|
|
Особливості паралельної моделі CUDA
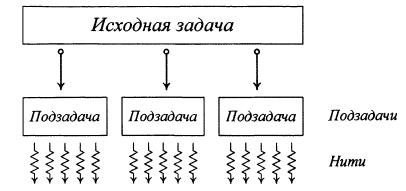
Важливим моментом є те, що хоча подібний підхід дуже схожий на pоботу з SIМD моделлю, є і принципові відмінності (компанія Nvidia використовує термін SIMT Siпgle Iпstructioп, Multiple Thread). Нитки розбиваються на групи по 32 нитки, звані wаrp'ами. Тільки нитки в межах одного warp'a виконуються фізично одночасно. Нитки з різних warp'ів мoжуть перебувати на різних стадіях виконання програми. При цьому управління wаrp'ми прозоро здійснює сам GPU. Для вирішення завдань CUDA використовує дуже велику кількість паралельно виконуваних ниток, при цьому зазвичай кожній нитці відповідає один елемент обчислюваних даних. Всі запущені на виконання нитки організовані в наступну ієрархію. Верхній рівень ієрархії - сітка (grid) - відповідає всім ниткам, які виконують дане ядро. Верхній рівень представляє з себе одновимірний або двомірний масив блоків (block).
Кожен блок - це одновимірний, двомірний або тривимірний масив ниток (thread). При цьому всі блоки, що утворюють сітку, мають однакову розмірність і розмір. Кожен блок в сітці має свою адресу, що складається з одного або двох невід'ємних цілих чисел (індекс блоку в сітці). Аналогічно кожна нитка всередині блоку також має свою адресу - одне, два або три невід'ємних цілих числа, які задають індекс нитки всередині блоку. Оскільки одне й те ж ядро виконується одночасно дуже великим числом ниток, то для тoгo, щоб ядро мало можливість однозначно визначити номер нитки (тобто і елемент даних, який потрібно обробляти), використовуються вбудовані змінні threadldx і blockldx. Кожна з цих змінних є тривимірним цілочисельним вектором. Зверніть увагу, що вони доступні тільки для функцій, які виконуються на GPU, для функцій, що виконуються на CPU, вони не мають сенсу. Також ядро може отримати розміри сітки і блоку через вбудовані змінні gridDim і blockDim. Подібне розділення всіх ниток є ще одним загальним прийомом використання CUDA - вихідне завдання розбивається на набір окремих підзадач, що вирішуються незалежно одна від одної. Кожній такій подзадачі відповідає свій блок ниток.
При цьому кожна підзадача спільно вирішується всіма нитками свого блоку. Розбиття ниток на warp'и відбувається окремо для кожного блоку; таким чином, всі нитки одного warp'a завжди належать одному блоку. При цьому нитки можуть взаємодіяти між собою тільки в межах блоку. Нитки різних блоків взаємодіяти між собою не можуть. Подібний підхід є вдалим компромісом між необхідністю забезпечити взаємодію ниток між собою і вартістю забезпечення такої взаємодії - забезпечити можливість взаємодії кожної нитки з кожної було б занадто складно і дорого. Існують лише два механізми, за допомогою яких нитки всередині блоку можуть взаємодіяти одна з одною: - колективна (shared) пам'ять; - бар'єрна синхронізація. Кожен блок отримує в своє розпорядження певний обсяг швидкої пам'яті, що розділяється (shаrеd), яку можуть спільно використовувати всі нитки блоку. Оскільки нитки блоку необов'язково виконуються фізично паралельно (тобто ми маємо справу не з чистою SIМD архітектурою, а має місце прозоре управління нитками), то для того, щоб не виникало проблем з одночасною роботою з shаrеd пам'яттю, необхідний деякий механізм синхронізації ниток блоку. CUDA пропонує досить простий спосіб синхронізації - так звана бар'єрна синхронізація. Для її здійснення використовується виклик вбудованої функції _syncthreads (), яка блокує нитки блоку до тих пір, поки всі нитки блоку не ввійдуть в цю функцію. Таким чином, за допомогою _syncthreads () ми можемо організувати «бар'єри» всередині ядра, які гарантують, що якщо хоча б одна нитка пройшла такий бар'єр, то не залишилося жодної за бар'єром (хто не пройшов його).
Ієрархія пам'яті CUDA
Таблиця 6.1 — Характеристики пам'яті GPU
Як видно з наведеної таблиці, частина пам'яті розташована безпосередньо в кожному з потокових мультипроцесорів (регістри і пам'ять, що розділяється), частина пам'яті розміщена в DRAM. Найбільш простим видом пам'яті є регістрова пам'ять (регістр). Кожен потоковий мультипроцесор містить 8192 або 16384 32-бітових регістрів (для позначення всіх регістрів потокового мультипроцесора використовується термін register file). Наявні регістри розподіляються між нитками блоку на етапі компіляції (і, відповідно, впливають на кількість блоків, які може виконувати один мультипроцесор). Кожна нитка отримує в своє монопольне користування кілька регістрів, які доступні як на читання, так і на запис (read / write). Нитка не має доступу до регістрів інших ниток, але свої регістри доступні їй протягом виконання даного ядра. Оскільки регістри розташовані безпосередньо в потоковому мультипроцесорі, то вони мають максимальну швидкість доступу. Якщо наявних регістрів не вистачає, то для розміщення локальних даних (змінних) нитки використовується так звана локальна пам'ять, розміщена в DRAM. Тому доступ до локальної пам'яті характеризується дуже високою латентністю - від 400 до 600 тактів. Наступним типом пам'яті в CUDA є так звана колективна (shared) пам'ять. Ця пам'ять розташована безпосередньо в потоковому мультипроцесорі, але вона виділяється на рівні блоків - кожен блок отримує в своє розпорядження одну і ту ж кількість пам'яті, що розділяється. Bcьогo кожен мультипроцесор містить 16 Кбайт пам'яті, що розділяється, і від тoгo, скільки такої пам'яті потрібно блоку, залежить кількість блоків, що можуть бути запущені на одному мультипроцесорі. Пам'ять, що розділяється має дуже невелику латентність (доступ до неї може бути настільки ж швидким, як і доступ до регістрів), доступна всім ниткам блоку, як на читання, так і на запис. Глобальна пам'ять - це звичайна DRАМ-пам'ять, яка виділяється за допомогою спеціальних функцій на CPU. Всі нитки сітки можуть читати і писати в глобальну пам'ять. Оскільки глобальна пам'ять розташована поза GPU, то природно, що вона має високу латентність (від 400 до 600 тактів). Правильне використання глобальної пам'яті є одним з краєугольних каменів оптимізації в CUDA. Константна і текстурна пам'ять, хоч і розташовані в DRAM, проте кешуються, тому швидкість доступу до них може бути дуже високою (набагато вище швидкості доступу до глобальної пам'яті). Обидва цих типу пам'яті доступні відразу всім ниткам сітки, але тільки на читання, запис в них може здійснювати тільки CPU за допомогою спеціальних функцій. Загальний обсяг константної пам'яті обмежений 64 Кбайтами. Текстурна пам'ять дозволяє отримати доступ до можливостей GPU по роботі з текстурами.   Что вызывает тренды на фондовых и товарных рынках Объяснение теории грузового поезда Первые 17 лет моих рыночных исследований сводились к попыткам вычислить, когда этот...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|