
|
|
Надежность теста. Теория надежности.Надежность одно из основных понятий психодиагностики и, вместе с тем, одно из самых сложных. К.М. Гуревич отмечает «Надежность - крайне сложное и многоплановое понятие, одна из основных функций которого - оценить постоянство показателей тестовых испытаний. В принципе можно сказать, что надежность должна обосновывать ошибку измерения - она должна показывать, какая часть изменчивости показателей ошибочна» [17, стр. 27]. На практике понятие " надежности" имеет два значения: одно связано с воспроизводимостью результатов тестирования, другое – с внутренней согласованностью теста [8]. На понятии " надежность " основывается вычисление " ошибки измерения ", с помощью которой определяются вероятные пределы колебания измеряемой величины, возникающей под воздействием случайных факторов. Можно сказать, что в широком смысле слова надежность теста показывает, в какой мере индивидуальные различия в тестовых результатах являются «истинными», а в какой мере они могут быть отнесены к случайным ошибкам. Надежность это помехоустойчивость теста, независимость его результатов от действия всевозможных случайных факторов. К числу таких факторов следует отнести: - разнообразие внешних материальных условий тестирования (время суток, освещенность, температура, наличие посторонних звуков и т.п.); - динамичные внутренние факторы, по-разному действующие на разных испытуемых в ходе тестирования (настроение, утомление, другие особенности состояния испытуемого); - информационно-социальные факторы (контакт с психологом, наличие других людей, сама ситуация тестирования и пр.). Разнообразие и изменчивость этих факторов так велики, что они обусловливают появление у каждого испытуемого непрогнозируемого по размеру и направлению отклонения измеренного тестового балла (т.е. такого, который можно было бы получить в идеальных условиях). Поэтому, общий разброс (дисперсию) результатов произведенных измерений можно представить как результат суммы двух источников разнообразия: самого измеряемого свойства и нестабильности измерительной процедуры, обусловливающей наличие ошибки измерения. Это нашло свое выражение в классической формуле, описывающей надежность теста в виде отношения истинной дисперсии к дисперсии эмпирически зарегистрированных баллов [1, 13, 15, 16]:
α = 1 - где: α - надежность теста;
Итак, эта формула читается так: надежность теста равняется единице минус отношение дисперсии ошибки к дисперсии эмпирически зарегистрированных баллов. Из этой формулы получаем, что стандартная ошибка измерения равна: В общем случае можно сказать, что ошибку измерения в психометрике определяют с помощью корреляционных методов, которые дают возможность оценить надежность (или, что одно и тоже точность) через устойчивость и согласованность результатов, полученных как на уровне целого теста, так и на уровне отдельных его пунктов. Рассмотрим вначале надежность теста, связанную с воспроизводимостью результатов тестирования – так называемую, "ретестовую" или "диахронную" надежность. Затем, проанализируем понятие "надежности", связанное с внутренней согласованностью теста. В завершении этого параграфа проанализируем критический взгляд на такие понятия, как "ретестовая надежность ", "синхронная надежность" и достаточно подробно остановимся на "теории надежности", позволяющей психологу, разрабатывающему или использующему тест, понять всю важность данного параметра теста. 1. Ретестовая (диахронная) надежность (надежность теста, как целого). Самый естественный способ определить надежность результатов теста - использовать тот же тест второй раз. В этом случае коэффициент надежности просто равен корреляции между двумя результатами, полученными на одних и тех же испытуемых в каждом из двух случае проведения теста. Приводя в руководстве к тесту его ретестовую надежность, всегда следует указывать, в каком интервале времени она измерена. Как правило, выбирают этот интервал исходя из следующих соображений. На дисперсию ошибки тестовых результатов обычно влияют случайные колебания с периодом от нескольких часов до нескольких месяцев. Поэтому, определяя тип тестовой надежности, стараются придерживаться небольших временных интервалов. (Например, при тестировании маленьких детей этот период должен быть еще короче, чем у взрослых испытуемых, поскольку в раннем детстве возрастные изменения происходят в течение месяца и даже быстрее.). В целом для любого типа испытуемых интервал между двумя последовательными применениями теста обычно не должен быть меньше двух недель и превышать 6 месяцев [1]. Следует учесть, что данное понятие надежности в основном характеризует выполнение теста самого по себе, а не тестируемую область поведения (т.е. характеризует стабильность теста, как измерительного инструмента). В качестве коэффициента корреляции для этого типа надежности обычно подсчитывают известный коэффициент корреляции произведения моментов Пирсона [1, 15]:
r - коэффициент корреляции между результатами двух тестовых испытаний;
∑ -сумма произведения отклонений от средних значений каждого испытуемого в первом и втором испытаниях; N - число испытуемых. Оценка значимости этого коэффициента производится следующим образом: - вычисляется квадратическая ошибка коэффициента корреляции по формуле
при малом числе наблюдений n берется "числом степеней свободы", обычно как n-2, и ошибка коэффициента корреляции вычисляется так
Ошибка коэффициента корреляции приближается к нулю, когда коэффициент корреляции приближается к единицы. Таким образом, при r =1 независимо от знака, mr =0. Значение коэффициента корреляции оценивается с помощью критерия достоверности, который представляет отношение этого коэффициента к своей средней квадратической ошибке, т.е.
