
|
|
Мотивировка нормальной формы Бойса-КоддаВ нормальной форме Бойса-Кодда не существует избыточности и аномалий включения, удаления и модификации. Оказывается, что любая схема отношения может быть приведена в нормальную форму Бойса-Кодда таким образом, чтобы декомпозиция обладала свойством соединения без потерь. Однако схема отношения может быть неприводимой в НФБК с сохранением зависимостей. В этом случае приходится довольствоваться третьей нормальной формой. 8.5. Пример нормализации до 3НФ Для улучшения структуры реляционной базы данных (устранения возможных аномалий) необходимо привести все таблицы базы данных к третьей нормальной форме или в более высокой форме (если это возможно). Таким образом, задача сводится к проверке нормализации всех сущностей, отображающихся в таблицы базы данных. Если таблица, получающаяся из некоторой сущности, не является таблицей в третьей нормальной форме, то она должна быть заменена на несколько таблиц, находящихся в третьей нормальной форме. Продолжим рассмотрение примера с отношением ЭКЗАМЕНАЦИОННАЯ ВЕДОМОСТЬ В начале этой лекции мы привели отношение к первой нормальной форме.
Ключом данного отношения будет совокупность атрибутов – Код студента и Код экзамена. Для более краткой записи процесса нормальзации введем следующие обозначения: КС – код студента, КЭ – код экзамена, Ф – фамилия, П – предмет, Д – дата, О-оценка. Выпишем функциональные зависимости КС, КЭ à Ф, П, Д, О КС, КЭ à Ф КС, КЭ à П КС, КЭ à Д КС, КЭ à О КЭ à П КЭ à Д КС à Ф В соответствии с определением, отношение находится во второй нормальной форме (2НФ), если оно находтяс в 1НФ и каждый неключевой атрибут зависит от первичного ключа и не зависит от части ключа. Здесь атрибуты П, Д, Ф зависят от части ключа. чобы избавиться от этих зависимостей необходимо произвести декомпозицию отношения. Для этого используем теорему о декомпозиции. Имеем отношение R (КС, Ф, КЭ, П, Д, О). Возьмем зависимость КС à Ф в соответствии с формулировкой теоремы исходное отношение равно соединению его проекций R 1(КС, Ф) и R 2(КС, КЭ, П, Д, О). В отношении R 1(КС, Ф) существует функциональная зависимость КС à Ф, ключ КС – составной не ключевой атрибут Ф не зависит от части ключа. Это отношение находтся в 2 НФ. Так как в этом отношении нет транзитивных зависимостей, отношение R (КС, Ф) находится в 3НФ, что и требовалось. Рассмотрим отношение R 2(КС, КЭ, П, Д, О) с составным ключом КС, КЭ. Здесь есть зависимость КЭ à П, КЭ à Д, КЭ à П, Д. Атрибуты П,Д зависят от части ключа, следовательно отношение не находится в 2НФ. В соответствии с теоремой о декомпозиции исходное отношение (используем функциональную зависимость КЭ à П, Д) равно соединению проекций R 3(КЭ, П, Д), R 4(КС, КЭ, О). В отношении R 3(КЭ, П, Д) существуют функциональные зависимости КЭ à П, КЭ à Д, КЭ à П, Д. Зависимости неключевых атрибутов от части ключа нет, следовательно отношение находится в 2НФ. Транзитивных зависимостей в этом отношении так же нет, следовательно отношение находится в 3НФ. Таким образом, исходное отношение приведено в к трем отношениям, каждое из которых находится в третьей нормальной форме R 1(КС, Ф), R 3(КЭ, П, Д), R 4(КС, КЭ, О). Заметим, что в отношении R 4 атрибуты КС, КЭ являются внешними ключами, используемыми для установления связей с другими отношениями. Представим полученную модель в виде диаграммы объектов-связей (ER-диаграммы). Для наглядности и возможности последующего программирования перейдем к английским названиям объектов (отношений) и атрибутов. Отношение R 1 представляет объект student с атрибутами id_st (первичный ключ), surname. Отношение R 3 представляет объект exam_st c атрибутами id_ex (первичный ключ), subject, date. Отношение R 4 представляет объект mark_st c атрибутами id_st (внешний ключ), id_ex (внешний ключ), mark. Первичный ключ здесь id_st, id_ex. Соответствующая ER-диаграмма изображена на рис. 8.1.
Рис. 8.1. ER-диаграмма, представляющая рассмотренный фрагмент предметной области.
8.6. Целостная часть реляционной модели. Напомним, что под целостностью базы данных понимается то, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную часть (правильная) информация. Поддержка целостности в реляционных БД основана на выполнении следующих требований. 1. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е., другими словами, любое отношение должно обладать определенным первичным ключом. Это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений. 2. Второе требование называется требованием целостности по ссылкам. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Связь между отношениями осуществляется с помощью миграции ключа. Пример внешнего ключа. СТУДЕНТ (Код студента, Фамилия) сдает ЭКЗАМЕН (Код студента, Предмет, Оценка). Атрибут Код студента сущности ЭКЗАМЕН называется внешним ключом, поскольку его значения однозначно характеризуют сущности, представленные кортежами некоторого другого отношения – отношения Студент (мы предполагаем, что поле Код студента является ключом отношения Студент). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом. Требование целостности по ссылкам или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа в ссылающемся отношении в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать). Ограничения целостности сущности и по ссылкам должны поддерживаться СУБД. Для соблюдения целостности сущности достаточно гарантировать отсутствие в любом отношении кортежей с одним и тем же значением первичного ключа. (В Access для этого предназначена специальная реализация целочисленного поля – поле типа «Счетчик».) С целостностью по ссылкам дела обстоят несколько более сложно. Понятно, что при обновлении ссылающегося отношения (вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. Но как быть при удалении кортежа из отношения, на которое ведет ссылка? Здесь существуют три подхода, каждый из которых поддерживает целостность по ссылкам. Первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (т.е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа). При втором подходе при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным. Наконец, третий подход (каскадное удаление) состоит в том, что при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи. В развитых реляционных СУБД обычно можно выбрать способ поддержания целостности по ссылкам для каждой отдельной ситуации определения внешнего ключа. Конечно, для принятия такого решения необходимо анализировать требования конкретной прикладной области. Заметим, что все современные СУБД поддерживают и целостность сущностей, и целостность по ссылкам, но позволяют пользователям выключать данные ограничения и, таким образом, строить базы данных, не соответствующие реляционной модели. Опыт показывает, что отход от основных положений реляционной модели приводит к краткосрочному выигрышу – алгоритмы становятся проще, но впоследствии серьезно усложняют задачу, особенно ее сопровождение. Краткие итоги: Лекция посвящена вопросам оптимизации схем отношений (структуры реляционной базы данных) на основе формальных методов теории реляционных баз данных. Здесь рассматривается ряд необходимых для этого понятий (функциональная зависимость, нормальные формы, декомпозиция схем отношений). Разбирается пример приведения таблицы к третьей нормальной форме, оптимальной по ряду показателей (исключающей избыточность, аномалии включения и удаления). Рассматриваются вопросы реализации целостности данных в реляциионных СУБД. В лекции рассматриваются вопросы использование формального аппарата для оптимизации схем отношений. Сформулирована проблема выбора рациональных схем отношений и пути реализации такого выбора путем нормализации (последовательного преобразования схемы отношения в ряд нормальных форм). Для формального описания соответствующего процесса определены понятие функциональной зависимости (зависимости между атрибутами отношения), ключа, сформулированы правила вывода множества функциональных зависимостей, понятие декомпозиции схемы отношения. Определены первая, вторая, третья нормальные формы и нормальная форма Бойса-Кодда. Приведен пример нормализации до 3НФ. Рассмотрены вопросы реализации условий целостности данных в реляционных СУБД.
