
|
|
ТЕМА: МНОГОФУНКЦИОНАЛЬНЫЕ СТАТИСТИЧЕСКИЕ КРИТЕРИИ.Стр 1 из 5Следующая ⇒ ЛЕКЦИЯ 6. ТЕМА: МНОГОФУНКЦИОНАЛЬНЫЕ СТАТИСТИЧЕСКИЕ КРИТЕРИИ. 1. Критерий φ* - угловое преобразование Фишера (+EXCEL) Биноминальный критерий m. Алгоритм выбора многофункциональных критериев. Многофункциональные статистические критерии – это критерии, которые могут использоваться по отношению к самым разнообразным данным, выборкам и задачам. С помощью этого рода критериев можно решать задачи на сопоставление уровней исследуемого признака, сдвигов и сравнение распределений. При этом данные могут быть представлены в любой шкале, выборки могут быть независимые и связанные. К многофункциональным статистическим критериям относятся угловое преобразование Фишера (j* критерий Фишера), применяемое в случае наличия двух выборок, и биноминальный критерий m для задач с одной выборкой. Применение многофункциональных критериевпозволяет определить, какая доля наблюдений в данной выборке характеризуется интересующим нас эффектом и какая доля этим эффектом не характеризуется. В качестве эффектов могут выступать: 1) качественные признаки (выражение согласия с предложением, выбор правой дорожки из двух и т.д.); 2) количественные признаки (уровень оценки, превышающий проходной балл, решение задачи менее чем за 20 секунд и т.п.); 3) соотношение значений или уровней признаков (преимущественное появление крайних признаков). Многофункциональные критерии, главным образом критерий φ*, применим к решению всех трех типов задач, рассмотренных в предыдущих лекциях: сопоставление уровней, определение сдвигов и сравнение распределений признака. В тех случаях, когда обследованы две выборки испытуемых, критерий φ* может эффективно заменять или, по крайней мере, эффективно дополнять традиционные критерии: Q - критерий Розенбаума, U - критерий Манна-Уитни, критерий χ2- Пирсона и критерий λ-Колмогорова-Смирнова.
1. Критерий φ* - угловое преобразование Фишера Назначение и описание критерия j* Критерий Фишера предназначен для сопоставления двух выборок по частоте встречаемости интересующего исследователя эффекта. Критерий оценивает достоверность различий между процентными долями двух выборок, в которых зарегистрирован интересующий исследователя эффект. Суть углового преобразования Фишера состоит в переводе процентных долей в величины центрального угла, который измеряется в радианах. Большей процентной доле будет соответствовать больший угол j, меньшей доле – меньший угол, но соотношения здесь нелинейные:
где Р – процентная доля, выраженная в долях единицы. При увеличении расхождения между углами j1 и j2 и увеличении численности выборок значение критерия возрастает. Чем больше величина j*, тем более вероятно, что различия достоверны. Критерии j* используется часто в сочетании с критерием l Колмогорова-Смирнова в целях достижения максимально точного результата. Гипотезы Н0: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 не больше, чем в выборке 2. Н1: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 больше, чем в выборке 2. Ограничения критери я φ* 1. Ни одна из сопоставляемых долей не должна быть равной нулю. Формально нет препятствий для применения метода φ в случаях, когда доля наблюдений в одной из выборок равна 0. Однако в этих случаях результат может оказаться неоправданно завышенным. 2. Верхний предел в критерии φ отсутствует - выборки могут быть сколь угодно большими. Нижний предел - 2 наблюдения в одной из выборок. Однако должны соблюдаться следующие соотношения в численности двух выборок: а) если в одной выборке всего 2 наблюдения, то во второй должно быть не менее 30: n1 =2 → n2 ≥ 30; б) если в одной из выборок всего 3 наблюдения, то во второй n1 =3 → n2 ≥7; в) если в одной из выборок всего 4 наблюдения, то во второй n1 =4 → n2 ≥5; г) при n1, n2 ≥5 возможны любые сопоставления. Возможно сопоставление выборок, не отвечающих этому условию, например, с соотношением n1=2, n2=15, но в этих случаях не удастся выявить достоверных различий. Других ограничений у критерия φ* нет. Рассмотрим несколько примеров, иллюстрирующих возможности критерия φ*. Пример 1: сопоставление выборок по качественно определяемому признаку. Пример 2: сопоставление выборок по количественно измеряемому признаку. Пример 3: сопоставление выборок и по уровню, и по распределению признака. Пример 4: использование критерия φ* в сочетании с критерием λ Колмогорова-Смирнова в целях достижения максимально точного результата.
