|
|
Окно сведений менеджера виртуальных машинСтр 1 из 4Следующая ⇒ 112. Дисциплины распределения ресурсов (ДРР) - весьма важный показатель, влияющий на эффективность работы ЭВМ. Применение той или иной дисциплины распределения зависит от особенностей использования данного ресурса, критериев оценки эффективности работы системы, а также от сложности реализации данной ДРР [12] Одноочередные дисциплины
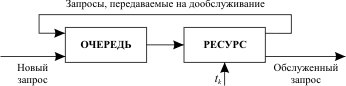
Схема доступа - очередь. Широко используется в качестве как самостоятельной дисциплины распределения, так и составной части более сложных дисциплин. Время нахождения в очереди длинных (то есть требующих большого времени обслуживания) и коротких запросов зависит только от момента их поступления.
Схема доступа - стек.
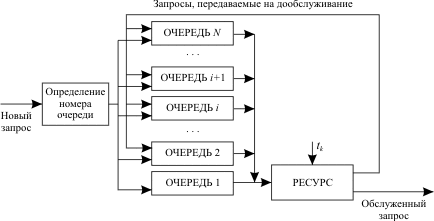
Запрос обслуживается в течение кванта времени tk. Если за это время обслуживание не завершено, то запрос передается в конец входной очереди на дообслуживание. Здесь короткие запросы находятся в очереди меньшее время, чем длинные. Многоочередные дисциплины Базовый вариант многоочередной дисциплины обслуживания представлен на рис. 13.4.
Основа дисциплины - круговой циклический алгоритм. Все новые запросы поступают в очередь 1. Время, выделяемое на обслуживание любого запроса, равно длительности кванта tk. Если запрос обслужен за это время, то он покидает систему, а если нет, то по истечении выделенного кванта времени он поступает в конец очереди i +1. На обслуживание выбирается запрос из очереди i, только если очереди 1,…, i -1 пусты. Таким образом, длинные запросы поступают сначала в очередь 1, затем постепенно доходят до очереди N и здесь обслуживаются до конца либо по дисциплинеFIFO, либо по круговому циклическому алгоритму. Модификации базового варианта многоочередной дисциплины обслуживания запросов.
tki = 2i-1 x tk где tk - квант времени, выделяемый для программ из очереди 1. Такая дисциплина обслуживания наиболее благоприятна коротким программам, хотя явного указания приоритетов программ здесь нет. Степень благоприятствования тем выше, чем меньше tk. Однако уменьшение длительности кванта ведет к увеличению накладных расходов, необходимых для перераспределения ресурса между программами. Данная ДРР может работать как с относительными, так и с абсолютными приоритетами программ.
Определение номера очереди, в которую поступает программа при первоначальной загрузке, осуществляется по алгоритму планирования Корбато: программа сразу поступает в очередь i = [log2 lp/ltk + 1], где lp - длина программы в байтах; ltk - число байт, которые могут быть переданы между ОЗУ и внешней памятью за время tk (рис. 13.5).
Эта дисциплина позволяет сократить количество системных переключений за счет того, что программам, требующим большего времени решения, будут предоставляться достаточно большие кванты времени уже при первом занятии ими ресурса (нерационально программе, которая требует для своего решения 1 час времени, первоначально выделять квант в 1 мс). 113. Виртуализация в вычислениях — процесс представления набора вычислительных ресурсов, или их логического объединения, который даёт какие-либо преимущества перед оригинальной конфигурацией. Это новый виртуальный взгляд на ресурсы составных частей, не ограниченных реализацией, физической конфигурацией или географическим положением. Обычно виртуализированные ресурсы включают в себя вычислительные мощности и хранилище данных. По-научному, виртуализация — это изоляция вычислительных процессов и ресурсов друг от друга. Примером виртуализации являются симметричные мультипроцессорные компьютерные архитектуры, которые используют более одного процессора. Операционные системы обычно конфигурируются таким образом, чтобы несколько процессоров представлялись как единый процессорный модуль. Вот почему программные приложения могут быть написаны для одного логического (виртуального) вычислительного модуля, что значительно проще, чем работать с большим количеством различных процессорных конфигураций. Виртуализация на уровне ОС Виртуализация на уровне операционной системы — виртуализирует физический сервер на уровне ОС, позволяя запускать изолированные и безопасные виртуальные серверы на одном физическом сервере. Эта технология не позволяет запускать ОС с ядрами, отличными от типа ядра базовой ОС. При виртуализации на уровне операционной системы не существует отдельного слоя гипервизора. Вместо этого сама хостовая операционная система отвечает за разделение аппаратных ресурсов между несколькими виртуальными серверами и поддержку их независимости друг от друга. § Solaris Containers/Zones § FreeBSD Jail § Linux-VServer (англ.) § LXC (Linux Containers) Аппаратная виртуализация — виртуализация с поддержкой специальной процессорной архитектуры. В отличие от программной виртуализации, с помощью данной техники возможно использование изолированных гостевых систем, управляемых гипервизором напрямую. Гостевая система не зависит от архитектуры хостовой платформы и реализации платформы виртуализации. Например, с помощью технологий аппаратной виртуализации возможен запуск 64-битных гостевых систем на 32-битных хостовых системах. Аппаратная виртуализация обеспечивает производительность, сравнимую с производительностью невиртуализованной машины, что дает виртуализации возможность практического использования и влечет её широкое распространение. Наиболее распространены технологии виртуализации Intel-VT и AMD-V. Виртуальная машина — это окружение, которое представляется для «гостевой» операционной системы, как аппаратное. Однако на самом деле это программное окружение, которое эмулируется программным обеспечением хостовой системы. Эта эмуляция должна быть достаточно надёжной, чтобы драйверы гостевой системы могли стабильно работать. При использовании паравиртуализации, виртуальная машина не эмулирует аппаратное обеспечение, а, вместо этого, предлагает использовать специальное API. Примеры применения: § тестовые лаборатории и обучение: Тестированию в виртуальных машинах удобно подвергать приложения, влияющие на настройки операционных систем, например инсталляционные приложения. За счёт простоты в развёртывании виртуальных машин, они часто используются для обучения новым продуктам и технологиям. § распространение предустановленного ПО: многие разработчики программных продуктов создают готовые образы виртуальных машин с предустановленными продуктами и предоставляют их на бесплатной или коммерческой основе. Такие услуги предоставляют Vmware VMTNили Parallels PTN
114. virt-manager предоставляет графический интерфейс для доступа к гипервизорам и виртуальным машинам в локальной и удаленных системах. С помощью virt-manager можно создать и полностью виртуализированные, и паравиртуализированные виртуальные машины. Кроме того, virt-manager выполняет управляющие функции:
В главном окне менеджера показаны все выполняющиеся виртуальные машины и выделенные им ресурсы (домен 0 включительно). Показанные поля можно отфильтровать. Двойной щелчок на имени виртуальной машины откроет ее консоль. Выбор виртуальной машины и двойной щелчок на кнопке Подробности (Details) откроет окно сведений об этой машине. Новая машина может быть создана в меню Файл (File). Мониторинг состояния С помощью менеджера можно изменить настройки контроля статуса. Потоки и процессы Процессы Термин «процесс» впервые появился при разработке операционной системы Multix и имеет несколько определений, которые используются в зависимости от контекста, согласно которым процесс — это:
Для описания состояний процессов используется несколько моделей. Самая простая — модель трех состояний. Она определяет следующие состояния процесса:
Выполнение — это активное состояние, во время которого процесс обладает всеми необходимыми ему ресурсами. В этом состоянии процесс непосредственно выполняется процессором. Ожидание — это пассивное состояние, во время которого процесс заблокирован и не может быть выполнен, потому что ожидает какое-то событие, например, ввода данных или освобождения нужного ему устройства. Готовность — это тоже пассивное состояние, процесс тоже заблокирован, но в отличие от состояния ожидания, он заблокирован не по внутренним причинам (ведь ожидание ввода данных — это внутренняя, «личная» проблема процесса — он может ведь и не ожидать ввода данных и свободно выполняться — никто ему не мешает), а по внешним, независящим от процесса, причинам. Рождение процесса — это пассивное состояние, когда самого процесса еще нет, но уже готова структура для появления процесса. Смерть процесса — самого процесса уже нет, но может случиться, что его «место", то есть структура данных, осталась в списке процессов. Такие процессы называются зобми. В ОС РВ время перехода процесса из одного состояния в другое должно быть детерминированно. Функции контроля за временем (deadline) возлагаются на планировщика (о планировании будет сказано далее). Операции над процессами Над процессами можно производить следующие операции:
Для создания процесса операционной системе нужно:
Иерархия процессов Процесс не может взяться из ниоткуда: его обязательно должен запустить какой-то процесс. Процесс, запущенный другим процессом, называется дочерним (child) процессом или потомком. Процесс, который запустил новый процесс называется родительским (parent), родителем или просто — предком. У каждого процесса есть два атрибута — PID (Process ID) - идентификатор процесса и PPID (Parent Process ID) — идентификатор родительского процесса. Процессы создают иерархию в виде дерева. Самым «главным» предком, то есть процессом, стоящим на вершине этого дерева, является процесс init (PID=1). Потоки Концепция процесса, пришедшая из мира UNIX, плохо реализуется в многозадачной системе, поскольку процесс имеет тяжелый контекст. Возникает понятие потока (thread), который понимается как подпроцесс, или легковесный процесс (light-weight process), выполняющийся в контексте полноценного процесса. С помощью процессов можно организовать параллельное выполнение программ. Для этого процессы клонируются вызовами fork() или exec(), а затем между ними организуется взаимодействие средствами IPC. Это довольно дорогостоящий в отношении ресурсов способ. С другой стороны, для организации параллельного выполнения и взаимодействия процессов можно использовать механизм многопоточности. Основной единицей здесь является поток, который представляет собой облегченную версию процесса. Чтобы понять, в чем состоит его особенность, необходимо вспомнить основные характеристики процесса.
Если рассматривать эти характеристики независимо друг от друга (как это принято в современной теории ОС), то:
Все потоки процесса разделяют общие ресурсы. Изменения, вызванные одним потоком, становятся немедленно доступны другим. При корректной реализации потоки имеют определенные преимущества перед процессами. Им требуется:
Задачи Как уже говорилось, СРВ — это программно-аппаратный комплекс, осуществляющий мониторинг какого-то объекта и/или управление им в условиях временнЫх ограничений. Возникающие на объекте события подлежат обработке в СРВ. Будем сопоставлять каждому типу события задачу. ЗАДАЧА (TASK) — блок программного кода, ответственный за обработку тех или иных событий, возникающих на объекте управления. Задача может быть «оформлена» в виде:
РАБОТА ЗАДАЧИ (JOB) — процесс исполнения блока программного кода в ходе обработки события. Каждая работа задачи характеризуется следующими временнЫми параметрами:
Упомянутые параметры определяются следующим:
116. Приоритет процесса определяет, как часто данный процесс, по сравнению с другими процессами, стоящими в очереди на выполнение процессора, будет исполняться процессором. Вы должны понять, что приоритет — понятие относительное. Ведь в данный момент в очереди на выполнение могут стоят двадцать процессов, а в следующий — два. Поэтому приоритет — это «плавающее» значение, которое определяет сама система в зависимости от текущей ситуации. В Linux значение приоритета может быть равно числу в диапазоне сорока значений. Как же я туманно выразился. На самом деле, все зависит от версии ядра Linux. Значение приоритета может быть в диапазоне от -20 до 19 или от 0 до 39. В обоих случаях возможное значение ограничено сорока числами. В ядрах версии 2.6.х значение приоритета находится в диапазоне от 0 до 39. Чем меньше число – тем выше приоритет процесса. То есть процесс с приоритетом 5 имеет больший приоритет, чем процесс с приоритетом 16. Вы не можете непосредственно изменять приоритет процесса, это прерогатива операционной системы. Но Вы можете определить, на сколько больше или меньше процесс будет «нравиться» системе. Для этого следует использовать поле nice. То есть для изменения приоритета администратор должен изменять значение поля nice. Если значение nice равно нулю — значит, у программы приоритет не изменен. Если в поле nice записано отрицательное число – приоритет процесса увеличен, положительное — уменьшен. 117. Доступ любой задачи к центральному процессу осуществляется через системные программы планировщика, диспетчера. Планирование это организация процессов в некоторую последовательность. Планировщик – программа ответственная за постановку процессов в очередь. Диспетчер – это программа, которая выбирает процесс из очереди, переводит его в активное состояние. Планирование диспетчеризации сокращенно называется планирование. Планирование процессов включает в себя решение следующих основных задач: 1) Определение момента времени для смены определяемого процесса; 2) Вывод процесса на выполнения из очереди готовых процессов; 3) Переключение контекстов в процессы; Первые две задачи решаются программными средствами, последняя – незначительной степени аппарата. Существует множество различных алгоритмов планирования процессов, рассмотрим подробнее две группы, наиболее чаще встречающихся