Вопросы настоящей лекции рассматриваются в [1-8]. Контрольные тесты
Задача 1. В чем состоит задача выбора рациональных схем отношений?
Вариант 1. Какие проблемы устраняются за счет выбора рациональных схем отношений?
ð+ дублирование ð+ потенциальная противоречивость ð+ потенциальная возможность потери сведений ð+ потенциальная возможность не включения информации в базу данных ð увеличение количества схем отношений
Вариант 2. С чем связано основное дублирование информации в реляционной базе данных?
ð с повторением одинаковых строк в одной таблице ð с повторением одинаковых столбцов в одной таблице ð+ с повторением одинаковых значений атрибутов в одной таблице ð с повторением одинаковых значений атрибута в разных таблицах
Вариант 3. Какие аномалии необходимо устранить при проектировании реляционной базы данных? ð создания ð+ удаления ð+ обновления ð+ включения ð выключения
Задача 2. Как механизм используется для выбора рациональных схем отношений?
Вариант 1. Как осуществляется выбор рациональных схем отношений?
ð+ путем нормализации ð+ путем последовательного преобразования отношений к ряду нормальных форм ð путем объединения схем отношений ð+ путем декомпозиции схем отношений
Вариант 2. Что такое нормализация?
ð+ последовательное преобразование отношений к ряду нормальных форм ð определенное объединение схем отношений ð+ определенная декомпозиция схем отношений ð преобразование отношений с использованием операций реляционной алгебры
Вариант 3. Что такое первая нормальная форма?
ð+ значения всех атрибутов отношения являются простыми ð+ значения всех атрибутов отношения являются неделимыми ð+ значения всех атрибутов отношения являются атомарными ð значения всех атрибутов отношения являются кортежами ð значения некоторых атрибутов отношения являются атомарными ð значения некоторых атрибутов отношения являются кортежами
Задача 3. Дать характеристику функциональных зависимостей.
Вариант 1. Что такое X функционально определяет Y?
ð+ каждое значение множества X связано с одним значением множества Y ð+ если два кортежа совпадают по значениям X, то они совпадают по значениям Y ð Y является функцией X ð Y зависит от X ð каждое значение множества Y связано с одним значением множества X ð если два кортежа совпадают по значениям Y, то они совпадают по значениям X
Вариант 2. Что характеризуют функциональные зависимости?
ð схему отношения ð+ все возможные значения отношения ð+ все возможные значения строк отношения ð+ отношение как переменную
Вариант 3. Как можно использовать функциональные зависимости для защиты логической целостности базы данных?
ð+ как ограничения целостности ð+ для проверки выполнения функциональной зависимости при обновлении данных ð для проверки правильности работы прикладных программ ð для автоматизированного формирования соответствующих данных
Задача 4. Как осуществляется нормализация схем отношений?
Вариант 1. Что такое декомпозиция схемы отношения?
ð замена схемы отношения R = { А 1, А 2, … Аn } совокупностью подмножеств R: R 1, R 2 таких, что R = R 1 Ç R 2 ð+ замена схемы отношения R = { А 1, А 2, … Аn } совокупностью подмножеств R: R 1, R 2 таких, что R = R 1 È R 2 ð замена схемы отношения R = { А 1, А 2, … Аn }совокупностью подмножеств R: R 1, R 2 таких, что R = R 1 ´ R 2 ð замена схемы отношения R = { А 1, А 2, … Аn }совокупностью подмножеств R: R 1, R 2 таких, что R = R 1 + R 2
Вариант 2. Как формулируется теорема о декомпозиции?
ð+ если R (A, B, C) удовлетворяет зависимости A à B, то R равно соединению проекций R (A, B), R (A, C) ð если R (A, B, C) удовлетворяет зависимости A à B, то R равно соединению проекций R (A, B), R (B, C) ð если R (A, B, C) удовлетворяет зависимости A à B, то R равно соединению проекций R (A, C), R (B, C) ð+ если R (A, B, C) удовлетворяет зависимости A à B, то R равно соединению проекций R (A, C), R (A, B)
Вариант 3. Какими свойствами должны обладать декомпозиции при нормализации?
