
|
|
ЗНАЙОМСТВО З БІБЛІОТЕКОЮ MPIМета роботи: вивчити каркас паралельних програм на базі функцій бібліотеки стандарту MPI, навчитися створювати паралельні програми та запускати їх на виконання
3.1 Теоретичні відомості Існує декілька функцій, які використовуються в будь-якому додатку MPI та призначені для ініціалізації, коректного завершення та виконання необхідних дій після виявлення помилки за логікою роботи програми.
Ініціалізація бібліотеки та MPI-середовища Одна з перших функцій в тілі головної програми main() – це функція ініціализації MPI- середовища:
MPI_Init(&argc,&argv);
До неї передаються адреси аргументів, які стандартно отримуються самою main() від операційної системи та зберігають параметри командного рядка. В кінець командного рядка програми MPI-завантажувач mpirun додає ряд інформаційних параметрів, які необхідні MPI_Init().
Аварійне завершення роботи MPI-середовища Викликається, якщо програма користувача повинна завершитися через помилки часу виконання, що пов’язані з MPI:
MPI_Abort(опис_області_зв’язку, код_помилки_MPI);
Виклик MPI_Abort() з будь-якої задачі примусово завершує роботу всіх задач, що під’єднані до заданої області зв’язку. Якщо вказано опис MPI_COMM_WORLD, то буде завершено весь додаток. Використовуйте код помилки MPI_ERR_OTHER, якщо не знаєте, як охарактеризувати помилку в класифікації MPI.
Нормальне закриття бібліотеки Останньою функцією будь-якого MPI-додатку є функція:
MPI_Finalize();
Дану функцію потрібно викликати перед поверненням з програми, тобто перед кожним оператором return в функції main(), який може бути викликаний після MPI_Init().
Інформаційні функції
Повідомляють розмір групи (тобто загальну кількість задач, під’єднаних до її області зв’язку) та порядковий номер задачі (процесу), що її викликає:
int size, rank; MPI_Comm_size(MPI_COMM_WORLD,&size); MPI_Comm_rank(MPI_COMM_WORLD,&rank);
Функції пересилки даних Для організації простої пересилки даних між процесами використовуються функції:
int MPI_Send(buf,count,datatype,dest,tag,comm); int MPI_Recv(buf,count,datatype,source,tag,comm, status); де void *buf – адреса буфера, тобто початкова адреса буфера прийому (передачі). Кожний процес має власні набори даних та власний буфер прийому (передачі), тому адреси буферів кожного з процесів відрізняються одна від одної; int count – розмір буфера в кількості комірок (не в байтах) типу datatype. Для функції передачі MPI_Send() вказується, скільки комірок потрібно передати, а для функції прийому MPI_Recv() – максимальна ємність приймального буфера. Якщо фактична довжина повідомлення, що надійшло, є меншою – останні комірки буфера не заповнюються, якщо більшою – виникне помилка часу виконання; MPI_Datatype datatype – тип комірок буфера. Функції MPI_Send() та MPI_Recv() оперують масивами однотипних даних. Для опису базових типів мови С в MPI визначені константи MPI_INT, MPI_CHAR, MPI_DOUBLE та інші, які мають тип MPI_Datatype. Їх назви утворюються префіксом MPI_ та ім’ям відповідного типу (int, char, double,...), що записуються великими літерами. Користувач може зареєструвати (визначити) в MPI-додатку свої власні типи даних, наприклад структури, після чого функції MPI зможуть обробляти їх таким же чином, як і базові типи; int dest (source) – номер процеса призначення (прийомника), з яким відбувається обмін даними; int tag – ідентифікатор повідомлення, за допомогою якого одне повідомлення відрізняється від іншого. Ідентифікатор повідомлення – ціле число від 0 до 32767, яке призначається користувачем. Важливо, щоб відправлене повідомлення з призначеним номером, було прийнято з таким же номером; MPI_Comm comm – опис області зв’язку (комунікатор); MPI_Status *status – статус завершення прийому. За адресою status міститься інформація про прийняте повідомлення, зокрема, його ідентифікатор, номер процеса-передавача, код завершення та кількість фактично прийнятих даних.
