
|
|
Классификация ILP-архитектур ⇐ ПредыдущаяСтр 4 из 4 • Суперскалярные – Процессор ищет независимые команды и планирует поток вычислений • VLIW / EPIC – Компилятор ищет независимые команды и планирует поток вычислений Itanium2 Эльбрус 2000 – VLIW/EPIC Alpha Power – RISC суперскаляр
TLP Многопоточность – это свойство платформы или программы, позволяющее процессу состоять из нескольких потоков команд, исполняющихся параллельно, без предписанного порядка во времени. Крупнозернистая многопоточность (Coarse-grained MT) • 2 и более аппаратных контекстов – – Счетчик команд – Буфер выборки инструкций • Одновременно не более 1 нити • Аппаратное переключение контекстов при прерывании
Мелкозернистая многопоточность (Fine-grained MT) • – Регистры общего назначения – Счетчик команд • Одновременно не более 1 нити • Аппаратное переключение на каждом такте
Одновременная многопоточность (Simultaneous MT) • – Регистры общего назначения – Буфер выборки инструкций – Буфер переупорядочивания – Стек возврата • Привязка команд и нитей • До нескольких нитей одновременно • Контексты активны, переключения не происходит CMP • POWER 4 • Barcelona • Clovertown • Opteron SMT • Alpha 21464 • Pentium 4 • Itanium 2 Архитектуры с параллелизмом на уровне команд (ILP). Способы выявления и реализации ILP. Примеры микропроцессоров.
ILP-процессоры • Имеют несколько исполнительных устройств • Исполняют несколько команд одновременно
Классификация ILP-архитектур • Суперскалярные – Процессор ищет независимые команды и планирует поток вычислений • VLIW / EPIC – Компилятор ищет независимые команды и планирует поток вычислений
Способы повышения производительности • Повышение темпа исполнения команд требует повышения темпа их доставки. Средства: – Спекулятивное исполнение команд • SS: автоматический выбор способа предсказания перехода • EPIC: способ предсказания перехода задает компилятор – Спекулятивная загрузка данных • SS: проверка корректности автоматическая • EPIC: проверка корректности по спец. команде – Разрешение ложных зависимостей по данным • SS: переименование регистров • EPIC: компилятор не допускает ненужных зависимостей – Оптимизация вызовов подпрограмм • SS: регистровый стек управляется процессоров автоматически • EPIC: регистровый стек управляется компилятором Суперскалярные • • Простой компилятор • Меньше ресурсов процессора – Регистры – Исп. устройства – Кэш • Меньше команд за такт: 3, 4, 5 (<50%) VLIW / EPIC • Простой конвейер • Сложный компилятор • Больше ресурсов процессора – Регистры – Исп. устройства – Кэш • Больше команд за такт: 6 (>50%)
Itanium2 Эльбрус 2000 – VLIW/EPIC Alpha Power – RISC суперскаляр
Архитектуры с параллелизмом на уровне данных (DLP). Способы выявления и реализации DLP. Примеры микропроцессоров. Параллельные вычислительные системы — это физические компьютерные, а также программные системы, реализующие тем или иным способом параллельную обработку данных на многих вычислительных узлах. Идея распараллеливания вычислений базируется на том, что большинство задач может быть разделено на набор меньших задач, которые могут быть решены одновременно. Обычно параллельные вычисления требуют координации действий. Параллельные вычисления существуют в нескольких формах: параллелизм на уровне инструкций, параллелизм данных. К ним возрос интерес вследствие существования физических ограничений на рост тактовой частоты процессоров
Параллелизм данных Основная идея подхода, основанного на параллелизме данных, заключается в том, что одна операция выполняется сразу над всеми элементами массива данных. Различные фрагменты такого массива обрабатываются на векторном процессоре или на разных процессорах параллельной машины. Распределением данных между процессорами занимается программа. Векторизация или распараллеливание в этом случае чаще всего выполняется уже на этапе компиляции – перевода исходного текста программы в машинные команды. Роль программиста в этом случае обычно сводится к заданию опций векторной или параллельной оптимизации компилятору, директив параллельной компиляции, использованию специализированных языков для параллельных вычислений.
• • Единообразная обработка массивов данных
SIMD-расширения были введены в архитектуру x86 с целью повышения скорости обработки потоковых данных. Основная идея заключается в одновременной обработке нескольких элементов данных за одну инструкцию.
• Векторно-конвейерные процессоры – Cray – Fujitsu VX/VP – NEC SX • Векторные расширения – x86: MMX, 3DNow!, SSE, SSE2, … – PowerPC: AltiVec • Перспективные векторные процессоры – STI Cell – Intel Larabee
Первой SIMD-расширение ввела фирма Intel - это расширение MMX. Оно стало использоваться в процессорах Pentium MMX и Pentium II. Расширение MMX работает с 64-битными регистрами MM0-MM7, физически расположенными на регистрах сопроцессора, и включает 57 новых инструкций для работы с ними. 64-битные регистры логически могут представляться как одно 64-битное, два 32-битных, четыре 16-битных или восемь 8-битных упакованных целых
Расширение 3DNow! - Технология 3DNow! была введена фирмой AMD в процессорах K6. Расширение работает с регистрами 64-битными MMX, которые представляются как два 32-битных вещественных числа с одинарной точностью. Система команд расширена 21 новой инструкцией, среди которых есть команда выборки данных в кэш L1. Расширение SSE С процессором Intel Pentium III впервые появилось расширение SSE. Это расширение работает с независимым блоком из восьми 128-битных регистров XMM0-XMM7. Каждый регистр XMM представляет собой четыре упакованных 32-битных вещественных числа с одинарной точностью. Команды блока XMM позволяют выполнять как векторные, так и скалярные операции. Кроме инструкций с блоком XMM в расширение SSE входят и дополнительные целочисленные инструкции с регистрами MMX, а также инструкции управления кэшированием.
Расширение SSE2 В процессоре Intel Pentium 4 набор инструкций получил очередное расширение - SSE2. Оно позволяет работать с 128-битными регистрами XMM как с парой упакованных 64-битных вещественных чисел двойной точности, а также с упакованными целыми числами: 16 байт, 8 слов, 4 двойных слова или 2 учетверенных (64-битных) слова. Введены новые инструкции вещественной арифметики двойной точности, инструкции целочисленной арифметики, 128-разрядные для регистров XMM и 64-разрядные для регистров MMX. Ряд старых инструкций MMX распространили и на XMM (в 128-битном варианте). 4-я лаба
  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 Регистры общего назначения
Регистры общего назначения 2 и более аппаратных контекстов
2 и более аппаратных контекстов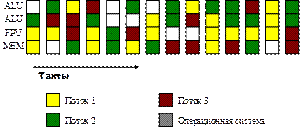 2 и более аппаратных контекстов
2 и более аппаратных контекстов Сложный конвейер
Сложный конвейер Векторные вычисления (SIMD)
Векторные вычисления (SIMD)