|
|
Лекция № 7. Базовые отношения
Как мы уже знаем, базы данных – это как бы своеобразный контейнер, основное предназначение которого заключается в хранении данных, представленных в виде отношений. Необходимо знать, что в зависимости от своей природы и структуры, отношения делятся на: 1) базовые отношения; 2) виртуальные отношения. Отношения базового вида содержат только независимые данные и не могут быть выражены через какие‑либо другие отношения баз данных. В коммерческих системах управления базами данных базовые отношения обычно называются просто таблицами в отличие от представлений, соответствующих понятию виртуальных отношений. В данном курсе мы будем довольно подробно рассматривать только базовые отношения, основные приемы и принципы работы с ними.
Базовые типы данных
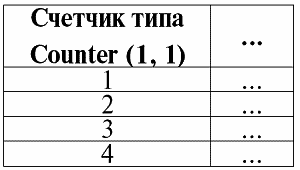
Типы данных, как и отношения, делятся на базовые и виртуальные. (О виртуальных типах данных мы поговорим чуть позже, посвятим этой теме отдельную главу.) Базовые типы данных – это любые типы данных, заданные в системах управления базами данных изначально, т. е. присутствующие там по умолчанию (в отличие от пользовательского типа данных, который мы проанализируем сразу после прохождения типа данных базового). Прежде чем перейти к рассмотрению собственно базовых типов данных, перечислим, каких типов данные вообще бывают: 1) числовые данные; 2) логические данные; 3) строковые данные; 4) данные, определяющие дату и время; 5) идентификационные данные. В системах управления базами данных по умолчанию ввели несколько наиболее распространенных типов данных, каждый из которых принадлежит какому‑то из перечисленных типов данных. Назовем их. 1. В числовом типе данных выделяют: 1) Integer. Этим ключевым словом обычно обозначают целый тип данных; 2) Real, соответствующий вещественному типу данных; 3) Decimal (n, m). Это десятичный тип данных. Причем в обозначении n – это число, фиксирующее общее количество знаков числа, а m показывает, сколько символов из них стоит после десятичной точки; 4) Money или Currency, введен специально для удобного представления данных денежного типа данных. 2. В логическом типе данных обычно выделяют только один базовый тип, это Logical. 3. Строковый тип данных насчитывает четыре базовых типа (имеются в виду, разумеется, наиболее распространенные): 1) Bit (n). Это строки бит с фиксированной длиной n; 2) Varbit (n). Это тоже строки бит, но с переменной длиной, не превышающей n бит; 3) Char (n). Это строки символов с постоянной длиной n; 4) Varchar (n). Это строки символов, с переменной длиной, не превышающей n символов. 4. Тип дата и время включает в себя следующие базовые типы данных: 1) Date – тип данных даты; 2) Time – тип данных, выражающих время суток; 3) Date‑time – тип данных, выражающий одновременно и дату, и время. 5. Идентификационный тип данных содержит в себе только один включенный по умолчанию в систему управления базами данных тип, и это GUID (глобальный уникальный идентификатор). Необходимо заметить, что все базовые типы данных могут иметь варианты различного по диапазону представления данных. Приведем пример: вариантами четырехбайтового типа данных integer могут быть восьмибайтовые (bigint) и двухбайтовые (smallint) типы данных. Поговорим отдельно о базовом типе данных GUID. Этот тип предназначен для хранения шестнадцатибайтовых значений так называемого глобального уникального идентификатора. Все различные значения этого идентификатора генерируются автоматически при вызове специальной встроенной функции NewId (). Это обозначение происходит от полного английского словосочетания New Identification, что в переводе буквально и означает «новое значение идентификатора». Каждое генерируемое на конкретном компьютере значение идентификатора уникально в пределах всех производимых компьютеров. GUID‑идентификатор используется, в частности, для организации репликации баз данных, т. е. при создании копий каких‑то уже имеющихся баз данных. Такие GUID‑идентификаторы могут быть использованы и разработчиками баз данных наравне с другими базовыми типами. Промежуточное положение между типом GUID и другими базовыми типами занимает еще один