанных с Ньютоном, создавшего теорию бесконечно малых – Теорию Диференциального и Интегрального исчисления. Это удивительное прозрение практически впервые породило аналит ические математические модели в точности соотв-щие реальным физическим процессам. Он выдвинул гениальную по простоте и адекватности идею что значительное количество физических моделей макромира увязывают в своих взаимоотношениях линейные перемещения с их скоростями,ускорениями и тд и создал строгий аппарат обращения с данными величинами и уравнениями связвывающими эти величины. С помощью этого аппарата была решена грандиозная задача - задача моделирования движения тел небесной механики. Паралельно эта задача породила к жизни сопутствующие направления исследований - теорию вероятности (ЛАГРАНЖ, МУАВР, БАЙЕС). Конечно ТВ имеет свои родные корни, связанные с изучением случайности, но вычислительные, практические аспекты ТВ стимулировала родственная «небесной механике» задачка из теории измерений. Именно ниже указанная задача стала первой сформулированной задачей статистического моделирования. Надо было наиболее точно определить начальные условия для реш задачи Неб Мех – то есть определить наиболее точное положение звезд на небосклоне по неоднократным их измерениям.. Таким образом в 1800-тых годах - Лаплас, Гаусс и Лежандр, каждый из которых в то время работал над теорией движения небесных тел и не мог обойти проблемы теории измерений предложили свои варианты решения такой задачи. Сначала о Лапласе. Лапласомбыло предложено оценивать неизвестное значение измеряемой величины Оказалось, что такое значение Позже, было показано что задача минимизации суммы модулей отклонений решаеться линейным программированием. О ЛП? Но в то время ученому сообществу более простой и технологичной показалась идея двух других французов – Гаусса и Лежандра которые для тех же условий задачи предложили минимизировать ф-нал
и предложили технологию Метода Наименьших Квадратов которую мы в общих чертах уже представляем. Ниже немного обобщим взгляд на эту технологию моделирования
Напомним, что нам известно Любая задача моделированмя по экспериментальным данным начинается с данных – таблицы результатов эксперимента или таблицы наблюдений –
Итак, матрица данных имеет m столбцов и n строк, соответственно геометрическую интерпретацию регресии можно получить в пространстве столбцов или в пространстве строк = или что то же самое в пространстве переменных (оси –переменные) или в пространстве точек. (оси - номера точек)
Свойство проективности МНК (вывод осн ф-ла МНК, используя теперь свойство проективности) 1. Напомним, что применяя МНК для регресии мы оцениваем параметры регресии Здесь Напомним что дальнейшие результаты будут такие же, если мы вместо (1) будем рассматривать модель более общую модель Результаты будут верны с точностью до переобозначения. Поэтому, рассуждая в дальнейшем об (1) что формально проще, имеем далее в виду и (2) то есть модель нелинейную по аргументам регрессии. 2. Описывая данные задачи регрессии в виде таблиц естественно и выводить основные результаты в матричном виде (что бы не выделять отдельно своб член - ниже для упрощения записи - вектор Коротко о проблемах СПС Мы уже знаем что подход в лоб - с критерием " максимум точности" модели для задачи структурно параметрического синтеза в условиях 1 шумов в данных и 2. значимой корреляции между входными переменными не корректен - почему?
1- модель с нулевой ошибкой может оказатся абсолютно непригодной на свежих данных (переобученная модель) ..... пример ракета-волки
2.- вопрос а с какой же ошибкой считать модель оптимальной в алгоритмах ШМР например решается с помощью заданием оператором вероятностей ошибок первого Это вероятности Но какие значения
3.- модель с сильно коррелированными (близкими к коллинеарности) аргументами может оказатся крайне неустойчивой к смене (даже однородных) обучающих выборок, при этом замена даже 1 точки или 1признака может дать существенную дисперсию оценки параметров модели.