Пример 1 - сопоставление выборок по качественно определяемому Признаку. В данном варианте использования критерия мы сравниваем процент испытуемых в одной выборке, характеризующихся каким-либо качеством, с процентом испытуемых в другой выборке, характеризующихся тем же качеством. Нас интересует, различаются ли две группы студентов по успешности решения новой экспериментальной задачи. В первой группе из 20 человек с нею справились 12 человек, а во второй выборке из 25 человек справились 10 человек. В первом случае процентная доля решивших задачу составит 12/20*100%=60%, а во второй 10/25*100%=40%. Достоверно ли различаются эти процентные доли при данных n1 и n2? Казалось бы, и "на глаз" можно определить, что 60% значительно выше 40%. Однако на самом деле эти различия при данных n1, n2 недостоверны. Проверим это. Сформулируем гипотезы. Н0: Доля лиц, справившихся с задачей, в первой группе не больше, чем во второй группе. H1: Доля лиц, справившихся с задачей, в первой группе больше, чем во второй группе. Теперь построим так называемую четырехклеточную, или четырехпольную таблицу, которая фактически представляет собой таблицу эмпирических частот по двум значениям признака: "есть эффект" - "нет эффекта". Таблица 1. Четырехклеточная таблица для расчета критерия при сопоставлении двух групп испытуемых по процентной доле решивших задачу.
В четырёхклеточной таблице, как правило, сверху размечаются столбцы "Есть эффект" и "Нет эффекта", а слева - строки "1 группа" и "2 группа". Участвуют в сопоставлениях, собственно, только поля (ячейки) А и В, то есть процентные доли по столбцу "Есть эффект". По Табл. XII Приложения 1 определяем величины φ, соответствующие процентным долям в каждой из групп. φ 1 (6О%) = 1,772 φ 2 (4О%) = 1,369 Теперь подсчитаем эмпирическое значение φ* по формуле:
где φ1 - угол, соответствующий большей % доле; φ2 - угол, соответствующий меньшей % доле; n1- количество наблюдений в выборке 1; n2- количество наблюдений в выборке 2.
В данном случае:
По Табл. ХШ Приложения 1 определяем, какому уровню значимости соответствует φ*эмп=1,34: p = 0,09 Можно установить и критические значения φ*, соответствующие принятым в психологии уровням статистической значимости:
φэмп = 1,34 φэмп < φкр
Построим «ось значимости». Полученное эмпирическое значение φ* находится в зоне незначимости. Ответ: Н0 принимается. Доля лиц, справившихся с задачей, впервой группе не больше, чем во второй группе. Пример 2 - сопоставление двух выборок по количественно измеряемому Признаку В данном примере использования критерия мы сравниваем процент испытуемых, достигших определенного уровня значения признака, в одной выборке с процентом испытуемых, достигающих этого уровня в другой выборке. В исследовании из 70 юношей - учащихся колледжа в возрасте от 14 до 16 лет было отобрано 10 испытуемых с высоким показателем по шкале Агрессивности и 11 испытуемых с низким показателем по шкале Агрессивности. Необходимо определить, различаются ли группы агрессивных и неагрессивных юношей по показателю расстояния, которое они спонтанно выбирают в разговоре с сокурсником. Данные представлены в Табл. 2. Отметим, что агрессивные юноши чаще выбирают расстояние в 50 см или даже меньше, в то время как неагрессивные юноши чаще выбирают расстояние, превышающее 50 см. Теперь мы можем рассматривать расстояние в 50 см, как критическое и считать, что если выбранное испытуемым расстояние меньше или равно 50 см, то "эффект есть", а если выбранное расстояние больше 50 см, то "эффекта нет". Мы видим, что в группе агрессивных юношей эффект наблюдается в 7 из 10, т. е. в 70% случаев, а в группе неагрессивных юношей - в 2 из 11, т. е. в 18,2% случаев. Эти процентные доли можно сопоставить по методу φ*, чтобы установить достоверность различий между ними.
