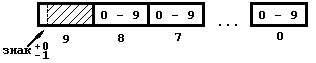|
|
Данные с фиксированной точкойСтр 1 из 8Следующая ⇒ Память
Память - устройство ЭВМ, предназначенное для хранения обрабатываемой информации. Прежде чем приступить к обсуждению организации данных в памяти нужно узнать в чем она измеряется. Бит - единица измерения количества информации и объема памяти. Измеряет минимальное количество информации, для кодирования которой достаточно одного двоичного разряда. Память ЭВМ состоит из элементов, способных запоминать значения битов (0 или 1). Такой выбор кода записи в вычислительной технике связан с тем, что в физическом мире наиболее просто реализуются системы, обладающие двумя устойчивыми состояниями. [От англ. BI (nary digi) T - binary-двоичный и digit-знак, цифра]
Минимальная адресуемая порция информации в памяти называется ячейкой памяти. Но что значит "адресовать", чтобы разобраться с этим для начала посмотрим в таблицу, в которой указана длина ячейки памяти в битах для разных вычислительных машин:
Основное преимущество ячеек памяти, как уже отмечалось выше, в том, что мы можем их адресовать, т.е. любая ячейка памяти имеет свой уникальный номер, по которому компьютер всегда может непосредственно по адресу обратиться к содержимому ячейки. Бит таким свойством не обладает (конечно если нам надо обратиться к 2057-му биту в компьютере IBM, то мы обращаемся к 257 байту и выделяем у него 1 бит (такие средства у компьютера есть), но как вы видите адресуем мы именно байт, а не бит).
Иногда последовательно идущие байты объединяют в более крупные структуры. Рассмотрим их:
На компьютере Intel *86 дополнительно есть
Слово(word) - состоит из 2 байт. Снизу указана последовательность следования байт (сначала идет байт с номером 0, потом 1,2,..).
Отметим "экзотическую" особенность представления чисел в данных компьютерах: числа размером в слово и двойное слово хранятся в памяти в перевернутом виде. Если на число отведено слово памяти, то старшие(левые) 8 битов хранятся в о втором байте слова, а младшие (правые) 8 битов - в первом байте; в терминах шестнадцатеричной системы: первые две цифры числа хранятся во втором байте слова, а две последние - в первом байте. Например, число 98 = 0062h (h означает hexadecimal - шестнадцатеричный) храниться в памяти так (А - адрес слова):
Зачем это сделано? Как известно, сложение и вычитание многозначных чисел мы начинаем с действий над младшими цифрами. С другой стороны, первые модели ПК (с процессором 8080) были 8-разрядными, в них за раз можно было считать из памяти только один байт. Поскольку в этих условиях многозначное число нельзя считать из памяти сразу, то в первую очередь приходиться считывать байт, где находятся младшие цифры числа, а для этого надо, чтобы такой байт хранился в памяти первым. По этой причине в первых моделях ПК и появилось "перевернутое" представление чисел. В последующих же моделях, где уже можно было сразу считать из памяти все число, ради сохранения преемственности, ради того, чтобы ранее составленные программы могли выполняться на новых ПК, сохранили это "перевернутое" представление. Поэтому на рисунке слова такая странная нумерация байтов. Т.е. старшая часть числа записывается во второй байт. Далее на рисунках числа под байтами означают порядок их записи в память.
Двойное слово (Double Word) - состоит из 4 байт
Для компьютеров Dec PDPII
Двойное слово также имеет размер 4 байта, но порядок следования байт другой:
Для компьютеров Motorola, IBM 370
Слово - имеет размер 4 байта и порядок следования байт прямой. Кроме этого слово подразделяется на 2 полуслова, каждое длиной 2 байта.
