
|
|
Лекции по курсу «Информатика»Стр 1 из 16Следующая ⇒ Лекции по курсу «Информатика» ДЕ1. Понятие информации. Общая характеристика процессов сбора, передачи, обработки и накопления информации Лекция 1.1. Основные задачи информатики Место информатики в современном научном знании
В жизни современного человека слово «информация» очень распространено и часто используется в разных контекстах. Информацией обычно называют любые сведения, которые кого-либо интересуют, которые мы получаем или передаем. Например, мы говорим: «В результате научных исследований нами получена информация о …» или «Из книг мы информированы о …, «По телевидению была передана информация о …». Фундаментальной чертой цивилизации является рост производства и потребления информации во всех отраслях человеческой деятельности. Вся жизнь человека, так или иначе, связана с получением, накоплением, обработкой, передачей информации. Практически в любой деятельности человека: в процессе чтения книг, просмотра телепередач, в разговоре мы получаем и обрабатываем информацию. Начиная с ХVII в. объем научной информации удваивался, примерно, каждые 20 лет, в настоящее время он удваивается в 5 – 6 лет и тенденция ускорения сохраняется. Одной из важнейших проблем человечества является лавинообразный рост потока информации в любой отрасли жизнедеятельности. Подсчитано, что современный специалист должен тратить около 80% своего рабочего времени, чтобы уследить за всеми новыми работами в его области деятельности. Увеличение объема используемой человеком информации и растущий спрос на нее обусловили появление отрасли знаний, связанной с автоматизацией обработки информации – информатики.
Лекция 1.2. Сигналы. Данные. Информация Понятия данные и информация Термин «информация» используется во многих науках и во многих сферах человеческой деятельности. Он происходит от латинского слова «informatio», «сведения, разъяснения, изложение». С точки зрения науки «Информатики», «информация» является первичным, а, следовательно, неопределенным понятием. Так же как понятия «точка» в математике, «тело» в механике, «поле» в физике. Понятию «информация» не возможно дать строгое определение, но можно описать его через проявляемые свойства. Как известно, в материальном мире все физические объекты, окружающие нас, являются либо телами, либо полями. Физические объекты, взаимодействуя друг с другом, порождают сигналы различных типов. В общем случае любой сигнал – это изменяющийся во времени физический процесс. Такой процесс может иметь различные характеристики. Та из них, которая используется для представления данных, называется параметром сигнала. Если параметр сигнала принимает ряд последовательных, конечных во времени, значений, то сигнал называется дискретным. Если параметр сигнал – непрерывная во времени функция, то сигнал называется непрерывным. Сигналы, в свою очередь, могут порождать в физических телах изменения свойств. Это явление называется регистрацией сигналов. Сигналы, зарегистрированные на материальном носителе, называются данными. Существует большое количество физических методов регистрации сигналов на материальных носителях. Это могут быть механические воздействия, перемещения, изменения формы или магнитных, электрических, оптических параметров, химического состава, кристаллической структуры. В соответствии с методами регистрации, данные могут храниться и транспортироваться на различных носителях. Наиболее часто используемый и привычный носитель – бумага; сигналы регистрируются путем изменения ее оптических свойств. Сигналы могут быть зарегистрированы и путем изменения магнитных свойств полимерной ленты с нанесенным ферромагнитным покрытием, как это делается в магнитофонных записях, и путем изменения химических свойств в фотографии. Данные несут информацию о событии, но не являются самой информацией, так как одни и те же данные могут восприниматься (отображаться или интерпретироваться) по-разному. Например, текст, написанный на русском языке (т.е. данные), даст различную информацию человеку, знающему алфавит и язык, и человеку, не знающему их. Чтобы получить информацию, имея данные, к ним необходимо применить методы, которые преобразуют данные в понятия, воспринимаемые человеческим сознанием. Методы, в свою очередь, тоже различны. Например, человек, знающий язык и алфавит, применяет адекватный метод, читая русский текст. Соответственно, человек, не знающий русского языка и алфавита, применяет неадекватный метод, пытаясь понять русский текст. Таким образом, можно считать, что информация – это продукт взаимодействия данных и адекватных методов. Или иными словами: информация – это используемые данные. Информация не является статическим объектом, она появляется и существует в момент слияния методов и данных, а все прочее время она находится в форме данных. Момент слияния данных и методов называется информационным процессом (рис. 1.1). Человек воспринимает первичные данные различными органами чувств (их у нас пять – зрение, слух, осязание, обоняние, вкус), и на их основе сознанием могут быть построены вторичные абстрактные (смысловые, семантические) данные. Взаимо- Регистрация действия сигналов Методы
Рис. 1.1. Формирование информации
Т.о. первичная информация может существовать в виде рисунков, фотографий, звуковых, вкусовых ощущений, запахов. Вторичная – в виде чисел, символов, текстов, чертежей, радиоволн, магнитных записей.
