|
|
Символьное кодирование информации.3.1.Коды символов
У каждого компьютера есть набор символов, который он использует. Как минимум этот набор включает 26 заглавных и 26 строчных букв, цифры от 0 до 9, а также некоторые специальные символы: пробел, точка, запятая, минус, символ возврата каретки и т. д. Для того чтобы передавать эти символы в компьютер, каждому из них приписывается номер: например, а=1, Ь=2,..., z=26, +=27, -=28. Отображение символов в целые числа называется кодом символов. Важно отметить, что связанные между собой компьютеры должны иметь один и тот же код, иначе они не смогут обмениваться информацией. По этой причине были разработаны стандарты. Ниже мы рассмотрим два самых важных из них.
3.2.ASCII
Один широко распространенный код называется ASCII (American Standard Code for Information Interchange - американский стандартный код для обмена информацией) Каждый символ ASCII-кода содержит 7 битов, таким образом, всего может быть 128 символов (табл. 2 5) Коды от 0 до 1F (в шестиадцатеричной системе счисления) соответствуют управляющим символам, которые не печатаются. Многие непечатные символы ASCII предназначены для передачи данных. Например, послание может состоять из символа начала заголовка SOH (Start of Header), самого заголовка, символа начала текста STX (Start of Text), самого текста, символа конца текста ЕТХ (End of Text) и, наконец, символа конца передачи EOT (End of Transmission). Однако на практике послания, отправляемые по телефонным линиям и сетям, форматируются по-другому, так что непечатные символы передачи ASCII практически не используются. Печатные символы ASCII наглядны, они включают буквы верхнего и нижнего регистров, цифры, знаки пунктуации и некоторые математические символы.
3.3.UNICODE
Компьютерная промышленность развивалась преимущественно в США, что привело к появлению кода ASCII. Этот код подходит для английского языка, но не очень удобен для других языков. Во французском языке есть надстрочные знаки (например, systeme), в немецком — умляуты (например, far) и т. д. В некоторых европейских языках есть несколько букв, которых нет в ASCII, например, немецкое 3 или датское 0. Некоторые языки имеют совершенно другой алфавит (например, русский или арабский), а у некоторых вообще нет алфавита (например, китайский). Компьютеры распространились по всему свету, и поставщики программного обеспечения хотят реализовывать свою продукцию не только в англоязычных, но и в тех странах, где большинство пользователей не говорят по-английски и где нужен другой набор символов. Первой попыткой расширения ASCII был IS 646, который добавлял к ASCII еще 128 символов, в результате чего получился 8-битный код под названием Latin-1. Добавлены были в основном латинские буквы со штрихами и диакритическими знаками. Следующей попыткой был IS 8859, который ввел понятие кодовая страница. Кодовая страница — набор из 256 символов для определенного языка или группы языков. IS 8859-1 - это Latin-1. IS 8859-2 включает славянские языки с латинским алфавитом (например, чешский, польский и венгерский). IS 8859-3 содержит символы турецкого, мальтийского, эсперанто и галисийского языков и т. д. Главным недостатком такого подхода является то, что программное обеспечение должно следить, с какой именно кодовой страницей оно имеет дело в данный момент, и при этом невозможно смешивать языки. К тому же эта система не охватывает японский и китайский языки. Группа компьютерных компаний разрешила эту проблему, создав новую систему под названием UNICODE, и объявила эту систему международным стандартом (IS 10646). UNICODE поддерживается некоторыми языками программирования (например, Java), некоторыми операционными системами (например, Windows NT) и многими приложениями. Вероятно, эта система будет распространяться по всему миру. Основная идея UNICODE - приписывать каждому символу единственное постоянное 16-битное значение, которое называется указателем кода. Многобайтные символы и escape-последовательности не используются. Поскольку каждый символ состоит из 16 битов, писать программное обеспечение гораздо проще. Так как символы UNICODE состоят из 16 битов, всего получается 65 536 кодовых указателей. Поскольку во всех языках мира в общей сложности около 200 000 символов, кодовые указатели являются очень скудным ресурсом, который нужно распределять с большой осторожностью. Около половины кодов уже распределено, и консорциум, разработавший UNICODE, постоянно рассматривает предложения на распределение оставшейся части. Чтобы ускорить принятие UNICODE, консорциум использовал Latin-1 в качестве кодов от 0 до 255, легко преобразуя ASCII в UNICODE. Во избежание излишней растраты кодов каждый диакритический знак имеет свой собственный код. А сочетание диакритических знаков с буквами – задача программного обеспечения. Вся совокупность кодов разделена на блоки, каждый блок содержит 16 кодов. Каждый алфавит в UNICODE имеет ряд последовательных зон. Приведем некоторые примеры (в скобках указано число задействованных кодов): латынь (336), греческий (144), русский (256), армянский (96), иврит (112), деванагари (128), гурмуки(128), ория(128), телугу (128)иканнада(128). Отметим, что каждому из этих языков приписано больше кодов, чем в нем есть букв. Это было сделано отчасти потому, что во многих языках у каждой буквы есть несколько вариантов. Например, каждая буква в английском языке представлена в двух вариантах: там есть строчные и заглавные буквы. В некоторых языках буквы имеют три или более форм, выбор которых зависит от того, где находится буква: в начале, конце или середине слова. Кроме того, некоторые