ð+ сохранение функциональных зависимостей ð+ соединения без потерь ð разбиение без потерь ð сохранение ключа
Задача 5. Приведение ко второй нормальной форме.
Вариант 1. При каких условиях отношение находится во второй нормальной форме?
ð+ если оно находится в первой нормальной форме и каждый неключевой атрибут зависит от всего первичного ключа ð если оно находится в первой нормальной форме и каждый неключевой атрибут зависит от части первичного ключа ð если оно находится в первой нормальной форме и каждый неключевой атрибут не зависит от первичного ключа ð+ если оно находится в первой нормальной форме и каждый неключевой атрибут не зависит от части первичного ключа
Вариант 2. Как осуществляется приведение ко второй нормальной форме?
ð+ производится декомпозиция с использованием функциональной зависимости, в которой неключевой атрибут зависит от части первичного ключа ð сначала схема отношения приводится к первой нормальной форме ð производится декомпозиция с использованием функциональной зависимости, в которой неключевой атрибут зависит от всего первичного ключа ð производится декомпозиция с использованием функциональной зависимости, в которой неключевой атрибут зависит от неключевого атрибута
Вариант 3. Какие аномалии устраняются второй нормальной формой? ð удаления ð избыточность ð обновления ð включения ð+ никакие
Задача 6. Приведение к третьей нормальной форме.
Вариант 1. При каких условиях отношение находится в третьей нормальной форме?
ð если оно находится во второй нормальной форме и каждый неключевой атрибут зависит от всего первичного ключа ð если оно находится во второй нормальной форме и каждый неключевой атрибут нетранзитивно зависит от части первичного ключа ð+ если оно находится во второй нормальной форме и каждый неключевой атрибут нетранзитивно зависит от первичного ключа ð если оно находится во второй нормальной форме и каждый неключевой атрибут не зависит от части первичного ключа
Вариант 2. Как осуществляется приведение к третьей нормальной форме?
ð производится декомпозиция с использованием функциональной зависимости, в которой неключевой атрибут зависит от части первичного ключа ð+ сначала схема отношения приводится ко второй нормальной форме ð+ производится декомпозиция с использованием функциональной зависимости, в которой неключевой атрибут транзитивно зависит от первичного ключа ð производится декомпозиция с использованием функциональной зависимости, в которой неключевой атрибут нетранзитивно зависит от первичного ключ
Вариант 3. Какие аномалии устраняются третьей нормальной формой?
ð удаления ð+ избыточность ð обновления ð+ включения ð+ никакие
Задача 7. Анализ функциональных зависимостей следующего отношения.
Вариант 1. Какие из перечисленных зависимостей существуют в этом отношении?
ð+ Код студента →Фамилия ð+ Предмет→Дата ð+ Код экзамена →Дата ð Код студента→Оценка Вариант 2. Каких из перечисленных зависимостей не существует в этом отношении?
ð Код студента, Фамилия→Фамилия ð Предмет→Дата ð Код экзамена →Дата ð+ Код студента→Оценка ð Код студента, Предмет→Оценка
Вариант 3. В какой зависимости определен первичный ключ отношения?
ð Код студента, Фамилия→Фамилия, Предмет ð Предмет→Дата ð Код экзамена →Дата ð Код студента→Оценка ð Код студента, Предмет→Оценка ð+ Код студента, Код предмета →Дата, Оценка
Задача 8. Как осуществляется поддержка целостности данных в реляционных СУБД?
Вариант 1. Какие требования должны выполняться для поддержки целостности данных в реляционных СУБД?