4.- Кроме того проблемы плохой обусловленности ХтХ часто не позволяют в принципе получать решение задачи в лоб как у= (ХтХ)-1ХтУ
Поэтому был предложен ряд методов который в оговоренных выше тех или иных условиях позволяет получать наилучшие в некотором смысле модели. Эти методы объединены названием (так введено основателями теор самоорганизации) " Индуктивное моделирование" а вот подтверждение насколько тот или иной метод лучше более или менее может быть подтвержден (до испытаний на новых объектных данных) только модельным экспериментом который восстанавливает насколько это возможно условия формирования экспериментальных данных и проверяет насколько точно проверяемый подход открывает преполагаемую структуру и параметры модели. Кратко по сути модельного эксперимента чуть позже далее
К1------ ------- К ---------- ==== Л Критерий Маллоуза Критерий Маллоуза оказываеся дает при этом несмещенную оценку ошибки прогнозирования , Но надо знать дисп шума 2. Пусть известно распределение шума Когда известно распределение шума Для нахождения параметров Тогда для поиска оптимальной структуры
где В частном случае нормального шума он принимает вид критерия Маллоуза. При этом на практике он применяется в упрощенном виде
Этот вариант формулы называют критерием Акаике-Маллоуза Данный критерий существенно ограничивает рост сложности модели наличием аддитивного члена 2s. Однако проблема применения состоит в том, что в практических задачах функция распределения шума да часто и его дисперсия неизвестны. А что тогда делать? Используют тогда менее обоснованные но практически неплохо работающие критерии 3. Байесовский информационный критерий (критерий Шварца):
4. Также популярен критерий финальной ошибки предсказания Акаике применяемый при неизвестном характере шума и корректирующий остаточную сумму квадратов ошибки
Критерии с использованием штрафа за сложность в неявном виде и с порождением новых выборок 1. Бутстреп – предполагается что раз данные n точек появились у нас в віборке то у них равная вероятность появления в віборке - отсюда алгоритм получения подобных выборок -имитационное моделирование исходной выборки с помощью равномерного распределения - ключевой момент если некоторая точка реализовалась она возвращается в множество генерации (т.о. получаем выборки размером n с возможным количеством повторения некоторых точек) 2. Критерий "скользящего контроля", "усредненный критерий регулярности", или "джекнайф"-складной нож: Используется при крайне малом количестве точек (когда точек просто маловато используют разбиения выборки по МГУА -- ниже)
Комментарий к материалу Поскольку во всех методах есть какие-то проблемы - (хотя с моей точки зрения алгоритмы МГУА наиболее совершенны и технологичны в настоящее время), то если бы рядом со мной стоял «старый зубр» - статистик (например Цейтлин Натан Абрамович автор книги “из опыта аналитического статистика”) он сумел бы доказывать что и Акаике и МГУА не совершенны, а в рамках АШР он, Цейтлин сможет получать модели не хуже чем мы по МГУА Ну что же. В этом он наверное прав. Но для этого надо быть Цейтлиным, и иметь многолетний опыт практической работы статистика, чтобы преодолевать проблему множественности моделей с помощью своего многолетнего опыта. Для других практиков, не такого высокопрофессионального уровня, то методология МГУА и рекомедации, которые мы рассмотрели выше позволят вам решать сложные практические задачи моделирования не хуже Цейтлина. Подведем промежуточные итоги: Покажем это Итак, по формулировке 1. – имеем
Предположим обратное, что для некоторого Тогда И при этом по определению не является истинным аргументом. Когда такое возможно? – либо это случайность (генератор так случайно сгенерировал для них Поскольку выбор в претенденты на участие в модели происходит в шаговых алгоритмах по величине ---------------------- Вот во всех остальных случаях, у классических шаговых алгоритмах начинаются сложности. Если 1. поданные на вход переменные (истинные и фиктивние) независимы а 2. данные точные без шума и 3. при этом количество наблюдений то с такой задачей открытия истинной модели могут справится классические шаговые и другие неклассические методы индуктивного моделирования. Покажем это.
Ситуация 3 3.П роблема шума в данных Итак, все дело в шуме, который обязательно присутствует в любых данных и даже минимальные уровень которого, деформирует исходные корреляционные отношения так, что из полного полинома невозможно увидеть истинную структуру. Теперь оценки параметров при фиктивных, но коррелированных с выходом аргументах, уже точно не будут нулевыми, а значимыми или незначимыми они будут и, насколько значимыми, оценить заранее невозможно. И даже при полном отсутствии шума в данных, шум все равно в расчетах присутствует, и, чем выше корреляция аргументов, тем хуже обусловленность матрицы (детерминант системы ближе к нулю) аргументов и тем выше уровень вычислительного шума. Поэтому никто мало кто (напрямую) при коррелированных аргументах не оценивает параметры полного полинома.
