|
|
Транспьютерный модуль (TРAM)Устанавливается в парные слоты на материнской плате, содержит только один транспьютер, а все остальное пространство занимает локальная оперативная память. ТРАМ размера 2 устанавливается на 4 слота позволяя использовать значительный ресурс локальной памяти и вычислительный ресурс одного транспьютера. На те же слоты можно поставить два ТРАМа размера 1, что даст вычислительный ресурс двух транспьютеров при незначительном объеме локальной памяти. Последовательный байтовый протокол передачи данных Интерфейсы транспьютерных линков, расположенных на одном кристалле с другими устройствами транспьютера поддерживают последовательный байтовый протокол передачи данных. Протокол передачи через регистр предполагает передачу информации и служебных разрядов – посылок: · Стартовую (11) · Стоповую (00) · Ответную (10)
рис. последовательный байтовый протокол передачи данных
Информационные разряды передаются в ответной посылке. Интерфейс транспьютера Т2 после получения стартовой посылки переходит в режим приема 8 информационных разрядов байта. Получив стоповую посылку интерфейс линка Т2 переходит в состояние выдачи ответной посылки на интерфейс выхода Т1 для синхронизации передачи следующего байта. Недостаток – временные задержки между передачей двух последовательных байт по линку. При наличии буферной памяти можно обеспечить непрерывный поток последовательно передаваемых байт. Ответная посылка должна выдаваться при передаче информационных разрядов байта, т.е. до получения стоповой посылки. При этом информационные разряды каждого байта будут записываться в буфер памяти, а поток служебных и информационных разрядов будут образовывать непрерывный сплошной поток. При заполнении буфера ответная посылка не выдается, и передача данных по линку приостанавливается до очистки буфера. Малая пропускная способность: · Разряды передаются последовательно · На каждый 8 информационных разрядов требуется 5 служебных. Параллельный байтовый протокол передачи данных Предполагает параллельную передачу всех информационных разрядов. Преимуществом последовательной передачи перед параллельной, является значительно большее расстояние корректной передачи данных. Универсальная ВА Реализуется на процессорах фирм INTEL, AMD, VIA. Среди универсальных ВА имеются одно-процессорные и много-процессорные вычислительные системы. Они предназначены для решения широкого спектра задач, в отличие от остальных названных ВА на СБИС, которые являются узкоспециализированными. Это достигается с помощью системы команд операционных систем и систем программирования CISC и RISC процессоров (CISC – с полным набором и RISC – сокращенным набором команд). Исторически сложилось, что после CISC процессоров появились RISC процессоры. Системы команд CISC процессоров позволяют с помощью одной операции обрабатывать набор данных, представляющих собой вектор, и в качестве результата получать либо скаляр, либо векторное значение. Система команд RISC процессоров состоит из 3х групп команд: 1) Позволяет считать данные из памяти и загрузить в регистр ЦП 2) Позволяет разгрузить регистр ЦП и сохранить данные в памяти 3) Позволяет выполнить операцию в регистрах ЦП Одна команда обработки данных в регистрах ЦП позволяет получить только один результат и сохранить его также в регистре ЦП. Преимуществом системы команд RISC процессоров является их простота и незначительное время, затраченное на их выполнение. Однако, для обработки векторных операндов требуется выполнить большое количество RISC - команд всех 3х групп (загрузка, разгрузка регистра и выполнения в них операций). С другой стороны одна сложная команда CISC процессора за более длительное время, чем одна команда RISC процессора может выполнить векторную операцию. В целом команды RISC процессора более простые по сравнению с командами CISC процессоров, которые являются более сложными. Количество команд для полного и сокращенного набора команд значения не имеет. Универсальная ВА на СБИС может выполнять в каждый момент времени одну или несколько команд. Среди них можно выделить простые и сложные процессоры. Простой процессор содержит только один ЦП, а сложный – представляет собой процессорное устройство, состоящий из 2х и более процессоров. Каждый из этих процессоров может выполнять одновременно одну или несколько команд.