коды были приписаны диакритическим знакам (112), знакам пунктуации (112), подстрочным и надстрочным знакам (48), знакам валют (48), математическим символам (256), геометрическим фигурам (96) и рисункам (192). Затем идут символы для китайского, японского и корейского языков. Сначала идут 1024 фонетических символа (например, катакана и бопомофо), затем иероглифы, используемые в китайском и японском языках (20 992), а затем слоги корейского языка (11 156). Чтобы пользователи могли создавать новые символы для особых целей, существует еще 6400 кодов. Хотя UNICODE разрешил многие проблемы, связанные с интернационализа- цией, он все же не мог разрешить абсолютно все проблемы. Например, латинский алфавит упорядочен, а иероглифы - нет, поэтому программа для английского языка может расположить слова «cat? и «dog» по алфавиту, сравнив значение кодов первых букв, а программе для японского языка нужны дополнительные таблицы, чтобы можно было вычислять, в каком порядке расположены символы в словаре. Еще одна проблема состоит в том, что постоянно появляются новые слова. 50 лет назад никто не говорил об апплетах, киберпространстве, гигабайтах, лазерах, модемах, «смайликах» или видеопленках. С появлением новых слов в английском языке новые коды не нужны. А вот в японском нужны. Кроме новых терминов, необходимо также добавить, по крайней мере, 20 000 новых имен собственных и географических названий (в основном китайских). Шрифт Брайля, которым пользуются слепые, вероятно, тоже должен быть задействован. Представители различных профессиональных кругов также заинтересованы в наличии каких-либо особых символов. Консорциум по созданию UNICODE рассматривает все новые предложения и выносит по ним решения. UNICODE использует один и тот же код для символов, которые выглядят почти одинаково, но имеют несколько значений или пишутся немного поразному в китайском и японском языках (как если бы английские текстовые процессоры всегда писали слово «blue» как «blew», потому что они произносятся одинаково). Одни считают такой подход оптимальным для экономии скудного запаса кодов, другие рассматривают его как англо-саксонский культурный империализм (а вы думали, что приписывание символам 16-битных значений не носит политического характера?). Дело усложняется тем, что полный японский словарь содержит 50 000 иероглифических знаков (не считая собственных имен), поэтому при наличии 20 992 кодов приходится делать выбор и чем-то жертвовать. Далеко не все японцы считают, что консорциум компьютерных компаний, даже если некоторые из них японские, является идеальным форумом, чтобы принимать решения, чем именно нужно жертвовать.
Лекция 6. Основные цифровые логические схемы. 1. Интегральные схемы. 2. Комбинационные схемы. 3. Арифметические схемы.
В предыдущих разделах мы увидели, как реализовать простейшие схемы с использованием отдельных вентилей. На практике в настоящее время схемы очень редко конструируются вентиль за вентилем, хотя когда-то это было распространено. Сейчас стандартные блоки представляют собой модули, которые содержат ряд вентилей. В следующих разделах мы рассмотрим эти стандартные блоки более подробно и увидим, как они используются и как их можно построить из отдельных вентилей.
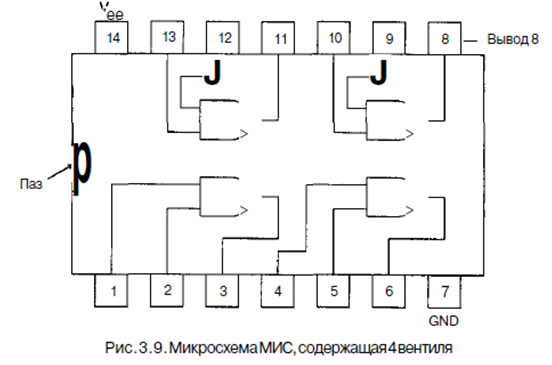
Интегральные схемы. Вентили производятся и продаются не по отдельности, а в модулях, которые называются интегральными схемами (ИС) или микросхемами. Интегральная схема представляет собой квадратный кусочек кремния размером примерно 5x5 мм, на котором находится несколько вентилей. Маленькие интегральные схемы обычно помещаются в прямоугольные пластиковые или керамические корпуса размером от 5 до 15 мм в ширину и от 20 до 50 мм в длину. Вдоль длинных сторон располагается два параллельных ряда выводов около 5 мм в длину, которые можно втыкать в разъемы или впаивать в печатную плату. Каждый вывод соединяется с входом или выходом какого-нибудь вентиля, или с источником питания, или с «землей». Корпус с двумя рядами выводов снаружи и интегральными схемами внутри официально называется двурядным корпусом (Dual Inline Package, сокращенно DIP), но все называют его микросхемой, стирая различие между куском кремния и корпусом, в который он помещается. Большинство корпусов имеют 14, 16, 18, 20, 22, 24, 28,40, 64 или 68 выводов. Для больших микросхем часто используются корпуса, у которых выводы расположены со всех четырех сторон или снизу. В предыдущих разделах мы увидели, как реализовать простейшие схемы Микросхемы можно разделить на несколько классов с точки зрения количе- ства вентилей, которые они содержат. Эта классификация, конечно, очень грубая, но иногда она может быть полезна: • МИС (малая интегральная схема): от 1 до 10 вентилей. • СИС (средняя интегральная схема): от 1 до 100 вентилей. • БИС (большая интегральная схема): от 100 до 100 000 вентилей. • СБИС (сверхбольшая интегральная схема): более 100 000 вентилей. Эти схемы имеют различные свойства и используются для различных целей. МИС обычно содержит от двух до шести независимых вентилей, каждый из которых может использоваться отдельно, как описано в предыдущих разделах. На рис. 3.9 изображена обычная микросхема МИС, содержащая четыре вентиля НЕ-И. Каждый из этих вентилей имеет два входа и один выход, что требует наличия 12 выводов. Кроме того, микросхеме требуется питание (Vcc) и «земля» (GND). Они разделяются всеми вентилями. На корпусе рядом с выводом 1 обычно имеется паз, чтобы можно было определить, что это вывод 1. Чтобы избежать путаницы на диаграмме, по соглашению не показываются неиспользованные вентили, источник питания и «земля».