Далее полученный критерий достоверности (t) сравнивается с табличным (см. приложение 2). Напомним из статистики, что если необходимо оценить достоверность различий, наблюдаемых между двумя коэффициентами корреляции, формула для расчета критерия достоверности принимает вид
Знание надежности теста позволяет уточнить "истинное" значение тестового балла индивида, применяя формулу:
r - эмпирическая надежность теста; Например, что испытуемый получил балл IQ по шкале Стенфорд-Бине равный 120 нормализованным очкам, Все выше сказанное касалось тестовс интервальными шкалами, для шкал порядка в качестве меры ретестовой надежности используется ранговый коэффициент корреляции Спирмена:
Оценка значимости коэффициента корреляции Спирмена производится аналогичным образом через расчет квадратической ошибки по формуле
Теперь проанализируем понятие "надежности", связанное с внутренней согласованностью теста, и которое находит свое выражение в таких понятиях, как "одномоментная" или "синхронная" надежность. 2. Одномоментная (синхронная) надежность (согласованность). Этот тип надежности независим от устойчивости (поскольку не имеет временного интервала) и имеет особую содержательную и операциональную природу. Ее надо понимать именно как согласованность частей теста. В психотехнике этот вид надежности часто называют коэффициентом внутренней согласованности теста. Для того, чтобы ее измерить следует скоррелировать между собой параллельные формы теста. Особо отметим, что проводится только однократное применение теста (а уже потом его искусственно разбивают на две параллельные формы). Чаще всего параллельные формы теста получают расщеплением составного теста на "четную" и "нечетную" половины: к первой относятся все четные пункты заданий теста, ко второй - соответственно, все нечетные. По каждой половине рассчитываются суммарные баллы и между двумя рядами баллов подсчитываются допустимые коэффициенты корреляции [1, 15]. Если параллельные формы тесты не нормализованы, то предпочтение отдается ранговой корреляции. При подобном расщеплении получается коэффициент корреляции, относящийся к половинам теста. Для того, чтобы найти надежность (согласованность) целого теста, пользуются формулой Спирмена-Брауна:
Следует отметить, что делить тест на две части можно разными способами, и каждый раз получаются несколько разные коэффициенты; поэтому в психометрике предложен способ оценки синхронной надежности, который соответствует разбиению теста на такое количество частей, сколько в нем отдельных пунктов. В этом случае, синхронную надежность теста можно оценить с помощью формулы Кронбаха:
α - коэффициент Кронбаха; k - количество пунктов (заданий) теста;
В 1957 году Дж. Китс предложил следующий критерий для оценки статистической значимости коэффициента α (1):
k - количество пунктов; n - количество испытуемых; α - надежность. Вычисленная статистика Как видно, формула Кронбаха позволяет оценить взаимную согласованность пунктов теста, используя только подсчет дисперсий (вся важность этой формулы для психометрики станет понятна после анализа теории надежности). Коэффициент α позволяет также оценить и среднюю корреляцию между i -тым и j -тым произвольными пунктами теста, так как он связан с этой средней корреляцией следующей формулой: α = где Из всего вышесказанного вытекает возможность повысить синхронную надежность теста, увеличивая численность пунктов теста (в k раз). Из формулы видно, что при больших k малое значение r - может сочетаться с высокой надежностью (например: пусть r = 0,1, аk = 100, тогда согласно формуле (***) имеем: α = 0,91). При прочих равных условиях, чем больше заданий содержит тест, тем выше его надежность. Все приведенные формулы относятся к оценке надежности одномерного теста, направленного на измерение одной характеристики. Перейдем теперь к обсуждению "теории надежности" тестов [10], опираясь на понятия изложенные выше. Теория надежности тестов. Известно [1, 2, 8, 10, 15, 16], что оценки полученные индивидуумами по психологическим тестам используются как численные выражения абстрактных психологических понятий. По этой причине важно иметь уверенность в том, что эти оценки по любому психологическому тесту, во-первых, имеют небольшую случайную ошибку измерения (что говорит о высокой статистической надежности) и, во-вторых, действительно измеряют то, что они ставят целью измерить (т.