алгоритмов: 1) Алгоритмы, основанные на квантование; 2) Алгоритмы, основанные на приоритетах. В соответствие с алгоритмами основанные на квантование, смена активного процесса происходит если: 1) Исчерпан квант процессорного времени; 2) Процесс завершился и покинул систему; 3) Процесс перешел в состояние ожидания; 4) Произошла ошибка. Процесс, который исчерпал свой квант, переводится в состояние готовность и ожидает, когда ему будет предоставлен новый квант процессорного времени. На дополнение в соответствие с определенными правилами выбирается новый процесс из очереди готовых, таким образом, не один процесс не занимает процессор на долго. Поэтому квантование широко используется в современной ОС. Кванты, выделяемые процессом, могут быть одинаковыми для всех процессов или различными, могут быть фиксированным величины или изменятся в разные периоды жизни процесса. Процессы, которые не полностью использовали выделенный квант, могут получить компенсацию в виде привилегий. По-разному могут организованными очереди процессов. На пример первый пришел первый обслужился(fee fo). Идея мультипрограммирования связанна с наличием очередей, процессор – основной ресурс многопроцессной системы. Использования ресурса осуществляется с помощью различных механизмов распределения ресурсов. 118. Функции ОС по управлению памятью Под памятью (memory) здесь подразумевается оперативная память компьютера. В отличие от памяти жесткого диска, которую называют внешней памятью (storage), оперативной памяти для сохранения информации требуется постоянное электропитание. Память является важнейшим ресурсом, требующим тщательного управления со стороны мультипрограммной операционной системы. Особая роль памяти объясняется тем, что процессор может выполнять инструкции протравы только в том случае, если они находятся в памяти. Память распределяется как между модулями прикладных программ, так и между модулями самой операционной системы. В ранних ОС управление памятью сводилось просто к загрузке программы и ее данных из некоторого внешнего накопителя (перфоленты, магнитной ленты или магнитного диска) в память. С появлением мультипрограммирования перед ОС были поставлены новые задачи, связанные с распределением имеющейся памяти между несколькими одновременно выполняющимися программами. Функциями ОС по управлению памятью в мультипрограммной системе являются: § отслеживание свободной и занятой памяти; § выделение памяти процессам и освобождение памяти по завершении процессов; § вытеснение кодов и данных процессов из оперативной памяти на диск (полное или частичное), когда размеры основной памяти не достаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место; § настройка адресов программы на конкретную область физической памяти. Помимо первоначального выделения памяти процессам при их создании ОС должна также заниматься динамическим распределением памяти, то есть выполнять запросы приложений на выделение им дополнительной памяти во время выполнения. После того как приложение перестает нуждаться в дополнительной памяти, оно может возвратить ее системе. Выделение памяти случайной длины в случайные моменты времени из общего пула памяти приводит к фрагментации и, вследствие этого, к неэффективному ее использованию. Дефрагментация памяти тоже является функцией операционной системы. Во время работы операционной системы ей часто приходится создавать новые служебные информационные структуры, такие как описатели процессов и потоков, различные таблицы распределения ресурсов, буферы, используемые процессами для обмена данными, синхронизирующие объекты и т. п. Все эти системные объекты требуют памяти»» В некоторых ОС заранее (во время установки) резервируется некоторый фиксированный объем памяти для системных нужд. В других же ОС используется более гибкий подход, при котором память для системных целей выделяется динамически. В таком случае разные подсистемы ОС при создании своих таблиц, объектов, структур и т. п. обращаются к подсистеме управления памятью с запросами. Защита памяти — это еще одна важная задача операционной системы, которая состоит в том, чтобы не позволить выполняемому процессу записывать или читать данные из памяти, назначенной другому процессу. Эта функция, как правило, реализуется программными модулями ОС в тесном взаимодействии с аппаратными средствами. 