Подобные микросхемы стоят несколько центов. Каждая микросхема МИС содержит несколько вентилей и примерно до 20 выводов. В 70-е годы компьютеры конструировались из большого числа таких микросхем, но в настоящее время на одну микросхему помещается целый центральный процессор и существенная часть памяти (кэш-памяти). Для удобства мы считаем, что у вентиля появляются изменения на выходе, как только появляются изменения на входе. На самом деле существует определенная задержка вентиля, которая включает в себя время прохождения сигнала через микросхему и время переключения. Время задержки обычно составляет от 1 до 10 не. В настоящее время стало возможным помещать до 10 млн. транзисторов на одну микросхему. Так как любая схема может быть сконструирована из вентилей НЕ-И, может создаться впечатление, что производитель способен изготовить микросхему, содержащую 5 млн. вентилей НЕ-И. К несчастью, для создания такой микросхемы потребуется 15 000 002 выводов. Поскольку стандартный вывод занимает 0,1 дюйм, микросхема будет более 18 км в длину, что отрицательно скажется на покупательной способности. Поэтому чтобы использовать преимущество данной технологии, нужно разработать такие схемы, у которых количество вентилей сильно превышает количество выводов. В следующих разделах мы рассмотрим простые микросхемы МИС, в которых несколько вентилей соединены определенным образом между собой для вычисления некоторой функции, но при этом требуется небольшое число внешних выводов.
Комбинационные схемы Многие применения цифровой логики требуют наличия схем с несколькими входами и несколькими выходами, в которых выходные сигналы определяются текущими входными сигналами. Такая схема называется комбинационной схемой. Не все схемы обладают таким свойством. Например, схема, содержащая элементы памяти, может генерировать выходные сигналы, которые зависят от значений, хранящихся в памяти. Микросхема, которая реализует таблицу истинности (например, приведенную на рис. 3.3, а), является типичным примером комбинационной схемы. В этом разделе мы рассмотрим наиболее часто используемые комбинационные схемы.
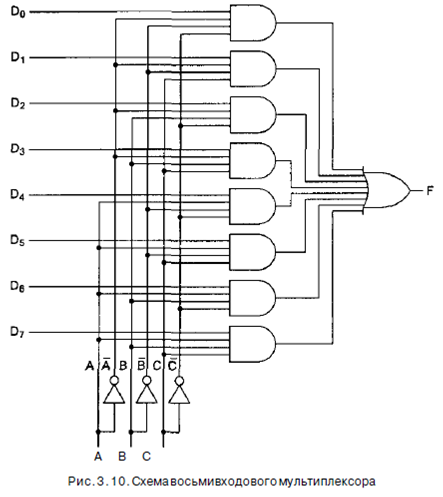
2.1.Мультиплексоры На цифровом логическом уровне мультиплексор представляет собой схему с 2" входами, одним выходом и п линиями управления, которые выбирают один из входов. Выбранный вход соединяется с выходом. На рис. 3.10 изображена схема восьмивходового мультиплексора. Три линии управления А, В и С кодируют 3-битное число, которое указывает, какая из восьми линий входа должна соединяться с вентилем ИЛИ и, следовательно, с выходом. Вне зависимости от того, какое значение будет на линиях управления, семь вентилей. И будут всегда выдавать на выходе 0, а оставшийся может выдавать или 0, или 1 в зависимости от значения выбранной линии входа. Каждый вентиль И запускается определенной комбинацией линий управления. Схема мультиплексора показана на рис. 3.10. Если к этому добавить источник питания и «землю», то мультиплексор можно запаковать в корпус с 14 выводами.