е. имеют высокую валидность, которая подробнее будет рассмотрена позже). По определению К. Купера [10], анализ понятий систематической и случайной ошибок измерения приводит к важному аспекту психометрики, известному как теория надежности. Следует напомнить, что главнейшей характеристикой психологических тестов является то, что каждая шкала теста должна оценивать одну (и только одну!) психологическую характеристику. Большинство тестов (составленных по типу опросников) обрабатываются суммированием по ключу ответов на каждое задание и интерпретировать значение набранного балла можно только в том случае, если все задания в шкале измеряют одну и ту же базовую психологическую характеристику. Если все утверждения измеряют одну психологическую характеристику, то чем выше оценки испытуемых, полученные по данному тесту, тем более развита у них эта характеристика. Однако если задания теста измеряют две и более совершенно разные характеристики, такая интерпретация невозможна. Поэтому очень важно убедиться в том, что все утверждения в определенной шкале оценивают одну (и только одну!) психологическую характеристику. Существуют два основных способа убедиться в этом. Теория надежности эта теория, в которой изначально предполагается, что все задания теста предназначены для того, чтобы измерять одну и ту же характеристику; кроме того, теория надежности позволяет проверить, так ли это в действительности. Для того чтобы лучше понять суть систематической и случайной ошибок, рассмотрим аналогию психологических и физических измерений. Физические измерения. Измерение предметов в повседневной жизни может проводиться с различной точностью, при этом всегда существует некоторая "ошибка измерения", связанная с определением физических параметров предмета, которая составляет небольшой процент от измеряемого параметра. Как правило, величина этой ошибки зависит от точности используемого измерительного инструмента. В частности, в случае измерения длины (например, стола) могут использоваться - рулетка, сантиметр или линейка, которые имеют свою, заданную ошибку измерения. Ошибка, связанная с проведением каждого измерения, может рассматриваться как случайная в том смысле, что она будет изменяться случайным образом от одного измерения к другому. К примеру, если бы измеряли некоторый стол одним и тем же инструментом 100 раз, его длина иногда могла оказаться равной, 155 см, в другой раз несколько меньше – 154. Однако если бы мы усреднили эти 100 измерений, они должны были бы дать более точную оценку его подлинной длины, чем та, которая получилась бы в результате одного измерения, поскольку случайные ошибки измерения имеют тенденцию нивелировать влияния друг друга при усреднении. Таким образом, ошибки измерения могут быть сведены к минимуму; при этом измерительные инструменты должны быть сконструированы так, чтобы получаемые с их помощью оценки гарантированно находились под влиянием только одной физической переменной - именно той, которую хотят измерить. Например, показатели длины, получаемые по шкале измерительной рулетки, не должны зависеть от времени дня, когда осуществляется измерение, от температуры помещения, где происходить измерение, света или фактуры измеряемого объекта или еще чего-либо, за исключением его длины. Это прямой эквивалент принципа, который заложен при использовании любого теста: измерительные инструменты должны измерять только одну (психологическую) характеристику объекта. На практике обеспечить это далеко не так просто. Допустим, что указанные выше измерительные инструменты, полностью свободны от ошибок измерения - «случайных ошибок», упоминавшихся выше. Дает ли это основание полагать, что длина стола может быть измерена с полной точностью? К сожалению, нет, поскольку ни один из этих инструментов не измеряет только длину. Сантиметр (особенно если он на тканевой основе), будет слегка вытягиваться или сжиматься в зависимости от изменения температуры и влажности, и поэтому в холодный влажный день или в сухой и жаркий он будет давать несколько различающиеся показатели. Точность других измерителей может (хотя и в очень малой степени) также зависеть от иных параметров окружающей среды. Таким образом, даже если мы примем, что все эти инструменты измеряют длину (и только ее одну), размеры, определяемые каждым из них, будут в действительности подвержены влиянию нескольких различных переменных. Назовем их источниками "систематической ошибки". В отличие от обсуждавшихся выше случайных ошибок, источники систематических ошибок не обнаруживают тенденцию к устранению, когда проводятся повторные измерения при одних и тех же физических условиях. Если мы 100 раз измеряем длину стола с помощью сантиметра в жаркий влажный день, то показатели будут всегда слегка преувеличены, поскольку измерительная лента будет коробиться. Если перечисленные три способа измерения длины стола (т.