
|
|
Этап центрирования входных переменныхДля этого, сначала входные обобщенные переменные
В дальнейшем волну в обозначениях переменных опусим подразумевая что переменные центрированы. Теперь в центрированных переменных Уравнения модели можем писать в виде
Можно показать что ниже описанная процедура формирования модели первого и последующих рядов позволяет находить модель в виде
Вы спросите?– а нужна ли еще зачем-то отрогонализация (кроме уменьшения еще на 1 размерности вектора параметров, который ищем через МНК) -из
Рис1 Рис 2 Рис 3 Рис 4 Напомним, что параметры расчитанные на ортогональных входных аргументах (независимых) наиболее точно расчитаны – для этого варианта расчета плоскость аргументов, куда опускается проекция, в пространстве расположена наиболее «устойчиво » относительно шума в данных – угол между векторами – таким образом ш ум данных на положение плоскости влияет в наименшей степени и таким образом посчитанная модель имеет наименьшую погрешность связанную с наличием шума.
Коэффициенты
Вывод формулы МНК для одномерного случая повторим применяя ранее ипользовавшийся прием: Нам необходимо приблизить
где точка – знак скалярного произведения векторов. Тоже самое можем записать в виде
Далее будем искать ортогонализироваые частные модели описание в виде здесь
При условии центрирования переменных по среднему значению в частных частных моделях (1) как уже говорили свободный член равен нулю, а коэффициент при третьем члене
где вектор Ортогональна добавка
где коэффициент
Смысл проведенного преобразования в том, что исходный вектор По сути эта процедура проекии является процедурой расчета методом наименш квадратов коефициету Сходимость алгоритма по моделям Сходимость последовательности.
  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 и выходная
и выходная  переменные центрируются по данным обучающей выборки А:
переменные центрируются по данным обучающей выборки А:

 , где
, где  - значения средних на выборке А:
- значения средних на выборке А: - от одного параметра избавились.
- от одного параметра избавились. где
где  - лучшая модель «s-1» ряда селекции
- лучшая модель «s-1» ряда селекции  -ортогонализированная к
-ортогонализированная к  -уже единственный параметр, который ищем методом наименьших квадратов.
-уже единственный параметр, который ищем методом наименьших квадратов. получать
получать  и таким образом пользоватся в дальнейшем ортогональной парочкой аргментов
и таким образом пользоватся в дальнейшем ортогональной парочкой аргментов 




 , на которых эта плоскость нами определяется- наиболее устойчивый - 900
, на которых эта плоскость нами определяется- наиболее устойчивый - 900 Формирования первого ряда моделей алгоритма
Формирования первого ряда моделей алгоритма  , (*)
, (*) перебираются из множества
перебираются из множества 
 частных моделей первого этапа находим по МНК на точках обучения - множестве точек А, требуя приближения моделями (*) выхода
частных моделей первого этапа находим по МНК на точках обучения - множестве точек А, требуя приближения моделями (*) выхода  ,
, Поэтому из (*) запишем
Поэтому из (*) запишем  (**). Отсюда, домножив слева каждую сторону (**) на вектор строку
(**). Отсюда, домножив слева каждую сторону (**) на вектор строку 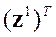 (далее знак транспонир. будем опускать применив знак скалярного произведения векторов) получим для каждой к -той модели претендента
(далее знак транспонир. будем опускать применив знак скалярного произведения векторов) получим для каждой к -той модели претендента или
или 
 , где IA - множество индексов обучающих точек А выборки данных.
, где IA - множество индексов обучающих точек А выборки данных. (1)
(1) = индекс этапа,
= индекс этапа,  - сформирован как лучший из F просчитанных путей нахождения обобщенной переменной путем образования произведения из расширенного множества входных переменных Т, при этом
- сформирован как лучший из F просчитанных путей нахождения обобщенной переменной путем образования произведения из расширенного множества входных переменных Т, при этом  - это ортогональная
- это ортогональная  составляющая вектора
составляющая вектора 
 .
. - это невязка модели предыдущего ряда а
- это невязка модели предыдущего ряда а  =
=  -
- 
 (1 *) см рямоугольный треугольник
(1 *) см рямоугольный треугольник определяется из из условия ортогональности;
определяется из из условия ортогональности; или
или  , отсюда
, отсюда 
 раскладывается по двум направлениям - по направлению вектора
раскладывается по двум направлениям - по направлению вектора  , и ортогональном ему направлении
, и ортогональном ему направлении  Рис. А
Рис. А ) участвует только его часть
) участвует только его часть  получается путем проекции вектора
получается путем проекции вектора  (вектор проекции - невязка
(вектор проекции - невязка  - обозначена пунктиром) на направление AВ, являющийся продолжением вектора
- обозначена пунктиром) на направление AВ, являющийся продолжением вектора 
 .
. к вектору выхода
к вектору выхода 

 ....
.... 
 становится очевидной из рассмотрения прямоугольного треугольника формирующейся векторами,
становится очевидной из рассмотрения прямоугольного треугольника формирующейся векторами,  ,
,  . Здесь, как указывалось ранее
. Здесь, как указывалось ранее  ,
,  - невязки лучших моделей
- невязки лучших моделей 
 соответствующего ряда. Если учесть что в прямоугольном треугольнике
соответствующего ряда. Если учесть что в прямоугольном треугольнике  ,
, 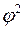 ,....
,....  ,
,