
|
|
Корреляционный анализ в EXCELСтр 1 из 3Следующая ⇒ Корреляционный анализ в EXCEL
Корреляционный анализ в EXCEL
Методы определения объема выборки В рамках международной практики применяются различные подходы к определению совокупности данных, кᴏᴛᴏᴩая в дальнейшем подвергается выборочной проверке: · оценка влияния таких факторов, как фактор уверенности, общая стоимость генеральной совокупности; допустимая и ожидаемая сумма ошибок; · оценка риска выборки, ожидаемой и допустимой степени отклонений; · определение числа элементов выборки, имеющих сальдо; · нахождение числа элементов выборки, основанных на оборотах по счетам бухгалтерского учета. Изучим каждый, подход подробнее. Таблица 6.1 Ошибки, различаемые в аудиторской выборке
Риск выборки возникает, когда вывод аудитора, сделанный на основе отобранной совокупности, отличается от вывода при применении идентичных процедур аудита к генеральной совокупности в целом. В аудите различают два типа рисков выборки. Риск первого типа представляет собой риск того, что аудитор сделает следующие заключения: § риск средств внутреннего контроля ниже, чем в действительности (при выполнении тестов средств внутреннего контроля); § существенной ошибки не существует, вопреки тому, что в действительности она есть (при выполнении аудиторских процедур проверки по существу). Риск данного типа оказывает влияние на надежность аудита и с большой степенью вероятности может привести к ненадлежащему аудиторскому мнению. Риск второго типа представляет собой риск того, что аудитор придет к следующим выводам: § риск средств внутреннего контроля выше, чем в действительности (при выполнении тестов средств внутреннего контроля); § имеет место существенная ошибка, тогда как в действительности ее не существует (при выполнении аудиторских процедур проверки по существу). Риск такого типа оказывает влияние на эффективность аудита, поскольку он обычно приводит к дополнительной работе по установлению того, что первоначальные выводы были неверны. Риск, не зависящий от аудиторской выборки, является следствием факторов, которые приводят аудитора к ошибочному выводу по любым причинам, кроме тех, которые связаны с объемом выборки (т.е. числом отбираемых для проверки элементов). Риск, связанный с выборкой, может быть снижен путем увеличения объема отбираемой совокупности, а не связанный — путем надлежащего планирования задания, текущего контроля за работой аудиторов и проверки выполнения процедур. Различают следующие виды выборки: § представительная (репрезентативная) — элементы ее генеральной совокупности имеют равную вероятность быть отобранными; § непредставительная (нерепрезентативная) — элементы ее генеральной совокупности не имеют равную вероятность быть отобранными. Аудитор полагается на свое профессиональное суждение при отборе элементов. Элементами выборки могут быть натуральные объекты (например, первичные учетные документы) или показатели в денежном выражении. Аудитор должен стараться сформировать репрезентативную совокупность путем отбора элементов выборки, которые обладают характеристиками, типичными для генеральной совокупности, так как целью выборки является получение выводов по всей генеральной совокупности. При формировании проверяемой совокупности необходимо исключать предвзятость. Для построения выборки аудитор определяет метод отбора элементов, который будет использоваться при тестировании с целью получения аудиторских доказательств. В соответствии с Федеральным правилом (стандартом) № 16 «Аудиторская выборка» различают следующие методы отбора элементов: 1. отбор всех элементов (сплошная проверка); 2. отбор специфических (определенных) элементов; 3. отбор отдельных элементов (формирование аудиторской выборки). Первый метод отбора не применяют при проведении тестов средств внутреннего контроля, его используют в отношении аудиторских процедур проверок по существу. Сплошная проверка целесообразна в следующих случаях: § генеральная совокупность состоит из небольшого числа элементов наибольшей стоимости; § неотъемлемый риск и риск средств контроля являются высокими, а другие средства не позволяют получить достаточные надлежащие аудиторские доказательства; § повторяющийся характер расчетов или иных процессов, осуществляемых с помощью компьютерной системы бухгалтерского учета, делает сплошную проверку эффективной с точки зрения соотношения затрат и результатов. Второй метод предполагает отбор специфических элементов. Различают специфические элементы наибольшей стоимости и ключевые элементы. К элементам наибольшей стоимости относят суммы сальдо счетов, которые превышают планируемую степень точности, т.