е. рулетка, сантиметр или линейка) находятся под влиянием различных физических переменных окружающей среды, то каким образом следует определять "подлинную" длину, руководствуясь этими тремя, слегка различающимися показателями? Решение, которое напрашивается само собой, состоит в том, чтобы усреднить эти три показателя, надеясь на интуитивную очевидность того, что среднее трех измерений окажется ближе к "подлинному" значению, нежели каждое из измерений, взятое поодиночке. Теперь можно подвести итог сказанному, сформулировав несколько основополагающих принципов [10]: • "Хорошие" измерительные инструменты - это такие, на которые мало влияет случайная ошибка. • "Хорошие" измерительные инструменты не подвержены влияниям источников систематической ошибки. • Проведение многократных измерений при разных физических условиях и усреднение результатов уменьшают вкладслучайных ошибок. • Усреднение измерений, полученных с помощью разных инструментов, будет вести к уменьшению вклада систематической ошибки. Измерения в психологии. В психологии ответ, который испытуемый дает на задание теста, представляет собой аналог измерения длины одним из методов, описанных выше, - с одной лишь существенной разницей, имеющей практическое значение, особенно в случае личностных измерений. Допустим, что в личностном опроснике задан вопрос: "Получаете ли вы удовольствие от шумных вечеринок?", на который можно ответить, отмечая по пятибалльной шкале ранги от – "совершенно согласен" до "совершенно не согласен". Попытаемся назвать ряд очевидных факторов, которые могут повлиять на то, какие ответы будут даваться. Среди таких факторов можно отметить следующие: - уровень экстраверсии (личностная черта); - число вечеринок, на которых недавно побывал испытуемый (фактор усталости); - возраст испытуемого; - его религиозные убеждения; - контекст, в котором задавался вопрос (диагностическая ситуация); - способ, который испытуемый использует при работе с пятибалльной шкалой: некоторые индивидуумы используют оценки 1 и 5 довольно свободно, в то время как другие никогда не обращаются к полюсам шкалы; - склонность соглашаться: установлено, что люди склонны соглашаться с утверждениями; - настроение испытуемого; - случайная ошибка: если задать ему тот же самый вопрос двумя минутами позже, можете получить несколько отличающийся ответ. Этот список, вероятно, может содержать и другие важные переменные, поскольку множество посторонних факторов определяет, каким образом индивидуум будет отвечать на вопрос в личностном тесте. Такое же заключение относится и к оценкам поведения испытуемого или к оценкам его способностей. Следовательно, любой фрагмент собранных данных при оценке индивидуальных различий, подвержен влиянию большого числа разнообразных факторов. В экспериментах, можно определить меру влияния каждого из этих факторов на индивидуальный ответ, полученный на каждый вопрос теста. Например, если вопрос предназначен для измерения такой черты, как экстраверсия, "хорошим" будет вопрос, при котором эффекты всех других переменных окажутся малы, аналогично тому, как на "хороший" показатель длины влияет расстояние, а не температура, давление воздуха или что-либо еще. В предыдущем примере, касавшемся измерения длины стола, реальная длина стола оказывала решающее влияние на показатели, получаемые с помощью сантиметра. К сожалению, в психологии это не так. Практически невозможно найти вопрос личностного теста, для которого диагностируемая черта объясняла бы более чем 20—30% вариативности индивидуальных ответов на вопросы. Большая часть вариативности обязана своим происхождением другим факторам. Проблема действительно сложная. Кажется, что невозможно придумать вопросы, которые измеряли бы черту в чистом виде, поскольку ответы индивидуумов на каждый вопрос теста подвержены влияниям множества черт, состояний, аттитюдов, настроений и везения. Можно ли надеяться, что личность или способности могут быть оценены с какой-либо степенью точности? Тем не менее, существует подход к решению этой проблемы. Например, можно привести некоторые другие вопросы, измеряющие экстраверсию, каждый из которых зависит от действия различного набора посторонних факторов. Известно [10], что Айзенк считает экстравертов социабельными, оптимистичными, разговорчивыми, импульсивными и т.