
|
|
Одномерный анализ: табулирование и представление данныхРезультаты измерения любой переменной могут быть представлены с помощью распределения наблюдений («случаев») по отдельным категориям данной переменной. Категория, в которую попадают одинаковые наблюдения, может быть номинальной («православный», «протестант» и т.п.) либо иметь числовое значение. В любом случае результатом такого упорядочения наблюдений будет их группировка. Работать с упорядоченными данными значительно проще, чем с исходным «сырым» массивом: в «сырых» данных, конечно, содержатся сведения о том, как много в выборке, например, пенсионеров, однако для получения нужной цифры придется перебрать все наблюдения «случай» за «случаем». Если данные сгруппированы, достаточно посмотреть, какова абсолютная частота, т. е. число наблюдений в данной выборке, попадающих в интересующую нас категорию. Для переменных, имеющих не произвольную метрику, т. е. измеренных на ординальном или интервальном уровне (см. гл. 6), нередко используется еще одна процедура, делающая представление данных более компактным и удобным в работе при сохранении заданного уровня точности. Предположим, что в каком-то исследовании 22,0782% опрошенных поддержали государственную программу приватизации, а исследование, проведенное месяц спустя, дало иное значение — 22,1327%. Даже если теоретический конструкт «поддержка программы приватизации» можно представить как непрерывный ряд числовых значений, на практике исследовательской переменной будет соответствовать некоторый набор дискретных числовых величин (категорий). Кроме того, тысячные или сотые доли процента едва ли будут существенны для интерпретации полученных результатов. Поэтому в представлении данных обычно используют процедуру округления. Определив необходимую степень точности — и соответственно приемлемый уровень неточности, — исследователь может округлить все полученные числовые значения до десятых долей или, скажем, до целых процентов. Так, в нашем примере округление до целого числа даст цифру 22%. В дальнейшем каждое последующее наблюдение, дающее числовое значение в интервале между 21,5% и 22,5%, будет попадать в класс «22% поддержки приватизации». В результате процедуры округления исследователь фактически устанавливает границы классов, объединяющих значения переменной в заданном интервале, и середины (центры) классов, т. е. усредненные значения для каждого интервала. Необходимость объединить значения переменной в 10—15 крупных классов-категорий часто возникает и при работе со «слишком хорошо измеренными» признаками, соответствующими шкалам интервалов или отношений (возраст, доход и т. п.). Во-первых, чрезмерное количество градаций переменной препятствует ее компактному представлению — табличному или графическому. Во-вторых, для конечной выборки обычно соблюдается следующая закономерность: число градаций (категорий) признака обратно пропорционально их заполненности. Переменная с огромным числом градаций, содержащих по 2—3 наблюдения, часто создает серьезные проблемы в статистическом анализе и оценивании (хотя для некоторых методов анализа — корреляция, регрессия и т. п. — эти проблемы, как мы увидим дальше, несущественны). Самым целесообразным выходом обычно оказывается перекодирование, «сжатие» исследовательской переменной. Здесь существует два основных подхода: 1) исходные градации объединяются в более крупные классы на основании каких-то содержательных соображений, причем полученные классы имеют приблизительно равную ширину (например, данные о возрасте часто перекодируют в более широкие «десятилетние» категории — 20—29 лет, 30—39 лет и т. п.); 2) решение о способе «сжатия» переменной принимают, основываясь на распределении наблюдений («случаев») по оси переменной, например, границы между «низким», «средним» и «высоким» доходом устанавливают так, чтобы в каждую категорию попало 33% наблюдений. Стремление к компактности и «читабельности» данных не должно вести к крайностям. Руководствуясь соображениями здравого смысла, исследователь должен избегать ситуаций, когда перегруппировка ведет к тому, что полученная переменная оказывается слишком грубым средством классификации наблюдений, не позволяющим выявить существенные для анализа различия. Важно также следить за тем, чтобы объединение категорий или числовых градаций переменной-признака не привело к искусственному созданию отношений и взаимосвязей, которые в действительности отсутствуют в данных. Независимо от того, какие статистические методы и модели собирается использовать исследователь, первым шагом в анализе данных всегда является построение частотных распределений для каждой изучавшейся переменной. Полученные результаты принято представлять в виде таблицы частотного распределения (или просто — таблицы распределения) для каждой существенной переменной. Примером табличного представления может служить приведенная ниже таблица 8.1, в которой представлены гипотетические данные выборочного опроса 500 владельцев домашних телефонов. Таблица 8.1 Частотное распределение ежемесячных расходов на международные телефонные переговоры
Иногда в таблице распределения указывают лишь относительные частоты, опуская абсолютные. Но и в этом случае в правом нижнем углу таблицы должны быть указаны абсолютное число ответивших (база для вычисления процентов) и число неответивших. Помимо табличного представления частотных распределений обычно используют и различные методы графического представления. Самый распространенный метод графического представления одномерных распределений — это гистограмма, или столбиковая диаграмма. Каждый столбик соответствует интервалу значений переменной, причем его середина совмещается с серединой данного интервала. Высота столбика отражает частоту (абсолютную или относительную) попадания наблюдавшихся значений переменной в определенный интервал. При построении гистограмм часто приходится использовать некоторые конвенции, основанные на сугубо практических соображениях. Так, используя при группировке значений переменной неравные интервалы либо оставляя крайние градации открытыми («старше 65 лет», «свыше 24000 рублей» и т. д.), мы все же отображаем эти интервалы на гистограмме с помощью столбиков, имеющих одинаковую ширину. Другое практическое правило позволяет сделать гистограмму визуально уравновешенной, т. е. более привлекательной: масштаб шкалы обычно выбирают так, чтобы общая высота гистограммы составляла приблизительно 40—60% ее ширины. Пример гистограммы для данных из таблицы 8.1 приведен на рисунке 14.