Более подробно. И так, коррелированность обуславливает 1. близость к нулю главного дискриминанта матрицы аргументов – чем выше коррелированность аргументов, тем ближе дискриминант к нулю, тем выше погрешность вычислений. Однако, проблема коррелированности аргументов в присутствии шума имеет еще одну важную особенность: 2. роль самого шума в искажении оценок параметров многократно возрастает. Оценки становятся и несостоятельными и смещенными и неэффективными. И, чем выше коррелированность, тем сильнее эффект искажения. Покажем это, используя геометрическую интерпретацию получения МНК оценок параметров модели Интерпретацию покажем в пространстве точек (см рис.1). Очевидно, что если коррелированность аргументов возрастает, то уменьшается угол между векторами х 1 и х 2,. При малом угле (рис.2) даже совершенно ничтожный шум в данных влияет через коррелированность, как через увеличительное стекло, на смещение положение плоскости аргументов. И, чем меньше угол между векторами, которые определяют плоскость тем легче шум вращает плоскость аргументов.
Рис1 Рис 2 Рис 3 Рис 4
Рис 3 показывает случай коллинеарности векторов х 1, х 2, что позволяет плоскости вертеться на оси векторов и принимать любое положение. Соответственно и проекции (модели) в эти сдвинутые плоскости будут как угодно разные. Именно поэтому, наиболее предпочтительный вариант проекции в плоскость, это в плоскость, определенную ортогональными (независимыми), а еще лучше ортонормированными векторами –рис.4.
Здесь важно понять, что как только мы определились (выбрали), какими исходными векторами (х 1, х 2) определена плоскость, куда будем опускать проекцию – все, модель по сути, уже зафиксирована. Это будет проекция в эту плоскость. И все выше сказанное относится только к тому, как перезадать эту плоскость так, чтобы А) вычислительный шум минимально повлиял на процесс определения проекции – надо перезадать плоскость ортогональными векторами и Б) минимизировать сам вычислительный шум нормировав вектора аргументов См рис 4 Кстати, именно поэтому, шум совсем не так страшен при оценке параметров, когда аргументы независимы – ортогональны: плоскость аргументов при этом максимально устойчива (к вращению шумом) и еще менее страшен, если он ортогонален к Х-ам и у,(тогда в случае ортогональности к выходу у он не войдет в модель, потому что корреляция его А устойчивость плоскости – определяет точность полученной проекции (нашей модели) в этой плоскости.
Отдельно проблема коллинеарности может оцениваться близостью главного детерминанта матрицы аргументов к нулю. Совместное влияние коллинеарности и разброса длин векторов аргументов отражающееся на погрешности вычисления оценок характеризуется понятием обусловленности матрицы аргументов. Степень обусловленности снизу оценивается т.н. числом обусловленности матрицы равным отношению максимального и минимального собственных собственных чисел матрицы аргументов. Чем данное отношение больше тем хуже степень обусловленности Вопрос – ведь данные уже с шумом, значит, уже плоскость определена на неистинных коррелированных аргументах и это уже плохо. И если теперь ортогонализировать вектора – то вроде как «поздно пить боржоми». Но модель полученная на ортогональных векторах будет лучшая с точки зрения того что 1. когда новые вектора приходят и мы их подставляем в модель – выражение модели их преобразует так, как будто мы посчитали модель на независимых некоррелированных векторах, т.о. минимизируя эффект вращения плоскости, на которой мы посчитали значение модели (проекции) 2. Минимизирует нормировкой одну из причин вычислительного шума (а если максимум на которой делим при нормировании меньше 1?).
Итак, для коррелированных аргументов при небольших М (10-20) и Р (2-3) возможно решать задачу структурно параметрического синтеза через полное описание, ортонормируя его в обобщенных аргументах (скажем обобщенные аргументы для МНК формируются как ортогональные полиномы Форсайта).