е. уровень существенности. При определении ключевых элементов аудитор отбирает сальдо счетов, существенных качественно, т.е. элементы, по которым возможна наибольшая вероятность наличия ошибки или искажения, и элементы существенные количественно, т.е. элементы (например, месяцы), имеющие наибольший оборот по данному счету в отчетном периоде. При использовании данного метода осуществляется построение непредставительной выборки, в связи с чем результаты, полученные по отобранным элементам, не могут быть экстраполированы на всю совокупность. Третий метод представляет собой отбор элементов для построения представительной выборки. Прежде чем отобрать элементы, необходимо определить объем выборки. Выбор метода или сочетания методов отбора элементов зависит от обстоятельств проверки, в частности аудиторского риска и эффективности аудита. Объем выборки определяют с применением специальных формул теории вероятности и математической статистики либо на основе профессионального суждения аудитора. В этом случае аудитор должен проанализировать, снижен ли риск выборки до приемлемо низкого уровня. Чем ниже риск, связанный с использованием выборочного метода, который готов принять аудитор, тем больше необходимый объем выборки (табл. 6.2). Таблица 6.2. Факторы, влияющие на объем выборки
Выборка является основой тестирования средств внутреннего контроля и процедур проверки по существу. В приложении 1 к Федеральному правилу (стандарту) аудиторской деятельности № 16 «Аудиторская выборка» [33] определены факторы, влияющие на объем отобранной совокупности для тестирования средств внутреннего контроля, которые должны рассматриваться вместе (табл. 6.3). Таблица 6.3. Факторы, влияющие на объем отобранной совокупности для тестирования средств внутреннего контроля
Факторы, влияющие на объем отобранной совокупности для проверки по существу, которые должны рассматриваться вместе, приведены в Приложении 2 к Федеральному правилу (стандарту) аудиторской деятельности № 16 «Аудиторская выборка» (табл. 6.4). Число элементов выборки, которая состоит из элементов, основанных на сальдо счетов, определяют по следующей формуле [84]: ЭВ = (ОС — ЭН — ЭК)*КП / (0,75*УС) § ОС — общий объем проверяемой совокупности в стоимостном (денежном) выражении; § ЭН — суммарное стоимостное (денежное) выражение элементов наибольшей стоимости; § ЭК — суммарное стоимостное (денежное) выражение ключевых элементов; § КП — коэффициент проверки; § УС — уровень существенности. Таблица 6.4. Факторы, влияющие на объем отобранной совокупности для проверки по существу
Значения коэффициента проверки, используемого при определении элементов выборки в зависимости от состояния систем бухгалтерского учета и внутреннего контроля аудируемого лица, представлены в прил. 10. При определении элементов выборки для отбора по номеру документа используется следующая формула (при условии, что наибольшие и ключевые значения в изучаемой совокупности отсутствуют): ЭВ = ГС*КП / УС § ГС — общее число документов генеральной совокупности. В этом случае аудируемое лицо должно обеспечить выполнение требования обязательного присвоения номера всем первичным учетным документам. К методам отбора элементов для построения выборки согласно Федеральному правилу (стандарту) № 16 относятся: случайный, систематический и бессистемный отбор. При построении выборки случайным отбором используется статистический к выборочной проверке, т.