д., - значит, можно сформулировать вопросы, которые измеряли бы и эти переменные тоже. Вопрос типа "Ведете ли вы себя тихо во время общественных мероприятий?" был бы подвержен влиянию определенного числа посторонних факторов, но лишь некоторые из них оказались бы теми же, что и для первого вопроса. Таким образом, если опросники конструировались из некоторого количества вопросов, на каждый из которых действует различный набор посторонних факторов, влияние последних будет иметь тенденцию к снижению, в то время как влияние черты будет накапливаться. Следовательно, чтобы разработать более точное измерение личностной черты, необходимо: - написать несколько вопросов, каждый из которых отражает разные аспекты черты и, следовательно, оказывается под воздействием различных наборов посторонних факторов; - оценить ответы на эти вопросы; - сложить эти оценки вместе. Средний балл, полученный по опроснику, неизбежно будет лучшей оценкой черты индивидуума, чем ответ на один-единственный вопрос, поскольку посторонние факторы устраняют действие друг друга. Это тот же принцип, о котором говорилось в примере с измерением длины стола. Когда мы используем этот принцип, 80%, 90% (и более) вариативности в общей оценке теста будет обусловливаться личностной чертой, что намного лучше, чем 20 или 30%, которые можно было бы получить с помощью одного отдельно взятого, даже самого хорошего, вопроса. Этот простой принцип составляет основу теории надежности, которую мы рассмотрим ниже. Прежде чем перейти к ней, необходимо ввести еще один термин – " специфическая вариативность". Вернемся к примеру с вопросом об экстраверсии. Вполне возможно, что некто, не являющийся экстравертом и не получающий удовольствия шумных компаний, и чей ответ не подвержен сильному влиянию любого другого постороннего фактора, может тем не менее просто извлекать удовольствие из "шумных" вечеринок. Другими словами, может получиться так, что некоторые индивидуумы ответят на этот вопрос полным согласием, даже, несмотря на то, что такой вариант ответа невозможно предугадать исходя из знания их установок, личностных черт и прочих обстоятельств из числа "побочных факторов". Этот факт и учитывается с помощью понятия, называемого "специфической вариативностью". Выше было показано, что отдельно взятый вопрос теста - плохое средство измерения черты и что значительно лучшую оценку ее выраженности можно получить, если мы сложим оценки, полученные по некоторому количеству вопросов, измеряющих различные аспекты черты. Представим себе, что для измерения определенной черты разработано около к вопросов, и они предъявляются приблизительно n испытуемым. Пока мы только допускаем, что все вопросы измеряют одну и ту же черту (проблемы о том, как проверить это допущение и устранить вопросы, которые плохо ее измеряют, будут рассмотрены позже). Специализированные компьютерные программы (такие, как операция оценки "надежности" в SPSS, "STADIA") могут быть использованы, чтобы вычислить по этим данным статистическую характеристику, которую различные авторы называют как: "надежность" теста, "альфа", "коэффициент альфа", "KR-20", "альфа Кронбаха" или "внутренняя согласованность". Деталей того, как вычисляется эта статистика, мы касаться не будем, но их можно найти в большинстве учебников по статистике. Как можно ожидать исходя из выше изложенного, на коэффициент альфа влияют два фактора: - средняя величина корреляции между вопросами теста. Поскольку ранее мы допустили, что различные задания теста подвержены действию разных посторонних факторов, единственная причина, по которой ответы индивидуумов на любую пару заданий должны коррелировать между собой, состоит в том, что оба вопроса измеряют одну и ту же скрытую черту. Поэтому, если все вопросы теста измеряют одну и ту же черту, корреляции между ними будут высокими и положительными; - количество вопросов в шкале. Еще раз подчеркнем, что общая цель построения шкалы из нескольких вопросов состоит в том, чтобы попытаться устранить действие посторонних факторов. Легко понять: чем больше вопросов в шкале, тем более вероятно, что все эти посторонние факторы будут устранены. В этом случае может оказаться полезной формула Спирмена - Брауна (рассмотренная выше). Она позволяет предсказать, как будет увеличиваться или уменьшаться надежность шкалы, если число вопросов в шкале меняется. Итак, надежность теста - это статистическая характеристика, которая может быть вычислена на основе любого набора данных (при условии, что выборка составляет не менее 200 испытуемых). Напомним также, что максимально возможное значение надежности составляет 1,0 (минимальное значение, при определенных обстоятельствах, может быть меньше 0). Для больших тестов квадратный корень из коэффициента альфа представляет очень близкую аппроксимацию к корреляции между оценками