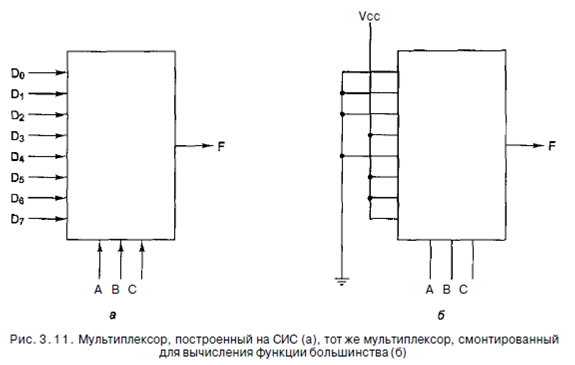
Используя мультиплексор, мы можем реализовать функцию большинства (см. рис. 3.3, а), как показано на рис. 3.11, б. Для каждой комбинации А, В и С выбирается одна из входных линий. Каждый вход соединяется или с Vcc (логическая 1), или с «землей» (логический 0). Алгоритм соединения входов очень прост: входной сигнал D; такой же, как значение в строке i в таблице истинности. На рис. 3.3, а в строках 0, 1, 2 и 4 значение функции равно 0, поэтому соответствующие входы заземляются; в оставшихся строках значение функции равно 1, поэтому соответствующие входы соединяются с логической 1. Таким способом можно реализовать любую таблицу истинности с тремя переменными, используя микросхему на рис. 3.11, а. Мы уже видели, как мультиплексор может использоваться для выбора одного из нескольких входов и как он может реализовать таблицу истинности. Его также можно использовать в качестве преобразователя параллельного кода в последовательный. Если подать 8 битов данных на линии входа, а затем переключать линии управления последовательно от 000 до i l l (это двоичные числа), 8 битов поступят на линию выхода последовательно. Обычно такое преобразование осуществляется при вводе информации с клавиатуры, поскольку каждое нажатие клавиши определяет 7- или 8-битное число, которое должно передаваться последовательно по телефонной линии.
Противоположностью мультиплексора является демультиплексор, который соединяет единственный входной сигнал с одним из 2" выходов в зависимости от значений п линий управления. Если бинарное значение линий управления равно к, то выбирается выход к.
2.2.Декодеры
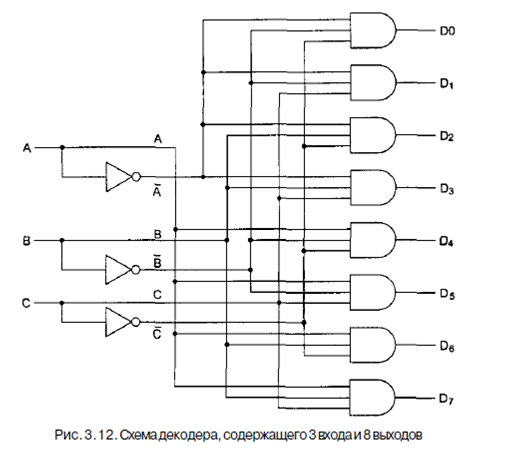
В качестве второго примера рассмотрим схему, которая получает на входе п-битное число и использует его для того, чтобы выбрать (то есть установить на значение 1) одну из 2" выходных линий. Такая схема называется декодером. Пример декодера для п=3 показан на рис. 3.12. Чтобы понять, зачем нужен декодер, представим себе память, состоящую из 8 микросхем, каждая из которых содержит 1 Мбайт. Микросхема 0 имеет адреса от 0 до 1 Мбайт, микросхема 1 - адреса от 1 Мбайт до 2 Мбайт и т. д. Три старших двоичных разряда адреса используются для выбора одной из восьми микросхем. На рис. 3.12 эти три бита - три входа А, В и С В зависимости от входных сигналов ровно одна из восьми выходных линий (Do,..., D7) принимает значение 1; остальные линии принимают значение 0. Каждая выходная линия запускает одну из восьми микросхем памяти. Поскольку только одна линия принимает значение 1, запускается только одна микросхема.
Принцип работы схемы, изображенной на рис. 3.12, не сложен. Каждый вен- тиль И имеет три входа, из которых первый или А, или А, второй или В, или В, а третий или С, или С. Каждый вентиль запускается различной комбинацией входов: Do - сочетанием А В С, Di - А В С и т. д.
2.3.Компараторы
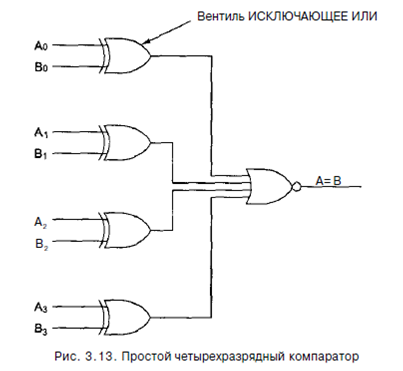
Еще одна полезная схема - компаратор. Компаратор сравнивает два слова, которые поступают на вход. Компаратор, изображенный на рис. 3.13, принимает два входных сигнала, А и В, каждый длиной 4 бита, и выдает 1, если они равны, и О, если они не равны. Схема основывается на вентиле ИСКЛЮЧАЮЩЕЕ ИЛИ, который выдает 0, если сигналы на входе равны, и 1, если сигналы на входе не равны. Если все четыре входных слова равны, все четыре вентиля ИСКЛЮЧАЮЩЕЕ ИЛИ должны выдавать 0. Эти четыре сигнала затем поступают в вентиль ИЛИ. Если в результате получается 0, значит, слова, поступившие на вход, равны; в противном случае они не равны. В нашем примере мы использовали вентиль ИЛИ в качестве конечной стадии, чтобы поменять значение полученного результата: 1 означает равенство, а 0 - неравенство.