специальный базовый тип – тип счетчика. Для обозначения данных этого типа используется специальное ключевое слово Counter (x0, ∆x), что в буквальном переводе с английского и означает «счетчик». Параметр x0 задает начальное значение, а ∆ x – шаг приращения. Значения этого типа Counter обязательно являются целочисленными. Необходимо отметить, что работа с этим базовым типом данных включает в себя ряд очень интересных особенностей. Например, значения этого типа Counter не задаются, как мы привыкли при работе со всеми другими типами данных, они генерируются по требованию, почти как для значений типа глобального уникального идентификатора. Также необычно, что тип счетчика может быть задан только при определении таблицы и только тогда! В программном коде этот тип использовать нельзя. Еще нужно помнить, что и при определении таблицы тип счетчика может быть задан исключительно для одного столбца. Значения данных типа счетчик генерируются автоматически при вставки строк. Причем эта генерация проводится без повторений, так что счетчик всегда будет уникально идентифицировать каждую строку. Но это создает некоторые неудобства при работе с таблицами, содержащими данные типа счетчик. Если, например, данные в отношении, заданном таблицей, изменятся и их придется удалить или поменять местами, значения счетчика легко могут «спутать карты», особенно если работает неопытный программист. Приведем пример, иллюстрирующий подобную ситуацию. Пусть дана следующая таблица, представляющая какое‑то отношение, в которую введены четыре строки:
Счетчик каждой новой строке автоматически дал уникальное имя. И пусть теперь необходимо удалить вторую и четвертую строчки из таблицы, а потом добавить одну дополнительную строчку. Эти операции приведут к следующему преобразованию исходной таблицы:
Таким образом, счетчик удалил вторую и четвертую строчки вместе с их уникальными именами, а не стал «переприсваивать» их новым строчкам, как можно было ожидать. Причем изменить вручную значение счетчика система управления базами данных никогда не позволит, так же как она не позволит объявить в одной таблице несколько счетчиков одновременно. Обычно счетчик используется как суррогатный, т. е. искусственный ключ в таблице. Интересно знать, что уникальных значений четырехбайтового счетчика при скорости генерации одно значение в секунду хватит более чем на 100 лет. Покажем, как это подсчитано:
1 год = 365 дней * 24 ч * 60 с * 60 с < 366 дней * 24 ч * 60 с * 60 с < 225 с. 1 секунда > 2‑25 год. 24*8 значений / 1 значение/секунду = 232 с > 27 год > 100 лет.
Пользовательский тип данных
Пользовательский тип данных отличается от всех базовых типов тем, что он не был изначально вшит в систему управления базами данных, он не был описан как тип данных по умолчанию. Этот тип может создать для себя любой пользователь и программист баз данных в соответствии с собственными запросами и требованиями. Таким образом, пользовательский тип данных – это подтип некоторого базового типа, т. е. это базовый тип с некоторыми ограничениями множества допустимых значений. В записи на псевдокоде, пользовательский тип данных создается с помощью следующего стандартного оператора:
Create subtype имя подтипа Type имя базового типа As ограничение подтипа;
Итак, в первой строчке мы должны указать имя нашего нового, пользовательского типа данных, во второй – какой из имеющихся базовых типов данных мы взяли за образец, создавая собственный, и, наконец, в третьей – те ограничения, которые нам необходимо добавить в уже имеющиеся ограничения множества значений базового типа данных – образца. Ограничения подтипа записываются как условие, зависящее от имени определяемого подтипа. Чтобы лучше понять принцип действия оператора Create, рассмотрим следующий пример. Пусть нам необходимо создать свой специализированный тип данных, допустим, для работы на почте. Это будет тип для работы с данными вида чисел почтового индекса. От обычных десятичных шестизначных чисел наши числа будут отличаться тем, что они могут быть только положительными. Запишем оператор, для создания нужного нам подтипа:
Create subtype Почтовый индекс Type decimal (6, 0) As Почтовый индекс > 0.
Почему мы взяли именно decimal (6, 0)? Вспоминая обычный вид индекса, мы видим, что такие числа должны состоять из шести целых чисел от нуля до девяти. Именно поэтому мы и взяли в качестве базового типа данных – десятичный тип. Любопытно заметить, что в общем случае условие, накладываемое на базовый тип данных, т. е. ограничение подтипа, может содержать логические связки not, and, or и вообще быть выражением любой произвольной сложности. Определенные таким образом пользовательские подтипы данных могут беспрепятственно использоваться наряду с другими базовыми типами данных и в программном коде, и при определении типов данных в столбцах таблицы, т. е. базовые типы данных и пользовательские при работе с ними совершенно равноправны. В визуальной среде разработки они появляются в списках допустимых типов вместе с другими базовыми типами данных. Вероятность того, что нам при проектировании новой собственной базы данных может понадобиться недокументированный (пользовательский) тип данных, достаточно велика. Ведь по умолчанию в систему управления базами данных вшиты только самые общие типы данных, пригодные соответственно для решения самых общих задач. При составлении предметных баз данных без проектирования собственных типов данных обойтись практически невозможно. Но, что любопытно, с равной вероятностью нам может понадобиться и удалить созданный нами подтип, чтобы не загромождать и не усложнять код. Для этого в системах управления базами данных обычно встроен специальный оператор drop, что и означает «удалить». Общий вид этот оператор удаления ненужных пользовательских типов имеет следующий:
Drop subtype имя пользовательского типа;
Пользовательские типы данных, как правило, рекомендуется вводить для подтипов достаточно общего назначения.
Значения по умолчанию
Системы управления базами данных могут иметь возможность создания любых произвольных значений по умолчанию или, как их еще называют, умолчаний. Эта операция в любой среде программирования имеет достаточно большой вес, ведь практически в любой задаче может возникнуть необходимость введения констант, неизменяемых значений по умолчанию. Для создания умолчания в системах управления базами данных используется уже знакомая нам по прохождению пользовательского типа данных функция Create. Только в случае создания значения по умолчанию используется также дополнительное ключевое слово default, которое и означает «умолчание». Другими словами, чтобы создать в имеющейся базе данных значение по умолчанию, необходимо использовать следующий оператор:
Create default имя умолчания As константное выражение;
Понятно, что на месте константного значения при применении этого оператора нужно написать значение или выражение, которое мы хотим сделать значением или выражением по умолчанию. И, разумеется, надо решить, под каким именем нам будет удобно его использовать в нашей базе данных, и записать это имя в первую строчку оператора. Необходимо заметить, что в данном конкретном случае этот оператор Create отвечает синтаксису языка Transact‑SQL, встроенному в систему Microsoft SQL Server. Итак, что мы получили? Мы вывели, что умолчание представляет собой именованную константу, сохраняемую в базах данных, как и ее объект. В визуальной среде разработки умолчания появляются в списке выделенных значений по умолчанию. Приведем пример создания умолчания. Пусть для правильной работы нашей базы данных необходимо, чтобы в ней функционировало значение со смыслом неограниченного срока действия чего‑либо. Тогда нужно ввести в список значений этой базы данных значение по умолчанию, отвечающему данному требованию. Это может быть необходимо хотя бы потому, что каждый раз при встрече в тексте кода с этим довольно громоздким выражением будет крайне неудобно выписывать его заново. Именно поэтому воспользуемся означенным выше оператором Create для создания умолчания, со смыслом неограниченного срока действия чего‑либо.