Компьютеры Dec VAX
Слово также имеет размер 4 байта, но порядок следования байт в слове обратный
Вернемся к компьютерам Intel и подробнее рассмотрим такую структуру как байт. По принятым соглашениям биты в байтах нумеруются справа налево(см рис.), но вообще для компьютеров это не верно (для IBM-370 порядок следования обратный):
Логические данные Логические данные (булевский тип) представлен двумя значениями: истина и ложь. Широко применяется в логических выражениях и выражениях отношения. Здесь есть одна проблема, она связана с машинным представлением логических значений "истина" и "ложь". Дело в том, что в ЭВМ, как правило, нет стандартных представлений логических величин. В ПК минимальная порция информации, обрабатываемая командами, - это байт, в связи с чем на одну логическую переменную обычно и отводят один байт. Но с другой стороны, для представления логического значения достаточно одного бита. Возникает вопрос: как заполнить 8 битов байта, если нужен только 1 бит? Это можно сделать по-разному, каждый может выбрать свой способ заполнения байта, поэтому и нет какого-то одного, стандартного способа представления логических величин. Рассмотрим только некоторые:
Символьные данные
Значением символьного типа является множество всех символов ПК.
1 символ = 1 байт (ASCII, ДКОИ, КОИ-8) 1 символ = 2 байта (Unicode)
В компьютере каждый символ обычно обозначен одним байтом - восьмью двоичными цифрами. Это всего 256 возможных значений. Естественно, все мыслимые символы в этот диапазон не уложить. Поэтому разработчики кодовой таблицы выбирают какие алфавиты охватить, а какие пропустить. Существует множество вариантов кодировки. Вот некоторые примеры реализации символов в разных кодировках:
ДКОИ латинская 'A' - C1 (16) русская 'А' - C1 (16) пробел - 20(16) - ASCII 40(16) - ДКОИ ноль - 30(16) - ASCII F0(16) - ДКОИ
Принятая в США (и зашитая в аппаратуру знакогенератора каждого IBM-совместимого компьютере) кодовая таблица 437 для DOS содержит самые частые в математических текстах греческие буквы и знаки, а также буквы характерные для некоторых западноевропейских алфавитов. Для того чтобы ввести в кодовую таблицу символы русского языка используют русификаторы. Они меняют вторую половину кодовой таблицы на русские символы. Но и тут нет единого стандарта. В зависимости от принятого способа кодировки русские строчные буквы могут образовывать один сплошной массив (кодировки ГОСТ и MIC), два массива (альтернативная кодировка), не сплошной массив (кодировка типа ЕСТЕЛ), неупорядоченный массив (кодировка КОИ-8). Постепенно набирает популярность новая кодовая таблица - Unicode. В ней каждый символ обозначен двумя байтами. В 65536 позициях новой таблицы умещаются все современные алфавиты, слоговые системы письма, специальные знаки(вроде интегралов и нот), даже китайские иероглифы. К сожалению, шрифтовой файл со всеми символами Unicode занимает несколько мегабайт. Кроме того в Турбо Паскале нет средств работы со шрифтами Unicode, в отличие от других языков (например, Delphi). Для кодировки символов на IBM-совместимых компьютерах чаще всего используется код ASCII (American Standard Code for Information Interchange - американский стандартный код для обмена информацией). Каждому символу в нем приписывается целое число в диапазоне 0..255. Это число служит кодом внутреннего представления символа. Символы с кодами (0..1F) относятся к служебным кодам.
Хранение текста С самого своего изобретения основной задачей компьютеров стало хранение и обработка информации. Если учесть, что большая часть информации представляет собой последовательность символов, то необходимость создания строковых типов возникла достаточно быстро. В основном задачу хранения символов можно решить следующим образом:
1) Массивы символов, т.е. данные хранятся в массиве, но этот тип хранения не очень удобен, т.к. слова состоят из разного числа символов и большая часть памяти просто не используется
2) Строки - самый удобный способ хранения, но реализовать его можно по-разному:
а) строка с первым значимым символом - это массив символов, первый элемент которого содержит длину строки. В языке Turbo Pascal для компьютеров IBM PC максимальная длина такой строки составляет 256 байт. Но как легко заметить большая часть памяти теряется.
б) строка с завершающим нулевым (null) символом - это последовательность символов в конце которой стоит символ с кодом #0. Основные достоинства этого способа хранения информации - отсутствие мусора, динамическое изменение размера строки (такой тип реализован в C, в последней версии Turbo Pascal 7.0 в рамках типа PChar).
Из этого следует, что строки требуют для своего хранения на 1 байт больше, чем нужно. Т.е. если нужна строка в n символов, то ее настоящая длина в памяти будет (n+1) символ.
Арифметические данные Обработка числовой информации на ЭВМ, как правило, происходит следующим образом. Поскольку исходные данные и результаты записываются в привычной для людей десятичной системе, а ЭВМ работает с двоичными числами, то при вводе числа переводятся в двоичную систему, после чего происходит обработка двоичных чисел, а при выводе результаты переводятся в десятичную систему. При этом на перевод чисел из одной системы в другую, естественно, тратиться время. Но если исходных данных и результатов немного, а их обработка занимает значительное время, тогда затраты на перевод не очень заметны. Однако есть класс задач (например, коммерческие), для которых характерен ввод большого массива числовых данных с последующим применением к ним всего одной-двух арифметических операций и выводом также большого количества результатов. В этих условиях переводы чисел из десятичной системы в двоичную и обратно могут занять львиную долю общих затрат времени, что, конечно, невыгодно. С учетом этого в компьютерах предусматривается специальное представление целых чисел, при котором они фактически не отличаются от записи чисел в десятичной системе и которое потому практически не требует перевода чисел из внешнего представления во внутреннее и обратно, и предусмотрены команды арифметических операций над такими числами. Данное представление чисел называется двоично-десятичным (binary coded decimal, BCD-числа) и строятся по следующему принципу: берется десятичная запись числа и каждая его цифра заменяется на 4 двоичные цифры (от 0000 до 1001), обозначающие эту цифру в двоичной системе. Различие между двоичными и двоично-десятичными представлениями чисел проявляется в том, что если в двоичном представлении за основу берется величина числа (независимо от того, как именно вначале оно было записано), то в двоично-десятичном представлении за основу берется запись числа, причем именно в десятичной форме (если число записать в другой системе, скажем в семеричной, то получилось бы иное представление).
Примеры представления: Intel *86: различаются неупакованные (1 цифра - 1 байт) и упакованные (2 цифры - 1 байт) десятичные цифры.
Упакуем, например, число 13 которое в двоичном виде записывается как 00001011, а в двоично-десятичном оно будет выглядеть как 00010011. Чтобы в двоично-десятичном числе был еще и знак, добавляют еще один байт, который считается знаковым. В пример приведу неупакованное девятизначное число со знаком:
IBM-370: Совершенно иначе десятичные данные реализованы в этих процессорах.
Неупакованные данные представляют собой объединение байт размером до 16 байт. При записи десятичное число разбивается на десятичные цифры записи и каждая из них записывается в отдельный байт. При этом каждый байт в шестнадцатеричной записи выглядит как F*(16), где * - десятичная цифра. При этом последний байт является знаковым и записывается в шестнадцатеричной системе как D*(16) если число отрицательное и C*(16) если число положительное. Для примера запишем числа +156(10) и –156(10) в таком виде.
Упакованные данные также представляют собой объединение байт размером до 16 байт. В них десятичное число записывается немного в другом виде. Теперь в каждый байт записывается не по одной цифре, а по две. Последний байт, как и в прошлой конструкции, играет роль знакового и представляет собой шестнадцатеричную запись *D(16) если число знаковое и *C(16) если беззнаковое (где * - последняя цифра в записи числа).
Данные с плавающей точкой Числа с плавающей точкой - форма представления чисел в ЭВМ с переменным представлением запятой, отделяющей целую часть от дробной. Действия над числами с плавающей точкой более трудоемки, а ЭВМ с плавающей запятой более сложны, чем вычислительные машины с фиксированной точкой. Диапазон чисел в ЭВМ с плавающей точкой шире, чем в ЭВМ с фиксированной точкой. В отличие от порядковых типов, значения которых всегда сопоставляются с рядом целых чисел и, следовательно, представляются в ПК абсолютно точно, значения вещественных типов определяют произвольное число лишь с некоторой конечной точностью, зависящей от внутреннего формата вещественного числа.