индивидуумов по определенному тесту и подлинной оценкой их черты. Например, коэффициент альфа равный 0,7, предполагает корреляцию равную 0,84 ( Поскольку основная цель использования психологических тестов - попытаться достичь максимально возможного приближения к подлинной оценке черты личности, из этого следует, что тесты должны иметь высокое значение коэффициента альфа. Широко распространенное эмпирическое правило указывает на то, что тест не должен использоваться, если он имеет коэффициент альфа ниже 0,7, а применять его при принятии важных решений по поводу конкретного индивидуума (например, для оценки необходимости коррекционного обучения) можно только в том случае, если величина коэффициента альфа больше 0,9. Теперь рассмотрим вопрос о содержании заданий теста. Проблема заключается в том, что довольно легко повысить среднюю корреляцию между заданиями теста, задавая несколько раз, по существу, один и тот же вопрос, слегка перефразируя его в каждом случае. Благодаря этому все посторонние факторы, которые влияют на первый вопрос, будут влиять и на второй. Поскольку оба вопроса имеют отношение к одному и тому же поведению, они будут также разделять большую часть своей специфической вариативности. Поэтому можно ожидать, что корреляция между двумя такими утверждениями будет близка к 1,0. Примерами двух таких утверждений могут быть: "Мне нравятся шумные компании" и "Мне нравятся шумные вечеринки". Поскольку эти два задания, по сути, задают один и тот же вопрос, трудно представить себе, что многие люди могли бы полностью согласиться с одним и столь же решительно не согласиться с другим. Ответы на эти два вопроса обязаны иметь высокую положительную корреляцию. При условии, что корреляции между заданиями теста обычно невелики (в лучшем случае порядка 0,2-0,4), корреляция 0,9, полученная в результате сопоставления двух фактически идентичных утверждений, существенно увеличит среднюю корреляцию по тесту. В результате этого произойдет значительное увеличение коэффициента альфа. Однако должно быть ясно, что в этом случае нарушаются два главных условия составления теста: каждый вопрос должен быть подвержен влиянию различного набора посторонних факторов, и каждый должен иметь свою собственную "уникальную" вариативность, которая не разделяется другими вопросами. Поэтому, крайне важно убедиться, что задания в каждой шкале хорошо подобраны. В некоторых случаях сделать это несложно. Например, в случае разработки словарного теста просто необходимо подбирать задания из словаря (исключая те слова, которые встречаются ниже определенного порога частотности, или слова архаичные, специальные, т.е. профессиональные, термины). Когда это сделано, единственное, что будет влиять на корреляцию между ответами на пару заданий, - степень, с которой каждое из них измеряет скрытую черту (грамотность). Не существует магической формулы для автоматической реализации этого принципа при конструировании тестов. Только от разработчика теста, зависит гарантия того, что единственной причиной, объясняющей корреляцию ответов на любую пару заданий, является та скрытая черта личности или способностей, которую они оба должны измерять. К сожалению, некоторые подходы к конструированию тестов, часто ведут к появлению большого количества искусственно завышенных корреляций, что дает, в свою очередь, завышенную оценку коэффициента альфа. Важно также обеспечить, чтобы выборка испытуемых, чьи тестовые оценки используются для вычисления коэффициента альфа, была репрезентативна группе, в которой будет применяться данный тест. Бессмысленно, например, установив величину коэффициента альфа в размере 0,9 на выборке студентов университета, затем считать, что этот тест будет годиться для использования на общей популяции, поскольку студенты университета - это не случайная выборка. Еще раз подчеркнем, что не существует количественного способа определить, будет ли тест, имеющий высокое значение коэффициента альфа на одной выборке, так же работать на другой, - это дело здравого смысла. Самое безопасное - вычислять коэффициент альфа во всех случаях использования теста, хотя в качестве предварительного условия обязательным будет тестирование большей выборки испытуемых (рекомендуется выборка - минимум 200 человек). При использовании должным образом коэффициент альфа может быть очень полезен. Выше мы использовали понятие " подлинная оценка", но не определили его значение. Рассмотрим его несколько подробнее. Любой тест можно рассматривать как комплекс заданий, выбранных из большого набора вопросов, которые потенциально могли быть заданы. Например, тест