Но при реальных размерностях практических задач мы опять вынуждены возвращаться к алгоритмам шаговой регрессии, где должна быть предусмотрена ортогонализация и нормировка аргументов при расчете их оценок по МНК (алгоритмы с ортогонализацией Грамма – Шмидта..).
Справка Схема МГУА В наиболее общем виде алгоритм МГУА нашел свое отражение в следующей обобщенной схеме:

  1 2 …. K 1 2 …. K


Рис. Общая схема алгоритма МГУА Схему проиллюстрируем для варианта МГУА на основе внешнего критерия – критерия регулярностиГ– блок: генератор частных описаний (моделей претендентов) Базовое утверждение МГУА Введение к схеме алгоритма Алгоритм относится к т.н. разновидности итерационных алгоритмов с вложенными структурами. Действительно, для произвольного ряда с номером «s» выражения для частных моделей (описаний)
где При заданнх критериях качества СКОА и НОСКОВ согласно которым порождается модель, генератор структур (1*) обеспечивает процесс, сходящийся на обучающей последовательности (куда, пока не понятно, но сходящийся), так как в худшем случае при
Входными данными алгоритма есть входные Рассматривается выборка из Подготовительный этап
от переменных исходного входного множества Т:
Далее При формировании частных моделей
На произвольном Обычный путь расчета модели
Уменьшим размерность векора искомых параметров. Напомним что размерность вектора параметров – это по сути размерность системы нормальных уравнений или что то же (напомним материал регрессионного анализа) - размерность матрицы Для такой постановки разработтан весь известный нам аппар   ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 Анализ Объекта - Синтез Модели - Анализ Модели =
Анализ Объекта - Синтез Модели - Анализ Модели =  ,
,  во всех парах доступных переменных (процессах)
во всех парах доступных переменных (процессах) 
 . дающим возможность приступить к задачам непосредственно моделирования (3-ий столбец-раздел задач). Кроме того мы рассмотрим и применение ПСА непосредственно к решению некоторых задач моделирования и классификации (мед диагностики)
. дающим возможность приступить к задачам непосредственно моделирования (3-ий столбец-раздел задач). Кроме того мы рассмотрим и применение ПСА непосредственно к решению некоторых задач моделирования и классификации (мед диагностики) по его повторным измерениям
по его повторным измерениям 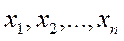 как такую величину
как такую величину  , которая обеспечивает минимум ф-лу
, которая обеспечивает минимум ф-лу 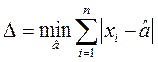 (*)
(*) соответствует нахождению выборочной эмпирической медианы -то есть такому числу
соответствует нахождению выборочной эмпирической медианы -то есть такому числу 
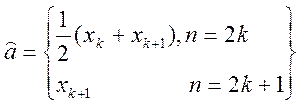 , справа и слева от которого находится одинаковое количество измерений.
, справа и слева от которого находится одинаковое количество измерений. (**)
(**)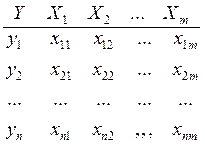 здесь m = кол.перем., n -кол точек данных
здесь m = кол.перем., n -кол точек данных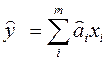 (1)
(1)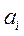 с точки зрения минимизации функционала
с точки зрения минимизации функционала  :
: 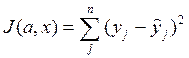 =
= 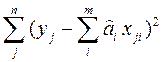 (1*)
(1*) и
и 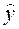 наблюдаемые и модельные значения соответственно.
наблюдаемые и модельные значения соответственно.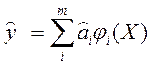 (2) и ф-нал
(2) и ф-нал 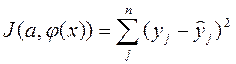 =
= 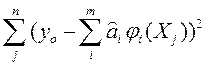 (2*)
(2*)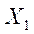 - ед.вектор) поэтому введем обозначения:
- ед.вектор) поэтому введем обозначения: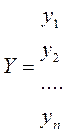 матрица
матрица 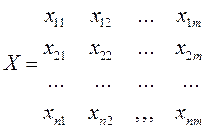 и вектор
и вектор 
 и второго рода -
и второго рода - 
 где RSS – квадрат нормы невязки у,
где RSS – квадрат нормы невязки у,  - дисперсия шума,
- дисперсия шума, 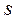 - сложность модели (для лин модели -количество расч параметров).