Intel *86 В этих процессорах нет команд, реализующих арифметические операции над вещественными числами. Это связано с тем, что аппаратная реализация этих операций - вещь дорогая, а при создании во главу угла всегда ставили дешевизну; поэтому, чтобы сократить стоимость ПК, в его систему команд и не включают команды вещественной арифметики. Как же тогда работать с вещественными числами? Возможны два решения данной проблемы. Во-первых, на основе имеющихся команд можно написать процедуры, реализующие арифметические операции над вещественными числами, и в те места программы, где требуется выполнить операции над вещественными числами, нужно вставить обращения к этим процедурам. Во-вторых, к ПК можно присоединить специальное устройство - арифметический сопроцессор, который умеет выполнять арифметические операции над вещественными числами. Центральный процессор взаимодействует с этим сопроцессором по следующему сценарию: когда надо выполнить вещественную операцию, центральный процессор посылает сигнал сопроцессору и передает ему соответствующие операнды (в ПК есть специальная команда для этого); сопроцессор выполняет указанную операцию, записывает результат в определенное место и возвращает управлению центральному процессору, который после этого продолжает свою работу. Вещественное число в компьютерах Intel занимает от 4 до 10 смежных байт и имеет следующую структуру в памяти ПК:
Здесь s - знаковый разряд числа; e - экспоненциальная часть (содержит двоичный порядок); m - мантисса числа. Если переписать число, записанное в памяти, то получим следующее число
а при переводе его из двоичного в десятичное получим обычную десятичную дробь. Рассмотрим по порядку все типы вещественных чисел на этих компьютерах. В таблице указан размер полей этих структур:
АДРЕСА Каждая ячейка памяти имеет адрес, который используется для ее нахождения. Адреса - это числа, начиная с нуля для первой ячейки увеличивающиеся по направлению к последней ячейке памяти. Поскольку адреса - это те же числа, компьютер может использовать арифметические операции для вычисления адресов памяти. Если в ЭВМ используется память большого размера, тогда для ссылок на ее ячейки приходится использовать "длинные" адреса (т.е. большие по размеру), а поскольку эти адреса указываются в командах, то эти команды оказываются "длинными" (речь, конечно же, идет о машинных командах). Это плохо, т.к. увеличиваются размеры машинных программ. Сократить размеры команд при "длинных" адресах можно, например, так. Любой адрес А можно представить в виде суммы B+D, где В - начальный адрес (база) того участка (сегмента) памяти, в котором находиться ячейка А, а D - это смещение, адрес ячейки А, отсчитанной от начала этого сегмента (от В). Если сегменты памяти небольшие, тогда и величина D будет небольшой, поэтому большая часть "длинного" адреса А будет сосредоточена в базе В. Этим и можно воспользоваться: если в команде надо указать адрес А, тогда "упрятываем" базу В в какой-нибудь регистр, а в команде вместо А указываем этот регистр и смещение D. Поскольку для записи D нужно меньше места, чем для адреса А, то тем самым уменьшается размер команды. С другой стороны, благодаря модификации адресов данная команда будет работать с адресом, равным сумме D и содержимого регистра, т.е. с нужным нам адресом А. Рассмотренный способ задания адресов в командах называется сегментированием адресов.
Далее рассматривается работа процессоров Intel *8086 при формировании физического адреса в реальном режиме работы. При этом следует учитывать, что работа других процессоров может происходить по-другому, но общий алгоритм работы скорее всего такой же. Однако следует учесть, что работа процессоров в защищенном режиме резко отличается от приведенного ниже. Большая часть арифметических операций, которые может выполнять микропроцессор 8088, ограничивается манипуляцией с 16-разрядными числами, что дает диапазон значений от 0 до 65.535 или 64 Кбайта. Поскольку полный адрес должен состоять из 20 разрядов, необходимо было разработать способ управления 20 разрядами. Решение было найдено путем использования принципа сегментированной адресации.
