
|
|
Класифікація (двійкових) кодів ⇐ ПредыдущаяСтр 6 из 6 За кількістю дозволених кодових комбінацій коди поділяють на ненадлишкові (коли Ненадлишкові коди В ненадлишкових кодах дозволені всі можливі кодові комбінації N 0, що можуть бути складені з n двійкових розрядів (біт), тобто загальна кількість кодових комбінаційдорівнює числу поєднань з двох кодових символів по n штук (N 0=2n). Тому будь-яке перекручування через перешкоди одного з кодових символів в кодовому слові викликає помилку, тому, що кодове слово перетворюється в деяке інше допустиме кодове слово. Таким чином приймач прийме повідомлення з помилкою. Тобто ненадлишкові коди не дозволяють виявляти помилки. Ненадлишкові коди бувають рівномірні і нерівномірні. В рівномірних кодах усі кодові комбінації мають однакову довжину і тому при передачі повідомлень не потрібно відокремлювати одну кодову комбінацію від іншої. Прикладом рівномірного коду є телеграфний код, за допомогою якого передають 32 символи кириліці. Код має основу m =2, загальна кількість кодових слів N 0=25=32, довжина кодового слова n =log32=log25=5 біт. Код складається із 5 символів двійкового алфавіту (0,1). Всього з урахуванням цифр і знаків є потреба передавати 54 символи, тому під час передачі повідомлень використовують регістрові кодові комбінації, що настроюють приймач на прийом букв або цифр. В комп’ютерних мережах використовується восьмирозрядний двійковий код (n =8 біт, N 0=28=256). Однак вже відчутна нестача кодових слів для кодування символів у 8 ‑розрядних ЕОМ. Виникає проблема кодування символів національних алфавітів. Двохсот п’ятдесяти шести символів недостатньо для того, щоб закодувати усі необхідні символи повідомлень. У зв’язку з цим, кодами деяких основних символів кодуються додаткові символи національних алфавітів, а при розкодуванні утворюються неоднозначності. Ця проблема особливо яскраво виявляється при прийомі повідомлень із Інтернету. Для розв’язання проблеми впроваджується 16-бітовий код, спроможний закодувати N 0=216=65536 символів. Рівномірні коди не завжди є оптимальними за числом розрядів, що припадають на один переданий символ. Як це зрозуміти? Наприклад, для передачі десяткових цифр потрібний 4-бітовий рівномірний код: {0000, 0001, 0010, 0011, 0100, 0101, 0110, 0111, 1000, 1001}. Але ентропія десяткової цифри не 4 біта, а
Звідси виникла ідея використання нерівномірних кодів, у котрих одні символи (наприклад ті, які часто зустрічаються в повідомленнях) кодують більш короткими кодовими комбінаціями, а решту (ті, що рідко зустрічаються в повідомленнях) – більш довгими. І таким чином можна скласти оптимальний нерівномірний код, у якому враховуються статистичні дані про частоту появи тих або інших символів у переданих повідомленнях. Як приклад нерівномірного коду розглянемо код Хаффмена для кодування десяткових цифр 0 ~000 2 ~010 4 ~100 6 ~1100(0110) 8 ~1110(1000) 1 ~001 3 ~011 5 ~101 7 ~1101(0111) 9 ~1111(1001). У середньому для запису кодом Хаффмена однієї десяткової цифри потрібно
Це майже дорівнює ентропії десяткової цифри 3,32 біта. Чому не 3,32 біта? Тому що нерівномірні коди мають бути префіксними, коли жодна кодова комбінація не є початком іншої, що дозволяє зчитувати повідомлення, записані без відокремлень одне від одного, за допомогою спеціального алгоритму. Алгоритм розпізнавання змісту повідомлень, закодованих кодом Хаффмена: виділяють два старших біта; якщо це «11» – то це тетрада (в кодовому слові 4 біта), інакше – це тріада. В такому вигляді повідомлення передаються каналами зв’язку. Після передачі повідомлення вже на приймачі в тріадах доповнюють 0 -й старший біт, а тетради спеціальним чином також перетворюють у двійковий код. До речі, рівномірні коди є префіксними за визначенням. Але щоб нерівномірні коди стали префіксними використовують специфічні прийоми на кшталт складання алгоритмів розпізнавання змісту повідомлень, наведеному вище. Надлишкові коди В надлишкових кодах загальна кількість кодових комбінацій N 0 значно перевищує кількість кодових комбінацій N, дозволених для запису символів повідомлень (коли N≪N 0 ). Для кодування використовуються тільки ті кодові комбінації, які відрізняються не менш ніж двома розрядами. Тому будь-яка поодинока помилка під час передачі повідомлення призведе до появи недопустимої кодової комбінації і, таким чином, помилка буде виявлена. Помилка виявлена. І тут постає питання: чи можливо її виправити? В залежності від відповіді на це питання надлишкові коди поділяють на коди з виявленням помилок і коди з виправленням помилок. 5.7.2.1. Коди з виявленням помилок Найпростіший метод виявлення помилок – це перевірка на парність (непарність) суми символів у кодовому слові. Наприклад, для передачі десяткових цифр (4 біта) можна ввести 5-й біт, значення якого визначається так, щоб число одиниць було непарним (табл. 32). Таблиця 32 – Визначення п’ятого біта в двійкових кодах десяткових цифр
Загальна кількість кодових слів N 0=25=32, а використовується тільки N=10 (N<N 0). Якщо через перешкоди при передачі зміниться на протилежний будь-який символ (біт) кодового слова, то число одиниць стане парним і таким чином помилка буде виявлена. Звісно виправити автоматично її не можливо. Потрібна повторна передача повідомлення. 5.7.2.2 Коди з виправленням помилок Для виправлення поодиноких помилок без повторної передачі повідомлення множину заборонених (тих, що не використовуються) кодових комбінацій (N з= N 0– N) слід поділити на N підмножин, кожна з яких відображає визначену дозволену кодову комбінацію. Суть виправлення полягає в тому, що під час прийому забороненої (помилкової) кодової комбінації, що належить одній з підмножин, вона автоматично заміняється дозволеною кодовою комбінацією, яка відповідає цій підмножині. Наприклад, повідомлення передають трьохбітовим кодом із кількістю дозволених кодових комбінацій N =2 (А1 ~010, А2 ~101). Загальна кількість кодових комбінацій N 0=23=8, кількість заборонених кодових комбінацій, які виправляються, N з= 8 –2=6. При поодинокій помилці в А1 (один біт перемінить значення на протилежне) на приймачі може бути отримана одна з таких заборонених кодових комбінацій:{110, 000, 011}. Їм відповідає дозволена кодова комбінація010. В усіх цих випадках буде правильний прийом. Відповідно при поодинокій помилці в А2, маємо іншу підмножину заборонених кодових комбінацій: {001, 111, 100}, їм відповідає дозволена кодова комбінація 101. Таким чином, якщо передається {110, 000, 011, 010} – читається як 010, якщо {001, 111, 100, 101} – читається як 101. Тобто поодинокі помилки не тільки виявляються, але і виправляються. При подвійних і потрійних помилках – прийом повідомлення залишається помилковим. В такому випадку приймач може й не збагнути те, що в отриманому повідомленні є помилки. Але можливість того, що буде перекручено два або більше символів в кодовому слові значно менше.   Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
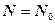 ) й надлишкові (коли
) й надлишкові (коли  <
<  ). Тут
). Тут  біта.
біта. біта.
біта.