3.2 Завдання до лабораторної роботи
3.2.1 Завдання 1 Програма демонструє використання функцій MPI для ініціалізації та завершення роботи паралельної програми, а також наводить звичайний приклад використання інформаційних функцій MPI_Comm_size() та MPI_Comm_rank(). Програма 3.1 #include "mpi.h" #include <stdio.h> int main(int argc,char *argv[]) { int size, rank, i; MPI_Init(&argc,&argv); //Ініціалізація бібліотеки MPI_Comm_size(MPI_COMM_WORLD,&size); /* Кількість процесів в додатку */ MPI_Comm_rank(MPI_COMM_WORLD,&rank); /* Власний номер процесу */ if(rank==0) printf("Amount of tasks=%d\n",size); printf("My number in MPI_COMM_WORLD=%d\n",rank); /* Точка синхронізації, після неї процес 0 друкує * аргументи командного рядка. В командному рядку * можуть бути параметри, що додаються * завантажувачем MPIRUN. */ MPI_Barrier(MPI_COMM_WORLD); if(rank==0) for(puts("CommandLine for task 0:"),i=0; i<argc; i++) printf("%d: \"%s\"\n",i,argv[i]); MPI_Finalize();//Всі процеси завершують виконання return 0; } Завдання для самостійного програмування
Варіант 1. Змінити вихідну програму так, щоб кожний процес виводив інформацію щодо парності свого номера. Варіант 2. Змінити вихідну програму так, щоб процес з номером, що дорівнює номеру робочого місця, виводив прізвище студента, а інші процеси виводили свій порядковий номер.
3.2.2 Завдання 2
Програма демонструє використання функцій прийому та передачі, а також використання функції MPI_Abort().
Програма 3.2 #include <mpi.h> #include <stdio.h> int main(int argc,char *argv[]) { int size, rank, count; double doubleData[20]; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&size); MPI_Comm_rank(MPI_COMM_WORLD,&rank); if(size!=2) // запустити тільки два процеси {if(rank==0) printf("Only 2 tasks reqiured instead of %d, abort\n",size); MPI_Barrier(MPI_COMM_WORLD); MPI_Abort(MPI_COMM_WORLD,MPI_ERR_OTHER); return -1; } if(rank==0) MPI_Send(doubleData, 5,MPI_DOUBLE,1,100,MPI_COMM_WORLD); else { MPI_Recv(doubleData,5,MPI_DOUBLE,0,100, MPI_COMM_WORLD,&status); // Визначаємо фактично прийняту кількість даних MPI_Get_count(&status,MPI_DOUBLE,&count); printf("Received %d elements\n",count); } MPI_Finalize(); return 0; } Завдання для самостійного програмування
Варіант 1. Доповніть вихідну програму так, щоб процес "1" виконував посилку, а процес "0" – прийом елементів масиву цілих чисел типу long, причому, розміри буферів передачі та прийому мають дорівнювати номеру робочого місця, помноженому на 10, а кількість елементів, що передаються – номеру робочого місця, збільшеного на одиницю. В процесі "0" реалізувати виведення кількості фактично прийнятих елементів. Варіант 2. Доповніть вихідну програму так, щоб процес "1" виконував посилку, а процес "0" – прийом елементів масиву чисел типу float, причому розміри буферів передачі та прийому мають дорівнювати номеру робочого місця, помноженому на 11, а кількість елементів, що передаються, дорівнює номеру робочого місця, збільшеному на одиницю. В процесі "0" вивести кількість фактично прийнятих елементів.
3.2.3 Завдання 3
Переробити програму завдання 2 так, щоб в якості буферів прийому та передачі використовувались масиви динамічної пам’яті.
3.2.4 Завдання 4
Напишіть програму, яка складається з чотирьох процесів. Процес "0" передає до процесів "1", "2" та "3" рядок з прізвищем студента. Процес "1" конкатенує прийнятий рядок з рядком, відповідним імені студента, і відсилає отриманий рядок назад. Процес "2" визначає кількість символів в прийнятому рядку та відсилає це число до нульового процесу. Процес "3" множить число, що дорівнює сумі кодів символів прийнятого рядка на число Після завершення обмінів процес "0" виводить на друк отримані від інших процесів значення.