ð+ уникальность любого кортежа отношения ð+ наличие у любого отношения первичного ключа ð+ для каждого значения внешнего ключа в ссылающемся отношении должен существовать кортеж с таким же значением первичного ключа в отношении, на которое ссылаются. ð для каждого значения первичного ключа в ссылающемся отношении должен существовать кортеж с таким же значением внешнего ключа в отношении, на которое ссылаются
Вариант 2. В чем состоят ограничения целостности сущности и по ссылкам?
ð+ для каждого значения внешнего ключа в ссылающемся отношении должен существовать кортеж с таким же значением первичного ключа в отношении, на которое ссылаются. ð для каждого значения первичного ключа в ссылающемся отношении должен существовать кортеж с таким же значением внешнего ключа в отношении, на которое ссылаются ð должны быть экземпляры сущностей ð+ экземпляры сущностей должны уникально идентифицироваться
Вариант 3. Какие варианты поддержки ограничений целостности по ссылкам используются в современных СУБД?
ð+ запрещается удалять кортеж, на который существуют ссылки. ð+ при удалении кортежа, на который существуют ссылки, во всех ссылающихся кортежах значение внешнего ключа заменяется на неопределенное ð+ при удалении кортежа, на который существуют ссылки, из ссылающегося отношения удаляются все ссылающиеся кортежи ð при удалении кортежа, на который существуют ссылки, удаляется ссылающееся отношение
Литература
1. Карпова Т. Базы данных. Модели, разработка, реализация. – СПб.: Питер, 2001. – 304 с. 2. Конноли Т., Бэгг К., Страчан А. Базы данных: проектирование, реализация и сопровождение. Теория и практика. 2-е изд.: Пер. с англ. – М.: Издательский дом «Вильямс», 2000. – 1120 с. 3. Ульман Дж. Д., Уидом Дж. Введение в системы баз данных: Пер. с англ. – М.: Лори, 2000. – 374 с. 4. Хомоненко А.Д., Цыганков В.М., Мальцев М.Г. Базы данных: Учебник для вузов. – СПб.: КОРОНА принт, 2000. – 416 с. 5. Толстобров А.П. Управление данными. Учебное пособие. Воронеж: Изд-во Воронежского ГУ, 2007 – 205 с. 6. Хансен Г., Хансен Дж. Базы данных: разработка и управление: Пер. с англ. – М.: ЗАО «Издательство «БИНОМ», 1999. – 704 с. 7. Дейт К.Дж. Введение в системы баз данных: Пер. с англ. – 6-е изд. – К.: Диалектика, 1998. – 784 с. 8. Швецов В.И., Визгунов А.Н., Мееров И.Б. Базы данных. Учебное пособие. Н.Новгород: Изд-во ННГУ, 2004. 271 с.
Лекция 9. Физические модели данных
Лекция посвящена вопросам физической организации данных в памяти компьютера. Здесь описывается структура памяти компьютера, и, с учетом ее особенностей представлены структуры хранения данных в оперативной и внешней памяти. Ключевые термины: физические модели данных, структуры хранения, представление данных в памяти ЭВМ, физическая запись, последовательный файл, списковая структура, В-дерево, хэш-функция, индексирование. Цель лекции: дать представление об основных типовых способах организации данных в памяти ЭВМ в СУБД с оценкой соответствующих моделей по времени доступа к данным в базе данных и по объему занимаемой памяти.