Если взять 16-ти разрядное число и добавить к нему в конце четыре двоичных нуля, то получится 20-ти разрядное число, которое может использоваться как адрес. Добавлением четырех нулей или сдвиг числа влево на четыре разряда фактически означает умножение числа на 16 и теперь диапазон значений будет составлять 1.024 Кбайт. К сожалению, число с четырьмя нулями в конце может адресовать только одну из 16 ячеек памяти - ту, адрес которой оканчивается на четыре нуля. Все остальные ячейки, адреса которых оканчиваются на любую из остальных 16 комбинаций из четырех бит, не могут быть адресованы при таком методе адресации. Для окончательного решения проблемы 20-разрядной адресации используются два 16-разрядных числа. Считается, что одно из них имеет еще четыре нуля в конце (выходящие за пределы разрядной сетки). Такое как бы 20-разрядное число называется сегментной частью адреса. Второе шестнадцатеричное число не сдвигается на четыре разряда и используется в своем нормальном виде. Это число называется относительной частью адреса или смещением относительно начала сегмента. Сложением этих двух чисел получают полный 20-разрядный адрес, позволяющий адресовать любую из 1.024 Кбайт ячеек памяти в адресном пространстве IBM/PC. Сегментная часть адреса задает ячейку с адресом, кратным 16, эта ячейка называется границей параграфа. Окончательное значение указывает конкретную ячейку на определенном удалении от границы параграфа. Чтобы лучше усвоить этот момент, рассмотрим все еще раз. Полный 20-разрядный адрес задается двумя частями, каждая из которых представляет собой 16-разрядное число. Сегментная часть адреса обрабатывается так, как будто он имеет четыре дополнительных нуля в конце. Эта сегментная часть может относиться к любой части всего адресного пространства - но она может указывать только на шестнадцатеричную границу, то есть, на адрес, оканчивающийся на четыре нуля. Относительная часть адреса прибавляется к сегментной части, образуя полный адрес. Относительная часть адреса может задавать любую ячейку памяти, отстоящую от ячейки, указываемой сегментной частью, не более чем на 64 Кбайта. После указанных выше соображений вам уже, наверное, понятно, что полный адрес можно указать в 4 байтах (как это и делается на компьютере) - эта структура называется дальним указателем. Если мы хотим хранить только смещение, то достаточно всего 2 байт - ближний указатель. Структура указателей этих типов для компьютеров Intel приведена на рисунке:
Для процессоров других фирм структура указателей может быть иной, например могут присутствовать дополнительные поля, сегмент и смещение могут иметь другие размеры. Рассмотрим порядок формирования физического адреса в реальном режиме работы (существует еще и так называемый защищенный режим работы микропроцессора, но про него мы говорить не будем). Под физическим адресом понимается адрес памяти, выдаваемый на шину микропроцессора. Другое название - линейный адрес. Эта двойственность в названии обусловлена наличием страничной модели организации оперативной памяти. Ее (стараничную модель) можно рассматривать как надстройку над сегментированной моделью. В случае использования этой модели оперативная память рассматривается как совокупность блоков фиксированного размера 4 Кбайт. Основное применение этой модели связано с организацией виртуальной памяти, что позволяет операционной системе использовать для работы программ пространство памяти большее, чем объем физической памяти. В страничной модели линейный адрес и физический адрес имеют разные значения. Эти названия являются синонимами только при отключении страничного преобразования адреса (в реальном режиме страничная адресация всегда отключена). Поэтому адресация происходит по следующей схеме: сначала логический адрес (записанный, например, в указателе) преобразуется в линейный адрес, а потом из линейного в физический (как вы увидели они в реальном режиме совпадают).