3.3 Зміст звіту
3.3.1 Мета лабораторної роботи. 3.3.2 Опис порядку створення та запуску паралельної MPI-програми. 3.3.3 Текст програми, розробленої в завданні 4. 3.3.4 Відповіді на контрольні питання. 3.4 Контрольні питання
3.4.1 Який стандарт MPI та яку назву має біблиотека (реалізація) функцій MPI, які використовуються в даній лабораторній роботі? 3.4.2 Які функції вихідної програми завдання 1 виконуються у всіх процесах? 3.4.3 Що означає ідентифікатор MPI_COMM_WORLD? 3.4.4 Для чого використовується власний номер процесу в комунікаторі? 3.4.5 Напишіть фрагмент паралельної програми, який використовує значення кількості процесів в області зв’язку. 3.4.6 Напишіть фрагмент паралельної програми, в кожному з процесів якої створюється масив динамічної пам’яті, розмір якого дорівнює добутку номера процесу на загальну кількість процесів. 3.4.7 До якого класу належать програми даної лабораторної роботи: SIMD чи MIMD? ЛАБОРАТОРНА РОБОТА № 4 ФУНКЦІЇ ОБМІНУ В MPI Мета роботи: продовжити вивчення функцій обміну бібліотеки MPI, зокрема, функцій колективного обміну. Освоїти деякі прийоми їх використання для розподілу даних та обчислень між паралельними процесорами.
4.1Теоретичні відомості
Для обміну даними між процесами всередині заданої області взаємодії можуть використовуватись функції колективного обміну. Ці функції повинні викликатись у всіх процесах області взаємодії. Для розсилання одних й тих же даних від одного процесу до всіх інших використовується функція широкомовного розсилання:
int MPI_Bcast(void *buf,int count,MPI_Datatype type, int root,MPI_Comm comm);
де buf – адреса буфера; count – кількість елементів даних у повідомленні; type – тип даних; root – ранг процесу, який виконує розсилання; comm – комунікатор. Для розподілу та збору даних використовуються, відповідно, наступні функції, вони мають однакові аргументи:
int MPI_Scatter(void *sendbuf,int sendcount, MPI_Datatype sendtype,void *rcvbuf,int rcvcount, MPI_Datatype rcvtype,int root,MPI_Comm comm);
int MPI_Gather(void *sendbuf,int sendcount, MPI_Datatype sendtype,void *rcvbuf,int rcvcount, MPI_Datatype rcvtype,int root,MPI_Comm comm);
Функція розподілу MPI_Scatter() розсилає рівні частини буфера sendbuf процесу root всім процесам. При цьому зміст буфера процесу root розбивається на рівні частини за кількістю процесів, які беруть участь в обміні, кожна з яких складається з sendcount елементів. Перша частина поміщається до буфера rcvbuf процесу, ранг якого дорівнює нулю, друга – до буфера rcvbuf процесу, ранг якого дорівнює одиниці і т.д. Аргументи, що належать до тієї частини списку аргументів функції, яка передається, мають силу тільки для процесу root. Функція MPI_Gather() має зворотню дію у порівнянні з функцією MPI_Scatter(), тобто вона приймає та розташовує за порядком прийняті дані з процесів, які передають. При цьому параметри прийому дійсні тільки для процесу, що приймає. Наступна функція є векторною версією функції MPI_Scatter() та призначена для розсилання різним процесам різної кількості елементів даних. int MPI_Scatterv(void *sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype, void *rcvbuf, int rcvcount, MPI_Datatype rcvtype, int root, MPI_Comm comm); В MPI_Scatter() функції параметр sendcounts – масив цілих чисел, який містить кількість елементів, що передаються кожному процесу (індекс дорівнює рангу процесу). Параметр displs – масив цілих чисел, кожний з елементів якого задає зсув відносно початку буфера передачі. Таким чином, displs[i] – номер елементу буфера передачі, починаючи з якого будуть передані дані в i -й процес в кількості sendcounts[i] елементів. Функція зведення MPI_Reduce() оброблює елементи масиву даних наступним чином. Функція бере один елемент від кожного процеса, виконує над ними задану операцію і розміщує результат у вказаному процесі. Синтаксис цієї функції: MPI_Reduce(void *buf, void *result, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm); де op – операція зведення, яка може мати значення, що визначені попередньо, такі як MPI_SUM, MPI_PROD, MPI_LAND, MPI_BAND, MPI_MAX і т.д. Всього 12 операцій. Крім того можна визначити свої власні операції зведення за допомогою функції MPI_Op_create().