Как уже отмечалось, концептуальная схема, специфицированная к СУБД, автоматически отображается в структуру хранения программами СУБД. Внешний пользователь может ничего не знать о том, как его представление о данных физически организовано в памяти вычислительной системы. Тем не менее от физического размещения данных в памяти ЭВМ существенно зависит время решения прикладных задач. В связи с этим, даже на одном из начальных этапов проектирования базы данных – этапе выбора СУБД, желательно знать возможности физических структур хранения, представляемых конкретными СУБД, и оценивать временные характеристики проектируемой базы данных с учетом этих возможностей. Способы физической организации данных в различных СУБД, как правило, различны и определяются типом используемой ЭВМ, инструментальными средствами разработки СУБД, а также критериями, которыми руководствуются разработчики СУБД при выборе методов размещения данных и способов доступа к этим данным. Заметим, что наиболее распространенным критерием служит время доступа к данным, однако в качестве критерия может выбираться, например, трудоемкость реализации соответствующих методов. В настоящей лекции будут рассмотрены типовые физические модели организации данных в конкретных СУБД. Физические модели данных служат для отображения моделей данных. Основными понятиями модели данных являются поле, логическая запись, логический файл. Слово «логический» введено, чтобы отличать понятия, относящиеся к логической модели данных, от понятий, относящихся к физической модели данных. Основными понятиями физической модели данных, используемыми для представления логической модели данных, являются поле, физическая запись, физический файл. В частности, логическая запись, состоящая из полей, может быть представлена в виде физической записи (из тех же полей), логический файл – в виде физического файла. Прежде чем конкретизировать понятия, относящиеся к физической модели данных, рассмотрим структуру памяти ЭВМ. 9.1. Структура памяти ЭВМ Важнейшей особенностью памяти ЭВМ, в значительной степени определяющей методы организации данных и доступа к ним, является её неоднородность. Существуют два разных типа памяти – оперативная (ОП) и внешняя (ВП), причем процессор работает только с данными из оперативной памяти (рис. 9.1.).
Рис. 9.1. Схема работы ЭВМ
Как уже многократно отмечалось, базы данных создаются для работы с большими объемами данных, что обусловливает необходимость использования внешней памяти. Поэтому организация данных и доступа к ним должна учитывать как специфику каждого типа памяти, так и способы их взаимодействия. Отметим основные свойства оперативной памяти: · единицей памяти является байт; · память прямоадресуема (каждый байт имеет адрес); · процессор выбирает для обработки нужные данные, непосредственно адресуясь к последовательности байтов, содержащих эти данные. Отметим основные свойства внешней памяти: · минимальной адресуемой единицей является физическая запись; · для последующей обработки (например, работы с полями) запись должна быть считана в оперативную память; · время чтения записи в ОП (занесения записи из ОП в ВП) на несколько порядков выше времени обработки процессором записи из ОП; · организация обмена осуществляется порциями, т.к. невозможно считать сразу всю базу данных.
9.2. Представление экземпляра логической записи Логическая запись представляется в оперативной памяти следующим образом:
Прямая адресация байтов позволяет процессору выбирать для обработки нужное поле. Заметим, что указанное представление не делает различий для записей в сетевой, иерархической и реляционных моделях. В случае сетевой и иерархической моделей некоторые поля могут являться указателями, тогда последовательность байтов, используемая для хранения этих полей, содержит адрес начала последовательности байтов, соответствующей записи – члену отношения. В большинстве современных СУБД используется формат записей фиксированной длины. В этом случае все записи имеют одинаковую длину, определяемую суммарной длиной полей, составляющих запись. В СУБД другие форматы записей (переменной длины, неопределенной длины) встречаются гораздо реже, поэтому в данной книге эти форматы не рассматриваются. Заметим, что поля записи, принимающие значения существенно разной длины в различных экземплярах записей, в предметной области встречаются достаточно часто. Примером может служить поле резюме в записи СОТРУДНИК. Резюме может составлять полстраницы текста, страницу и т.д. Возникает проблема – как эту информацию переменной длины представить в записи фиксированной длины. Возможным вариантом является установление размера соответствующего поля по максимальному значению. В этом случае у многих экземпляров записи указанное поле будет заполнено не полностью и, таким образом, память ЭВМ будет использоваться неэффективно. Более эффективный и часто используемый в СУБД прием организации таких записей состоит в следующем. Вместо поля (полей), принимающего значение существенно разной длины, в запись включается поле-указатель на область памяти, где будет размещаться значение исходного поля. Как правило, эта область является областью внешней памяти прямого доступа. В процессе ввода соответствующего значения в выделенной области занимается столько памяти, какова длина этого значения. На рис. 9.2 представлен пример вышеуказанного представления экземпляров записей из N полей, причем поле N принимает значения соответственно разной длины у разных экземпляров записей.