Create default «срок не ограничен» As ‘9999‑12‑31 23: 59:59’
Здесь также был использован синтаксис языка Transact‑SQL, согласно которому значения констант типа «дата – время» (в данном случае, ‘9999‑12‑31 23: 59:59’) записываются как строки символов определенного направления. Интерпретация строк символов как значений типа «дата – время» определяется контекстом использования этих строк. Например, в нашем конкретном случае, сначала в константной строчке записано предельное значение года, а потом времени. Однако при всей своей полезности умолчания, как и пользовательский тип данных, иногда тоже могут требовать того, чтобы их удалили. В системы управления базами данных обычно есть специальный встроенный предикат, аналогичный оператору, удаляющему ненужный более пользовательский тип данных. Это предикат Drop и сам оператор выглядят следующим образом:
Drop default имя умолчания;
Виртуальные атрибуты
Все атрибуты в системах управления базами данных делятся (по абсолютной аналогии с отношениями) на базовые и виртуальные. Так называемые базовые атрибуты – это хранимые атрибуты, которые необходимо использовать не один раз, а следовательно, целесообразно сохранить. А, в свою очередь, виртуальные атрибуты – это не хранимые, а вычисляемые атрибуты. Что это значит? Это значит, что значения так называемых виртуальных атрибутов реально не хранятся, а вычисляются через базовые атрибуты на ходу посредством задаваемых формул. При этом домены вычисляемых виртуальных атрибутов определяются автоматически. Приведем пример таблицы, задающей отношение, в которой два атрибута – обычные, базовые, а третий атрибут – виртуальный. Он будет вычисляться по специально введенной формуле.
Итак, мы видим, что атрибуты «Вес Кг» и «Цена Руб за Кг» – базовые атрибуты, потому что они имеют обыкновенные значения и хранятся в нашей базе данных. А вот атрибут «Стоимость» – виртуальный атрибут, потому что он задан формулой своего вычисления и реально в базе данных храниться не будет. Интересно заметить, что в силу своей природы, виртуальные атрибуты не могут принимать значения по умолчанию, да и вообще, само понятие значения по умолчанию для виртуального атрибута лишено смысла, а следовательно, не применяется. И еще необходимо знать, что, несмотря на то что домены виртуальных атрибутов определяются автоматически, тип вычисляемых значений иногда нужно заменить с имеющегося на какой‑нибудь другой. Для этого в языке систем управления базами данных имеется специальный предикат Convert, с помощью которого и может быть переопределен тип вычисляемого выражения. Convert – это так называемая функция явного преобразования типов. Записывается она следующим образом:
Convert (тип данных, выражение);
Выражение, стоящее вторым аргументом функции Convert, посчитается и выведется в виде таких данных, тип которых указан первым аргументом функции. Рассмотрим пример. Пусть нам необходимо посчитать значение выражения «2*2», но вывести это нужно не в виде целого числа «4», а строкой символов. Для выполнения этого задания запишем следующую функцию Convert:
Convert (Char (1), 2 * 2).
Таким образом, можно увидеть, что данная запись функции Convert в точности даст необходимый нам результат.
Понятие ключей
При объявлении схемы базового отношения могут быть заданы объявления нескольких ключей. С этим мы уже не раз сталкивались прежде. Наконец настало время поговорить более подробно о том, что же такой ключи отношения, а не ограничиваться общими фразами и приближенными определениями. Итак, дадим строгое определение ключа отношения. Ключ схемы отношения – это подсхема исходной схемы, состоящая из одного или нескольких атрибутов, для которых декларируется условие уникальности значений в кортежах отношений. Для того чтобы понять, что такое условие уникальности или, как его еще называют, ограничение уникальности, вспомним для начала определения кортежа и унарной операции проекции кортежа на подсхему. Приведем их:
t = t (S) = { t (a) | a ∈ def (t) ⊆ S } – определение кортежа, t (S) [ S’ ] = { t (a) | a ∈ def (t) ∩ S’ }, S’ ⊆ S – определение унарной операции проекции;
Понятно, что проекции кортежа на подсхему соответствует подстрока строки таблицы. Итак, что же такое ограничение уникальности ключевых атрибутов? Объявление ключа К для схемы отношения S приводит к формулированию следующего инвариантного условия, называемого, как мы уже говорили, ограничением уникальности и обозначаемого как:
Inv < K → S > r(S): Inv < K → S > r (S) = ∀ t 1, t 2 ∈ r (t 1[ K ] = t 2 [ K ] → t 1(S) = t 2(S)), K ⊆ S;