на правописание - это выборка большого количества слов из словаря. Тест, измеряющий тревогу, - это набор всех (многих!) вопросов, которые можно было бы перечислить с целью измерения множества аспектов тревоги. Тест математических способностей - это выборка из почти бесконечного числа математических заданий, которые только можно было бы написать. Итак, подлинное значение черты индивидуума - это оценка, которую он получил бы, если бы ему предъявили каждое возможное задание из полного набора. Поясним это на примере. Если было бы необходимо оценить чью-либо способность правильно писать каждое слово из словаря, то можно было бы узнать точно, каковы способности этого человека к правописанию, поскольку отсутствовала бы ошибка измерения, обусловленная случайным выбором заданий. Однако в реальном тесте используется лишь небольшая выборка заданий из всего возможного набора. Если задания теста формируют репрезентативную выборку по отношению к полному набору заданий, то квадратный корень из коэффициента альфа довольно точно оценивает корреляцию между оценкой, полученной испытуемыми при выполнении теста, и их подлинной оценкой (т.е. оценкой, которую они могли бы получить, если бы им были предъявлены все задания из полного набора). Чем выше величина коэффициента альфа, тем меньше будет ошибка при измерении черты; зная надежность теста и стандартные отклонения тестовых оценок, можно найти статистическую характеристику, которая называется "стандартная ошибка измерения", которая показывает насколько ошибка измерения может быть связана с каждым измерением (формула для вычисления стандартной ошибки приведена ниже Таким образом, знание надежности теста позволяет делать некоторые заключения, касающиеся величины ошибки, которая, вероятно, имеется в любом измерении, при условии, конечно, что задания данного теста можно считать репрезентативными по отношению к полному набору заданий.   ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  ЧТО ПРОИСХОДИТ ВО ВЗРОСЛОЙ ЖИЗНИ? Если вы все еще «неправильно» связаны с матерью, вы избегаете отделения и независимого взрослого существования...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|

 - дисперсия ошибки;
- дисперсия ошибки; -дисперсия теста.
-дисперсия теста. . Можно сказать, что величина ошибки измерения - обратный индикатор точности измерения: чем выше ошибка, тем шире диапазон неопределенности на шкале (доверительный интервал), внутри которого оказывается статистически возможной расположение истинного балла данного испытуемого [15].
. Можно сказать, что величина ошибки измерения - обратный индикатор точности измерения: чем выше ошибка, тем шире диапазон неопределенности на шкале (доверительный интервал), внутри которого оказывается статистически возможной расположение истинного балла данного испытуемого [15]. , где
, где -эмпирическая дисперсия первого испытания;
-эмпирическая дисперсия первого испытания; - эмпирическая дисперсия второго испытания;
- эмпирическая дисперсия второго испытания; ;
; ;
; ;
; .
. , где
, где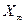 -истинный балл;
-истинный балл; -эмпирический балл i-го испытуемого;
-эмпирический балл i-го испытуемого; -среднее для теста;
-среднее для теста; , где
, где  - разность рангов i-го испытуемого в первом и втором ранговом ряду (1, 4).
- разность рангов i-го испытуемого в первом и втором ранговом ряду (1, 4).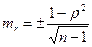 ;
;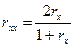 , где
, где - эмпирически рассчитанная корреляция для половин;
- эмпирически рассчитанная корреляция для половин; - надежность целого теста.
- надежность целого теста. ,где
,где - дисперсия по i-му пункту теста;
- дисперсия по i-му пункту теста; , где
, где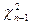 - эмпирическое значение статистики χ2 с п-1 степенью свободы;
- эмпирическое значение статистики χ2 с п-1 степенью свободы; , (***)
, (***) - средняя корреляция между пунктами теста.
- средняя корреляция между пунктами теста. =0,84), между оценками, полученными по тесту, и подлинными оценками испытуемых, в то время как величина коэффициента альфа, равная 0,9, подразумевает, что корреляция достигает такого высокого значения, как 0,95.
=0,84), между оценками, полученными по тесту, и подлинными оценками испытуемых, в то время как величина коэффициента альфа, равная 0,9, подразумевает, что корреляция достигает такого высокого значения, как 0,95. ; где σ –стандартное отклонение тестовых оценок; α – коэффициент надежности теста).
; где σ –стандартное отклонение тестовых оценок; α – коэффициент надежности теста).