Методы оптимизации Выравнивание: Если вы хотите, чтобы ваша программа работала с максимальной скоростью, то надо учитывать малейшие нюансы в организации компьютера. Одним из таких мест является выравнивание. Дело в том, что компьютеры фирмы Intel читают информацию быстрее с кратных двум адресов, поэтому одно и тоже слово начинающееся с кратного адреса и с нечетного адреса будут прочитаны за различное время. В связи с этими обстоятельствами во многие компиляторы языков высокого уровня вводятся специальные директивы, чтобы компилятор размещал данные с кратных адресов. Но тут опять же надо следить за компилятором. Некоторые компиляторы не смотрят за записями (т.е. когда несколько разных типов данных объединяются в одну структуру) и выравнивают только начало записи, а не внутренние данные. В этом случае рекомендуется вводить фиктивные (неиспользуемые)данные. Существует несколько видов выравнивания: выравнивание по адресу кратному 2 (на границу слова), 4 (на границу двойного слова), 16 (на границу параграфа), 256 (на границу страницы размером 256 байт) и 4 Кбайта (адрес следующей страницы памяти размером 4 Кбайт). Последние три вида выравнивания выполняются в основном для сегментов. При правильном выравнивании доступ к данным выполняется быстрее!
Порядок заполнения данными: Это тоже очень сильно влияет на скорость обработки данных. Все дополнительное оборудование очень медленно по сравнению со скоростью процессора. Поэтому для эффективного использования скорость процессора используются устройства, которые называют буферами или кэшем. Кэш служит промежуточным запоминающим устройством, которое может с большой скоростью взять информацию из процессора и отдать информацию на меньшей скорости какому-либо оборудованию. Поэтому, как правило, между процессором и оперативной памятью компьютера стоит несколько различных кэшей различных уровней. Из этого следует, что порядок данных в памяти должен быть по возможности таким как при выполнении. Данные системы Turbo Pascal
Классы памяти:
1. Статический - постоянно присутствуют в памяти от начала до конца работы программы(типизированные константы; константы и переменные основной части программы). Особый интерес в связи с этим представляют собой типизированные константы. Дело в том, что даже если эта константа объявлена в подпрограмме, то для нее выделяется статический класс памяти.
Пример: procedure <имя процедуры>; const x:integer = 20; { x - типизированная константа} begin <делаем что-нибудь> x:=30; end;
При первом вызове этой процедуры переменной X присвоится значение 20, но при повторном ее вызове X будет равно уже 30, т.к. повторной инициализации переменной X не происходит (статический класс памяти).
2. Автоматический - память объектам выделяется при входе в блок и освобождается при выходе из него (локальные переменные подпрограмм)
3. Управляемая память(динамическая) - пользователь сам решает когда и сколько памяти ему нужно. Для реализации динамической памяти используются переменные типа указатель. Работа с динамической памятью реализуется через так называемую кучу, которая состоит из всей свободной памяти на данном компьютере. Когда пользователю необходимо выделить память он посылает администратору кучи запрос на выделение необходимого количества памяти с помощью функций GetMem или New. Если такое количество есть, то указателю присваивается адрес начала свободной области памяти необходимого объема. А потом пользователь интерпретирует полученную память так как хочет. В конце работы пользователь обязан вернуть то количество памяти которое он взял.
Примечание: Наглядный пример - блокнот из 11 страниц в котором пишут карандашом. Естественно, что в любой момент любую страницу можно очистить стирательной резинкой. Давайте поработаем администратором кучи. Для начала зарезервируем одну страницу для рабочих нужд (на ней мы будем хранить указатели). Указатель - это ссылка на место в блокноте где мы храним связанные с ними (указателями) данные. Прежде чем работать с какой-либо из страниц блокнота мы на нашей страничке записываем данные о начальной страничке наших данных, а также количество взятых страниц. Т.е. например для пункта 2 (см. текст ниже) мы пишем например так: Работа1 - 1 страница - 3 страницы Записи такого вида позволяют не запутаться компилятору в сложной структуре памяти. 1) Блокнот в начале работы пустой: 0 0 0 0 0 0 0 0 0 0 это означает что все 10 страниц - пустые (0 - ничего нет) 2) Предположим, что нам понадобилось для 1 работы 3 страницы. Ищем первые три пустые страницы и забираем их (это в переводе на компьютерный язык называется выделением памяти): 1 1 1 0 0 0 0 0 0 0 3) Для следущей 2 и 3 работы понадобилось соответственно 1 и 4 страницы. Получим: 1 1 1 2 3 3 3 3 0 0 4) Теперь предположим, что 2 работу мы сделали и страницы, выделенные под эту работу нам не нужны, - стираем все что на них написано и они снова готовы к использованию(освобождение памяти): 1 1 1 0 3 3 3 3 0 0 5) Теперь освободим страницы для работы 1 и выделим для 4 работы 2 страницы 0 0 0 0 3 3 3 3 0 0 4 4 0 0 3 3 3 3 0 0 6) Как вы видите страницы оказались фрагментированными: сначала идут 2 занятые страницы, потом 2 пустые, потом 4 занятые и 2 пустые страницы, т.е. свободно 4 страницы. Предположим, что теперь вам необходимо 3 страницы для следующей работы. Казалось бы, чего проще - ведь четыре пустых страницы, но на самом деле вы не сможете выделить страницы, т.к. не сможете найти 3 подряд идущих страницы. Обидно, но так же обстоит дело и на компьютере: из-за фрагментации кучи может возникнуть ситуация когда свободно больше памяти чем надо, а выделить необходимый объем вам не удастся и в таких случаях фиксируется ошибка.
4. Базированный класс - память объектам выделяется в одних и тех же участках памяти.
Пример: var x:longint; b:array[1..4] of byte absolute x;
В данном примере память для объекта b, который является массивом из 4 байт, выделяется в том же самом месте, что и для переменной X. Меняя значения массива мы тем самым меняем значение X.
Пример с указателями: type ab = array[1..4] of byte; {вводим новый тип} var x:longint; pb:^ab; {pb - указатель на массив из 4 элементов} begin <делаем что-нибудь> pb:=@x; {pb указывает на адрес переменной X}
Примечание:операция @ - взятие адреса объекта
Типы данных:
Логические: boolean - 1 байт (нормализованный) ByteBool ¦ WordBool ¦} ненормализованные LongBool ¦ 0 - false, иначе - true
Целые беззнаковые: Byte - 1 байт. Значения: 0..255 Word - 2 байта. Значения: 0..65535
Целые знаковые: ShortInt - 1 байт. Значения: -128..127 Integer - 2 байта. Значения: -32768..32767 LongInt - 4 байта. Значения: -2147483648..2147483647
Вещественные типы данных:
Представляют собой вещественные значения, которые используются в арифметических выражениях и занимают в памяти от 4 до 10 байт. Эффективное использование типов single, double, extended, comp возможно только при наличии сопроцессора 8087 при включенной директиве {$N+}. По умолчанию она находится в выключенном состоянии {$N-}. Вещественные десятичные числа в форме с плавающей точкой в таблице представлены в экспоненциальном(научном) виде: mE+p, где m - мантисса (целое или дробное число с десятичной точкой), "E" означает "десять в степени", p - порядок (целое число).
5.18e+02 = 5.18 * 10^2 = 518 10e-03 = 10 * 10^-3 = 0.01
Пример: var Summa: Single; Root1, Root2: Double;
Символьные: Char - 1 байт (код ASCII - кодовая таблица IBM PC) В программе значения переменных и констант типа char должны быть заключены в апострофы. Например, 'А' обозначает букву А, ' ' - пробел, ';' - точку с запятой.
Строки символов:
В Turbo Pascal для строк существует такая структура данных как string. Описывается она по-разному: string - 256 байт (строка из не более чем 255 символов) string[max] - max+1 байт (строка из не более чем max символов, где 0<max<256) Как легко видеть размер строки на 1 байт больше, чем количество доступных символов.