- сложность модели (для лин модели -количество расч параметров).
 предполагаетсяч использование метода наибольшего правдоподобия. Как известно, для этого надо найти такие
предполагаетсяч использование метода наибольшего правдоподобия. Как известно, для этого надо найти такие  при каждом варианте структуры
при каждом варианте структуры  .
.
 - максимизированное значение функции правдоподобия модели.
- максимизированное значение функции правдоподобия модели.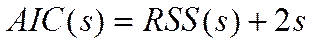



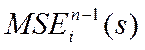 - значение критерия MSEi при синтезе модели на n-1 точке - то есть при выброшеной из выборки i- той точке при данном s. Когда s определено - считаем параметры на полной выборке.
- значение критерия MSEi при синтезе модели на n-1 точке - то есть при выброшеной из выборки i- той точке при данном s. Когда s определено - считаем параметры на полной выборке. для всех
для всех  в силу их независимости и
в силу их независимости и для всех
для всех  истинных (по определению, истинный аргумент имеет связь с выходом)
истинных (по определению, истинный аргумент имеет связь с выходом)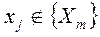 выполняется
выполняется 
 связан с выходом
связан с выходом 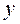 .
. количества претендентов на аргументы в модель
количества претендентов на аргументы в модель при аргументах х 1 и х 2, как коэффициентов проекции исходного вектора
при аргументах х 1 и х 2, как коэффициентов проекции исходного вектора  в плоскость х 1, х 2.
в плоскость х 1, х 2.


 равна нулю с выходной переменной.
равна нулю с выходной переменной.





















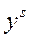 выглядят как вложенные матрешки:
выглядят как вложенные матрешки: (1*)
(1*) - лучшая модель «s-1» ряда селекции
- лучшая модель «s-1» ряда селекции  - некоторый новый аргумент,
- некоторый новый аргумент,  - параметр, который ищем по МНК.
- параметр, который ищем по МНК. =0 то
=0 то и алгоритм дает решение в точке стабилизации. - ухудшатся решение не может.
и алгоритм дает решение в точке стабилизации. - ухудшатся решение не может. О писание алгоритма
О писание алгоритма
 и выходная
и выходная  переменные, представленные матрицей данных
переменные, представленные матрицей данных  и вектором выхода
и вектором выхода  , здесь -
, здесь -  точек - это множество W, разделеное на обучающую A и проверочнyю (тестовую) B последовательности данных.
точек - это множество W, разделеное на обучающую A и проверочнyю (тестовую) B последовательности данных.
 формируются –
формируются –  ,
,  ,
, 
 входных переменных для алгоритма, будем иметь суммарное множество переменных:
входных переменных для алгоритма, будем иметь суммарное множество переменных: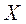 :
: 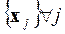 ,
,  и их функций
и их функций  :
:  ,
,  . Т.о
. Т.о 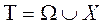
 как множество произведений
как множество произведений нулевого, первого второго, и др. порядков
нулевого, первого второго, и др. порядков или иначе
или иначе 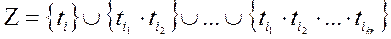 .
. последовательно вводят в модель ортогонализованный вариант
последовательно вводят в модель ортогонализованный вариант  обобщенных переменных
обобщенных переменных  , взятых из множества
, взятых из множества  в слагаемом модели
в слагаемом модели  , количество элементов (мощность) данного множества
, количество элементов (мощность) данного множества  -том этапе (ряду) алгоритма для каждого из F лучших описаний предыдущего этапа генеруеться моделей претендентов.
-том этапе (ряду) алгоритма для каждого из F лучших описаний предыдущего этапа генеруеться моделей претендентов. по двум агументам (
по двум агументам ( ) –нужно расчитывать три параметра:
) –нужно расчитывать три параметра: (2*)
(2*) (только у нас тут переменные
(только у нас тут переменные  . Для уменьшения размерности уравнения (2*) эквивалентно сводится к уравнению типа (1*).
. Для уменьшения размерности уравнения (2*) эквивалентно сводится к уравнению типа (1*).