е. статистическая выборка. Она предполагает любой подход к выборке, который имеет следующие характеристики: случайный (либо систематический со случайным выбором начальной точки) отбор тестируемой совокупности; применение теории вероятности для оценки результатов выборки, включая оценку риска, который связан с использованием аудиторской выборки. При нестатистической выборке для отбора статей аудитор опирается на профессиональное суждение. Построение выборки случайным отбором проводится с использованием таблицы (см. прил. 10) или генератора случайных чисел. Номер документа элементов, попавших в выборку случайным отбором, определяют по формуле НД — (ЗК — ЗН)СЧ + ЗН § ЗК — значение конечное, т.е. номер последнего документа генеральной совокупности; § ЗН — значение начальное, т.е. номер первого документа генеральной совокупности; § СЧ — случайное число. Числа берут из таблицы случайных чисел. Первое число выбирают случайно, а следующие числа — по порядку, т.е. по столбцу или строке. Рассмотрим построение выборки на примере ОАО «Факел» по статье «Сырье, материалы и другие аналогичные ценности» формы № 1 «Бухгалтерский баланс». Общий размер проверяемой совокупности в соответствии со строкой «Запасы» составляет 1904,0 тыс. р. Число документов за проверяемый период по бухгалтерскому счету «Материалы» — 1500. Документы пронумерованы с 1 по 1500. Наибольшие и ключевые элементы по рассматриваемой статье отсутствуют. По данным предыдущей проверки было установлено, что система внутреннего контроля отвечает необходимым требованиям, однако были выявлены ошибки по счетам бухгалтерского учета, поэтому коэффициент проверки равен 2. Уровень существенности по данной статье составляет 46 тыс. р. (прил. 8 строка «Сырье, материалы и другие аналогичные ценности»). Рассчитаем число элементов выборки: ЭВ = 1904*2 / 46 = 83 Таким образом, число элементов, по которым будет построена выборка по статье «Сырье, материалы и другие аналогичные ценности», составляет 83 документа. Далее методом случайного отбора определяем, какие номера документов попадут в выборку, используя формулу 6.3 и таблицу случайных чисел. Случайное число выбирается случайным образом, в нашем случае это будет значение из строки 2 второго столбца. Далее случайные числа берутся по столбцу (табл. 6.5). Таблица 6.5. Определение номера четырех документов методом случайного отбора
Остальные номера документов, попавших в выборку, определяются аналогично. Систематический отбор построения выборки предполагает отбор элементов из генеральной совокупности через определенный интервал. Интервал определяют по следующей формуле: ИНТ = (ЗК — ЗН) / ЭВ § ЭВ — число элементов выборки без учета элементов наибольшей стоимости, т.е. ключевых элементов. Используя данную формулу, определим интервал для рассматриваемого примера: ИНТ = (1500 — 1) / 115 = 13 Для построения статистической выборки с использованием интервала стартовая точка, т.е. первый номер документа, попавшего в выборку, определяется случайным отбором по формуле СТ = ИНТ * СЧ + ЗН Определим стартовую точку случайным отбором с использованием формулы (6.5). Случайное число выберем по строке 6 графы 4 таблицы случайных чисел (см. прил. 10): СТ = 13*0,1927 + 1 = 4. В данном случае стартовая точка соответствует 4. Номера других документов, попавших в выборку, вычисляют по следующей формуле: НД — СТ + ИНТ(а — 1), § а — порядковый номер элемента выборки (табл. 6.6). Таблица 6.6. Определение номера первых четырех документов методом случайного отбора первого номера документа