Итак, данное ограничение уникальности Inv < K → S > r (S) ключа К означает, что если любые два кортежа t 1 и t 2, принадлежащие отношению r (S), равны в проекции на ключ К, то это непременно влечет за собой равенство этих двух кортежей и в проекции на всю схему отношения S. Другими словами, все значения кортежей, принадлежащих ключевым атрибутам, уникальны, единственны в своем отношении. И второе важное требование, предъявляемое к ключу отношения, – это требование неизбыточности. Что это значит? Это требование означает, что ни для какого строгого подмножества ключа требование уникальности не предъявляется. На интуитивном уровне понятно, что ключевой атрибут – это тот атрибут отношения, который однозначно и точно определяет каждый кортеж отношения. Например, в следующем отношении, заданном таблицей:
ключевым атрибутом является атрибут «№ зачетной книжки», потому что у различных студентов не может быть одинакового номера зачетной книжки, т. е. для этого атрибута выполняется ограничение уникальности. Интересно, что в схеме любого отношения могут встретиться самые разные ключи. Перечислим основные виды ключей: 1) простой ключ – это ключ, состоящий из одного и не более атрибута. Например, в экзаменационной ведомости по конкретному предмету простым ключом является номер зачетки, потому что по нему можно однозначно идентифицировать любого студента; 2) составной ключ – это ключ, состоящий из двух и более атрибутов. Например, составным ключом в списке учебных аудиторий являются номер корпуса и номер аудитории. Ведь каким‑то одним из этих атрибутов однозначно определить каждую аудиторию не представляется возможным, а их совокупностью, т. е. составным ключом, это сделать довольно легко; 3) суперключ – это любое надмножество любого ключа. Следовательно, сама схема отношения заведомо является суперключом. Из этого можно сделать вывод, что любое отношение теоретически имеет, как минимум, один ключ, а может иметь их и несколько. Однако объявление суперключа вместо обычного ключа логически недопустимо, так как связано с ослаблением автоматически контролируемого ограничения уникальности. Ведь супер ключ хоть и обладает свойством уникальности, но не обладает свойством неизбыточности; 4) первичный ключ – это просто ключ, который при задании базового отношения был объявлен первым. Важно, что допустимо объявление одного и только одного первичного ключа. Кроме того, атрибуты первичного ключа ни в коем случае не могут принимать Null‑значений. При создании базового отношения в записи на псевдокоде первичный ключ обозначается primary key и в скобках указывается имя атрибута, который и является этим ключом; 5) кандидатные ключи – это все остальные ключи, объявленные после первичного ключа. В чем заключаются основные отличия кандидатных ключей от ключей первичных? Во‑первых, кандидатных ключей может быть несколько, тогда как первичный ключ, как было сказано выше, может быть только один. И, во‑вторых, если атрибуты первичного ключа не могут принимать Null‑значений, то на атрибуты кандидатных ключей это условие не накладывается. На псевдокоде при задании базового отношения кандидатные ключи объявляются при помощи слов candidate key и в скобках рядом, как и в случае объявления первичного ключа, указывается имя атрибута, который и является данным кандидатным ключом; 6) внешний ключ – это ключ, объявленный в базовом отношении, который при этом ссылается на первичный или кандидатный ключ того же самого или какого‑то другого базового отношения. При этом отношение, на которое ссылается внешний ключ, называется ссылочным (или родительским) отношением. А отношение, содержащее внешний ключ, называется дочерним. В записи на псевдокоде внешний ключ обозначается как foreign key, в скобках непосредственно после этих слов указывается имя атрибута данного отношения, являющегося внешним ключом, а после этого записывается ключевое слово references («ссылается») и указать имя базового отношения и имя атрибута, на который и ссылается данный конкретный внешний ключ. Также при создании базового отношения для каждого внешнего ключа записывается условие, называемое ограничением ссылочной целостности, но подробно мы будем говорить об этом позднее.
  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  Что вызывает тренды на фондовых и товарных рынках Объяснение теории грузового поезда Первые 17 лет моих рыночных исследований сводились к попыткам вычислить, когда этот... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|