119. Один процесс в памяти Частный случай схемы с фиксированными разделами – работа менеджера памяти однозадачной ОС. В памяти размещается один пользовательский процесс. Остается определить, где располагается пользовательская программа по отношению к ОС – в верхней части памяти, в нижней или в средней. Причем часть ОС может быть в ROM (например, BIOS, драйверы устройств). Главный фактор, влияющий на это решение, – расположение вектора прерываний, который обычно локализован в нижней части памяти, поэтому ОС также размещают в нижней. Примером такой организации может служить ОС MS-DOS. Защита адресного пространства ОС от пользовательской программы может быть организована при помощи одного граничного регистра, содержащего адрес границы ОС. Оверлейная структура Так как размер логического адресного пространства процесса может быть больше, чем размер выделенного ему раздела (или больше, чем размер самого большого раздела), иногда используется техника, называемая оверлей (overlay) или организация структуры с перекрытием. Основная идея – держать в памяти только те инструкции программы, которые нужны в данный момент. Потребность в таком способе загрузки появляется, если логическое адресное пространство системы мало, например 1 Мбайт (MS-DOS) или даже всего 64 Кбайта (PDP-11), а программа относительно велика. На современных 32-разрядных системах, где виртуальное адресное пространство измеряется гигабайтами, проблемы с нехваткой памяти решаются другими способами (см. раздел "Виртуальная память"). Коды ветвей оверлейной структуры программы находятся на диске как абсолютные образы памяти и считываются драйвером оверлеев при необходимости. Для описания оверлейной структуры обычно используется специальный несложный язык (overlay description language). Совокупность файлов исполняемой программы дополняется файлом (обычно с расширением. odl), описывающим дерево вызовов внутри программы. Для примера, приведенного на рис. 8.5, текст этого файла может выглядеть так: A-(B,C)C-(D,E)Синтаксис подобного файла может распознаваться загрузчиком. Привязка к физической памяти происходит в момент очередной загрузки одной из ветвей программы. Оверлеи могут быть полностью реализованы на пользовательском уровне в системах с простой файловой структурой. ОС при этом лишь делает несколько больше операций ввода-вывода. Типовое решение – порождение линкером специальных команд, которые включают загрузчик каждый раз, когда требуется обращение к одной из перекрывающихся ветвей программы. Тщательное проектирование оверлейной структуры отнимает много времени и требует знания устройства программы, ее кода, данных и языка описания оверлейной структуры. По этой причине применение оверлеев ограничено компьютерами с небольшим логическим адресным пространством. Как мы увидим в дальнейшем, проблема оверлейных сегментов, контролируемых программистом, отпадает благодаря появлению систем виртуальной памяти. Заметим, что возможность организации структур с перекрытиями во многом обусловлена свойством локальности, которое позволяет хранить в памяти только ту информацию, которая необходима в конкретный момент вычислений. 120. Мультипрограммный режим с ФИКСИРОВАННЫМИ границами. Мультипрограммирование с фиксированными разделами (Multiprogramming with a fixed number of tasks) предполагает разделение адресного пространства на ряд разделов фиксированного раздела. В каждом разделе размещается один процесс. Наиболее простой и наименее эффективный режим MFT соответствует случаю, когда трансляция программ осуществляется в абсолютных адресах для соответствующего раздела. В этом случае, если соответствующий раздел занят, то процесс остается в очереди во внешней памяти даже в том случае, когда другие разделы свободны. Уменьшить фрагментацию при мультипрограммировании с фиксированными разделами можно, если загрузочные модули получать в перемещаемых адресах. Такой модуль может быть загружен в любой свободный раздел после соответствующей настройки. При мультипрограммировании с трансляцией в перемещаемых адресах имеются две причины фрагментации. Первая размер загруженного процесса меньше размера, занимаемого разделом (внутренняя фрагментация), вторая размер процесса в очереди больше размера свободного раздела, и этот раздел остается свободным (внешняя фрагментация). Для защиты памяти при мультипрограммировании с фиксированным разделами необходимы два регистра. Первый регистр верхней границы (наименьший адрес), второй регистр нижней границы (наибольший адрес). Прежде чем программа в разделе N начнет выполняться, ее граничные адреса загружаются в соответствующие регистры. В процессе работы программы все формируемые ею адреса контролируются на удовлетворение неравенства а < Адр. < б При выходе любого адреса программы за отведенные ей границы, работа программы прерывается. 