Нейровычислительная ВА Для реализации нейросетей разработаны специализированные ПЭ, называемые нейрочипами, которые имеют на кристалле определенное количество нейронов, входов и выходов, память весов. Среди нейрочипов встречаются аналоговые, цифровые и гибридные. Наиболее быстродействующие - аналоговые, но у них имеется существенный недостаток, связанный с точностью представления данных. Цифровые нейрочипы имеют высокую точность, но выполняют операции с большей задержкой, чем аналоговые. Производительность нейросети задается для процесса вычисления и обучения. Процесс получения результата характеризуется количеством соединений или передач данных между нейронами в единицу времени, а процесс обучения характеризуется временем, которое необходимо затратить на обучение решения конкретной задачи, что фактически соответствует вычислительной производительности системы, вычисляемой количеством операций в секунду. Нейросети по режиму работы делятся на два вида: · Синхронные характеризуются одновременным выполнением во всей сети, либо только операции передачи данных, либо только вычислением. · Асинхронная таким свойством не обладает. То есть в каждый момент времени в сети происходят различные операции - соединение нейронов и выполнение вычислений. Кроме нейронов для реализации этой ВА применяют процессоры фирмы INTEL, AMD, медийные процессоры, ЦСП, транспьютеры. Все перечисленные типы процессоров эффективно вычисляют операцию умножения с накоплением с=axb+с которая используется для получения выходного значения нейронов.
Архитектура современных процессоров
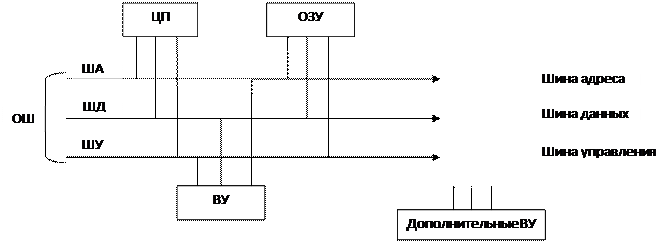
Среди современных МП в настоящее время существует несколько архитектур: · Фон Неймановская ВА · Гарвардская ВА · Транспьютерная ВА · ВА длинного командного слова · Другие, в частности производные от перечисленных ВА Фон Неймановская ВА Конструкция ЭВМ основывается на предположениях Джона фон Неймана, выдвинутых им в 1944 г. при разработке нового компьютера EMAC. Он сформулировал основные принципы работы компьютера: 1. Принцип программного управления вычислениями на процессоре 2. Управляющие программы и данные хранятся в оперативной памяти 3. Обмен данными между памятью и процессором осуществляется через специальное устройство – общую шину (ОШ) Также были сформулированы и другие принципы, но 3 названных являются фундаментальными и определяют способ управления вычислениями, назначение и объем оперативной памяти, и способ передачи данных между памятью и процессором через специальное коммуникационное устройство – каналы данных.
рис. структура классической фон Неймановской ВА
Фон Неймановская ВА также называется архитектурой общей шины, которая состоит из шин адреса, данных и управления. Существует также мультиплексированная шина, в которой шина адреса и шина данных являются совмещённой, а шина управления отдельной. В мультиплексированную ОШ встроено специальное устройство – мультиплексор, выполняющий функции коммутатора для передачи данных по одному проводнику шине адреса и данных. Для фон Неймановской ВА характерна единая оперативная память с единым адресным пространство и одним ЦП.
Принципиальные различия между раздельной и мультиплексированной ОШ
1. Пропускная способность при передаче команд и данных больше за счёт раздельности шин, вследствие чего могут одновременно передаваться команды и данные 2. Раздельные шины не содержат коммутаторов для подключений к устройствам адреса и данных 3. Площадь раздельной шины на кристалле больше площади мультиплексированной шины, что существенно с точки зрения количества размещаемых на кристалле устройств, которые участвуют в вычислительных процессах.   Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|



 Практически все современные процессоры имеют на кристалле устройство, которые называется “Конвейер команд”, на вход которого поступает поток команд, одновременно обрабатывается несколько команд, а на выходе получается поток результатов, получаемый в результате выполнения команд.
Практически все современные процессоры имеют на кристалле устройство, которые называется “Конвейер команд”, на вход которого поступает поток команд, одновременно обрабатывается несколько команд, а на выходе получается поток результатов, получаемый в результате выполнения команд. Современная универсальная ВА на СБИС осуществляет обработку многих потоков команд и данных. К универсальным ВА можно отнести одноядерные, 2-х ядерные и 4-х ядерные процессоры.
Современная универсальная ВА на СБИС осуществляет обработку многих потоков команд и данных. К универсальным ВА можно отнести одноядерные, 2-х ядерные и 4-х ядерные процессоры.