2.4.Программируемые логические матрицы
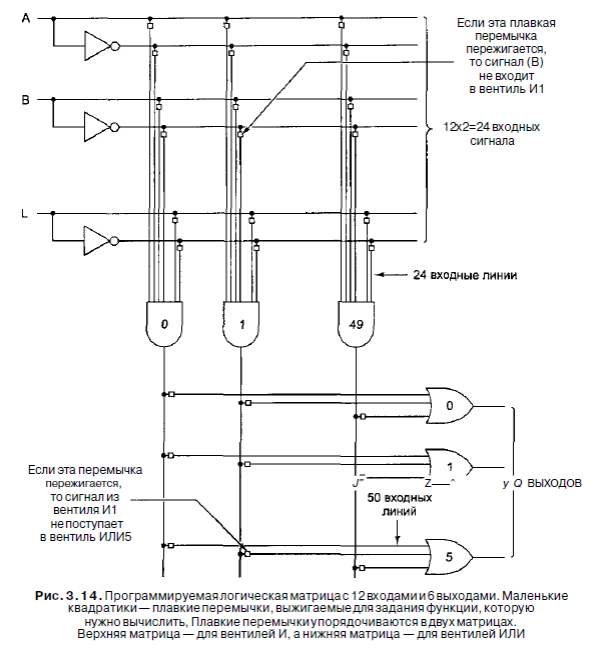
Ранее мы рассказывали, что любую функцию (таблицу истинности) можно представить в виде суммы произведений и, следовательно, воплотить в схеме, используя вентили И и ИЛИ. Для вычисления сумм произведений служит так называемая программируемая логическая матрица (рис. 3.14). Эта микросхема содержит входы для 12 переменных. Дополнительные сигналы (инверсии) генерируются внутри самой микросхемы. В итоге всего получается 24 входных сигнала. Какой именно входной сигнал поступает в определенный вентиль И, определяется по матрице 24x50 бит. Каждая из входных линий к 50 вентилям И содержит плавкую перемычку. При выпуске с завода все 1200 перемычек остаются нетронутыми. Чтобы запрограммировать матрицу, покупатель выжигает выбранные перемычки, прикладывая к схеме высокое напряжение.
Выходная часть схемы состоит из шести вентилей ИЛИ, каждый из которых содержит до 50 входов, что соответствует наличию 50 выходов у вентилей И. Какие из потенциально возможных связей действительно существуют, зависит от того, как была запрограммирована матрица 50x6. Микросхема имеет 12 входных выводов, 6 выходных выводов, питание и «землю» (то есть всего 20 выводов). Приведем пример использования программируемой логической матрицы. Рассмотрим схему, изображенную на рис. 3.3, б. Она содержит три входа, четыре вентиля И, один вентиль ИЛИ и три инвертора. Если запрограммировать нашу матрицу определенным образом, она сможет вычислять ту же функцию, используя три из 12 входов, четыре из 50 вентилей И и один из 6 вентилей ИЛИ. (Четыре вентиля И должны вычислять ABC, ABC, ABC И ABC; вентиль ИЛИ принимает эти 4 произведения в качестве входных данных.) Можно сделать так, чтобы та же программируемая логическая матрица вычисляла одновременно сумму четырех функций одинаковой сложности. Для простых функций ограничивающим фактором является число входных переменных, для более сложных - вентили И и ИЛИ.
Матрицы, программируемые в условиях эксплуатации, все еще используются. Однако предпочтение отдается матрицам, которые изготавливаются на заказ. Они разрабатываются заказчиком и выпускаются производителем в соответствии с запросами заказчика. Такие программируемые логические матрицы гораздо дешевле. А теперь мы можем обсудить три разных способа воплощения таблицы истинности, приведенной на рис. 3.3, а. Если в качестве компонентов использовать МИС, нам нужны 4 микросхемы. С другой стороны, мы можем обойтись одним мультиплексором, построенным на СИС, как показано на рис. 3.11, б. Наконец, мы можем использовать лишь четвертую часть программируемой логической матрицы. Очевидно, если необходимо вычислять много функций, использование программируемой логической матрицы более эффективно, чем применение двух других методов. Для простых схем предпочтительнее более дешевые МИС и СИС.
Арифметические схемы Перейдем от СИС общего назначения к комбинационным схемам СИС, которые используются для выполнения арифметических операций. Мы начнем с простой 8-разрядной схемы сдвига, затем рассмотрим структуру сумматоров и, наконец, изучим арифметико-логические устройства, которые играют существенную роль в любом компьютере.
3.1.Схемы сдвига
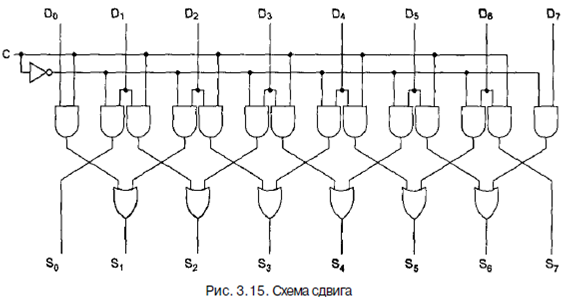
Первой арифметической схемой СИС, которую мы рассмотрим, будет схема сдвига, содержащая 8 входов и 8 выходов (рис. 3.15). Восемь входных битов подаются на линии Do,..., D7. Выходные данные, которые представляют собой входные данные, сдвинутые на 1 бит, поступают на линии So,. •., S7. Линия управления С определяет направление сдвига: 0 - налево, 1 - направо.