Таблица 2. Сформулируем гипотезы. Н0: Доля лиц, которые выбирают дистанцию d≤50см, в группе агрессивных юношей не больше, чем в группе неагрессивных юношей. H1: Доля лиц, которые выбирают дистанцию d≤50см, в группе агрессивных юношей больше, чем в группе неагрессивных юношей. Теперь построим так называемую четырехклеточную таблицу. Таблица 3. Четырехклеточная таблица для расчета критерия ф* при сопоставлении групп агрессивных (n1=10) и неагрессивных юношей (n2=11)
По Табл. XII Приложения 1 определяем величины φ, соответствующие процентным долям "эффекта" в каждой из групп. φ*(70%) = 1,982 φ*(18,2%) = 0,881 Подсчитаем эмпирическое значение φ *:
Критические значения φ* нам уже известны:
Построим для наглядности «ось значимости».
Полученное эмпирическое значение φ* находится в зоне значимости. Ответ: H0 отвергается. Принимается Н1. Доля лиц, которые выбирают дистанцию в беседе меньшую или равную 50 см, в группе агрессивных юношей больше, чем в группе неагрессивных юношей (р<0,01). На основании полученного результата мы можем сделать заключение, что более агрессивные юноши чаще выбирают расстояние менее полуметра. Пример 3 - сопоставление выборок и по уровню, и по распределению Признака. В данном примере мы вначале проверим, различаются ли группы по уровню какого-либо признака, а затем сравним распределения признака в двух выборках. В исследовании использовался опросник, направленный на выявление тенденции к вытеснению из памяти фактов, имен, намерений и способов действия, обусловленному личными, семейными и профессиональными комплексами. Выборка из 50 студентов Педагогического института, не состоящих в браке, не имеющих детей, в возрасте от 17 до 20 лет, была обследована с помощью данного опросника для выявления интенсивности ощущения собственной недостаточности, или "комплекса неполноценности". Результаты обследования представлены в Табл. 4. а) Можно ли утверждать, что между показателем энергии вытеснения, диагностируемым с помощью опросника, и показателями интенсивности ощущения собственной недостаточности существуют какие-либо значимые соотношения? Таблица 4. Показатели интенсивности ощущения собственной недостаточности в группах студентов с высокой (n1=18) и низкой (n2=24) энергией вытеснения
Несмотря на то, что средняя величина в группе с более энергичным вытеснением выше, в ней наблюдаются также и 5 нулевых значений. Для сравнения двух распределений мы могли бы применить критерий χ2 или критерий λ, но для этого нам пришлось бы укрупнять разряды, а кроме того, в обеих выборках n<30.
Критерии φ* позволит нам проверить эффект несовпадения двух распределений, если мы условимся считать, что "эффект есть", если показатель чувства недостаточности принимает либо очень низкие (0), либо, наоборот, очень высокие значения (> 30), и что "эффекта нет", если показатель чувства недостаточности принимает средние значения, от 5 до 25. Сформулируем гипотезы. H0: Крайние значения показателя недостаточности (либо 0, либо 30 и более) в группе с более энергичным вытеснением встречаются не чаще, чем в группе с менее энергичным вытеснением. H1: Крайние значения показателя недостаточности (либо 0, либо 30 и более) в группе с более энергичным вытеснением встречаются чаще, чем в группе с менее энергичным вытеснением. Создадим четырехклеточную таблицу, удобную для дальнейшего расчета критерия φ*. Таблица 5. Четырехклеточная таблица для расчета критерия φ* при сопоставлении групп с большей и меньшей энергией вытеснения по соотношению показателей недостаточности
3. В первоначальной выборке было 50 человек, но 8 из них были исключены из рассмотрения как имеющие средний балл по показателю энергии вытеснения (14 - 15). Показатели интенсивности чувства недостаточности у них тоже средние: 6 значений по 20 баллов и 2 значения по 25 баллов. По Табл. XII Приложения 1 определим величины φ, соответствующие сопоставляемым процентным долям: φ 1 (88,9%) = 2,462 φ 2 (33,3%) = 1,230 Подсчитаем эмпирическое значение φ*:
Критические значения φ* при любых n1, n2, как мы помним из предыдущего примера, составляют:
φ*эмп = 3,951 φ*эмп > φ*кр (p≤0.01) Табл. XIII Приложения 1 позволяет нам и более точно определить уровень значимости полученного результата: р<0,001. Ответ: H0 отвергается. Принимается H1. Крайние значения показателя недостаточности (либо 0, либо 30 и более) в группе с большей энергией вытеснения встречаются чаще, чем в группе с меньшей энергией вытеснения.