Бессистемный отбор проводится без применения какой-либо систематизации. Его не используют при статистической выборке. Аудитору в отношении выборки необходимо: анализировать каждую ошибку, экстраполировать результат на всю совокупность, оценить риски выборки. В соответствии с Федеральным стандартом № 16 аудитор должен проанализировать результаты выборочной проверки, характер и причину любых выявленных ошибок, а также их возможное воздействие на цели конкретного теста и другие области аудита. При тестировании средств внутреннего контроля аудитор уделяет основное внимание организации и эффективности их функционировании, а также оценке их риска. Если при этом выявляются ошибки, то аудитор должен проанализировать: § прямое влияние выявленных ошибок на достоверность финансовой (бухгалтерской) отчетности; § надежность системы бухгалтерского учета и внутреннего контроля, а также ее влияние на планируемые аудиторские процедуры. В случае если анализ обнаруженных искажений установил, что у многих из них есть общие характеристики, аудитор может принять решение выявить все элементы генеральной совокупности, которые обладают общей характеристикой, и провести аудиторские процедуры к сформированной страте. Аудитор признает ошибку аномальной, когда он в достаточной мере уверен, что она не является представительной по отношению к генеральной совокупности. По результатам аудиторских процедур по существу проверки элементов отобранной совокупности аудитор должен экстраполировать выявленные ошибки, оценивая их полную возможную величину во всей генеральной совокупности. Аудитору необходимо проанализировать воздействие экстраполированной ошибки на цели конкретного теста и на другие области аудита, а также сравнить ее с допустимой ошибкой. Допустимая ошибка для процедуры проверки по существу является допустимым искажением и представляет сумму, меньшую или равную существенности на уровне отдельных показателей финансовой отчетности или сальдо счетов, групп однотипных операций. Полная прогнозная величина ошибки определяется по формуле: ОШп = ОШв * (ОС — ЭН — ЭК) / СЭВ + ОШн + ОШк § ОШв — фактическая величина ошибок, выявленная при выборке; § ОС — общий объем проверяемой совокупности; § ЭН — сумма стоимости элементов наибольшей стоимости; § ЭК — сумма стоимости ключевых элементов (т.е. имеющих большую вероятность наличия искажений); § СЭБ — суммарная стоимость элементов выборки; § ОШн — фактическая величина ошибок при проверке элементов наибольшей стоимости; § ОШк — фактическая величина ошибок при проверке ключевых элементов. При отсутствии наибольших и ключевых элементов в рассматриваемой совокупности полная прогнозная ошибка рассчитывается по следующей формуле: ОШп = ОШв * ОС / СЭВ В зависимости от соотношения величины полной прогнозной ошибки и уровня существенности возможны различные действия аудитора (табл. 6.7). Таблица 6.7. Зависимость действий аудитора от величины полной прогнозной ошибки
Если анализ результатов проверки отобранной совокупности показывает, что необходимо пересмотреть предварительную оценку соответствующей характеристики генеральной совокупности, то аудитор может: § обратиться к руководству аудируемого лица с просьбой проанализировать выявленные ошибки, рекомендовать руководству аудируемого лица принять меры к обнаружению в данной области учета других ошибок, а также произвести необходимые корректировки; § видоизменить запланированные аудиторские процедуры; § рассмотреть влияние результатов проверки отобранной совокупности на выводы, содержащиеся в аудиторском заключении. В рабочих документах отражаются все стадии проведения выборки и анализ ее результатов
http://зачётка.рф/book/3575/140886/АУДИТОРСКАЯ%20ВЫБОРКА.html#4 http://old.ipbr.org/?page=vestnik&vestnik=2011-03&pvp#5 http://www.docaudit.ru/programms/obligatory/ka/user_guid/2/23/2313/ http://www.coolreferat.com/%D0%90%D1%83%D0%B4%D0%B8%D1%82%D0%BE%D1%80%D1%81%D0%BA%D0%B0%D1%8F_%D0%BF%D1%80%D0%BE%D0%B2%D0%B5%D1%80%D0%BA%D0%B0_%D0%B4%D0%B5%D0%BD%D0%B5%D0%B6%D0%BD%D1%8B%D1%85_%D1%81%D1%80%D0%B5%D0%B4%D1%81%D1%82%D0%B2_%D0%B2_%D0%BA%D0%B0%D1%81%D1%81%D0%B5_%D0%BF%D1%80%D0%B5%D0%B4%D0%BF%D1%80%D0%B8%D1%8F%D1%82%D0%B8%D1%8F_%D0%BD%D0%B0_%D0%BF%D1%80%D0%B8%D0%BC%D0%B5%D1%80%D0%B5_%D0%97%D0%90%D0%9E_%D0%9C%D0%B8%D0%BA%D0%BE%D1%8F%D0%BD%D0%BE%D0%B2%D1%81%D0%BA%D0%B8%D0%B9_%D0%BC%D1%8F%D1%81%D0%BE%D0%BA%D0%BE%D0%BC%D0%B1%D0%B8_%D1%87%D0%B0%D1%81%D1%82%D1%8C=8 Статистический метод Выборка формируется на основе применения любого подхода к выборке, который имел бы следующие характеристики:
При статистической выборке элементы для выборки отбираются случайным образом, то есть так, чтобы у каждого элемента была бы некоторая ненулевая вероятность быть выбранным. Для случайного отбора используется таблица случайных чисел или генератор случайных чисел — программный продукт в электронно-вычислительной технике. Таблица случайных чисел представляет собой список случайных чисел в табличной форме для удобства их выбора. При использовании таблицы случайных чисел первая точка для проведения проверки выбирается произвольным методом. Эта цифра является номером документа, который подлежит проверке. Затем, начиная с этого номера, берется подряд вниз по столбцу необходимое число цифр (элементов) таблицы. Таблица, использованная в данной статье, взята из Методических рекомендаций, разработанных в рамках проекта ТАСИС «Реформа российского аудита». В этой таблице 30 столбцов и 60 строк (табл. 1). Таблица 1. Фрагмент таблицы случайных чисел
Рекомендуется первое случайное число в данной таблице находить случайным же образом. Выбираем произвольно два числа, первое из которых должно находиться в диапазоне от 1 до 30, а второе — в диапазоне от 1 до 60. На пересечении соответствующего столбца и строки с такими координатами находится искомое случайное число. Использование генератора случайных чисел несколько проще. Например, для получения случайных чисел в Excel в первую ячейку вводится функция «=случмежду» и устанавливаются нижняя и верхняя границы диапазона. Получаем первое число. Это номер первого документа выборки. Для получения следующих номеров используем простой прием «протяжки». Для этого устанавливаем курсор в первую ячейку на черный квадрат в правом нижнем углу ячейки. Нажимаем на левую кнопку мышки и, не отпуская ее, идем вниз по колонке до нужной ячейки — в нашем примере до 10-й. Отпускаем кнопку мышки. В ячейках получаем 10 случайных чисел. Эти числа следует зафиксировать, так как любое действие с вашей стороны в ячейке таблицы будет изменять полученные случайные числа. Колонка полученных чисел после протяжки остается выделенной. Ставим курсор на выделение, нажимаем правую кнопку мышки и выбираем функцию «копировать». Скопированные ячейки выделяются бегущей рамкой. Переходим в соседнюю колонку. Нажимаем правую кнопку мышки и во всплывающем окне выбираем функцию «специальная вставка». Нажимаем левую кнопку. Появляется окно, где выбираем функцию «значения», нажимаем левую кнопку, затем ОК. В колонке появляются 10 значений, которые будут зафиксированы и уже не будут изменяться в дальнейшем. Эти числа являются номерами документов, которые необходимо проверить. Может оказаться так, что выпадут два одинаковых номера. В этом случае берут для проверки следующий или предыдущий номер. Пример 1 Проверяется совокупность документов, нумерация которых начинается с № 300 и заканчивается № 2500. Необходимо отобрать 10 документов. Необходимым условием является, чтобы проверяемые документы были пронумерованы подряд и не обязательно начиная с единицы. Вариант 1. Используем таблицу случайных чисел от 0 до 1 (табл. 1). Выбираем первую цифру, например, 0,0441 (первый столбец, вторая строка). Для получения остальных чисел берем подряд вниз по колонке еще 9 чисел. Как видим, эти числа не соответствуют номерам совокупности. Нам нужны случайные числа в границах от 300 до 2500. Чтобы привести случайные числа в соответствие с номерами совокупности, умножаем случайное число из таблицы на разность 2500 (конечное значение) и 300 (начальное значение), то есть на 2200. Затем к полученному результату прибавляем начальное значение 300. Возьмем первое случайное число 0,0441. 0,0441×2200 + 300 = 397. Таким же образом поступаем с остальными девятью числами. Получаем номера документов, составляющих выборку (табл. 2). Таблица 2. Выборка документов