Рис. 9.2. Представление полей переменной длины
Конкретной реализацией такой схемы является поле типа МЕМО в СУБД (dBase III+, FoxPro, Access и т.д.).
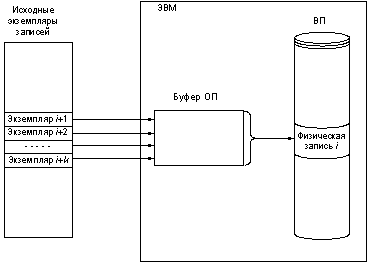
9.3. Организация обмена между оперативной Единицей обмена данными между оперативной и внешней памятью является физическая запись. Физическая запись читается (записывается) за одно обращение к внешней памяти. В частности, физическая запись может соответствовать одному экземпляру логической записи. Число обращений к внешней памяти при работе с базой данных определяет время отклика системы. В связи с этим для уменьшения числа обращений к БД при работе с ней увеличивают длину физической записи (объединяют в одну физическую запись несколько экземпляров логических записей). В этом случае физическую запись называют также блоком, число k экземпляров логических записей, составляющих физическую запись, – коэффициентом блокировки. Ввод исходных данных в БД осуществляется следующим образом: · в ОП последовательно вводятся k экземпляров логических записей (кортежей); · введенные k экземпляров объединяются в физическую запись (блок); · физическая запись заносится во внешнюю память. Ввод k экземпляров записей исходной таблицы, составляющих i-ю физическую запись, изображен на рис. 9.3.
Рис. 9.3. Схема занесения записей во внешнюю память
Обработка данных, хранящихся во внешней памяти, осуществляется следующим образом: · физическая запись (блок) считывается в оперативную память; · обрабатываются экземпляры логических записей внутри блока (выбираются нужные поля, производится сравнение ключевого поля с заданным значением, осуществляется корректировка полей, выполняются операции удаления и т.п.). В некоторых СУБД (например, MS SQL Server) единицей обмена между оперативной и внешней памятью является страница (вид физической записи, размер которой фиксирован и не зависит от длины логической записи). Организация обмена между оперативной и внешней памятью в этом случае аналогична описанной выше. Отличие здесь будет состоять в том, что экземпляры логических записей формируются в буфере, размером со страницу)если сразмер страницы не кратен длине логической записи, страница может быть заполнена неполностью, физическая запись на внешнем носителе, соответственно, будет заполнена не полностью).
9.4. Структуры хранения данных во внешней памяти ЭВМ В современных СУБД наибольшее распространение получили табличные модели данных. В связи с этим, а также для большей определенности в настоящем разделе мы будем говорить о структурах хранения для табличной модели. Однако отметим, что некоторые из рассматриваемых ниже структур хранения могут использоваться и для представления сетевых и иерархических моделей. В качестве внешней памяти мы рассматриваем наиболее распространенную в современных ЭВМ память прямого доступа. Память прямого доступа дает возможность обращения к любой записи, если известен её адрес. Для упрощения изложения мы не будем конкретизировать ряд служебных полей, которые содержит физическая запись, и их рассмотрение опускаем. 9.4.1. Последовательное размещение физических записей В этой структуре хранения записи в памяти размещаются последовательно друг за другом. Как уже отмечалось, считаем, что все записи имеют равную длину. Физический адрес записи может быть легко вычислен по номеру записи (для вычисления необходимо знать формат соответствующей физической записи). Физическая запись с номером I содержит логические записи с номерами (I – 1) k +1 (I – 1) k +2 … (I – 1) k + k I = 1, 2, …, знаком Рассмотрим, как реализуются основные элементарные операции модели данных в этой структуре хранения, и оценим число этих операций. Напомним, что с точки зрения пользователя в табличной модели данных эти операции является операциями над строками (столбцами) таблицы.   ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|



 ;
;