б) Подтвердим совершенно иную гипотезу при анализе материалов данного примера. Докажем, что в группе с большей энергией вытеснения показатель недостаточности все же выше, несмотря на парадоксальность его распределения в этой группе. Сформулируем гипотезы. Н0: Самые низкие показателя недостаточности (нулевые) в группе с большей энергией вытеснения встречаются не чаще, чем в группе с меньшей энергией вытеснения. Н1: Самые низкие показатели недостаточности (нулевые) встречаются в группе с большей энергией вытеснения чаще, чем в группе с менее энергичным вытеснением. Сгруппируем данные в новую четырехклеточную таблицу. Таблица 7. Четырехклеточная таблица для сопоставления групп с разной энергией вытеснения по частоте нулевых значений показателя недостаточности
Определяем величины (р и подсчитываем значение φ*: φ*1 (27,8%) = 1,111 φ*2 (8,3%) = 0,584
φ*эмп >φ*кр (p≤0,05) Ответ: H0 отвергается. Самые низкие показатели недостаточности (нулевые) в группе с большей энергией вытеснения встречаются чаще, чем в группе с меньшей энергией вытеснения (р<0,05). Пример 4 - использование критерия φ* в сочетании с критерием λ Колмогорова-Смирнова в целях достижения максимально точного результата Если выборки сопоставляются по каким-либо количественно измеренным показателям, встает проблема выявления той точки распределения, которая может использоваться как критическая при разделении всех испытуемых на тех, у кого "есть эффект" и тех, у кого "нет эффекта". Чтобы максимально повысить мощность критерия φ*, можно сделать это с помощью алгоритма расчета критерия λ, позволяющего, обнаружить точку максимального расхождения между двумя выборками. В совместном исследовании проводился опрос английских общепрактикующих врачей двух категорий: а) врачи, поддержавшие медицинскую реформу и уже превратившие свои приемные в фондодержащие организации с собственным бюджетом; б) врачи, чьи приемные по-прежнему не имеют собственных фондов и целиком обеспечиваются государственным бюджетом. Опросники были разосланы выборке из 200 врачей, репрезентативной по отношению к генеральной совокупности английских врачей по представленности лиц разного пола, возраста, стажа и места работы - в крупных городах или в провинции. Ответы на опросник прислали 78 врачей, из них 50 работающих в приемных с фондами и 28 - из приемных без фондов. Каждый из врачей должен был прогнозировать, какова будет доля приемных с фондами в следующем году. На данный вопрос ответили только 70 врачей из 78, приславших ответы. Распределение их прогнозов представлено в Табл. 8 отдельно для группы врачей с фондами и группы врачей без фондов. Различаются ли каким-то образом прогнозы врачей с фондами и врачей без фондов? Таблица 8 Сформулируем гипотезы. H0: Доля лиц, прогнозирующих распространение фондов на 41%-100% всех врачебных приемных, в группе врачей с фондами не больше, чем в группе врачей без фондов. H1: Доля лиц, прогнозирующих распространение фондов на 41%-100% всех приемных, в группе врачей с фондами больше, чем в группе врачей без фондов. Определяем величины φ1 и φ2 по Таблице XII приложения 1, Напомним, что φ1 - это всегда угол, соответствующий большей процентной доле. φ1 (57,2%) = 1,727 φ2 (36.0%) = 1,287 Теперь определим эмпирическое значение критерия φ*:
По Табл. ХШ Приложения 1 определяем, какому уровню значимости соответствует эта величина: р =0,039. По той же таблице Приложения 1 можно определить критические значения критерия φ*:
Для наглядности можем построить "ось значимости":
Ответ: H0 отвергается (р =0,039). Доля лиц, прогнозирующих распространение фондов на 41-100% всех приемных, в группе врачей, взявших фонд, превышает эту долю в группе врачей, не взявших фонда. Иными словами, врачи, уже работающие в своих приемных на отдельном бюджете, прогнозируют более широкое распространение этой практики в текущем году, чем врачи, пока еще не согласившиеся перейти на самостоятельный бюджет.