Чтобы понять, как работает такая схема, рассмотрим пары вентилей И (кроме крайних вентилей) Если С=1, правый член каждой пары включается, пропуская через себя соответствующий бит. Так как правый вентиль И соединен с входом вентиля ИЛИ, который расположен справа от этого вентиля И, происходит сдвиг вправо. Если С=0, включается левый вентиль И из пары, и тогда происходит сдвиг влево.
3.2.Сумматоры
Компьютер, который не умеет складывать целые числа, практически немыслим. Следовательно, схема для выполнения операций сложения является существенной частью любого процессора. Таблица истинности для сложения одноразрядных целых чисел показана на рис. 3.16, а. Здесь имеется два результата: сумма входных переменных А и В и перенос на следующую (левую) позицию. Схема для вычисления бита суммы и бита переноса показана на рис. 3.16,6. Такая схема обычно называется полусумматором.
Полусумматор подходит для сложения битов нижних разрядов двух многобитовых слов. Но он не годится для сложения битов в середине слова, потому что не может осуществлять перенос в эту позицию. Поэтому необходим полный сумматор (рис. 3.17). Из схемы должно быть ясно, что полный сумматор состоит из двух полусумматоров. Сумма равна 1, если нечетное число переменных А, В и Вход переноса принимает значение 1 (то есть если единице равна или одна из переменных, или все три). Выход переноса принимает значение 1, если или А и В одновременно равны 1 (левый вход в вентиль ИЛИ), или если один из них равен 1, а Вход переноса также равен 1. Два полусумматора порождают и биты суммы, и биты переноса. Чтобы построить сумматор, например, для двух 16-битных слов, нужно продублировать схему, изображенную на рис. 3.17, б, 16 раз. Перенос производится в левый соседний бит. Перенос в самый правый бит соединен с 0. Такой сумматор называется сумматором со сквозным переносом. Прибавление 1 к числу 111... 111 не осуществится до тех пор, пока перенос не пройдет весь путь от самого правого бита к самому левому. Существуют более быстрые сумматоры, работающие без подобной задержки. Естественно, предпочтение обычно отдается им. Рассмотрим пример более быстрого сумматора. Разобьем 32-разрядный сумматор на 2 половины: нижнюю 16-разрядную и верхнюю 16-разрядную. Когда начинается сложение, верхний сумматор еще не может приступить к работе, поскольку он не узнает значение переноса, пока не совершится 16 суммирований в нижнем сумматоре. Однако можно сделать одно преобразование. Вместо одного верхнего сумматора можно получить два верхних сумматора, продублировав соответствующую часть аппаратного обеспечения. Тогда схема будет состоять из трех 16-разрядных сумматоров: одного нижнего и двух верхних U0 и U1, которые работают параллельно. В сумматор U0 в качестве переноса поступает 0, а в сумматор U1 в качестве переноса поступает 1. Оба верхних сумматора начинают работу одновременно с нижним сумматором, но только один из результатов суммирования в двух верхних сумматорах будет правильным. После сложения 16 нижних разрядов становится известно значение переноса в верхний сумматор, и тогда можно определить правильный ответ. При таком подходе время сложения сокращается в два раза. Такой сумматор называется сумматором с выбором переноса. Можно разбить каждый 16-разрядный сумматор на два 8-разрядных и т. д.
3.3.Арифметико-логические устройства
Большинство компьютеров содержат одну схему для выполнения операций И, ИЛИ и сложения над двумя машинными словами. Обычно такая схема для п-битных слов состоит из п идентичных схем для индивидуальных битовых позиций. На рис. 3.18 изображена такая схема, которая называется арифметико-логическим устройством, или АЛУ. Это устройство может вычислять одну из 4 следующих функций: А И В, А ИЛИ В, В и А+В. Выбор функции зависит от того, какие сигналы поступают на линии Fo и F,: 00,01,10 или 11 (в двоичной системе счисления). Отметим, что здесь А+В означает арифметическую сумму А и В, а не логическую операцию И. В левом нижнем углу схемы находится двухразрядный декодер, который порождает сигналы включения для четырех операций. Выбор операции определяется сигналами управления Fo и Fj. В зависимости от значений Fo и Fi выбирается одна из четырех линий разрешения, и тогда выходной сигнал выбранной функции проходит через последний вентиль ИЛИ.
В верхнем левом углу схемы находится логическое устройство для вычисления А И В, А ИЛИ В и В, но по крайней мере один из этих результатов проходит через последний вентиль ИЛИ в зависимости от того, какую из разрешающих линий выбрал декодер. Так как ровно один из выходных сигналов декодера будет равен 1, то и запускаться будет ровно один из четырех вентилей И. Остальные три вентиля будут выдавать 0 независимо от значений А и В. АЛУ может выполнять не только логические и арифметические операции над А и В, но и делать их равными нулю, отрицая ENA (сигнал разрешения А) или ENB (сигнал разрешения В). Можно также получить X, установив INVA (инверсию А). Зачем нужны ENA, ENB и INVA, мы рассмотрим в главе 4. При нормальных условиях и ENA, и ENB равны 1, чтобы разрешить поступление обоих входных сигналов, а сигнал INVA равен 0. В этом случае А и В просто поступают в логическое устройство без изменений.
