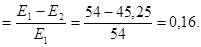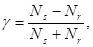|
|
Взаимосвязь правонарушения и решения суда
Другой тип коэффициентов взаимосвязи номинальных (и не только номинальных) переменных называют мерами «пропорционального уменьшения ошибки». Все они основаны на следующем предположении (или модели): если две переменные взаимосвязаны, мы можем предсказать значение одной переменной для данного наблюдения (случая), зная, какое значение принимает другая переменная. Степень соответствия такого предсказания действительности и используется в качестве коэффициента взаимосвязи. Любой коэффициент взаимосвязи, основанный на модели «пропорционального уменьшения ошибки» («ПУО»), имеет общую структуру, задаваемую формулой:
где Е 1 — количество ошибок в предсказаниях значений зависимой переменной, с деланных без учета распределения по второй, независимой, переменной, а Е 2 — количество ошибок в предсказаниях значений зависимой переменной, сделанных на основе значений независимой переменной. Конкретные коэффициенты, основанные на «ПУО», будут различаться в зависимости от того, что мы считаем ошибкой и как подсчитывается количество ошибок. В качестве примера можно рассмотреть «may-коэффициент» Гудмана-Краскела [198]. Ошибкой в данном случае считается просто ошибочная классификация наблюдения, отнесение его в «неправильную» категорию. Рассмотрим таблицу сопряженности для приводимого Мюллером и соавторами примера[199] гипотетических данных о влиянии типа правонарушения на характер решения суда (см. табл. 8.7). Ошибка предсказания зависимой переменной (приговор), сделанного исключительно на основе ее собственного распределения, т. е. без учета распределения независимой переменной, определяется следующим образом. Мы знаем (см. маргиналы столбцов в нижней строчке таблицы), что в 60 случаях из 100 приговор был условным, но нам неизвестно, в каких именно шестидесяти случаях он был условным. Точно так же мы знаем, что в десяти случаях судья ограничился денежным штрафом, но мы наверняка неоднократно ошибемся, наугад определяя для каждого случая из 100, считать ли его одним из десяти «штрафных». Если бы каждому случаю соответствовала карточка с надлежащей надписью, которую мы с завязанными глазами помещали бы в одну из трех стопок, то при угадывании мы могли бы руководствоваться лишь значениями маргиналов по столбцам: в конечном счете в первой стопке должно оказаться 10 карточек, во второй — 60, а в третьей — 30. Если мы наугад поместим во вторую стопку «условных приговоров» 60 карточек, то для каждой отдельной карточки (для каждого наблюдения) вероятность ошибки будет равна вероятности попадания туда карточки «штраф» или «тюремное заключение», т. е. 10/100 + 30/100 = 40/100. Иными словами, в среднем мы сделаем Е 1 = 24 + 9 + 21 = 54 ошибки.
Представим теперь, что распределяя карточки по трем категориям приговора, мы располагаем сведениями о том, каково значение второй переменной — «характер преступления» — для каждой карточки, т. е. для каждого наблюдения. Пусть, например, кто-нибудь каждый раз сообщает нам, каким было в данном случае правонарушение, предоставляя нам возможность самостоятельно предсказать приговор суда. Мы также знаем заранее, что 5 (12,5%) автомобильных краж из 40 повлекли за собой штраф, 30 (75%) — условный срок, а еще 5(12,5%) — тюремное заключение. Нам, однако, предстоит угадать, какие именно из этих 40 случаев автомобильных краж попали в каждую из трех описанных категорий приговора. Процесс подсчета числа ошибок при таком угадывании сходен с вышеописанным. Зная, каково распределение наблюдений в строке «автомобильные кражи», мы можем оценить ожидаемые ошибки. Ожидаемая ошибка при случайном помещении 5 карточек с автомобильными кражами (из 40) в категорию «штраф» составит t
Таблица 8.8 Ранги четырех школьниц по привлекательности (X) и популярности(Y)
Для простейшего случая таблицы сопряженности 2 x 2 существует более простая в вычислительном отношении формула:
t где a, b, с, d — частоты в клетках таблицы (см. табл. 8.4) [200]. Отметим здесь, что направление связи далеко не всегда очевидно, т. е. не всегда можно уверенно утверждать, какая из переменных является зависимой. Если исследователь решит, что независимой является переменная, расположенная по горизонтали (а не по вертикали, как в нашем примере), он сможет подсчитать другую величину «тау-коэффициента», на этот раз идя «от строк» и выполнив все операции в обратном порядке. (Для четырехклеточных таблиц величины «тау» по строкам и по столбцам будут равны.) Примером ПУО-коэффициента, специально предназначенного для измерения связи двух ординальных (т. е. измеренных на порядковом уровне) переменных, может служить коэффициент «гамма». «Гамма» измеряет относительное уменьшение ошибки предсказания ранга конкретного наблюдения по зависимой переменной. Для того чтобы вручную рассчитать значение «гаммы» для небольшой выборки, нужно упорядочить наблюдения по независимой и зависимой переменным, как это показано в таблице 8.8 для данных о внешней привлекательности (экспертные оценки) и популярности школьниц (данные опроса одноклассников). Далее нужно сравнивать случаи (т. е. школьниц) попарно, определяя, сходится или расходится порядок расположения двух этих случаев по двум переменным. Если упорядочения сходятся, пара называется согласованной, если они не сходятся, то пару нужно считать несогласованной. Результаты анализа для данных таблицы 8.8 представлены в таблице 8.9. Предполагается, что если согласованных (т. е. правильно предсказывающих порядок по зависимой переменной) пар больше, чем несогласованных, связь между переменными велика. Если несогласованных пар больше, то связь отрицательна (чем выше ранг по одной переменной, тем ниже ранг по другой). Если же различие между числом согласованных и несогласованных пар невелико, то связь между переменными просто отсутствует. Поэтому формула для «гаммы» такова:
где N s — число согласованных пар, Nr — число несогласованных пар. Таблица 8.9 Попарные сравнения рангов по переменным X и Y
* Примечание. Здесь использованы лишь начальные буквы имен, т. е. «О > С» означает, что ранг Оли выше ранга Светы.
Для данных, используемых в нашем примере:
О том, как измерить связь (корреляцию) количественных переменных, мы поговорим немного позже, сделав одно важное отступление.   Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
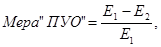
 ошибки для категории «условный приговор». Для первой категории («штраф») мы в среднем сделаем 10 х (60/100 + 30/100) = 9 ошибок. Для категории «тюремное заключение» (30 карточек) мы можем ожидать, что сделаем 21 ошибку. Суммарное значение числа ошибок предсказания Е 1(если в расчет принимается только распределение зависимой переменной) составит сумму этих трех значений:
ошибки для категории «условный приговор». Для первой категории («штраф») мы в среднем сделаем 10 х (60/100 + 30/100) = 9 ошибок. Для категории «тюремное заключение» (30 карточек) мы можем ожидать, что сделаем 21 ошибку. Суммарное значение числа ошибок предсказания Е 1(если в расчет принимается только распределение зависимой переменной) составит сумму этих трех значений: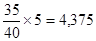 ошибки; при случайном размещении 30 карточек с автомобильными кражами в категорию «условный приговор» мы ожидаем, что ошибок предсказания в среднем будет
ошибки; при случайном размещении 30 карточек с автомобильными кражами в категорию «условный приговор» мы ожидаем, что ошибок предсказания в среднем будет 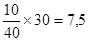 ошибки и т. д. Размещая 5 фальшивомонетчиков из 10 в стопку «штрафов», мы сделаем
ошибки и т. д. Размещая 5 фальшивомонетчиков из 10 в стопку «штрафов», мы сделаем  ошибки. Проведя аналогичные подсчеты для всех трех строк таблицы 8.7 и просуммировав все ожидаемые ошибки, мы получим величину Е 2, т. е. ожидаемое число ошибок в предсказаниях приговора суда, сделанных с учетом информации о характере преступления (независимой переменной). Для данных, приведенных в таблице 8.7, величина Е 2составит 45,25. Отсюда,
ошибки. Проведя аналогичные подсчеты для всех трех строк таблицы 8.7 и просуммировав все ожидаемые ошибки, мы получим величину Е 2, т. е. ожидаемое число ошибок в предсказаниях приговора суда, сделанных с учетом информации о характере преступления (независимой переменной). Для данных, приведенных в таблице 8.7, величина Е 2составит 45,25. Отсюда,