АЛГОРИТМ Расчет критерия φ* 1. Определить те значения признака, которые будут критерием для разделения испытуемых на тех, у кого "есть эффект" и тех, у кого "нет эффекта". Если признак измерен количественно, использовать критерий λдля поиска оптимальной точки разделения. 2. Начертить четырехклеточную таблицу из двух столбцов и двух строк. Первый столбец - "есть эффект"; второй столбец - "нет эффекта"; первая строка сверху - 1 группа (выборка); вторая строка - 2 группа (выборка). 3. Подсчитать количество испытуемых в первой группе, у которых "есть эффект», и занести это число в левую верхнюю ячейку таблицы. 4. Подсчитать количество испытуемых в первой выборке, у которых "нет эффекта", и занести это число в правую верхнюю ячейку таблицы. Подсчитать сумму по двум верхним ячейкам. Она должна совпадать с количеством испытуемых в первой группе. 5. Подсчитать количество испытуемых во второй группе, у которых "есть эффект", и занести это число в левую нижнюю ячейку таблицы. 6. Подсчитать количество испытуемых во второй выборке, у которых "нет эффекта", и занести это число в правую нижнюю ячейку таблицы. Подсчитать сумму по двум нижним ячейкам. Она должна совпадать с количеством испытуемых во второй группе (выборке). 7. Определить процентные доли испытуемых, у которых "есть эффект", путем отнесения их количества к общему количеству испытуемых в данной группе (выборке). Записать полученные процентные доли соответственно в левой верхней и левой нижней ячейках таблицы в скобках, чтобы не перепутать их с абсолютными значениями. 8. Проверить, не равняется ли одна из сопоставляемых процентных долей нулю. Если это так, попробовать изменить это, сдвинув точку разделения групп в ту или иную сторону. Если это невозможно или нежелательно, отказаться от критерия φ* и использовать критерий χ2. 9. Определить по Табл. XII Приложения 1 величины углов φ для каждой из сопоставляемых процентных долей. 10. Подсчитать эмпирическое значение φ* по формуле:
где: φ1 - угол, соответствующий большей процентной доле; φ2 - угол, соответствующий меньшей процентной доле; n1 - количество наблюдений в выборке 1; n2 - количество наблюдений в выборке 2. 11. Сопоставить полученное значение φ* с критическими значениями: φ* < 1,64 (р≤0,05) и φ*≤2,31 (р < 0,01). Если φ*эмп > φ*кр., Н0 отвергается. При необходимости определить точный уровень значимости полученного φ*эмп по Табл. XIII Приложения 1.
Алгоритм j*-критерия Фишера (Excel) 1. Пусть исследуемое свойство в первой выборке отмечено у m 1 респондентов, во второй выборке ‒ у m 2 респондентов. Обозначим n1 – объем первой выборки, n2 – объем второй выборки. 2. Строкам столбца А таблицы Excel присваиваются названия: «m 1», «m 2», «n 1», «n 2», «а 1», «а 2», «фи1», «фи2», «ФИ», «Н». В строки столбца В таблицы Excel заносятся численные значения «m 1», «m 2», «n 1», «n 2», соответствующие строкам столбца А1 таблицы Excel. 1. В строках столбца В таблицы Excel («а1», «а2», «фи1», «фи2», «ФИ») проводятся вычисления по формулам: а 1 = m 1/ n1; а 2 = m 2/ n2; фи1 =2*ASIN(КОРЕНЬ(a 1)); фи2 =2*ASIN(КОРЕНЬ(a 2)); ФИ =ABS(фи1 – фи2)*КОРЕНЬ(n1 * n2 /(n1 + n2)). 2. Вычисленное значение ФИ является основанием для статистического вывода. Если ФИ < 1,29, то принимается гипотеза Н 0. Если 1,29 ≤ ФИ < 1,64, то принимается гипотеза Н 1(p ≤ 0,10). Если 1,64 ≤ ФИ < 2,31, то принимается гипотеза Н 1(p ≤ 0,05). Если 2,31 ≤ ФИ, то принимается гипотеза Н 1 (p ≤ 0,01). Пример использования φ*-критерия Фишера (Excel) У 27 девушек и 22 юношей измерили уровень мотивации к из- беганию неудач. Высокий уровень выявлен у 16 девушек и у 11 юношей. Есть ли статистически значимые различия долей девушек от юношей, имеющих высокий уровень мотивации к избеганию неудач
Число юношей с высоким уровнем мотивации Всего девушек Всего юношей =В1/В3 =В2/В4 =2*ASIN(КОРЕНЬ(B5) =2*ASIN(КОРЕНЬ(B6)
=ABS(B7-B8)*КОРЕНЬ(B3*B4/(B3+B4))
Статистический вывод. Так как ФИ < 1,29, то принимается гипотеза Н 0. Содержательный вывод. Нет статистически значимых отличий процентов девушек (59%) и юношей (50%) с высоким уровнем мотивации к избеганию неудач
Биноминальный критерий m. Гипотезы H0: Частота встречаемости данного эффекта в обследованной выборке не превышает теоретической (заданной, ожидаемой, предполагаемой). Н1: Частота встречаемости данного эффекта в обследованной выборке превышает теоретическую (заданную, ожидаемую, предполагаемую). И разных гипотезах.
Пояснения к Таблице 1. A) Если заданная вероятность Р<0,50, а ƒэмп >ƒтеор (например, допустимый уровень брака - 15%, а в обследованной выборке получено значение в 25%), то биномиальный критерий применим для объема выборки 2≤n≤50. Б) Если заданная вероятность Р<0,50, а ƒэмп<ƒтеор (например, допустимый уровень брака - 15%, а в обследованной выборке наблюдается 5% брака), то биномиальный критерий неприменим и следует применять критерий χ2(см. Пример 2). B) Если заданная вероятность Р=0,50, а ƒэмп>ƒтеор (например, вероятность выбора каждой из равновероятных альтернатив Р=0,50, а в обследованной выборке одна из альтернатив выбирается чаще, чем в половине случаев), то биномиальный критерий применим для объема выборки 5≤n≤300. Г) Если заданная вероятность Р=0,50, а ƒэмп<ƒтеор (например, вероятность выбора каждой из равновероятных альтернатив Р=0,50, а в обследованной выборке одна из альтернатив наблюдается реже, чем в половине случаев), то вместо биномиального критерия применяется критерий знаков G, являющийся "зеркальным отражением" биномиального критерия при Р=0,50. Допустимый объем выборки: 5≤n≤300. Д) Если заданная вероятность Р>0,50, а ƒэмп>ƒтеор (например, среднестатистический процент решения задачи - 80/о, а в обследованной выборке он составляет 95%), то биномиальный критерий неприменим и следует применять критерий χ2 (см. Пример 3). Е) Если заданная вероятность Р>0,50, а ƒэмп<ƒтеор (например, среднестатистический процент решения задачи – 80%, а в обследованной выборке он составляет 60%), то биномиальный критерий применим при условии, что в качестве "эффекта" мы будем рассматривать более редкое событие - неудачу в решении задачи, вероятность которого Q=l—Р=1—0,80=0,20 и процент встречаемости в данной выборке: 100%—75%=25%. Эти преобразования фактически сведут данную задачу к задаче, предусмотренной п. А. Допустимый объем выборки: 5≤n≤300 (см. пример 3). Пример 1 Впроцессе тренинга сенситивности в группе из 14 человек выполнялось упражнение "Психологический прогноз". Все участники должны были пристально вглядеться в одного и того же человека, который сам пожелал быть испытуемым в этом упражнении. Затем каждый из участников задавал испытуемому вопрос, предполагавший два заданных варианта ответа, например: "Что в тебе преобладает: отстраненная наблюдательность или включенная