Рис. 14. Гистограмма для данных о расходах на Телефонные переговоры
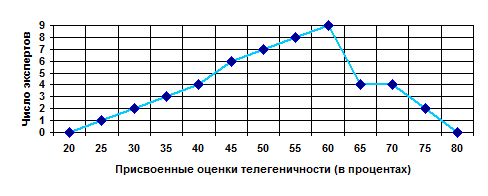
Если просто соединить между собой точки, соответствующие абсолютным или относительным частотам (ось ординат) для середин интервалов, мы получим так называемый полигон распределения. Эта операция, разумеется, будет иметь какой-то смысл лишь для количественных переменных, которые мы в принципе можем представить себе как непрерывные. На рисунке 15 изображен полигон распределения для экспертных оценок телегеничности политического лидера (50 экспертов оценивали политика в процентах по отношению к некоторому абсолютному эталону телегеничности).
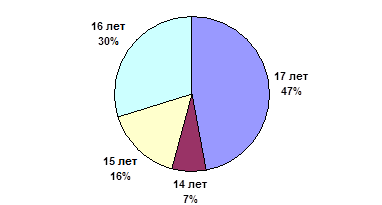
Еще один популярный способ графического представления, обычно используемый для качественных данных (т. е. для номинальных или ординальных измерений), — это круговая диаграмма. Каждый сектор круговой диаграммы представляет дискретную категорию переменной. Величина сектора пропорциональна частоте категории для данной выборки. На рисунке 16 приведена круговая диаграмма, иллюстрирующая распределение подростков, страдающих вялотекущей формой шизофрении, по возрасту на момент начала («дебюта») заболевания[192].
Рис. 16. Заболеваемость вялотекущей формой шизофрении у подростков мужского пола по возрастам, %
Какую бы форму представления данных мы ни избрали, полученное частотное распределение все еще содержит «слишком много» деталей, не отвечая при этом на весьма важные для содержательного анализа вопросы о самых типичных значениях признака и диапазоне разброса отдельных наблюдений. Для облегчения работы с частотными распределениями, а также для обобщенного представления их характеристик, обычно используют определенные числовые значения — статистики. Дело в том, что специалисты по статистике используют последний термин в двух значениях: как название своей дисциплины и как обозначение какой-либо числовой функции, описывающей результаты наблюдений. Наибольшее практическое значение имеют две группы статистик: меры центральной тенденции и меры изменчивости (разброса). Меры центральной тенденции указывают на расположение среднего, или типичного, значения признака, вокруг которого сгруппированы остальные наблюдения. Понятие среднего, центрального, значения в статистике, как и в повседневной жизни, подразумевает нечто «ожидаемое», «обычное», «типичное». Способность среднего значения давать некую обобщенную информацию о распределении вытекает из того соотношения, которое связывает среднее значение с другими «особыми» точками распределения — минимумом и максимумом: зная среднее значение, мы можем утверждать, что наименьшее наблюдаемое значение полученного распределения — например, распределения веса или интеллекта — было не больше среднего, а наибольшее зафиксированное значение— не меньше среднего. Отличие статистической трактовки среднего значения (или, точнее, мер центральной тенденции) от его «житейской» трактовки заключается прежде всего в том, что в статистике, в отличие от повседневной жизни, понятие среднего значения может быть строго задано лишь для одномерного распределения переменной-признака. Мы можем, например, указать на семью со средним душевым доходом, но при этом не следует ожидать, что данная семья будет средней или типичной в каких-то других отношениях, т. е. будет иметь средний размер, среднюю жилплощадь и т. п. В повседневном общении мы приписываем понятию среднего куда более широкий и менее точный смысл. В этом нет большой беды, пока мы не смешиваем «житейскую» и «статистическую» интерпретации. Мы действительно получаем полезную информацию, узнав, что окружающие говорят о ком-то как о «человеке средних способностей», но будет ошибкой заключить, что некто X, имеющий средний показатель интеллекта, наверняка имеет средние успехи в учебе или посредственно сочиняет стихи. Именно поэтому популярные газетные образы «среднего российского подростка» или «среднего читателя», в сущности, лежат за пределами корректного использования статистики. Самой простой из мер центральной тенденции является мода (Мо). Для номинальных переменных мода — это единственный способ указать наиболее типичное, распространенное значение. Разумеется, исследователь может пользоваться модальным значением и для характеристики распределения переменных, измеренных на более высоком уровне, если для этого существуют содержательные основания (например, описывая распределение ответов на вопрос о количестве подписываемых журналов). Мода — это такое значение в совокупности наблюдений, которое встречается чаще всего. Например, если в выборке содержится 60% православных, 30% мусульман и 10% представителей других конфессий, то модальным значением будет «православный». У моды как меры центральной тенденции есть определенные недостатки, ограничивающие ее интерпретацию. Во-первых, в распределении могут быть две и более моды (соответственно оно является бимодальным или мультимодальным). Скажем, если в группе из десяти человек четверо не имеют автомобиля (0), четверо имеют один автомобиль, один человек имеет две машины и еще один — три, то нам придется указать два модальных значения — 0 и 1. Кроме того, мода чрезвычайно чувствительна к избранному способу группировки значений переменной. Объединяя категории ответа, мы резко увеличиваем число наблюдений в отдельных категориях. Это открывает широкий простор для манипулирования данными (не всегда добросовестного). Поэтому «правилом хорошего тона» при вычислении модального значения для сгруппированных количественных данных является выравнивание ширины для всех интервалов класса. Еще одно важное правило касается случаев, когда частоты для всех наблюдаемых значений почти равны. Здесь лучше воздержаться от вычисления моды, так как в этом случае она просто не может быть интерпретирована как мера центральной тенденции. Если, скажем, 48% болельщиков поддерживают сборную Италии, а 49% — сборную Бразилии, модальное значение «поддерживает бразильцев» будет не очень модальным. И все же во многих случаях вычисление моды и необходимо, и полезно. Например, для архитектора, занимающегося планированием жилых домов, знание модального значения для размера семьи в данной местности, может оказаться весьма важным. Другая мера центральной тенденции — медиана — обычно используется для ординальных переменных, т. е. таких переменных, значения которых могут быть упорядочены от меньших к большим. Пример вычисления медианы рассматривался нами в главе 6. Напомним, что медиана (Md) — это значение, которое делит упорядоченное множество данных пополам, так что одна половина наблюдений оказывается меньше медианы, а другая — больше. Иными словами, медиана — это 50-й процентиль распределения. Как мы уже видели, при работе с большим массивом данных удобнее всего искать медиану, построив на основании частотного распределения распределение накопленных частот (или построив распределение накопленных процентов на основании распределения процентов). Для того чтобы найти медианное значение для маленького массива наблюдений, достаточно упорядочить наблюдения от меньших значений переменной к большим: то значение, которое окажется в середине, и будет медианным. Например, для ряда: 17 баллов, 18 баллов, 20 баллов, 21 балл, 22 балла, медианой будет значение 20 баллов. Если число значений в группе наблюдений четное, то медианой будет среднее двух центральных значений. Медиану иногда называют «позиционным средним», так как она указывает именно среднюю позицию в упорядоченном ряду наблюдений. Медиана может совпадать или не совпадать с модой. При этом медиана лучше всего соответствует нашему интуитивному представлению о середине упорядоченной последовательности чисел. Некоторые исследователи даже полагают, что медиана — лучше и «справедливее» среднеарифметического при описании таких величин, как, скажем, доход семьи. Ведь семьи, имеющие доход ниже среднего, могут составить и 60, и 70% населения. Когда же мы говорим, например, что медианный доход составил 10 млн. рублей в год, то не более 50% семей окажутся «ниже среднего уровня». На медиану не влияют величины «крайних» очень больших или малых значений. И все же для количественных переменных самойважной и распространенной является другая мера центральной тенденции— среднее арифметическое, которое чаще всего называют просто средним (и обозначают как
где Х 1 ... X i — наблюдаемые значения, n — число наблюдений, å — знак арифметической суммы. В таблице 8.2 показано, как вычислить средний возраст для выборки из 20 посетителей библиотеки. Заметьте, что каждое значение просто умножается на свою абсолютную частоту. Приведенный нами пример (см. табл. 8.2) показывает, насколько среднее уязвимо для «крайних» значений. Фактически для нашей небольшой выборки молодых людей прибавление одного — восьмидесятилетнего — читателя заметно увеличило средний возраст. Следует, однако, помнить о том, что степень «возмущения» среднего под влиянием единичных очень больших или малых значений уменьшается в прямом соответствии с ростом объема выборки. Заметим также, что при расчете среднего для сгруппированных, данных частоты умножаются на значение, соответствующее середине интервала группировки.
Таблица 8.2   ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем...  ЧТО ПРОИСХОДИТ ВО ВЗРОСЛОЙ ЖИЗНИ? Если вы все еще «неправильно» связаны с матерью, вы избегаете отделения и независимого взрослого существования... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|

 ).Процедура определения среднего общеизвестна: нужно просуммировать все значения наблюдений и разделить полученную сумму на число наблюдений. В общем случае:
).Процедура определения среднего общеизвестна: нужно просуммировать все значения наблюдений и разделить полученную сумму на число наблюдений. В общем случае: