|
|
Интерпретатор математических формул, реализованный на основе метода Дейкстры.Unit Aintr; Interface Uses Astream, Astack, Apro; Type {Если мы будем проверять правильность соседства лексем, то во флаге удобно держать тип предыдущей лексемы. Для этого объявим новый тип.} LexType = (opar { (}, cpar {) }, sgn {знак}, value{значение}); Type Pintr = ^Cintr; Cintr = object Public constructor Init (Pst:PFStreamTxt); {Передается указатель на поток} Destructor Done; virtual; Procedure Interpretate; Private P:PFStreamTxt; Pro:Cpro; St:CstackCh; {стек Дейкстры} Oldlex:lextype; {флаг Дейкстры} Procedure Failure (n:word); Procedure Lexem; {процедура обработки очередной лексемы} Procedure Number; {интерпретатор числа } Function Weight (x:char):byte; {возвращает приоритет операции или скобки} Function Right (x:byte):boolean; {возвращает значение ассоциативности; на входе – вес, на выходе истина если операции с таким весом правоассоциативны и ложь в противном случае} Procedure PushPop (x:char); {организует выталкивание из стека Дейкстры} End;
Implementation Uses Crt; Constructor Cintr.Init; Begin P:=PST; Writeln(‘Pro.Create’); Pro.Create; St.Create; {oldlex будет установлена в процессе интерпритации} end;
Destructor Cintr.Done; Begin St.Destroy; Writeln (‘Pro.Destroy’); Pro.Destroy; P:=nil; End;
Procedure Cintr.Interpretate; Var S:string; Begin St.Push (‘(‘); {помещаем первую неявную скобку} Oldlex:= opar; While not p^.IsEnd do Lexem; If not ((oldlex=value) or (oldlex=cpar)) then failure (1); PushPop (‘)’); If not st.IsEmpty then failure(2); Writeln (‘Pro.Show’); Pro.Top2Str (s); {вершина стекового процессора преобразуется в строковую переменную} Writeln (‘Ответ =’,s); {далее необязательная часть} Pro.Del; {чистим стековый процессор} If not Pro.IsEmpty then Failure(3); End;
Procedure Cintr.Lexem; Var c:char; Begin C:= p^.getchar; Case c of ‘0’..’9’: begin if not ((oldlex=opar) or (oldlex=sgn)) then failure(11); number; oldlex:=value; end; ‘(‘: begin if not ((oldlex=opar) or (oldlex=sgn)) then failure(12); st.Push (c); p^.skip; oldlex:=opar; end; ‘)’:begin If not ((oldlex=value) or (oldlex=cpar)) then failure (13); PushPop (c); P^.Skip; Oldlex:=cpar; End; ‘+’,’-‘,’*’,’/’:begin if (c=’+’) and ((oldlex=opar) or (oldlex=sgn)) then begin if not ((weight(‘p’)>weight(st.top)) or (((weight(‘p’)=weight(st.top)) and right(weigth(‘p’))) then failure (14); p^.skip; Oldlex:=sgn; End else if (c=’-’) and ((oldlex=opar) or (oldlex=sgn)) then begin if not ((weight(‘m’)>weight(st.top)) or (((weight(‘m’)=weight(st.top)) and right(weigth(‘m’))) then failure (15); PushPop(‘m’); p^.skip; Oldlex:=sgn; End else if c in [‘+’,’-’,’*’,’/’] then Begin If not ((oldlex=value) or (oldlex=cpar)) then failure (16); PushPop(c); P^.skip; Oldlex:=sgn; End {else if одноместные операции}; End; Else failure(17); End; End;
{Текст можно было несколько сократить в части обработки операций, если запоминать значение веса вершины стека. Удобнее Top заменить на GetTop.}
procedure Cintr.PushPop; var y:char; begin while true do begin if st.IsEmpty then failure(21); if ((weight(x)>weight(st.top)) or (((weight(x)=weight(st.top)) and right(weigth(x))) then break else begin st.pop(y); case y of ‘m’:begin writeln (‘Pro.Inv’); pro.Inv; end; ‘+’: begin writeln (‘Pro.Add’); pro.Add; end; ‘-‘:begin writeln (‘Pro.Sub’); pro.sub; end; ‘*’:begin writeln (‘Pro.Mul’); pro.Mul; end; ‘/’:begin writeln (‘Pro.Div’); pro._Div; end; end; end; end; if x in [‘m’,’+’,’-‘,’*’,’/’] then st.Push(x); else if x=’)’ then begin if not (st.top=’(‘) then failure(22); st.Pop(y); end; end;
function Cintr.Weight; begin case x of ‘(‘:weight:=0; ‘)’:weight:=1; ‘+’,’-‘:weight:=2; ‘/’:weight:=3; ‘*’:weight:=4; ‘p’,’m’:weight:=5; else failure(31); end; end;
function Cintr.Right; begin case x of 2:Right:=false; 3:right:=true; 4:right:=false; 5:right:=true; else right:=false; end; end;
procedure Cintr.Number; ……. End;
Procedure Cintr.Failure; Begin …… halt(1); end;
end.
Может возникнуть вполне резонный вопрос: какой из представленных двух компиляторов лучше? Ответ на него очень прост: первый проще создавать, а второй изменять. Если вы программировали первый вариант, то обратили внимание, что в нем практически пишешь программу по грамматике, при этом лишается всякая самостоятельность. Тогда как во втором компиляторе приходится применять различные конструкции для получения нужного результата. А теперь попробуем изменить оба компилятора (попробуем хотя бы изменить приоритет операций). В первой программе на методе нисходящего разбора это потребует практически полной переписки программы, тогда как во втором достаточно всего лишь изменить цифру в процедуре Weight. Похожим образом создаются языки программирования. Только там компилятор обеспечивает перевод программы с языка программирования на машинный язык. Кроме этого в нашей работе используется однопроходной вариант, не содержащий отдельного блока лексического анализа. Обычно вначале файл преобразуется: лексемы заменяются кодами. В наше случае лексемы достаточно просты поэтому дополнительное преобразование не понадобилось. В работе настоящего компилятора не ограничиваются однопроходным вариантом. Например, в языке Alpha компилятор выполняет около 30 проходов (притом из них 15 - оптимизация). В результате получается программа по скорости работы опережающая программу на Assembler'е.
Абстрактные структуры данных. Часть 2 Последовательность. Последовательность – это набор элементов разделенный на две части: первая часть состоит из всех элементов уже прочитанных к данному моменту времени (before), вторая часть состоит из всех непрочитанных элементов (after).
1. Конструктор – создает по умолчанию пустую последовательность. 2. Деструктор – уничтожает последовательность. 3. Доступ для чтения (Get) – считывает значение 1-го элемента непрочитанной части. 4. Доступ для изменения (Put, Set,…) –изменение значения 1-го элемента непрочитанной части. 5. Вперед (Skip) – изменение соотношения между прочитанной и непрочитанной частями. 6. Пуста? (IsEmpty) – проверка является ли последовательность пустой или нет. 7. Сделать пустой (DoEmpty, Clear, …) – выбрасывает все элементы из последовательности и делает пустыми обе части. 8. В конце? (IsEnd) – проверяет совпадает ли прочитанная часть со всей последовательностью. 9. В начало (GoTop) – непрочитанная часть совпадает со всей последовательностью. 10. Добавить (Append) – добавляет элемент в конец непрочитанной части. 11. Прочесть очередной элемент (Read) – считывает элемент и увеличивает прочитанную часть на 1.(является дополнительной т.к имеются методы 3 и 5) Если сравнить набор методов последовательности и набор методов потока то можно заметить, что поток – частный случай видоизменённой последовательности. Необходимо заметить, что у последовательности нет метода изменения конкретного элемента. Принципы реализации: 1. Последовательность может быть организована на основе сплошной памяти в куче (массив, строка). 2. Односвязный список в куче. 3. На основе физического файла во внешней памяти. Приведем пример реализации последовательности на основе односвязного списка. 1. Односвязный список без буфера
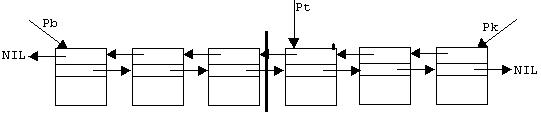
Для реализации последовательности на базе односвязного списка необходимо хранить также указатель на начало (Pb), на начало непрочитанной части (Pt), на конец (Pe). 2. Односвязный список с буфером. Буферный элемент предназначен для того чтобы облегчить процесс написания программ, при наличии буфера программисту не требуется рассматривать отдельно случаи пустой и полной последовательности. Линейный двунаправленный список (L2 - список): Элементы списка L2 – списка линейно упорядочены. Положение перед первым элементом списка называется началом списка, положение за последним элементом списка называется концом списка. Кроме элементов в списке имеется ещё указатель, расположенный в начале, в конце или между элементами списка. Обе части списка имеют одинаковые права то есть все команды пишутся обеих частей. Указатель текущего состояния может двигаться как вперед так и назад.
Набор методов для работы со L2 – списком: 1. Конструктор - создает по умолчанию пустой список. 2. Деструктор – уничтожает список. 3. Пуст? (IsEmpty) - функция, проверяющая пустоту списка. 4. В начало\В конец – переход в начало\конец списка. 5. Доступ для чтения элемента до\за указателем (GetBefore\GetAfter). (д) 6. Доступ для изменения элемента до\за указателем. (д) 7. Вперед\назад - перемещение текущего указателя. 8. В конце\В начале – функция, проверяющая положение текущего указателя списка. 9. Вставить за\до – вставка элемента после\перед указателя. 10. Изъять за\до - изъятие элемента после\перед указателем. 11:.Удалить за\до – удаление в соответствующей части. (д) 12.Сделать пустым. (д) (д) – методы, которые могут быть получены с помощью комбинации остальных. Идея реализации. 1. на основе сплошной памяти 2. 3. на основе двусвязного списка. Рассмотрим более подробно 3-ий способ реализации. 1-ый случай (без буфера). Схематично этот вариант можно показать следующим образом:
2-ой случай (с буфером).
3-ий случай (с двумя буферами)
Этот метод является симметричным, так как часть «до» является зеркальным отражением части «за» это свойство позволяет значительно упростить написание этой реализации. 4-й случай (с общим буфером).
  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|