Свойства информации Понятие «информация» имеет большое количество разнообразных свойств, но для дисциплины информатика наиболее важными являются следующие свойства: 1. Дуализм характеризуется двойственностью информации. С одной стороны, информация объективна в силу объективности данных. С другой стороны – субъективна, в силу субъективности применяемых методов. Иными словами, методы могут вносить в большей или меньшей степени субъективный фактор и т.о. влиять на информацию в целом. Например, два человека читают одну и ту же книгу и получают подчас весома разную информацию, хотя прочитанный текст, т.е. данные, были одинаковы. Более объективная информация применяет методы с меньшим субъективным элементом. 2. Полнота информации характеризует степень достаточности данных для принятия решения или создания новых данных на основе имеющихся. Неполный набор данных оставляет большую долю неопределенности, т.е. большое число вариантов выбора, а это потребует применения дополнительных методов, например, экспертных оценок, бросания жребия и т.п. Избыточный набор данных затрудняет доступ к нужным данным, создает повышенный информационный шум, что также вызывает необходимость дополнительных методов, например, фильтрацию, сортировку. И неполный и избыточный наборы данных затрудняют получение информации и принятие адекватного решения. 3. Достоверность – это свойство, характеризующее степень соответствия информации реальному объекту с необходимой точностью. Измеряется достоверность информации доверительной вероятностью необходимой точности, т.е. вероятностью того, что отображаемое информацией значение параметра отличается от истинного значения этого параметра в пределах необходимой точности. 4. Адекватность информации выражает степень соответствия создаваемого на основе информации образа реальному объекту, процессу, явлению. Адекватность информации может выражаться в трех формах: - Синтаксическая адекватность отображает формально-структурные характеристики информации и не затрагивает ее смыслового содержания. На синтаксическом уровне учитываются тип носителя и способ представления информации, скорость передачи и обработки, размеры кодов представления информации, надежность и точность преобразования этих кодов и т.п. Информацию, рассматриваемую только с синтаксических позиций, обычно называют данными, т.к. при этом не имеет значения смысловая сторона. Эта форма способствует восприятию внешних, структурных характеристик; - Семантическая (смысловая) адекватность определяет степень соответствия образа объекта и самого объекта и предполагает учет смыслового содержания информации. Эта форма служит для формирования понятий и представлений, выявления смысла, содержания информации и ее обобщения; - Прагматическая (потребительская) адекватность отражает отношение информации и ее потребителя, соответствие информации цели управления, которая на ее основе реализуется. Прагматические свойства информации проявляются только при наличии единства информации (объекта), пользователя и цели управления. Прагматический аспект рассмотрения связан с ценностью, полезностью использования информации при выработке потребителем решения для достижения своей цели. 5. Доступность информации, Информация должно быть доступна восприятию пользователя. Доступность обеспечивается выполнением соответствующих процедур ее получения и преобразования. Например, в ИС информация преобразовывается к доступной и удобной для восприятия пользователя форме. 6. Актуальность информации. Информация существует во времени, т.к. существуют во времени все информационные процессы. Информация, актуальная сегодня, может стать совершенно ненужной по истечении некоторого времени. Например, программа телепередач на нынешнюю неделю будет неактуальна для многих телезрителей на следующей неделе.
Некоторые системы счисления
В позиционной системе счисления число может быть представлено в виде суммы произведения коэффициентов на степени основания системы счисления: AnAn-1An-2…A1A0,A-1A-2…=An*Bn + An-1*Bn-1 + An-2*Bn-2 + … + A1*B1 + A0*B0 + A-1*B-1 + A-2*B-2 + …
(здесь знак «точка» отделяет целую часть от дробной; знак «звездочка» используется для обозначения операции умножения; B – основание системы счисления; A – коэффициенты). Таким образом, значение каждого знака в числе зависит от позиции, которую занимает знак в записи числа. Именно поэтому такие системы счисления называют позиционными (система счисления обозначается индексом в скобках справа от числа). Примеры: 23,43(10)= 2*101 + 3*100 + 4*10-1 + 3*10-2 = 23,43(10) 692(10) = 6*102 + 9*101 + 2*100 = 692(10) 1101(2)= 1*23 +1*22 + 0*21 + 1*20 = 13(10) 112(3) = 1*32 + 1*31 + 2*30 = 13(10) 341,5(8) = 3*82 + 4*81 + 1*80 + 5*8-1 =225,625(10) A1F,4(16) = A*162 + 1*161 + F*160 + 4*16-1 = 2591,25(10).
Кроме позиционных систем счисления существуют такие, в которых значение знака не зависит от того места, которое он занимает в числе. Такие системы счисления называются непозиционными. Наиболее известным примером непозиционной системы является римская. В этой системе используется 7 знаков (I, V, X, L, C, D, M), которые соответствуют следующим величинам: I (1), V(5), X (10), L (50), C (100), D (500), M (1000).
Вопросы для самоконтроля 1. Что понимается под системой счисления? 2. Какие системы счисления вы знаете? 3. В чем отличие позиционной системы счисления от непозиционной? 4. Какие системы счисления используются в вычислительной технике, и в чем заключается преимущество их использования? 5. Что называется основанием системы счисления? 6. Каковы способы перевода чисел из одной системы счисления в другую? 7. Как выглядят таблицы сложения и умножения в двоичной системе счисления? Структуры данных Автоматизированная обработка больших объемов данных становится проще, если данные упорядочены (структурированы). Применяются следующие структуры данных: Линейная структура данных (список) – это упорядоченная структура, в которой адрес данного однозначно определяется его номером (индексом). Пример: список учебной группы, дома, стоящие на одной улице. В списках, как известно, новый элемент начинается с новой строки. Если элементы располагаются в строчку, то вводится разделительный знак между элементами. Поиск осуществляется по разделителям (например, чтобы найти десятый элемент, надо отсчитать девять разделителей). Если элементы списка одной длины, структура называется вектором данных, разделители не требуются. При длине одного элемента d, зная номер элемента n, его начало определяется соотношением d(n-1). Табличная структура данных – это упорядоченная структура, в которой адрес данного однозначно определяется двумя числами – номером строки и номером столбца, на пересечении которых находится ячейка с исходным элементом. Если элементы располагаются в строчку, вводятся два разделительных знака – между элементами строки и между строками. Поиск, аналогично линейной структуре осуществляется по разделителям. Если элементы таблицы одной длины, структура называется матрицей данных, разделители в ней не требуются. При длине одного элемента d, зная номер строки m и номер столбца n, а также строк и столбцов M, N, найдем адрес его начала: d[N(m – 1) + (n – 1)]. Таблица может быть трехмерной, тогда три числа характеризуют положение элемента, а может быть n – мерной.
MS Word MS Excel …
Иерархическая структура – это структура, в которой адрес каждого элемента определяется путем (маршрутом доступа), идущим от вершины структуры к данному элементу. Иерархическую структуру образуют, например, почтовые адреса, файловая система компьютера: Линейная и табличная структуры более просты, чем иерархическая, но, если в линейной структуре появляется новый элемент, то упорядоченность сбивается. Например, если в списке студентов появляется новый человек, расположенный по алфавиту список нарушается. В иерархической структуре введение нового элемента не нарушает структуры дерева. Недостатком является трудоемкость записи адреса и сложность упорядочивания. H:\Stud\tsi11\Ivanov\Text\my_file.doc Россия \ Ростовская область \ Ростов – на – Дону \ ул. Б. Садовая \дом 1\кв. 11
Хранение данных При хранении данных решаются две задачи: - как сохранить данные; - как обеспечить быстрый удобный доступ к ним. В компьютерных технологиях единицей хранения данных является объект переменной длины, называемый файлом. Файл – это поименованная область на внешнем носителе, содержащая данные определенной длины, обладающая собственным именем. Современные файлы могут содержать данные различных типов. Например, в текстовом файле могут содержаться графические вставки, таблицы и пр. Имя файла фактически несет в себе адресные функции в иерархических структурах. Имя файла может иметь расширение, в котором хранятся сведения о типе данных. При автоматической обработке по типу файла может запускаться приложение (программа), работающее с ним. Для доступа к файлам, которых на жестком диске может быть сотни тысяч, используется определенное ПО, предназначенное для централизованного управления данными. Системы управления данными называются файловыми системами. Именно файловая система решает задачи распределения внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным. Благодаря этому, работа с файлами во многом стала напоминать работу с обычными документами. Информация любого типа хранится в виде файлов, выступающих в роли логически завершенных совокупностей данных. Для пользователя файл является основным и неделимым элементом хранения данных, который можно найти, изменить, удалить, сохранить или переслать, но только целиком. С физической точки зрения, файл – это всего лишь последовательность байтов. Способ использования или отображения этой последовательности определяется типом файла – текстовый, звуковой, исполняемый модуль программы и т.п. Для хранения различных видов информации необходимо использовать по-разному устроенные файлы. Способ организации данных (структура файла) называется форматом. Файловая система – это часть ОС компьютера и поэтому всегда несет на себе отпечаток свойств конкретной ОС. Некоторые форматы файлов стандартизированы и должны поддерживаться любой ОС и работающими в ней приложениями (например, графические файлы.GIF или JPEG). Наряду с этим всегда имеются форматы, специфичные только для данной системы (например, исполняемые файлы MS DOS или Windows). Есть форматы, разработанные для конкретных приложений, работающих под управлением данной ОС (например, формат.xls, используемый MS Excel). В некоторых случаях при разработке приложений программистам приходится создавать новые форматы. Структура файла может быть простой. Например, текст может сохраняться в виде последовательности байтов, прямо соответствующих формату ASCII. Но в большинстве случаев вместе с данными приходится сохранять и дополнительную информацию. Например, особенности форматирования текста (размеры символов, шрифты и т.п.). Процесс форматирования можно рассматривать, как процедуру придания некоторых свойств фрагменту текста. Поэтому, для сохранения форматирования нужно иметь два типа кодов, для обозначения блока текста, к которому применяется форматирование, и для указания свойства (типа форматирования). Если система служебных кодов определена, то для сохранения текста требуется вставка в него управляющих символов. Например, надо сохранить таблицу из шести чисел, имеющую две строки и три столбца (2 х 3):
Для хранения чисел используются ячейки фиксированного размера (например, два байта). Поэтому, если в файл записано 6 чисел, то при чтении данных из него нужно извлечь шесть раз по 2 байта. Т.к. память ПК линейна, то возникает задача, как сохранить не только сами числа, но и структуру таблицы. Очевидно, что если таблица запоминается построчно, то основным параметром, определяемым ее вид, является количество чисел в строке (т.е. количество столбцов). Поэтому, договариваемся, что первое число в файле – это длина строки таблицы, затем записывается количество строк, а далее построчно сохраняются числовые элементы таблицы. Тип данных, представляющий их, также должен быть оговорен. Число строк необходимо запомнить, чтобы знать, где остановиться при чтении информации. Таблица может быть записана в файл в виде следующей последовательности: Сформулированными правилами должна будет пользоваться не только программа, сохраняющая таблицу, но и любая другая, которой потребуется прочесть данные из таблицы, т.к. формат файла определяет способ правильной интерпретации хранимых данных. Размещение в начале файла блока служебной информации часто используется в многочисленных форматах, например, в файлах баз данных или графических данных.
