
|
|
Тема 3. Многомерная выборка.
В отличие от одномерных методов отбора, теория и практика многомерной выборки находится в начальной стадии разработки. Вопросы множественного расслоения, глубокого расслоения, отбора по решетке исследуются в зарубежной экономической литературе, начиная с 50-80-х годов прошлого века (Р. Джессен, У. Кокрен, Г. Махаланобис, Паттерсон, Далениус). В 1990-ые годы появляются работы по многомерной выборке (Т. Чернышева, С. Степанов, Н. Бокун). Предлагаются разные способы многомерного отбора, т.е. отбора единиц из генеральной совокупности по группе атрибутивных и количественных признаков, отличающиеся методом построения основы выборки, формой реализации принципа многомерности, способом построения многомерного показателя. В зависимости от характера учета многомерности их можно объединить в три агрегированных группы: 1. Расслоение в независимых признаках; 2. Расслоение по композитному признаку; 3. Комбинированные методы. Расслоение в независимых признаках. Признаки единицы наблюдения считаются абсолютно независимыми, расслоение по каждому из них проводится независимо, конечные слои определяются с учетом всех полученных независимых границ. Данный подход порождает большие количества конечных слоев слабой заполненности. При желании отразить в количестве слоев по размерности известные данные о структуре объекта исследователь сталкивается с проблемой ограничения объема выборки. Количество слоев, превышающее 7-8, фактически не дает эффекта сокращения ошибки, достигнув точки насыщения. Для оптимизации многомерного расслоения и получения представительных выборок по системе независимых показателей целесообразно использовать методы типизации, оптимизации и комбинаторного анализа, что реализуется при отборе из типизированных основ выборки. При этом типизация включает стратификацию единиц отбора по ряду признаков, классификацию территориальных единиц и выделение количественно однородных структурных частей изучаемой совокупности. Методы оптимизации используются при отборе объектов наблюдения и размещении объема выборки, в процессе которого: а) требуется представить все выделенные структурные части; б) обеспечить достаточность числа отобранных единиц для получения результатов в пределах заданной точности как в целом по совокупности, так и по отдельным областям изучения. Методы комбинаторного анализа применяются для выделения типичных непересекающихся объектов и поиска оптимального варианта выборки. Составление типизированных основ предполагает формирование одной или нескольких комбинационных таблиц, позволяющих получить упорядоченное размещение номеров единиц наблюдения по совокупности образованных малых комбинационных блоков (графоклеток), отражающих структурные соотношения показателей и их призначной части. При построении выборочной совокупности учитывается число образованных блоков, заданная доля отбора, число групп по каждому из анализируемых признаков. Можно использовать: простой случайный отбор без возвращения, механический отбор, гнездовую, многоступенчатую выборку. Отбор из двумерной или множественной основы выборки (Джессен Р., Кокрен У., Махаланобис Г. И.) применяется при наличии двух и более основ выборки (домохозяйства и кварталы города; фермерские хозяйства на определенной территории, справочник отраслей (видов деятельности) и предприятий). Предполагается организация исследуемой совокупности в две и более основы, причем каждый элемент данной совокупности связан хотя бы с одной единицей в каждой из возможных основ выборки. Отбор по решетке (Далениус, Йейтс, Джессен, Паттерсон) используется, если генеральная совокупность может быть классифицирована (разделена на группы) по нескольким показателям таким образом, что каждая «клетка» занята только одним элементом или гнездом. Отборосуществляется по схеме «решетки»: если мы имеем квадрат со стороной р, разделенный на р 2 единичных квадратов, то можно извлечь выборку объемом в р единичных квадратов так, чтобы каждый ряд и каждый столбец большого квадрата содержал один из отбираемых единичных квадратов. Ряды и столбцы большого квадрата могут соответствовать любой группировке по двум признакам, где число групп по каждому признаку одинаковое, а каждая подгруппа содержит по одной единице. Подобные схемы возможны и при группировке по трем и более признакам. Обычно выделяются три типа отбора по решетке: 1) случайные квадратные решетки; 2) прямоугольные решетки; 3) кубические случайные решетки. Расслоение по композитному признаку. Строится дополнительный обобщающий показатель, учитывающий исходные признаки единиц наблюдения. По данному показателю осуществляется одномерное расслоение. Возможно два подхода к построению композитного признака: 1) использование эконометрической модели в виде определенной функции; 2) определение нормированного значения многомерного показателя. В первом случае существенным моментом является выбор вида функции, определение состава учитываемых исходных признаков и формы их участия в композитной формуле. Определение нормированного значения многомерного показателя в большей мере стандартизировано, при этом сам показатель может рассчитываться следующим образом:
где
Таблица 1. - Способы нормирования индивидуальных значений признака
Применение отбора по композитному признаку дает возможность использовать методы одномерной выборки, минуя методологические и организационные сложности многомерного отбора. К недостаткам расслоения по композитному признаку следует отнести невозможность одновременно учесть и числовые, и атрибутивные параметры. Кроме того, построение оптимизирующей функции применимо только к составу относительно однородных признаков (например, финансовых). Тем не менее использование данного метода представляется эффективным: в значении композитного признака «смешиваются» различные признаки, превращаясь в один агрегированный показатель, который можно интерпретировать как «вес предприятия». Комбинированные методы сочетают в себе приемы многомерности, используемые как при расслоении в независимых признаках, так и при расслоении по композитному признаку. Модель многомерной выборки в виде специализированной нейронной сети рассматривает исследуемую совокупность в виде структурной модели групп - случайных величин - абстрактных типических единиц наблюдения, которым присущи количественные (численность занятых, доход, объем производства и т.д.) и атрибутивные признаки (вид деятельности, форма собственности и т.д.). Значения признаков конкретного предприятия колеблются в определенных границах, не охватывая весь спектр величин от минимума по всей совокупности до максимума. Критерии формирования элементов подобной сети, т.е. нейронов, отражают сочетание объективных характеристик исследуемых объектов и субъективных (предпочтения наблюдателя). В качестве данных для обучающих ситуаций используется информация об объектах наблюдения, взятая из статистического регистра. Любая из выборок, построенная по предлагаемой модели, будет предназначена для проведения наблюдения и оценки показателей генеральной совокупности в момент времени, отдаленный от момента получения исходной информации. Для отбора единиц в выборку может быть использован метод имитационного моделирования. Практическое использование модели нейронной сети осложняется двумя факторами: а) потенциальной неадекватностью обучающих ситуаций тем ситуациям, в которых создаваемая нейронная сеть будет действовать, б) необходимостью интегрирования нейронной сети и существующего программного обеспечения обработки статданных в одну систему, что в настоящее время не представляется возможным вследствие чрезмерной сложности и несовместимости разнородных программных продуктов. Более простой вариант комбинационного подхода к формированию многомерной выборки - ее построение с помощью кластерного анализа. В соответствии с данным подходом исследуемая совокупность делится с помощью методов кластерного анализа (иерархический агломеративный метод, метод k-средних) на однородные группы. Внутри каждой полученной группы выделяется основной (ведущий) признак, по которому осуществляется последующий случайный или механический отбор единиц в выборку. Если по ведущему показателю коэффициент вариации превышает 50%, возможно дополнительное расслоение внутри кластера. По каждому признаку считается стандартная ошибка выборки. Если она превышает допустимые границы, то возможно три способа ее снижения: 1) увеличение объема выборки в кластере; 2) дополнительное расслоение единиц в кластере по ведущему признаку; 3) повторение процесса кластеризации, причем возможно использование того же метода кластеризации, что и ранее, но с увеличением числа шагов, либо использование итеративного метода с заданием числа кластеров r > l. Анализ существующих методов формирования многомерной выборки позволяет сделать вывод, что применение расслоения по независимым признакам может привести к чрезмерно большому числу групп в исследуемой совокупности. Расслоение по композитному признаку свободно от данного недостатка, но отсутствует гарантия того, что динамика уровня и вариации композитного признака будут пропорциональны динамике уровня и вариации исходных показателей. Комбинированные методы достаточно сложны и трудоемки. Оптимальным представляется разработка такой модели выборки, которая предусматривала бы возможность выбора экспертом (исследователем) метода построения одномерной или многомерной выборки в зависимости от объема совокупности, числа и характера рассматриваемых признаков. В составе одномерных выборок имеют приоритет по эффективности оптимальное и простое случайное расслоение, из многомерных методов наиболее приемлемыми по степени надежности и доступности для пользователя представляются методы кластерного анализа.