Пример: var Name: string[30]; {Строка не более чем из 30 символов} Address: string; {Строка не более чем из 255 символов}
Подпрограммы и их параметры Процедуры и функции представляют собой относительно самостоятельные фрагменты программы, оформленные особым образом и снабженные именем. Упоминание этого имени в тексте программы называется вызовом процедуры(функции). Отличие функции от процедуры заключается в том, что результатом исполнения операторов, образующих тело функции, всегда является некоторое единственное значение или указатель, поэтому обращение к функции можно использовать в соответствующих выражениях наряду с переменными и константами. Условимся далее называть процедуру или функцию общим именем "подпрограмма". Подпрограммы представляют собой инструмент, с помощью которого любая программа может быть разбита на ряд в известной степени независимых друг от друга частей. Такое разбиение необходимо по двум причинам. Во-первых, это средство экономии памяти: каждая подпрограмма существует в программе в единственном экземпляре, в то время как обращаться к ней можно многократно из разных точек программы. При вызове подпрограммы активизируется последовательность образующих ее операторов, а с помощью передаваемых подпрограмме параметров нужным образом модифицируется реализуемый в ней алгоритм. Вторая причина заключается в применении методики нисходящего проектирования программ. В этом случае алгоритм представляется в виде последовательности достаточно крупных подпрограмм, реализующих более или менее самостоятельные смысловые части алгоритма. Подпрограммы в свою очередь могут разбиваться на менее крупные подпрограммы нижнего уровня и т.д. Последовательное структурирование программы продолжается до тех пор, пока реализуемые подпрограммами алгоритмы не станут настолько простыми, чтобы их можно было легко запрограммировать. Рассмотрим пример использование подпрограмм на Паскале (для упрощения программы не делается проверок на деление на 0):
Function iDiv(a,b:real):real; {Функция делит одно число на другое и возвращает результат} begin iDiv:= a/b; end;
var x,y: real; begin readln(x,y); writeln(iDiv(x,y),' ',iDiv(x,-y)); end.
Для вызова функции iDiv мы просто вызвали ее в качестве параметра при обращении к встроенной процедуре WRITELN. Параметры X и Y в момент обращения к функции - это фактические параметры. Они подставляются вместо формальных параметров A и B в заголовке функции и затем над ними осуществляются нужные действия. Полученный результат присваивается идентификатору функции - именно он и будет возвращен как значение функции при выходе из нее. В программе функция iDiv вызывается дважды - сначала с параметрами X и Y, а затем X и -Y, поэтому были получены 2 разных результата. Механизм замены формальных параметров на фактические позволяет нужным образом настроить алгоритм, реализованный в подпрограмме. Подведем краткий итог: формальный параметр - это переменная в теле подпрограммы, а фактический - это выражение, стоящее в параметрах в точке вызова подпрограммы над которым проделываются формально описанные действия подпрограммы. Способы передачи параметров 1) по значению - при вызове подпрограммы выделяется память для формального параметра. Вычисляется значение фактического параметра и результат записывается в указанную память. Далее подпрограмма уже работает с этой копией (используется для входных параметров; т.к. мы работаем с копией, то сам фактический параметр изменить уже нельзя, что гарантирует защиту от побочного эффекта). По окончании работы подпрограммы память освобождается. 2) для результата - память для переменной выделяется, но туда ничего не записывается, по окнончанию работы подпрограммы происходит запись из нее в фактический параметр (используется для передачи выходных параметров, т.е. результата). 3) значение-результат - используются оба механизма (может использоваться для входных, входно-выходных и выходных параметров, но может возникнуть побочный эффект). 4) по ссылке(адресу) - память не выделяется, подпрограмма работает с памятью выделенной фактическому параметру (может быть использовано для входных, входно-выходных и выходных параметров) 5) Текст, макроподстановка – везде, где встречается обработка формального параметра происходит автоматическая замена формального параметра на текст фактического. При этом в зависимости от текста фактического параметра не всегда может произойти корректная работа компилятора. Пример: пусть x заменяется на a+b, тогда выражение вида x:=x+1 заменяется на выражение a+b:=a+b+1, а это ошибка, т.к. не понятно значение какой переменной необходимо менять. В Паскале реализованы не все из указанных выше способов передачи параметров. В этом языке программирования способ передачи определяется по описанию заголовка подпрограммы. Есл   Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|