Часто заголовок файла включает идентификатор формата файла. Программы, предназначенные для просмотра файлов определенного типа, начинают работу с чтения служебной информации и проверки возможности восприятия формата файла. Современные программные системы позволяют одновременно включать в файл данные разных видов, а это требует разработки очень сложных форматов. Придумать простой формат, который позволил бы хранить множество видов данных вместе, невозможно. Поэтому, например, для хранения документов в MS Office строятся так называемые структурированные хранилища – фактически файловые системы, спрятанные в одном файле. Наличие разных форматов для хранения данных одного и того же типа затрудняет переносимость их из среды одного приложения (программы) в среду другого. Проблема обычно решается использованием специальных программ, называемых конверторами. Вопросы для самоконтроля 1. Как представляются числа в памяти компьютера? 2. Как представляются символьные и текстовые данные? 3. Как представляются звуковые данные? 4. Как представляются графические данные? 5. Какими способами формируются графические изображения? 6. Что вы можете рассказать о моделях RGB и CMYK? 7. Что вы можете сказать об особенностях хранения данных различных типов? История развития средств ВТ Слово «компьютер» означает «вычислитель», т.е. устройство для вычислений. Потребность в автоматизации обработки данных, в том числе и вычислений, возникла очень давно. Многие тысячи лет назад для счета использовались пальцы, счетные палочки, камешки, веревки с узелками. Более 1500 лет назад для вычислений стали использовать абак (разновидностью которого являются русские счеты). В 1642 г. Блэз Паскаль изобрел устройство, механически выполняющее сложение чисел, а в 1673 г. Готфрид Вильгельм Лейбниц сконструировал арифмометр, позволяющий механически выполнять четыре арифметических действия. Начиная с XIX в. арифмометры получили очень широкое применение. На них выполняли даже артиллерийской стрельбы. Существовала и специальная профессия – счетчик – человек, работающий с арифмометром, быстро и точно соблюдающий определенную последовательность инструкций (такая последовательность инструкций получила название «программа»). Но многие расчеты производились медленно – даже десятки счетчиков должны были работать несколько недель и месяцев. Причина проста – при таких расчетах выбор выполняемых действий и запись результатов производились человеком, а скорость его работы весьма ограничена. В первой половине XIX в. английский математик Чарльз Бэббидж попытался построить универсальное вычислительного устройство – аналитическую машину - которая должна была выполнять вычисления без участия человека. Для этого она должна была уметь исполнять программы, вводимые с помощью перфокарт (карт из плотной бумаги с информацией, наносимой с помощью отверстий, которые придумал Жакард, они в то время уже широко употреблялись в ткацких станках), и иметь «склад» для запоминания данных и промежуточных результатов (память). Бэббидж не смог довести до конца работу по созданию аналитической машины – она оказалась слишком сложной для техники того времени. Однако, он разработал все основные идеи. В 1943 г. американец Говард Эйкен с помощью работ Бэббиджа на основе электромеханических реле смог построить на одном из предприятий фирмы IBM такую машину под названием «Марк-1». Еще раньше идеи Бэббиджа были переоткрыты немецким инженером Конрадом Цузе, который в 1941 г. построил аналогичную машину. К тому времени, потребность в автоматизации вычислений (в том числе и для военных нужд – баллистики, криптографии) уже стала настолько велика, что над созданием машин подобного типа одновременно работало несколько групп исследователей. Начиная с 1943 г. группа специалистов под руководством Джона Мочли и Преспера Экерта в США начала конструировать машину уже на основе электронных ламп, а не реле. Их машина, названная ENIAC, работала в тысячу раз быстрее, чем «Марк-1», однако для задания программы приходилось в течение нескольких часов или даже дней подсоединять нужным образом провода. Чтобы упростить процесс задания программы, Мочли и Экерт стали конструировать машину, которая бы могла хранить программу в своей памяти. В 1945 г. к работе был привлечен знаменитый математик Джон фон Нейман, который подготовил доклад об этой машине, в котором ясно и просто сформулировал общие принципы функционирования универсальных вычислительных устройств, и разослал его многим ученым. Первый компьютер, в котором были воплощены принципы фон Неймана, был построен в 1949 г. английским исследователем Морисом Уилксом.