Тема 4. Статистическая оценка уровня инфляции.
1. Инфляция: основные понятия, механизм регулирования. 2. Частные и агрегированные показатели инфляции.
1. Инфляция: основные понятия, механизм регулирования
Инфляция представляет собой обесценение денежных средств, то есть снижение покупательной способности, которое вызывается комплексом монетарных, структурно-воспроизводственных, психологических и внешних причин. Инфляция, как сложное экономическое явление требует комплексного изучения. В основу классификации инфляционных процессов могут быть положены различные признаки: темпы роста цен, механизм возникновения и способы проявления, степень сбалансированности и предсказуемости, степень зависимости от внешних факторов, степень открытости и ряд других признаков. Так, по темпам роста цен различают инфляцию: а) ползучую (темп прироста цен до 10 % в год); б) галопирующую (от 10-50 % до 200-300 %); в) гиперинфляцию (свыше 50 % в месяц и на протяжении не менее полугода). По механизму возникновения и способам проявления инфляция в рыночной экономике традиционно подразделяется на инфляцию спроса и инфляцию издержек (предложения). Инфляция спроса обусловлена краткосрочным превышением совокупного спроса над совокупным предложением. Инфляция издержек возникает вследствие превышения совокупного предложения над совокупным спросом, что вызвано резким ростом цен на факторы производства (ресурсы, труд, капитал) или уменьшением совокупного предложения. По степени сбалансированности выявляется сбалансированная и несбалансированная инфляция. При первой цены растут умеренно и почти на все товары и услуги. При втором типе инфляции цены на различные товары постоянно меняются в различных пропорциях по отношению друг к другу. По степени предсказуемости можно выделить: 1) ожидаемую инфляцию, которая основана на научном прогнозе и предсказуема с достаточной степенью надежности; 2) неожиданную инфляцию, характеризующуюся внезапными скачками цен. По степени зависимости от внешних факторов выделяютвнутреннюю инфляцию и импортируемую, то есть обусловленную внешними факторами инфляцию. По степени открытости выделяют инфляцию открытую и скрытую. Скрытой инфляции присущ дефицит товаров, отложенный или неудовлетворенный спрос и постоянные цены. Этот тип инфляции характерен для командно-административной экономики.
  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  Что вызывает тренды на фондовых и товарных рынках Объяснение теории грузового поезда Первые 17 лет моих рыночных исследований сводились к попыткам вычислить, когда этот...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 ,
, - многомерный признак (признаки отбора) по i -ой единице наблюдения; Рij - нормированное значение j- го признака i -ой единицы наблюдения (способы нормирования см. табл. 1);
- многомерный признак (признаки отбора) по i -ой единице наблюдения; Рij - нормированное значение j- го признака i -ой единицы наблюдения (способы нормирования см. табл. 1);  - один из способов нормирования; k - общее количество признаков; yij - индивидуальное значение j -го признака у i- й единицы наблюдения;
- один из способов нормирования; k - общее количество признаков; yij - индивидуальное значение j -го признака у i- й единицы наблюдения; 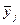 - среднее значение j -го признака.
- среднее значение j -го признака.
 , наиболее часто используется т.к.
, наиболее часто используется т.к. 

 - нормированное (эталонное) значение признака,
- нормированное (эталонное) значение признака,