4.2 Завдання до лабораторної роботи
4.2.1 Завдання 1 Програма виконує паралельне обчислення суми ряду
Програма 4.1 #include "mpi.h" #include <stdio.h> #include <math.h> #define N 400000 int main(int argc,char *argv[]) {int P, M; double x[N], a[N]; int myrank; long i,j; double sum=0.0, total=0.0; double start_time,use_time; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&P); MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
if(myrank==0) {srand((unsigned)time(NULL)); for(i=0;i<N;i++) { x[i]=-1.073741824+rand()*1E-9; a[i]=(-1.073741824+rand()*1E-9)*0.1; } M=N/P; }
if(myrank==0) { start_time=MPI_Wtime(); } MPI_Bcast(&M,1,MPI_INT,0,MPI_COMM_WORLD); MPI_Scatter(x,M,MPI_DOUBLE,x,M,MPI_DOUBLE,0, MPI_COMM_WORLD); MPI_Scatter(a,M,MPI_DOUBLE,a,M,MPI_DOUBLE,0, MPI_COMM_WORLD);
for(i=0;i<M;i++) sum+=a[i]*x[i];
MPI_Barrier(MPI_COMM_WORLD); MPI_Reduce(&sum,&total,1,MPI_DOUBLE,MPI_SUM,0, MPI_COMM_WORLD); if(myrank==0) { use_time=MPI_Wtime()-start_time; printf("t=%lf sec.\n",use_time); printf("sum in %d procs is %.5f\n",P,total); } MPI_Finalize(); return 0; }
Завдання для самостійного програмування
4.2.1.1 Створити програму обчислення суми ряду. Перший варіант: а) б) в) г) якщо Для обчислення синуса в програмі створити окрему функцію, Другий варіант: а) б) в) г) якщо Для обчислення косинуса в програмі створіть окрему функцію, 4.2.1.2 Виміряйте час виконання розробленої програми на одному, двох, трьох та чотирьох процесорах для N=240000 та визначте прискорення обчислень для цих випадків. Дані занесіть до таблиці 4.1 (форми таблиць наведені нижче). Намалюйте графік залежності прискорення від кількості процесорів. 4.2.1.3 Дослідити та намалювати графіки залежності прискорення від кількості членів ряду при обчисленнях на чотирьох процесорах, змінюючи кількість членів ряду від 20000 до 240000 з дискретністю 20000. Вимірювання виконуйте 3 рази з інтервалом між вимірюваннями 15 хвилин, результати вимірювань занесіть до таблиці 4.2. 4.2.1.4 Додайте до програми код для вимірювання часу, який витрачається на виконання двох функцій MPI_Scatter(), дослідіть та намалюйте графіки залежності цього часу від довжини масиву, що розсилається при виконанні задачі на чотирьох процесорах. Результати занесіть до таблиці 4.3.
Таблиця 4.1 – Залежність прискорення від кількості процесорів (N =240000, номер робочого місця №)
Таблиця 4.2 – Залежність прискорення від кількості членів ряду при P =4
Таблиця 4.3 – Залежність швидкості розсилання від довжини масиву при P =4
4.2.2 Завдання 2
Постановка задачі. Нехай необхідно обчислити суму ряду В другому елементі ряду, що розглядається, необхідно виконати одне множення, в третьому – два і т.д. Загальна кількість множень будь-якого "відрізка" ряду з
де Тоді кількість операцій множення, яку повинний виконати кожний процесор, можна визначити за формулою:
Для знаходження кількості операцій множення, яку повинний виконати перший процесор, складемо рівняння:
де Розв’язуючи це квадратне рівняння, знайдемо значення
і т.д. З тим, щоб врахувати незначну неточність у визначенні довжин відрізків, пов’язану з цілочисленним розподіленням, кількість елементів відрізка для останнього процесора знайдемо із співвідношення:
Реалізація програми. Для розподілення різної кількості елементів між процесами використовується функція MPI_Scatterv(), яку описано вище.
Програма 4.2 #include "mpi.h" #include <stdio.h> #include <math.h> #define N 10000 int main(int argc,char *argv[]) { int P; //Number of processes double *x, *a; int myrank; long i,j; double q, an, nn; int *pn, *poffset; // pointers to numbers array and // to offsets array int n, offset; // numbers multiples and offset double C; double mul=1.0, sum=0.0, total=0.0; double start_time,use_time; MPI_Status status;
MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&P); MPI_Comm_rank(MPI_COMM_WORLD,&myrank); if(myrank==0) { pn=(int *)malloc(P*sizeof(int)); if(pn==NULL) {printf("Not memory for n\n"); return -1;} poffset=(int *)malloc(P*sizeof(int)); if(poffset==NULL) {printf("Not memory for offset\n"); return -1;} C=N*(1.0+N)/P; an=1; pn[P-1]=N; poffset[0]=0; for(i=0;i<P-1;i++) { q=(2*an-1)/2.0; nn=-q+sqrt(q*q+C); an+=nn; pn[i]=(int)floor(nn); pn[P-1]-=pn[i]; } poffset[0]=0; for(i=1;i<P;i++) poffset[i]=poffset[i-1]+pn[i-1]; for(i=0;i<P;i++) printf("process %d will be do %d multiples\n",i,pn[i]); }
MPI_Scatter(pn,1,MPI_INT,&n,1,MPI_INT,0, MPI_COMM_WORLD); MPI_Scatter(poffset,1,MPI_INT,&offset,1,MPI_INT,0, MPI_COMM_WORLD);
if(myrank==0) {x=(double *)malloc(N*sizeof(*x)); if(x==NULL) {printf("Not memory\n"); return -1;} a=(double *)malloc(N*sizeof(*a)); if(a==NULL) {printf("Not memory\n"); free(x); return -1;} srand((unsigned)time(NULL)); for(i=0;i<N;i++) {x[i]=(-1.073741824+rand()*1E-9)*0.8; a[i]=(-1.073741824+rand()*1E-9)*0.01; } } if(myrank!=0) { x=(double *)malloc(n*sizeof(*x)); if(x==NULL) {printf("Not memory\n"); return -1;} a=(double *)malloc(n*sizeof(*a)); if(a==NULL) {printf("Not memory\n");free(x); return -1;} }
if(myrank==0) start_time= MPI_Wtime(); MPI_Scatterv(x,pn,poffset,MPI_DOUBLE,x,n,MPI_DOUBLE,0, MPI_COMM_WORLD); MPI_Scatterv(a,pn,poffset,MPI_DOUBLE,a,n,MPI_DOUBLE,0, MPI_COMM_WORLD);
for(i=0;i<n;i++) { for(j=0;j<i+1+offset;j++) mul*=x[i]; sum+=a[i]*mul; mul=1.0; }
MPI_Barrier(MPI_COMM_WORLD); MPI_Reduce(&sum,&total,1,MPI_DOUBLE,MPI_SUM,0, MPI_COMM_WORLD); if(myrank==0) { use_time = MPI_Wtime()-start_time; printf("total=%.12e used=%f sec.\n", total,use_time); free(pn); free(poffset); } free(x); free(a); MPI_Finalize(); return 0; } Завдання для самостійного програмування
4.2.2.1 Для перевірки результату паралельного обчислення додайте до програми код, який обчислює суму даного ряду тільки в нульовому процесі та використовує для обчислення степеня бібліотечну функцію. 4.2.2.2 Використовуючи наведені вище програми, розробіть власну програму, в якій між паралельними процесорами розподіляється однакова кількість членів ряду 4.2.2.3 Виміряйте час роботи програми для трьох, досить великих значень кількості членів ряду і порівняйте його з часом вирішення цієї задачі за допомогою вихідної програми даного завдання для двох, трьох та чотирьох процесорів. Результати наведіть у вигляді таблиці.
4.3 Зміст звіту
4.3.1 Мета лабораторної роботи. 4.3.2 Тексти програм. 4.3.3 Графіки, таблиці та висновки, отримані при дослідженнях. 4.3.4 Відповіді на контрольні питання. 4.4 Контрольні питання
4.4.1 Чи можна оператор M=N/P в програмі першого завдання виконати у всіх процесах? Якщо так, покажіть, що треба змінити в програмі. 4.4.2 Використовуючи довідкові матеріали на комп’ютері, самостійно вивчіть функцію MPI_Gatherv(). 4.4.3 Що таке функція обміну з блокуванням, які функції її виконують в MPI? 4.4.4 Для чого використовується функція MPI_Barrier()? 4.4.5 Як в програмі, що використовує функції MPI, створити приймальний буфер, який у точності відповідає повідомленню, що передається? 4.4.6 Чим відрізняються алгоритми логарифмічного здвоєння та рекурсивного подвоєння? 4.4.7 Опишіть роботу функції MPI_Scan(). 4.4.8 Як можна розподілити між процесорами обчислення множення матриць? ЛАБОРАТОРНА РОБОТА № 5   Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
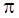 , та відсилає отримане значення до процеса "0".
, та відсилає отримане значення до процеса "0". . Для цього до кожного з
. Для цього до кожного з  процесів за допомогою функції MPI_Scatter() передається відповідна частина масивів чисел
процесів за допомогою функції MPI_Scatter() передається відповідна частина масивів чисел  та
та  , кожна з яких складається з
, кожна з яких складається з  елементів. Процеси обчислюють часткові суми ряду (змінна sum), які далі за допомогою функції MPI_Reduce() приводяться до загальної суми (змінна total).
елементів. Процеси обчислюють часткові суми ряду (змінна sum), які далі за допомогою функції MPI_Reduce() приводяться до загальної суми (змінна total). , де
, де  ,
,  ,
,  ,
,  . Функцію
. Функцію  обчислювати за допомогою розкладання її в ряд Тейлора:
обчислювати за допомогою розкладання її в ряд Тейлора:  Обчислення кожного значення функції
Обчислення кожного значення функції  ;
;  ;
;  ;
; ;
; ;
;  ;
; , то перехід на п. б), інакше – кінець.
, то перехід на п. б), інакше – кінець. нехай дорівнює 500.
нехай дорівнює 500.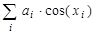 , де
, де  обчислювати за допомогою розкладання її в ряд Тейлора:
обчислювати за допомогою розкладання її в ряд Тейлора:  Обчислення кожного значення функції
Обчислення кожного значення функції  ;
; 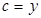 ;
;  ;
; ;
;  ;
; , де
, де  – досить велике число та обчислення слід розподілити між
– досить велике число та обчислення слід розподілити між  повинна обчислюватись шляхом їх перемноження. Якщо в кожному процесорі обчислювати частину суми, яка складається з
повинна обчислюватись шляхом їх перемноження. Якщо в кожному процесорі обчислювати частину суми, яка складається з  елементів вихідного ряду, то це приведе до нерівномірного навантаження процесорів. Наприклад, якщо
елементів вихідного ряду, то це приведе до нерівномірного навантаження процесорів. Наприклад, якщо  . В результаті перший процесор виконає 55, другий – 155, а третій – 255 множень. В програмі реалізовано рівномірний розподіл навантаження обчислень цієї модельної задачі наступним чином.
. В результаті перший процесор виконає 55, другий – 155, а третій – 255 множень. В програмі реалізовано рівномірний розподіл навантаження обчислень цієї модельної задачі наступним чином. елементів утворюють арифметичну прогресію, отже:
елементів утворюють арифметичну прогресію, отже: ,
, – номер першого елемента ділянки.
– номер першого елемента ділянки. .
. ,
, – кількість елементів першого відрізка. Початком другого відрізка, очевидно, буде елемент з номером
– кількість елементів першого відрізка. Початком другого відрізка, очевидно, буде елемент з номером  , тоді кількість елементів другого відрізка, призначеного для обчислення на другому процесорі, можна знайти аналогічно, розв’язуючи рівняння:
, тоді кількість елементів другого відрізка, призначеного для обчислення на другому процесорі, можна знайти аналогічно, розв’язуючи рівняння: ,
, .
.