121. Мультипрограммирование с переменными разделами. (multiprogramming with a variable number of tasks (MVT). Метод Multiprogramming with a Variable number of Tasks предполагает разделение памяти на разделы и использование загрузочных модулей в перемещаемых адресах, однако, границы разделов не фиксируются. 0ОС90 КбаРаздел 1П5П4П3П2П1Раздел 2Раздел 3Раздел 480 Кб Как следует из рисунка, в начальной фазе отсутствует фрагментация, связанная с тем, что размер очередного процесса меньше размера, занимаемого этим процессом раздела. На этой фазе причиной фрагментации является несоответствие размера очередного процесса и оставшегося участка памяти. По мере завершения работы программы освобождаются отдельные разделы. В том случае, когда освобождаются смежные разделы, границы между ними удаляются и разделы объединяются. 0ОС90 КбаРаздел 1П7П6П5100 КбРаздел 4 За счет объединения или слияния смежных разделов образуются большие фрагменты, в которых можно разместить большие программы из очереди. Таким образом, на фазе повторного размещения действуют те же причины фрагментации, что и для метода MFT. 3.2.4. Мультипрограммирование с переменными разделами и уплотнением памяти. Ясно, что метод Multiprogramming with a Variable number of Tasks порождает в памяти множество малых фрагментов, каждый из которых может быть недостаточен для размещения очередного процесса, однако суммарный размер фрагментов превышает размер этого процесса. Уплотнением памяти называется перемещение всех занятых разделов по адресному пространству памяти. Таким образом, чтобы свободный фрагмент занимал одну связную область. На практике реализация уплотнения памяти сопряжена с усложнением операционной системы и обладает следующими недостатками: 1. в тех случаях, когда мультипрограммная смесь неоднородна по отношению к размерам программ, возникает необходимость в частом уплотнении, что расходует ресурс процессорное время и компенсирует экономию ресурса памяти. 2. во время уплотнения все прикладные программы переводятся в состояние “ожидание”, что приводит к невозможности выполнения программ в реальном масштабе времени. Когда блоки доступной памяти располагаются между участками распределенной памяти, то говорят, что происходит фрагментация памяти. Хотя свободной памяти как правило бывает достаточно, что- бы удовлетворить запрос памяти, однако трудность заключается в том, что размеры отдельных участков свободной памяти недостаточны для этого, несмотря на то, что при их объединении получится дос- таточный объем памяти. На рис.18 показано, как при определенной последовательности обращения к процедурам "New" и "Dispose" может возникнуть такая ситуация. Когда блоки доступной памяти располагаются между участками распределенной памяти, то говорят, что происходит фрагментация памяти. Хотя свободной памяти как правило бывает достаточно, что- бы удовлетворить запрос памяти, однако трудность заключается в том, что размеры отдельных участков свободной памяти недостаточны для этого, несмотря на то, что при их объединении получится дос- таточный объем памяти.
В некоторых случаях фрагментация уменьшается, так как функ- ции динамического распределения памяти объединяют соседние участ- ки памяти. Например, пусть были выделены участки памяти A,B,C,и D /см. ниже/. Затем освобождаются участки B и C. Эти участки можно объединить, поскольку они располагаются рядом. Однако, если осво- бождаются участки B и D, то объединить их нельзя будет, поскольку между ними находится участок C который еще не освобожден: ________________________ ¦ ¦ ¦ ¦ ¦ ¦ A ¦ B ¦ C ¦ D ¦ ¦_____¦_____¦_____¦_____¦
Так как B и D освобождены, а C занят, то может возникнуть вопрос: "Почему бы Турбо Паскалю не переслать содержимое C в D и затем объединить B и C?" Трудность заключается в том, что ваша программа не будет "знать", что это пересылка произошла. Один из способов предотвращения большой фрагментации заклю- чается в том, чтобы всегда выделять одинаковые участки памяти. В этом случае все освобожденные участки могут использоваться при любых последующих запросах на выделение памяти и таким образом будет использована вся свободная память. Если нельзя использовать всегда одинаковый размер выделяемых участков, то следует ограни- читься только несколькими размерами. Иногда этого можно достиг- нуть путем объединения нескольких запросов на выделение небольших участков в один запрос на выделен   ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Что вызывает тренды на фондовых и товарных рынках Объяснение теории грузового поезда Первые 17 лет моих рыночных исследований сводились к попыткам вычислить, когда этот... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|