Эволюция ЭВМ В развитии вычислительной техники принято выделять пять поколений ЭВМ. § ЭВМ 1 поколения. ЭВМ, элементной базой которой являлись лампы. Она обладала малым быстродействием и объемом памяти, неразвитой операционной системой, программированием на машинном языке. Использовалась в 50-е годы («Урал», БЭСМ). § ЭВМ II поколения. ЭВМ, элементной базой которой являются полупроводники. Она имеет изменяемый состав внешних устройств, использует языки программирования высокого уровня и принцип библиотечных программ. Наиболее большое применение нашла в 60-е годы (БЭСМ-6, М-220, «Минск-32», «Весна»). § ЭВМ III поколения. ЭВМ, характерными признаками которой являются интегральная элементная база, развитая конфигурация внешних устройств с использованием стандартных средств сопряжения, высокое быстродействие и большой объем основной и внешней памяти, развитая операционная система, обеспечивающая работу в мультипрограммном режиме. Появление первых ЭВМ этого поколения относится к началу 70-х годов (ЕС ЭВМ, СМ ЭВМ, IBM). § ЭВМ IV поколения. ЭВМ, характерными признаками которой являются элементная база на основе больших интегральных схем (БИС), виртуальная память, многопроцессорность, параллелизм выполнения операций, развитые средства диалога. Появилась в середине 80-х годов («Эльбрус-2», ПЭВМ ЕС1841, ЕС1842, IBM PC). § ЭВМ V поколения. ЭВМ, характерными признаками которой являются использование в качестве элементной базы сверхбольших интегральных схем (СБИС), применение принципа «управления потоками данных» (в отличие от принципа фон Неймана «управление потоками команд»), использование новых решений в архитектуре вычислительной системы и принципов искусственного интеллекта. Вопросы для самоконтроля 1. Какие ключевые события из истории развития вычислительной техники вам известны? 2. По каким признакам ЭВМ относят к тому или иному поколенияю? 3. Каковы совокупные признаки ЭВМ 1-, 2-, 3-, 4-го поколений?
Элемент памяти Основой любого компьютера является ячейка памяти, которая может хранить данные или команды. Основой любой ячейки памяти является функциональное устройство, триггер (или защелка), которое может по команде принять или выдать один двоичный бит, а, главное, сохранять его. Триггер строится на основе базового набора логических схем (рис. 2.1.3.).
  
Рис. 2.1.3. Схема триггера в состоянии хранения бита информации.
1 и 2 – это два элемента «логическое НЕ», 3 и 4 – два элемента «логическое И-НЕ», которые представляют собой комбинацию логических элементов «И» и «НЕ». Такой элемент на входе выполняет операцию логического умножения, результат которой инвертируется на выходе логическим отрицанием. Триггер имеет два выхода Q и Для записи в триггер 1 на вход S подается 1 (рис.2.1.4.). На выходе схемы 1 получится 0, который обеспечит на выходе схемы 3 единицу. С выхода схемы 3 единица поступит на вход схемы 4, на выходе которой значение изменится на ноль (
   
S 0 1 Q
0 1 0
Рис. 2.1.4. Запись в триггер единицы.
Регистры Триггер служит основой для построения функциональных узлов, способных хранить двоичные числа, осуществлять их синхронную параллельную передачу и запись, а также выполнять с ними некоторые специальные операции. Такие функциональные узлы называются регистрами.
Регистр – это набор триггеров, число которых определяет разрядность регистра. Разрядность регистра кратна восьми битам: 8-, 16-, 32-, 64- разрядные регистры. Кроме этого, в состав регистра входят схемы управления его работой. Регистр содержит n триггеров, образующих n разрядов (рис. 2.1.6.). Перед записью информации регистр обнуляется подачей единичного сигнала на вход «сброс». Запись информации в регистр производится синхронно подачей единичного сигнала «Запись». Этот сигнал открывает входные вентили (схемы «логическое И»), и на тех входах x1, …, xn, где присутствует единичный сигнал, произойдет запись единицы. Чтение информации из регистра также производится синхронно, подачей сигнала «Чтение» на выходные вентили. Обычно регистры содержат дополнительные схемы, позволяющие организовать такие операции, как сдвиг информации (регистр сдвига) и подсчет поступающих единичных сигналов (регистры счетчики).
Центральный процессор Центральный процессор (ЦП) – функционально-законченное программно-управляемое устройство обработки информации, выполненное на одной или нескольких СБИС. В современных ПК разных фирм применяются процессоры двух основных архитектур: · Полная система команд переменной длины – Complex Instruction Set Computer (CISC); · Сокращенный набор команд фиксированной длины – Reduced Instruction Set Computer (RISC). Весь ряд процессоров фирмы Intel, устанавливаемых в ПК IBM имеют архитектуру CISC, а процессоры Motorola, используемые фирмой Apple для своих ПК, имеют архитектуру RISC. Обе архитектуры имеют свои достоинства и недостатки. CISC - процессоры имеют обширный набор команд (до 400), из которых программист может выбрать, наиболее подходящую в данном случае, команду. Недостатком является то, что большой набор команд усложняет внутреннее устройство управления процессором, увеличивает время исполнения команды на микропрограммном уровне. Команды имеют различную длину и время исполнения. RISC – архитектура имеет ограниченный набор команд и каждая команда выполняется за один такт работы процессора. Небольшое число команд упрощает устройство управления процессором. К недостаткам можно отнести то, что если требуемой команды в наборе нет, программист вынужден реализовать ее с помощью нескольких команд из имеющегося набора, увеличивая размер программного кода. Упрощенная схема процессора, отражающая основные особенности архитектуры микро - уровня, приведена на рис. 2.2.1. Наиболее сложным функциональным устройством процессора является устройство управления выполнением команд. Оно содержит: · Буфер команд, который хранит одну или несколько очередных команд программы; читает следующие команды из запоминающего устройства, пока выполняется очередная команда, уменьшая время ее выборки из памяти; · Дешифратор команд расшифровывает код операции очередной команды и преобразует его в адрес начала микропрограммы, которая реализует исполнение команды;
©2015- 2024 zdamsam.ru Размещенные материалы защищены законодательством РФ.
|



 Мой компьютер
Мой компьютер

 Диск С: Диск D: Диск H:
Диск С: Диск D: Диск H:




 1
1

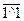 =0). Этот ноль на входе схемы 3 будет поддерживать сигнал на выходе в состоянии единицы. Теперь можно снять единичный сигнал на входе S, на выходе схемы 3 все равно будет высокий уровень, т.е. триггер сохраняет записанную в него 1. Единичный сигнал на входе 3 необходимо удерживать некоторое время, пока на выходе схемы 4 не появится нулевой сигнал. Затем на входе S вновь устанавливается нулевой сигнал, но триггер поддерживает единичный сигнал на выходе Q, т.е. сохраняет записанную в него единицу. Точно также, подав единичный сигнал на вход R, можно записать в триггер ноль.
=0). Этот ноль на входе схемы 3 будет поддерживать сигнал на выходе в состоянии единицы. Теперь можно снять единичный сигнал на входе S, на выходе схемы 3 все равно будет высокий уровень, т.е. триггер сохраняет записанную в него 1. Единичный сигнал на входе 3 необходимо удерживать некоторое время, пока на выходе схемы 4 не появится нулевой сигнал. Затем на входе S вновь устанавливается нулевой сигнал, но триггер поддерживает единичный сигнал на выходе Q, т.е. сохраняет записанную в него единицу. Точно также, подав единичный сигнал на вход R, можно записать в триггер ноль.

 R 1
R 1 




 АЛУ
АЛУ ((__lxGc__=window.__lxGc__||{'s':{},'b':0})['s']['_228467']=__lxGc__['s']['_228467']||{'b':{}})['b']['_699615']={'i':__lxGc__.b++};
((__lxGc__=window.__lxGc__||{'s':{},'b':0})['s']['_228467']=__lxGc__['s']['_228467']||{'b':{}})['b']['_699615']={'i':__lxGc__.b++};




