
|
|
Логическая схема однофакторного дисперсионного комплекса
Для проверки достоверности полученного вывода необходимо провести проверку по F -критерию. Определяют значение критерия Фишера (F), представляющего собой отношение двух дисперсий – факториальной и остаточной –
Лабораторная работа №2. Цель: использование методики однофакторного дисперсионного анализа для определения взаимосвязей. Объект изучения: урожайность условных полей (см. условие ниже). Оборудование и материалы: калькулятор. Предположим, что изучается влияние возрастающих доз удобрения определенного типа на урожайность какой-либо культуры. Пусть имеются четыре дозы удобрения (А1…А4, причем А1<A2<A3<A4), которое использовали на пяти делянках по каждой дозе (m=4, n=5). Требуется выяснить: влияет ли повышение дозы удобрения на урожайность и если да, то достоверен ли этот вывод настолько, чтобы можно было рекомендовать этот опыт сельскому хозяйству. Результаты представьте в виде таблице по аналогии с типовым примером Результаты первичных наблюдений приведены в таблице. Таблица 2.5 Исходные данные для расчета однофакторного дисперсионного комплекса
Регрессионный анализ В экологических исследованиях, и особенно в обработке экспериментальных данных, обычно используется регрессионный анализ, который тесно связан с корреляционным анализом и является его логическим продолжением, углубляя представления о корреляционной связи. Под регрессией подразумевается зависимость изменений одного признака от изменений другого или нескольких признаков (множественная регрессия). В отличие от строгой функциональной зависимости y = f(x) в регрессионной модели одному и тому же значению величины x могут соответствовать несколько значений величины y, иными словами, при фиксированном значении x величина y имеет некоторое случайное распределение. В соответствии с этим регрессия, подобно корреляции, может быть парной (простой) или множественной, а в зависимости от формы связи – линейной или нелинейной. Здесь мы рассмотрим только самый простой случай линейной регрессии. В случае простого линейного регрессионного анализа целесообразно придерживаться следующей схемы исследования. Пусть имеется две переменные – X (независимая) и Y (зависимая). Случайным образом отбираем n индивидов из генеральной совокупности и измеряем для них обе переменные. Далее строим диаграмму рассеяния признаков. Анализируя её, мы можем эмпирически оценить допустимо ли предположение о линейной зависимости между переменными. При большом числе переменных точки графика образуют «облако» характерной формы.
Рисунок 2.1. Типы диаграмм рассеяния.
По форме «облака» можно сделать некоторые выводы (рис. 2.1): А) положительная линейная корреляция (r > 0) (например, связь между ростом и весом); Б) отрицательная линейная корреляция (r < 0) (например, связь между возрастом и весом монеты); В) отсутствие связи (r = 0); Г) отрицательная нелинейная корреляция (r < 0) (например, связь между спросом и ценой на товар).
Теперь рассчитываем таблицу коэффициентов корреляции Пирсона. В отличие от корреляционного анализа, требующего достаточно большого объема выборки, анализ регрессии возможен и при наличии всего нескольких пар сопряженных наблюдений, однако его имеет смысл проводить лишь при обнаружении достоверных и достаточно сильных (порядка r ≥ 0,7) связей между признаками. После того как мы определились с характером связи, строим модель в виде линейной функции:
где значения b это некоторый параметр, указывающий на связь двух выборок. Например, b0 – это значение Y, полученное при X = 0, тогда b1 – прирост Y при увеличении X на единицу (скорость изменения). Рассчитываются коэффициенты модели весьма просто:
Полученные данные подставляем в формулу линейной регрессии и строим график линейной регрессии. Далее требуется оценить степень связности двух линий регрессии – эмпирической и теоретической. Для этих целей оценивают дисперсии. Обычно используют уже вам известную таблицу дисперсионного анализа. Таблица 2.6 Таблица дисперсионного комплекса для простой линейной регрессии
Обусловленная регрессией сумма квадратов SSD получила своё название потому, что её можно записать как функцию оценённого коэффициента регрессии b1:
Итак, чем больше коэффициент регрессии, тем больше сумма квадратов регрессии, «обусловленная регрессией». F -отношение может быть использовано для проверки гипотез.
Анализ временных рядов Существуют две основные цели анализа временных рядов: 1. Определение природы ряда. Определение закономерностей, которые можно выделить посредством исследования графика. 2. Прогнозирование. Предсказание будущих значений временного ряда по настоящим и прошлым значениям. Обе эти цели требуют, чтобы модель ряда была идентифицирована и, более или менее, формально описана. Как только модель определена, вы можете с ее помощью интерпретировать рассматриваемые данные (например, использовать в вашей теории для понимания сезонного изменения цен на товары, если занимаетесь экономикой или прогнозировать вылов рыбы если занимаетесь исследованиями продуктивности рыбных рек). Не обращая внимания на глубину понимания и справедливость теории, вы можете экстраполировать затем ряд на основе найденной модели, т.е. предсказать его будущие значения (прогнозирование). Но при исследовании сложных систем здесь возникает проблема адекватности прогнозной модели. Практика исследования сложных систем говорит нам, что мы не можем построить абсолютно адекватную модель поведения сложных систем, а, следовательно, не можем абсолютно достоверную модель будущего состояния системы. Единственно достоверным методом прогнозирования на настоящий момент остаётся только паттерн-анализ (по мнению В.В. Налимова), который основан на выделении устойчивых повторяющихся сочетаний (паттернов), которые впоследствии можно использовать в качестве индикаторов процесса. Как и большинство других видов анализа, анализ временных рядов предполагает, что данные содержат систематическую составляющую (обычно включающую несколько компонент) и случайный шум (ошибку), который затрудняет обнаружение регулярных компонент. Большинство методов исследования временных рядов включает различные способы фильтрации шума, позволяющие увидеть регулярную составляющую более отчетливо. Большинство регулярных составляющих временных рядов принадлежит к двум классам: они являются либо трендом, либо сезонной составляющей. После исключения из временного ряда этих двух компонент, остаётся стационарный временной ряд или же не остаётся ничего, тогда выяснятся, что ряд целиком состоит из тренда или сезонной составляющей. Для выявления периодичности временного ряда используются автокорреляционные функции, ряд Фурье и другие сложные методы. Тренд представляет собой общую систематическую линейную или нелинейную компоненту, которая может изменяться во времени. Сезонная составляющая – это периодически повторяющаяся компонента. Оба эти вида регулярных компонент часто присутствуют в ряде одновременно. Например, численность популяции может возрастать из года в год, но она также содержат сезонную составляющую (как правило, существует период особой активности – брачный период). Любой ряд динамики разделён на три компоненты:
где f(t) – детерминированная (определяемая) компонента, представляющая аналитическую функцию, которая выражает тенденцию в ряду динамики; g(t) – стохастическая (вероятностная) компонента, моделирующая периодический характер вариаций исследуемого явления; h – случайная компонента типа «белый шум», т.е. необъяснённые факторы или, так называемые, флуктуации. Отметим также некоторые особенности временных рядов. Биометрические данные часто имеют пропуски наблюдений, для восстановления которых используются различные алгоритмы. Как правило, пропущенный участок получают путём осреднения значений соседних интервалов или с помощью более сложных алгоритмов. Другая особенность временных рядов это – выбросы. Под выбросами обычно понимают наблюдения, являющиеся в том или ином смысле аномальными (на графике они выражаются через резкие пики или падения значений, причём зачастую единичные). Такие случаи анализируются и исключаются из общего рассмотрения при создании тренда. Также интересны разрывы. Разрыв временного ряда – это скачкообразное изменения уровня временного ряда, т.е. выброс в ряду значений. Очевидно, что к идентификации выбросов и разрывов в экологических рядах следует подходить с особой осторожностью, чтобы не потерять значимые данные, т.к. они могут характеризовать некий периодический или системный процесс. Не существует «автоматического» способа обнаружения тренда во временном ряде. Однако если тренд является монотонным (устойчиво возрастает или устойчиво убывает), то анализировать такой ряд обычно нетрудно. Если временные ряды содержат значительную ошибку, то первым шагом выделения тренда является сглаживание. Как правило, сглаживание подразумевает изменение масштаба для выявления более общей тенденции. Сглаживание всегда включает некоторый способ локального усреднения данных, при котором несистематические компоненты взаимно погашают друг друга. Самый общий метод сглаживания – скользящее среднее, в котором каждый член ряда заменяется простым или взвешенным средним n соседних членов. Вместо среднего можно использовать медиану значений, попавших в окно значений. Основное преимущество медианного сглаживания, в сравнении со сглаживанием скользящим средним, состоит в том, что результаты становятся более устойчивыми к выбросам (имеющимся внутри окна). Если в данных имеются выбросы (связанные, например, с ошибками измерений), то сглаживание медианой обычно приводит к более гладким или, по крайней мере, более «надежным» кривым, по сравнению со скользящим средним с тем же самым окном. Основной недостаток медианного сглаживания в том, что при отсутствии явных выбросов, он приводит к более «зубчатым» кривым (чем сглаживание скользящим средним) и не позволяет использовать веса. Также используется взвешенное сглаживание. В данном случае определяются взвешенные средние, взятые с разных точек ряда динамики. Метод экспоненциального сглаживания (метод Брауна) применяется для нестационарных временных рядов. Для целей прогнозирования используются сходные методы. Например, частым методом прогнозирования является метод скользящих средних:
т.е. метод основан на составлении нового ряда из простых средних арифметических, которые были вычислены для предыдущих промежутков. Аналогично применяются и другие методы сглаживания (взвешенное, медианное, экспоненциальное).
  Что вызывает тренды на фондовых и товарных рынках Объяснение теории грузового поезда Первые 17 лет моих рыночных исследований сводились к попыткам вычислить, когда этот...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|


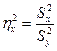





 и сравнивают его с табличным в зависимости от числа степеней свободы n1= m -1 и n2= mn-m. Для того, чтобы отвергнуть нулевую гипотезу, необходимо, чтобы полученное значение критерия было больше табличного. Однофакторный дисперсионный анализ удобно представить в виде таблицы:
и сравнивают его с табличным в зависимости от числа степеней свободы n1= m -1 и n2= mn-m. Для того, чтобы отвергнуть нулевую гипотезу, необходимо, чтобы полученное значение критерия было больше табличного. Однофакторный дисперсионный анализ удобно представить в виде таблицы:
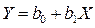 ,
, ,
, .
.







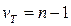
 .
. ,
, ,
,