Вариант 2. Для формирования выборки применяем генератор случайных чисел в Excel. В первую ячейку вводим функцию «=случмежду(300;2500)» и методом «протяжки» получаем 10 случайных чисел. Допустим, получены числа 1365, 903, 1371, 996, 957, 1435, 2285, 711, 394 и 1337. Это и есть номера документов, которые нужно проверить. Не следует забывать фиксировать полученные значения. Систематический отбор Систематический отбор также относится к статистическим методам. Для систематического отбора число элементов в генеральной совокупности делится на объём отобранной совокупности. При этом получается число, которое называется интервалом выборки. Пример 2 Имеем для проверки совокупность с № 300 до № 2500, то есть 2200 документов. Проверке подлежат 100 документов. Делим 2200 на 100 и получаем число 22. Это интервал выборки, который указывает, что проверке подлежит каждый 22-й документ. После этого случайным образом выбираем номер первого документа для проверки, например с применением таблицы случайных чисел. Допустим, этот номер будет 20. Затем к этому числу прибавляем число 22, получаем следующий номер для проверки 42, к этому номеру опять прибавляем 22 и получаем следующий номер 64 и т.д. Номера для проверки 20, 42, 64, 86, 108 и т.д., пока не будут отобраны все 100 документов. Может оказаться, что для отбора всех документов не хватит номеров в отбираемой совокупности. В этом случае продолжение счета переходит в начальные номера до тех пор, пока не будут отобраны все запланированные 100 документов. Оценка результатов Поскольку целью выборки является получение выводов по всей генеральной совокупности, аудитор старается сформировать репрезентативную (представительную) совокупность путем отбора элементов выборки, обладающих характеристиками, типичными для генеральной совокупности. Проверяемая совокупность элементов должна формироваться таким образом, чтобы исключалась предвзятость. Такими свойствами обладает статистическая выборка. Оценка результатов проведенной проверки с применением статистических методов всей совокупности (экстраполяция) проводится по следующей формуле (так называемая прогнозируемая ошибка): Сумма нарушений Прогнозируемая ошибка = --------------------------- х Сумма совокупности Сумма проверенных элементов Пример 3 При нестатистической выборке аудитор для отбора элементов опирается на профессиональное суждение. Пусть для некоторой проверяемой совокупности суммарная стоимость всех элементов составляет 64 000 000 руб., уровень существенности — 3 000 000 руб. Допустим, что в ходе проверки были рассмотрены элементы репрезентативной (то есть с применением статистического метода) выборки на общую сумму 595 000 руб., а сумма обнаруженных ошибок составляет 17 000 руб. В этом случае получаем: 17 000 руб.: 595 000 руб. х 64 000 000 руб. = 1 828 571 руб. Полученную прогнозируемую ошибку сравниваем с установленным уровнем существенности. Она значительно меньше установленного уровня существенности (3 000 000 руб.). Следовательно, проверяемая совокупность достоверна. Нестатистическая выборка Эта выборка формируется с использованием подхода, не соответствующего характеристикам, которые определяют статистическую выборку. При нестатистической выборке аудитор для отбора элементов опирается на профессиональное суждение. Как уже говорилось, отбор специфических элементов не является выборкой, так как выводы по результатам процедур, применяемых к отобранным таким способом элементам, не могут быть распространены на всю генеральную совокупность. Нестатистическая выборка может формироваться с использованием следующих невероятностных методов:
Поскольку при применении невероятностных методов получаем нерепрезентативную (непредставительную) выборку, то экстраполяция величины полученной ошибки на генеральную совокупность с применением статистических (математических) методов не используется. Результаты оцениваются в соответствии с аудиторским мнением о достоверности проверенной совокупности. Комбинированный метод Как правило, статистические методы в чистом виде на практике не применяются. Обычно применяется комбинированный метод, который состоит из сочетания сплошного, статистического и нестатистического методов. Например, из всей проверяемой совокупности отбираются элементы, которые проверяются сплошным методом:
Суммы этих элементов вычитаются из суммы всей совокупности, а выборочная проверка осуществляется из оставшейся совокупности, допустим, статистическим методом. В оставшейся совокупности проводится экстраполяция. При этом найденные нарушения в элементах выше уровня существенности и специфических элементах не экстраполируются, так как проверка была проведена сплошным методом, и сумма нарушений при этом является абсолютной. В этом случае при оценке совокупности на достоверность сумма нарушений складывается из сумм:
Полученная сумма сравнивается с уровнем существенности, и если она ниже, делается вывод о достоверности проверяемой совокупности. Другой пример. Можно отобрать элементы, стоимость которых превышает определенную величину, чтобы подвергнуть проверке большую часть общей суммы (например, не менее 70%). Если таких элементов слишком много для проведения сплошной проверки, в этой совокупности проводится выборочная проверка одним из описанных способов. Стратификация При проведении выборки может использоваться метод стратификации. Это процесс деления генеральной совокупности на страты (подмножества), каждая из которых представляет собой группу элементов выборки со сходными характеристиками (чаще всего используется стоимость). Когда элементы генеральной совокупности широко варьируются по стоимости, целесообразно сгруппировать элементы, сходные по стоимости, в отдельные страты. При надлежащей стратификации генеральной совокупности общий объём отобранных совокупностей по стратам, как правило, меньше, чем объём отобранной совокупности, когда для всей генеральной совокупности формировалась бы одна отобранная совокупность. Объём выборки При определении объёма выборки (количества отбираемых для проверки элементов) необходимо проанализировать риск, связанный с использованием выборочного метода. Уровень риска, связанного с использованием выборочного метода, который аудитор готов принять, оказывает прямое влияние на объём выборки. Если установлен высокий риск хозяйственной деятельности и риск средств контроля, необходимо увеличение выборки. При низком уровне риска объём выборки уменьшается. Объём выборки может определяться с применением специальных формул, полученных на основе теории вероятности и математической статистики, либо определяться на основе профессионального суждения аудитора. Следует отметить, что объём выборки не зависит от числа элементов генеральной совокупности. С точки зрения статистики 1000 элементов или 10 000 элементов оказывают ничтожно малое влияние на объём выборки. Объём выборки при применении статистических методов определяется той степенью надежности результатов, которую аудитор хочет обеспечить. Как правило, для этого используются степень надежности с 90%-ной или 95%-ной вероятностью. Это означает, что результат, который получен при проверке, надежен с 90%-ной или 95%-ной вероятностью, и только с 10%-ной или 5%-ной вероятностью аудитор мог ошибиться. Если уровень риска низкий, аудитор может уменьшить выборку. При этом достоверность полученных результатов будет с меньшей вероятностью (например, с вероятностью 70 или 80%). Расчет объёма выборки описывается в специальной литературе, например, «Аудит Монтгомери» под редакцией проф. Я.В. Соколова и многих других. Служба внутреннего аудита должна быть обеспечена подробной методикой проведения выборочной проверки при оценке достоверности бухгалтерской (финансовой) отчётности
Корреляционный анализ в EXCEL
©2015- 2026 zdamsam.ru Размещенные материалы защищены законодательством РФ.
|
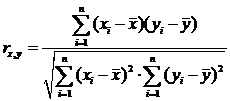
 Вычисленное по этой формуле значение tнабл сравнивается с критическим значением t-критерия, которое берется из таблицы значений t Стьюдента с учетом заданного уровня значимости и числа степеней свободы (n-2).
Вычисленное по этой формуле значение tнабл сравнивается с критическим значением t-критерия, которое берется из таблицы значений t Стьюдента с учетом заданного уровня значимости и числа степеней свободы (n-2).