эмпатия?" "Продолжал бы ты работать или нет, если бы у тебя появилась материальная возможность не работать?" "Кто тебя больше утомляет - люди нахальные или занудные?" и т. п. Испытуемый должен был лишь молча выслушать вопрос, ничего не отвечая. Во время этой паузы участники пытались определить, как он ответит на данный вопрос, и записывали свои прогнозы. Затем ведущий предлагал испытуемому дать ответ на заданный вопрос. Теперь каждый участник мог определить, совпал ли его прогноз с ответом испытуемого или нет. После того, как было задано 14 вопросов (13 участников + ведущий), каждый сообщил, сколько у него получилось точных прогнозов. В среднем было по 7-8 совпадений, но у одного из участников их было 12, и группа ему спонтанно зааплодировала. У другого участника, оказалось всего 4 совпадения, и он был очень этим огорчен. Вопросы: 1) Имела ли группа статистические основания для аплодисментов? 2) Имел ли огорченный участник статистические основания для грусти? 1) Решение первого вопроса задачи. По-видимому, группа будет иметь статистические основания для аплодисментов, если частота правильных прогнозов у участника А превысит теоретическую частоту случайных угадываний. Если бы участник прогнозировал ответ испытуемого случайным образом, то, в соответствии с теорией вероятностей, шансы случайно угадать или не угадать ответ на данный вопрос у него были бы равны P=Q=0,5. Определим теоретическую частоту правильных случайных угадывании: ƒтеор = n*P где n - количество прогнозов; Р - вероятность правильного прогноза при случайном угадывании. ƒтеор =14*0,5=7 Итак, нам нужно определить, "перевешивают" ли 12 реально данных правильных прогнозов 7 правильных прогнозов, которые могли бы быть у данного участника, если бы он прогнозировал ответ испытуемого случайным образом. Требования, предусмотренные ограничением 3, соблюдены: Р=0,50; ƒэмп>ƒтеор. Данный случай относится к варианту "В" Табл. 1. Сформулируем гипотезы к первому вопросу: H0: Количество точных прогнозов у участника А не превышает частоты, соответствующей вероятности случайного угадывания. Н1: Количество точных прогнозов у участника А превышает частоту, соответствующую вероятности случайного угадывания. По Табл. XIV Приложения 1 определяем критические значения критерия m при n=14, Р=0,50:
Мы помним, что за эмпирическое значение критерия m принимается эмпирическая частота: mэмп=ƒэмп =12 mэмп≥ mкр (р≤0,01) Построим "ось значимости".
Зона значимости простирается вправо, в область более высоких значений m, а зона незначимости - в область более низких значений. Ответ: H0 отвергается. Принимается H1. Количество точных прогнозов у участника А превышает (или по крайней мере равняется) критической частоте вероятности случайного угадывания (р≤0,01). Группа вполне обоснованно ему аплодировала!
2) Решение второго вопроса задачи. Основания для грусти могут появиться, если количество правильных прогнозов оказывается достоверно ниже теоретической частоты случайных угадываний. Необходимо определить, 4 точных прогноза участника Б - это достоверно меньше, чем 7 теоретически возможных правильных прогнозов при случайном угадывании или нет? В данном случае Р=0,50; ƒэмп<ƒтеор. В соответствии с ограничением 4, в данном случае мы должны применить критерий знаков, который по существу является зеркальным отражением или "второй стороной" одностороннего биномиального критерия (вариант "Г" Табл. 1). Вначале нам нужно определить, что является типичным событием для участника Б. Это неправильные прогнозы, их 10. Теперь мы определяем, достаточно ли мало у него нетипичных правильных прогнозов, чтобы считать перевешивание неправильных прогнозов достоверным. Сформулируем гипотезы. H0: Преобладание неправильных прогнозов у участника Б является случайным. Н1: Преобладание неправильных прогнозов у участника Б не является случайным. По Табл. V Приложения 1 определяем критические значения критерия знаков G для n=14:
Построим "ось значимости". Мы помним, что в критерии знаков зона значимости находится слева, а зона незначимости - справа, так как чем меньше нетипичных событий, тем типичные события являются более достов   ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 ,
,














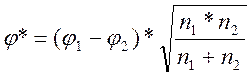
 Число девушек с высоким уровнем мотивации
Число девушек с высоким уровнем мотивации