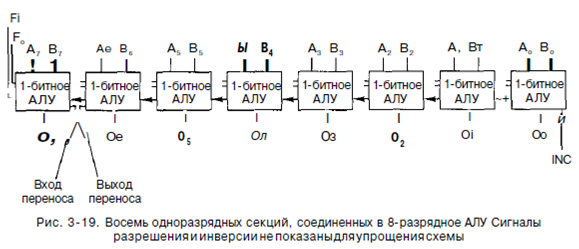
В нижнем правом углу находится полный сумматор для подсчета суммы А и В и для осуществления переносов. Переносы необходимы, поскольку несколько таких схем могут быть соединены для выполнения операций над целыми словами. Одноразрядные схемы, подобные той, которая изображена на рис. 3.18, называются разрядными микропроцессорными секциями. Они позволяют разработчику сконструировать АЛУ любой желаемой ширины. На рис. 3.19 показана схема 8-разрядного АЛУ, составленного из восьми одноразрядных секций. Сигнал INC (увеличение на единицу) нужен только для операций сложения. Он дает возможность вычислять такие суммы, как А+1 и А+В+1.
Лекция 7. Микросхемы памяти. 1.Защелки, триггеры. 2.Регистры и организация памяти. 3.Микросхемы памяти ОЗУ и ПЗУ. Память Память является необходимым компонентом любого компьютера. Без памяти не было бы компьютеров, по крайней мере таких, какие есть сейчас. Память используется как для хранения команд, которые нужно выполнить, так и данных. В следующих разделах мы рассмотрим основные компоненты памяти, начиная с уровня вентилей. Мы увидим, как они работают и как из них можно получить память большой емкости.
Защелки, триггеры.
1.1.Защелки
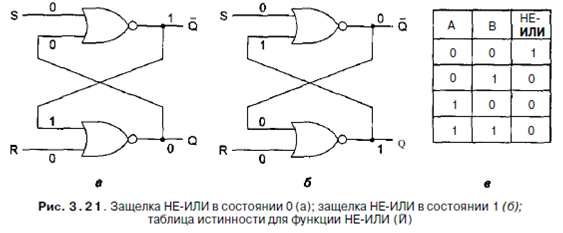
Чтобы создать один бит памяти, нам нужна схема, которая каким-то образом «запоминает» предыдущие входные значения. Такую схему можно сконструировать из двух вентилей НЕ-ИЛИ, как показано на рис. 3.21, а. Аналогичные схемы можно построить из вентилей НЕ-И. Мы не будем упоминать эти схемы в дальнейшем, поскольку они, по существу, идентичны схемам с вентилями НЕ-ИЛИ.
Схема, изображенная на рис. 3.21, а, называется SR-защелкой. У нее есть два входа: S (setting — установка) и R (resetting — сброс). У нее также есть два комплементарных (дополнительных) выхода: Q и Q. В отличие от комбинационной схемы, выходные сигналы защелки не определяются текущими входными сигналами. Чтобы увидеть, как это осуществляется, предположим, что S=0 и R=0 (вообще они равны 0 большую часть времени). Чтобы провести доказательство, предположим также, что Q=0. Так как Q возвращается в верхний вентиль НЕ-ИЛИ и оба входа этого вентиля равны 0, то его выход, Q, равен 1. Единица возвращается в нижний вентиль, у которого в итоге один вход равен 0, а другой - 1, а на выходе получается Q=0. Такое положение вещей, по крайней мере, состоятельно (рис. 3.21, а). А теперь давайте представим, что Q=l, a R и S все еще равны 0. Верхний вен- тиль имеет входы 0 и 1 и выход Q (то есть 0), который возвращается в нижний вентиль. Такое положение вещей, изображенное на рис. 3.21, б, также состоятельно. Положение, когда оба выхода равны 0, несостоятельно, поскольку в этом случае оба вентиля имели бы на входе два нуля, что привело бы к единице на выходе, а не к нулю. Точно так же невозможно иметь оба выхода равных 1, поскольку это привело бы к входным сигналам 0 и 1, что вызывает на выходе 0, ане 1. Наш вывод прост: при R=S=0 защелка имеет два стабильных состояния, которые мы будем называть 0 и 1 в зависимости от Q. А сейчас давайте рассмотрим действие входных сигналов на состояние защелки. Предположим, что S принимает значение 1, в то время как Q=0. Тогда входные сигналы верхнего вентиля будут 1 и 0, что приведет к выходному сигналу Q=0. Это изменение делает оба входа в нижний вентиль равными 0 и, следовательно, выходной сигнал равным 1. Таким образом, установка S на значение 1 переключает состояние с 0 на 1. Установка R на значение 1, когда защелка находится в состоянии 0, не вызывается изменений, поскольку выход нижнего вентиля НЕ-ИЛИ равен 0 и для входов 10, и для входов 11. Используя подобную аргументацию, легко увидеть, что установка S на значение 1 при состоянии защелки 1 (то есть при Q=l) не вызывает изменений, но установка R на значение 1 приводит к изменению состояния защелки. Таким образом, если S принимает значение 1, то Q будет равно 1 независимо от предыдущего состояния защелки. Сходным образом переход R на значение 1 вызывает Q=0. Схема «запоминает», какой сигнал был в последний раз: S или R. Используя это свойство, мы можем конструировать компьютерную память.
1.2.Синхронные SR-защелки
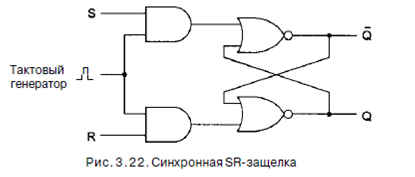
Часто бывает удобно сделать так, чтобы защелка меняла состояние только в определенные моменты. Чтобы достичь этой цели, мы немного изменили основную схему и получили синхронную SR-защелку (рис. 3.22).
Эта схема имеет дополнительный синхронизирующий вход, который обычно равен 0. Если этот вход равен 0, то оба выхода вентилей И равны 0 независимо от S и R, и защелка не меняет состояние. Когда значение синхронизирующего входа равно 1, действие вентилей И исчезает и состояние защелки становится зависимым от S и R. Для обозначения того факта, что синхронизирующий вход равен 1(то есть состояние схемы зависит от значений S и R), часто используется термин стробировать. До сих пор мы скрывали, что происходит, если S=R=1. И по понятным причинам: когда и R, и S в конце концов возвращаются к 0, схема становится недетерминированной. Единственное состоятельное положение при S=R=1- это Q=Q=0, но как только оба входа возвращаются к 0, защелка должна перейти в одно из двух стабильных состояний. Если один из входов принимает значение 0 раньше, чем другой, оставшийся в состоянии 1 «побеждает», потому что когда один из входов равен 1, он управляет состоянием защелки. Если оба входа переходят к 0 одновременно (что маловероятно), защелка переходит в одно из своих состояний наугад.
1.3.Синхронные D-за щелки
Чтобы разрешить неопределенность SR-защелки (неопределенность возникает в случае, если S=R=1), нужно предотвратить появление подобной неопределенности. На рис. 3.23 изображена схема защелки только с одним входом D. Так как входной сигнал в нижний вентиль И всегда является обратным кодом входного сигнала в верхний вентиль И, ситуация, когда оба входа равны 1, никогда не возникает. Когда D=l и синхронизирующий вход равен 1, защелка переходит в состояние Q,= l. Когда D=0 и синхронизирующий вход равен 1, защелка переходит в состояние Q=0. Другими словами, когда синхронизирующий вход равен 1, текущее значение D отбирается и сохраняется в защелке. Такая схема, которая называется синхронной D-защелкой, представляет собой память объемом 1 бит. Значение, которое было сохранено, всегда доступно на выходе Q. Чтобы загрузить в память текущее значение D, нужно пустить положительный импульс по линии синхронизирующего сигнала.
Такая схема требует наличия 11 транзисторов. Более сложные схемы могут хранить 1 бит, имея всего 6 транзисторов. На практике обычно используются последние.
1.4.Триггеры (flip-flops)
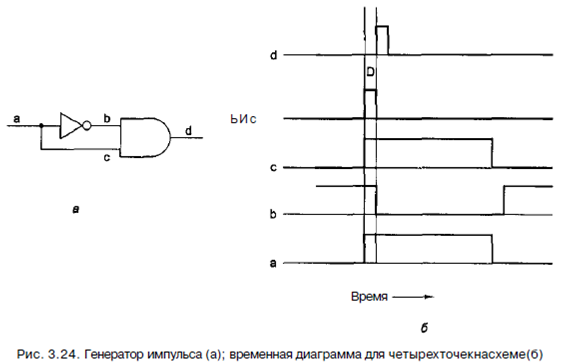
Многие схемы выбирают значение на определенной линии в определенный момент времени и запоминают его. В такой схеме, которая называется триггером, переход состояния происходит не тогда, когда синхронизирующий сигнал равен 1, а во время перехода синхронизирующего сигнала с 0 на 1 (нарастающий фронт) или с 1 на 0 (задний фронт). Следовательно, длина синхронизирующего импульса не имеет значения, поскольку переходы происходят быстро. Подчеркнем еще раз различие между триггером и защелкой. Триггер запускается фронтом сигнала, а защелка запускается уровнем сигнала. Обратите внимание, что в литературе эти термины часто путаются. Многие авторы используют термин «триггер», когда речь идет о защелке, и наоборот. Существует несколько подходов к разработке триггеров. Например, если бы существовал способ генерирования очень короткого импульса на нарастающем фронте синхронизирующего сигнала, этот импульс можно было бы подавать в D-защелку. В действительности такой способ существует. Соответствующая схема показана на рис. 3.24, а.
На первый взгляд может показаться, что выход вентиля И всегда будет нуле- вым, поскольку функция И от любого сигнала с его инверсией дает 0, но на самом деле ситуация несколько более тонкая. При прохождении сигнала через инвертор происходит небольшая, но все-таки не нулевая задержка. Данная схема работает именно благодаря этой задержке. Предположим, что мы измеряем напряжение в четырех точках а, Ь, с и d. Входовый сигнал в точке а представляет собой длинный синхронизирующий импульс (см. нижний график на рис. 3.24, б). Сигнал в точке b показан над ним. Отметим, что этот сигнал инвертирован и подается с некоторой задержкой. Время задержки зависит от типа инвертора и обычно составляет несколько наносекунд. Сигн   ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|