|
|
Пошаговая детализация и нисходящее проектирование.Технология нисходящего проектирования с пошаговой детализацией является неотъемлемой частью создания хорошо структурированных программ. При написании программы с использованием этой технологии вся задача рассматривается как единственное предложение (вершина), выражающее общее назначение программы. Так как вершина редко отображает достаточное количество деталей, на основании которых можно написать программу, то поэтому надо начинать процесс детализации. Вершина разделяется на ряд более мелких задач в том порядке, в котором эти задачи должны выполнятся. В результате получим первую детализацию. Далее каждая из подзадач разбивается на подзадачи, принадлежащие второму уровню детализации. Программист завершает процесс нисходящей разработки с пошаговой детализацией, когда алгоритм настолько детализирован, чтобы его можно было бы преобразовать в программу. Вывод: пошаговая реализация это тактика разработки программы, а нисходящее проектирование это стратегия программирования. Цели структурного программирования: 1. Обеспечить дисциплину программирования. 2. Улучшить читабельность программы. 3. Повысить эффективность программы. 4. Повысить надежность программы. Рекурсия и итерация
Явный вызов. Косвенный вызов. А вызывает В, В вызывает А, обе функции рекурсивны. Обычный вызов означает, что в тот момент когда вызывается некоторая программа, следует остановка основной программы, запоминание точки вызова, затем выделяется память для подпрограммы. Все поочередно-вызываемые подпрограммы образуют структуру-стек, то же самое происходит и с данными, таким образом затраты на память связаны с глубиной стека. Рекурсивная задача в общем случае разбивается на ряд этапов. Для решения задачи вызывается рекурсивная функция. Эта функция знает, как решать только простейшую часть задачи — так называемую базовую задачу ( или несколько таких задач ). Если функция вызывается для решения базовой задачи, она просто возвращает результат. Если функция вызывается для решения более сложной задачи, то она делит эту задачу на две части: одну часть, которую функция решать умеет, и ту которую решать не умеет. Чтобы сделать рекурсию выполнимой, последняя часть должна быть похожа на исходную задачу, но по сравнению с ней проще или несколько меньше. Поскольку новая задача подобна исходной, функция вызывает новую копию самой себя, чтобы начать работать над меньшей проблемой — это называется рекурсивным вызовом или шагом рекурсии. Шаг рекурсии выполняется до тех пор, пока исходное обращение функции еще не закрыто. Шаг рекурсии может приводить к большому числу таких рекурсивных вызовов, поскольку функция продолжает деление каждой новой подзадачи на две части. Задача: написать подпрограмму решения уравнения f(x)=0, если известно, что f(x) непрерывна на [a,b] и имеет разные знаки на концах отрезка. Далее приводится пример программы содержащей итеративный и рекурсивный метод решения этой задачи.
program test; {$N+} {генерация кода с помощью сорпоцессора математических вычислений 8087 } uses crt; Type _Real = single; _FR2R = function(x: _Real): _Real; {——————————рекурсивный метод——————————————} Procedure Solve(a,b: _Real;f:_FR2R; eps: _Real; var root: _Real); {a,b - концы отрезка,f-левая часть уравнения f(x)=0,eps>0-точность решения, предпологается f -непрерывна и имеет разные знаки на концах a и b, root - найденный корень} var fa,fb,fr: _Real; Begin fa:=f(a); {вычисление значения функции на конце отрезка} root:= (a+b)/2.0; {деление отрезка пополам} fr:= f(root); {вычисление значения функции в середине отрезка} if fr=0.0 then exit; {если 0 то выход} if abs(b-a)<2.0*eps then exit; {провепка точности} if ((fa>0.0) and (fr<0.0)) or ((fa<0.0) and (fr>0.0)) then {проверка знака на концах} solve(a,root,f,eps,root) else solve(root,b,f,eps,root); end; {—————————метод итераций—————————————————} Procedure Solve1(a,b: _Real;f:_FR2R; eps: _Real; var root: _Real); var eps2,fa,fb,fr: _Real; begin fa:=f(a); {вычисление значения функции на концах отрезка} fb:=f(b); eps2:=2.0*eps; while abs(b-a)>eps2 do {прерывем если погрешность меньше заданной} begin root:=(a+b)/2.0; fr:=f(root); {вычисление значения функции в середине} if fr=0 then break; {если 0 то выход из подпрограммы} if ((fa>0.0) and (fr<0.0)) or ((fa<0.0) and (fr>0.0)) then{проверка знака} begin b:=root; {переименовываем концы} fb:=fr; end else begin a:=root; fa:=fr; end; end; root:= (a+b)/2.0; {уменьшения отрезка} end;
function f1(x:_Real):_Real;far; begin f1:=sqr(x)-4.0; {задание функции} end; function f2(x:_Real):_Real;far; begin f2:=cos(x)-x; {задание функции} end; var a,b,x,eps:_Real; begin clrscr; write('a,b,eps 1-го уравнения: '); readln(a,b,eps); solve(a,b,f1,eps,x); writeln('x1 = ',x); solve1(a,b,f1,eps,x); writeln('x2 = ',x); write('a,b,eps 2-го уравнения: '); readln(a,b,eps); solve(a,b,f2,eps,x); writeln('x3 = ',x); solve1(a,b,f1,eps,x); writeln('x4 = ',x); end.
Данная программа демонстрирует два метода решения поставленной задачи. Рекусивный метод менее эффективен, так как каждый раз программа распологает все данные в стеке. Для доказательства правильности работы рекурсивной программы можно воспользоваться методом математической индукции. Задача о Ханойских башнях: легенда гласит, что в одном из монастырей Дальнего Востока монахи пытались переместить стопку дисков с одного колышка на другой. Начальная стопка имела 64 диска, нанизанных на один колышек так, что их размеры последовательно уменьшались к вершине. Монахи пытались переместить эту стопку с этого колышка на второй при условии, что при кажлом перемещении можно брать только один диск и больший диск никогда не должен находиться над меньшим диском. Третий колышек предоставляет возможность временного размещения дисков. Считается, что когда монахи решат эту задачу наступит конец света. Требуется чтобы программа печатала четкую последовательность перемещений дисков с колышка на колышек.
Программа, демонстрирующая решение задачи выводит последовательность в файл с именем Proces.txt.
Type _Name = char;{тип совместимый с выводом в текстовый файл} _Unsign = byte; Procedure HT(source,dest,tmp:_Name;n:_Unsign; var F:text); {sourece,dest,tmp - названия источника, приемника и вспомогательного колышка, n - число дисков, F - файл, открытый для записи. Процедура печатает список ходов,файл остается открытым} begin if n = 1 then writeln(F,source,'->',dest) {если диск один то сразу перемещаем его на колышек приемник} else begin HT(source,tmp,dest,n-1,F); {меняем местами вспосогательный и приемник колышки} writeln(F,source,'->',dest); {выводим шаг} HT(tmp,dest,source,n-1,F); {меняем местами вспомогательный и источник колышки} end; end; var n:_Unsign; f: text; s,d,t: _name; f_name: string;
begin write('Введите названия источника: '); readln(s); write('Введите названия приемника: '); readln(d); write('Введите названия вспомогательного диска: '); readln(t); write('Введите количество дисков: '); readln(n);
assign(f,’Process.txt’); {связываем файловую переменную с именем файла} rewrite(f); {инициируем запись в файл} HT(s,d,t,n,f); {вызов функции} end.
Как и для предыдущей задачи для доказательства правильности работы алгоритма используем метод математической индукции. Глубина стека ≈ n, число ходов 2n-1. Метод итераций (повторений)
Пусть М – некоторое множество (значения должны быть допустимы), Р подмножество М, где Р – множество решений. При этом х Î Р Û p(х)=истина. Пусть Т некоторое преобразование из М\Р в М, т.е. Т:М\Р®М. Метод итераций (дословно – повторений) состоит в том, что строится некоторое преобразование (отображение) Т:М\Р®М и это преобразование последовательно применяется, начиная с какого-то х0ÎM: X1=T(x0), x2=T(x1), …, xn=T(xn-1), … до тех пор, пока мы впервые не получим xi такое, что p(xi)=истина (естественно, должна быть уверенность, что рано или поздно такое xi найдется). Напишем программу, находящую х. Пусть х0ÎМ (некоторая точка М) – начальное значение. x:=х0; {хÎМ} while not p(x) do begin {xÎM\P} x:=T(x); {xÎM} end; {xÎP} Для корректности данной программы необходимо и достаточно доказать, что цикл завершится за конечное число шагов. Иллюстрация работы программы:
При этом множества М и Р могут быть выбраны различными способами. Примеры:
1. Вычисление интеграла Римана
При этом величина Ikp + (Ikp - Ip)/(ks+1 - 1) будет точнее, чем Ikp. Она носит название первого шага метода Ромберга. Рассмотрим программу вычисления интеграла. {$N+} Type _Real = single; fr2r = function (x: _Real):_Real; Function Integral (a, b: _Real; f: fr2r; eps: Real): Real; {a, b – пределы интегрирования, f – достаточно гладкая подынтегральная функция; eps>0 – критерий Рунге. Функция возвращает приближенное значение интеграла Римана} var Iprev, Ipost, R: _Real; p: word; h: _Real; const p0=16; k=2;{или 3} gamma=…..{ks+1-1}; {далее могут следовать другие необходимые константы} begin if a=b then begin Integral:=0.0; exit; end; p:=p0; h:=(b-a)/p; {Вычисление Ipost для числа разбиений p, а также, возможно, его частей} R:=1e30; While abs (R) > eps do Begin Iprev:= Ipost; P:= p*k; h:= h/k;{p-иногда не обязателен} {Вычисляем Ipost для p разбиений, и, возможно, его части} R:= (Ipost- Iprev)/gamma; End; Integral:= Ipost+R; End;
Замечания: 1) Процесс сопровождают погрешности округления. Поэтому если eps выбрать достаточно малой, то процесс зациклится. 2) Вычисление квадратурных сумм следует организовать так, чтобы погрешность была меньше. Для этого, например, суммы необходимо накапливать с более высокой точностью.
2. Вычисление функции Бесселя J0(x) = å (-1)k((x/2)2k/(k!)2), где k изменяется от 0 до Данный ряд сходится к функции Бесселя при любом значении аргумента. Суммирование производится до тех пор, пока элемент ряда не станет меньше значения погрешности, т.е. êaNú <eps. Напишем простейшую программу подсчитывающую значение функции Бесселя по ряду. Function J0 (x, eps: _Real):_Real; {x – аргумент функции, eps>0 – погрешность округления. Функция возвращает приближенное значение функции Бесселя} var k: word; a, s: _Real; begin k:= 0; a:=1.0; s:= 1.0; while abs(a) > eps do begin k:= k + 1; a:= -a * sqr (x/2.0) / sqr (k); s:=s+a; end; j0:= s; end; При этом k лучше было бы хранить как вещественное число. Для увеличения скорости работы программы удобно затабулировать квадрат знаменателя. Запишем разность знаменателей на следующих один за другим шагах цикла. Zk+1 = (k+1)2-k2 = 2k + 1, в свою очередь, табулируя полученную линейную функцию, получаем Uk+1 = Zk+1 –Zk = 2. Таким образом нахождение k2 сводится к сложению представленному следующей таблицей:
Теперь мы можем написать подпрограмму, которая будет несравненно лучше предыдущей. Type _Real = single; Function J0 (x, eps: _Real): _Real; {x – значение аргумента, eps>0 – погрешность округления. Функция возвращает приближенное значение функции Бесселя}
const u: _Real = 2.0; var s, a, z, z0, r: _Real; begin a:= 1.0; s:= a; z:= -1.0; z0:= 0.0; r:= -sqr (x/2.0); while abs (a) > eps do begin z:= z + u; z0:= z0 + z; a:= a*r/z0; s:=s+a; end; J0:= s; end; Математические свойства данной программы будут те же, т.к. используется тот же математический аппарат. Функция Бесселя, вычисляемая в данной программе характеризуется следующими графиками:
maxçakú ~ ((x/2)2[x/2]/([x/2]!)2)
maxçDakú ~ b1-t maxçakú, где t – длина мантиссы, b - основание системы счисления принятой в компьютере. Таким образом, не следует брать слишком маленькие значения eps. Минимальное значение eps зависит от х и возрастает с ростом модуля х. Из всего вышесказанного можно сделать вывод, что метод рядов Тейлора хотя и является хорошим математическим аппаратом для исследований, но не приспособлен для вычислений, т.к. область его применения ограничивается небольшой окрестностью точки разложения (в данном случае точки 0).
Метод инварианта цикла. Метод инварианта цикла является частным случаем метода итераций. Задается некоторое множество величин М, РÌ М – подмножество результатов. Надо найти точку х Î Р. Для этого выделим множества IÌ M и QÌ M причем такие, что Æ ¹ I Ç Q Ì P. Таким образом, наша задача сводится к нахождению точки, которая будет принадлежать пересечению этих множеств. Причем использовать будем только такие преобразования, которые не выходят из I, то есть в нашем случае принадлежность точки множеству I является инвариантом (величиной неизменной). Пусть x0 Î I – начальная точка. Т:I\Q®I – преобразование инвариантно относительно принадлежности точки множеству I. Иллюстрация к вышесказанному:
Под действием преобразования Т точка х0 переходит в некоторую точку х1, принадлежащую множеству I. Точка х1, в свою очередь, переходит в точку х2, также принадлежащую I. Этот процесс продолжается пока некоторая точка хN не перейдет в точку принадлежащую некоторому множеству Q, которое выбрано так чтобы его пересечение с I содержалось в P. Полученная точка с одной стороны принадлежит Q, а с другой принадлежит I, в силу инвариантности преобразования Т относительно I. Схема программы: x:= x0; {xÎI} while not q(x) do begin {x ÎI\Q} x:= T(x); {x Î I} end; {x Î IÇQ Ì P}
Напишем программу иллюстрирующую вышеописанный метод, которая будет обеспечивать возведенее числа в целую положительную степень. Type _Real = single; _Unsign = word; function power (x: _Real; n: _Unsign ): Real; {х - основание, n – показатель. Подпрограмма обеспечивает возведение в степень } var z:= _Real; begin z:= 1.0; while n > 0 do {z*xn - инвариант} begin if odd(n) then {проверка нечетности} begin dec(n); {n:=n-1} z:= z*x; end else begin n:= n chr 1; {n:= n div 2} x:= sqr(x); end; end; power:= z; end; Докажем, что данная программа завершится за конечное число шагов. Подпрограмма завершает свою работу когда z = xn, т.е. пердназначена для возведения х в n – ую степень. Число повторений равно количество “0” + 2*количество “1” –1 в двоичной записи числа n <= 2*количество значащих цифр – 1 в двоичной записи = 2*]log2n[ - 1. При этом данная программа будет очень эффективна.
Метод инвариантной функции.
Метод инвариантной функции является частным случаем метода инварианта цикла. В данном случае х = х0 и необходимо вычислить f(x0). При этом I = {множество x | f(x) = f(x0)} P = {множество x | f(x) вычисляется легко}. Построим преобразование Т – инвариантное относительно I, а в качестве условия окончания примем само значение P (Q = P). Схема программы: x:= x0; {x Î I} while not p(x) do begin {x Î I\P} x:= T(x); {x Î I} end; {x Î P Ç I} result:= f(x);
Для доказательства правильности достаточно доказать, что цикл выполнится за конечное число шагов. Напишем программу иллюстрирующую данный метод. Пусть x = (a, b), а f(x) = Н.О.Д.(a, b). Необходимо вычислить Н.О.Д.(a, b). В данной программе будет использоваться тот факт, что делитель двух чисел будет являться делителем их разности. a:= a0; b:= b0; {>=0} while (a>0) and (b>0) do begin if a>b then a:= a - b else b:= b – a; end; result:= a+b; { условием выхода из цикла является равенство 0 либо a, либо b, поэтому сумма этих чисел будет нам давать то из чисел которое не равно 0 }
Метод индуктивной функции. Введём обозначения: А- некоторый алфавит, т. е. какое-то конечное или бесконечное множество, например множество букв русского языка или множество действительных чисел; Wk – множество конечных последовательностей длины >= к. f: Wk ® Y. Цель: подсчитать значение функции на этой последовательности. Выделим класс функций, для которых указанная задача решается легко. Функция f называется индуктивной, если $ отображение g:Y*A®Y такое, что " w Î Wk " xÎA f(w*x)=g(f(w),x), где f(w*x) – значение функции на последовательности расширенной на элемент x, т.е. если мы знаем значение функции на последовательности w и нам надо узнать значение на расширенной последовательности w на элемент x, то достаточно знать значение функции для w и сам элемент x. Пусть k = 0 P.GoTop; {Встать в начало} f:= f0;{f0 – значение функции на пустой последовательности} while not P.IsEnd do {IsEnd – означает что последовательность прочитана} begin P.Read(x);{или x:=P.Get;P.Skip} f:= g(f,x); end; {f=результат} При k = 1. P.GoTop; If not P.IsEnd then Begin P.Read(x); f:= f({x}); while not P.IsEnd do begin P.Read(x); f:= g(f,x); end; {f=результат} end else … {обработка ошибки};
С ростом k текст программы существенно усложняется. Примером индуктивной функции может служить функция нахождения максимума из последовательности чисел. Определим нашу функцию на пустой последовательности D. Max{x} = x = max(max(D),x). T. e. " x max(D)<= x. Таким образом max(D) = - P.GoTop; Max:= - While not P.IsEnd do Begin P.Read(x); if x>max then max:= x; end;
Или в другом виде: i:= 1; max:= -32768; while i<=n do begin x:= a[i]; i:= i+1; if x>max then max:= x; end; Утверждение (критерий индуктивности). F индуктивна Û " a, b ÎW: F (a) = F (b), "xÎX выполнено F (a*x) = F (b*x) т. е. F индуктивна тогда и только тогда, когда из равенства значений F на последовательностях a и b следует равенство и на любых “одинаково удлинненных” последовательностях a*x и b*x. Очень часто мы имеем дело с функциями которые индуктивными не являются. Это означает, что информации, заключенной в F(w) и х, недостаточно для вычисления F (w*x). Можно, однако, посмотреть, какой именно информации нам не хватает, и рассмотреть более сложную функцию, включив в нее и эту информацию тоже. В этом случае можно использовать индуктивное расширение. Определение. F: Wk ® YF называется игдуктивным расширением f:Wk® Yf если 1) F – индуктивна; 2) Всегда значение функции f можно восстановить по F, т.е. $ p:YF®Yf, такое что "wÎWk f(w) = p(F(w)). Например, нахождение номера максимального элемента последовательности не является индуктивной функцией. Индуктивное расширение: 1) номер максимального элемента на w; 2) максимальный элемент на w; 3) номер последнего элемента в w. Теорема. Для любой неиндуктивной функции существует индуктивное расширение. Функция отображающая последовательность в себя, является универсальным индуктивным расширением для любой функции. Определение. Пусть F1, F2 – два индуктивных расширения для функции f. Будем говорить, что F1<=F2 если существует преобразование p:Y2®Y1 такое что "w F1(w) = p(F2(w)). Функция F^ называется минимальным индуктивным расширением функции f, если "F- индуктивное расширение f. 1. F^<=F 2. F^(Wк)=YF^ (если отображение «НА») Теорема. Для любой неиндуктивной функции существует бесконечное количество минимальных индуктивных расширений, но все они изоморфны друг другу.
Практические выводы: 1). С точки зрения информации надо программировать то минимальное индуктивное расширение время обработки которого минимально. 2). Минимальное расширение можно не использовать. Действительно, хранится лишняя информация, но если информация стоит мало памяти, а её использование существенно сокращает время основного преобразования, то есть получаем выигрыш по времени.
То есть использовать или не использовать минимальное расширение зависит от требований по времени и объему памяти в программе.
Общая схема вычисления неиндуктивной функции, с использованием индуктивного расширения. P.GoTop; F:=F0;{вычисление индуктивного расширения не пустой последовательности } while not P.IsEnd do begin P.read(x); {x:=P.Get;P.Skip} F:=g(F,x) {g-преобразование, определ. в определ. индуктивной функции} end; f:=p(F);
Определение: Значение уÎYf называется стационарным для функции f, действующей из пространства последовательности в Yf, то есть f:W®Yf, если
 "wÎW/ f(w)= y "x ÎA f(w*x)=y "wÎW/ f(w)= y "x ÎA f(w*x)=y
Пример Существует ли в последовательности элемент, удовлетворяющий указанному условию.
Пусть j:W®Yj; f<=j<=F yj=pj(yF) Тогда схему можно изменить
P.GoTop; F:=F0; While not (P.IsEnd or stat (pj(F))) do begin x:=P.Read; F:=g(F,x); end; f:=p(F);
Допустим A={(,) +,t}. Рассматриваем класс произвольных формул, построенных на этом алфавите. True False t+t +t (t+t)+t () (t) t+t) ((t)) (t
Написать программу, осуществляющую анализ правильности формулы.
Индуктивное расширение.
f0(w)-w может быть продолжено, до правильной формулы F(w)= f1(w)- разность числа открывающих и закрывающих скобок f2(w)- последний символ в w
Докажем, что эта функция является индуктивным расширением. f(w)=истина Û f1(w)=0 & f0(w) & (f2(w))=’t’ Ú f2(w)=’)’)
f0(D)=истина
f2(D)= два решения ‘t’
Построение g
f2(w*x)=x
f1(w*x)= x=’)’Þ f1(w)-1 иначе Þ f1(w)
f0(w*x)= f0(w) & (сочетание f2(w) и х-правильное) & (f1(w*x)>=0)
Индуктивное расширение и формула не имеют стационарных точек. Стационарные точки имеют f0
Type Fch= file of char;
Function ok(var f:Fch):boolean; {F-oткрыт для чтения; ok-возвращают правильность формулы}
var x:char; f0:boolean; f1:integer; f2:char; begin seek(F,0); f0:=true; f1:=0; f2:=’(’;
while not(eof(F) or (not(f0)) do begin read(F,x); case x of f ‘(’: f1:=f1+1; ‘)’: f1:=f1-1; end; f0:=(f1>=0) and Sootv(f2,x) f2:=x; end; ok:=f0 and (f1=0) and ((f2=’t’) or (f2=’)’)); end;
function Sootv(a,b:char):boolean; begin sootV:=(((a=’(‘)or (a=’t’)) and b=’t’) or ((a=’)’) or (a=’t’)) and (b=’t’)) or (((a=’)’) or (a=’t’)) and (b=’)’)) or (((a=’(’) or (a=’+’)) and (b=’(‘)); end;
ЗАЩИТНОЕ ПРОГРАММИРОВАНИЕ Иногда, при эксплуатации программ, приходиться сталкиваться с ошибками, возникающими в процессе их выполнения. Возможны ошибки следующих типов: ð ошибки в программе ð ошибки в спецификациях ð ошибки в данных ð ошибки в передаче данных В связи с этим нужно минимизировать потенциальные неприятности. Принцип защитного программирования заключается в контроле допустимости обрабатываемых данных и генераций соответствующего кода ошибки. Требуется проверять передаваемые данные в точке входа в конкретную подпрограмму. То есть для более надежной (продуманной) работы подпрограммы требуется максимально расширить область допустимых данных передаваемых подпрограмме. Также требуется умение программы корректно генерировать исключительные ситуации. Генерацию должна производить отдельная программа обработки ошибок, которая в соответсвии с определенной ошибкой генерирует либо код ошибки, либо производит прекращение программы (фатальные ошибки). Требуется заметить, что также возможно и игнорирование определенного типа ошибок.
АБСТРАКТНЫЕ ТИПЫ ДАННЫХ Типом данных называется совокупность возможных значений и операций над этими значениями. Абстрактным типом данных называется тип данных, реализация которого скрыта от пользователя. То есть пользователь знает возможные значения этого типа, и операции над этими значениями, но не знает, как именно реализован этот тип. Классифицируются типы данных по скорости доступа к элементу структуры и размером памяти занимаемой этой структурой. По скорости доступа различают следующие типы данных: ð структуры прямого доступа (динамический вектор). ð структуры последовательного доступа (стек). В первом случае время доступа ограничено константно и не зависит от размера структуры, во втором случае время зависит от размера. По размерам, занимаемым в памяти, различают следующие структуры данных: ðстатические структуры ðдинамические структуры Статические структуры не меняют пространство занятой памяти, оно выделяется при создании структуры, и освобождается при её удалении. Динамические структуры изменяют пространство занятой памяти в ходе работы программы.
СТРУКТУРА ДАННЫХ - СТАТИЧЕСКАЯ ТАБЛИЦА. Статическая таблица – это таблица, размер которой задается при её создании. Для данной структуры определим следующий набор допустимых операций: Ø Создание таблицы заданных размеров. Ø Уничтожение таблицы. Ø Доступ к размерам таблицы (операция наблюдатель). Ø Доступ к чтению элемента по индексу (операция наблюдатель). Ø Доступ к элементу для изменения (модификатор).
Данные операции являются необходимым минимумом для работы с таблицей. Теперь рассмотрим способы реализации внутренней структуры разрабатываемого типа. В поле памяти таблица будет занимать некоторую область, в которой будут храниться размеры таблицы, ёе элементы, а также некоторая дополнительная информация. Необходимо определить, каким образом элементы таблицы будут храниться в памяти. Возможны следующие способы организации хранения элементов: 1. В памяти выделяется фиксированная область в виде двумерного массива, довольно больших размеров, заведомо превышающих размеры таблицы:
2. В памяти выделяется область статической памяти (одномерный вектор),
 в которую последовательно записываются строки таблицы: в которую последовательно записываются строки таблицы:
3. Этот способ является аналогом способа 2, но использует динамически выделенную память, то есть сначала задаются размеры таблицы, затем рассчитывается длина одномерного куска памяти и выделяется необходимое количество памяти в куче. 4. Недостаток способа №3 – это ограничение по памяти, то есть когда программа размещается в ОЗУ, ей соответствует некоторая область памяти, в которую записываются сначала все типизированные константы, а затем все глобальные переменные, данная область называется сегментом данных и имеет размер в 64Кб. То есть существует ограничение на размер структуры. Способ №4 использует метод, позволяющий обойти это ограничение. Суть этого метода заключается в следующем: задается нетипизированный указатель на одномерный массив, элементами которого являются указатели на одномерные массивы, состоящие из элементов строк (столбцов) нашей таблицы.
Замечание: Этот способ имеет более быстрый доступ к элементам таблицы и дает возможность создавать таблицы больших размеров.
Следующий модуль демонстрирует использование метода №3. Unit ATable; {$N+} {подключение числового сопроцессора} Interface{интерфейсная часть} Type _Month = (jan,feb,mar,apr,may,jul,jun,avg,sep,oct,nov,dec); _Ind1 = _Month; {тип столбца} _Ind2 = integer; {тип строки} _Elem = single; {тип элементов таблицы} Ptable = pointer; {нетипизированный указатель не таблицу} Procedure Create (var pt: Ptable; low1,high1: _Ind1; low2,high2: _Ind2; x:_Elem); {процедура инициализации таблицы, low1,high1,low2,hihg2- начальные и конечные значения индексов, pt – указатель на таблицу, х-элемент, которым изначально заполняется таблица}
Procedure Destroy (var pt: Ptable);
Function GetLow1 (pt: Ptable):_Ind1; Function GetLow2 (pt: Ptable):_Ind2; Function GetHigh1 (pt: Ptable):_Ind1; Function GetHigh2 (pt: Ptable):_Ind2; {Функции GetLow1,GetLow2,GetHigh1,GetHihg2 принимают в качестве параметра указатель на таблицу и возвращают начальные и конечные знечения индекса} Function Get (pt:Ptable; i1: _Ind1; i2: _Ind2):_Elem; {возвращает элемент (i1,i2)} Procedure Put (pt:Ptable; i1: _Ind1; i2: _Ind2; x: _Elem); {записывает элемент(i1,i2)}
Implementation{раздел описаний} Uses Crt; Type AT = Array[0..0] of _Elem; {одномерный массив } Pat = ^AT; {указатель на одномерный массив}
Rep = Record l1,h1: _Ind1; l2,h2: _Ind2; P: PAT; size1,size2: word; End; Prep = ^Rep; {указатель на запись, в которой находятся все параметры таблицы} Procedure failure(n: byte); {внутренняя процедура обработки ошибок} Begin ClrScr; Writeln('Ошибка: '); Case n of 1: Writeln('недостаточно памяти для создания таблицы'); 2: Writeln('неверные границы при создании таблицы'); 3: Writeln('неверные индексы при доступе для чтения'); 4: Writeln(' неверные индексы при доступе для записи'); End; Halt(1); {выход в операционную среду} End;
Procedure Create; Var v: Prep; k: longint; Begin if sizeof(Rep)>MaxAvail then failure(1); {проверка свободной памяти в куче} New(v); {освобождение места под запись Rep} if (Low1>High1) or (low2>high2) then failure(2); {проверка вводимых индексов} with v^ do begin l1:=low1; {параметры таблицы} l2:=low2; {параметры таблицы} h1:=high1; {параметры таблицы} h2:=high2; {параметры таблицы} size1:= ord(h1)-ord(l1)+1;{расчет длины строки} size2:= ord(h2)-ord(l2)+1; {расчет длины столбца} k:= longint(size1)*longint(size2)*sizeof(_Elem); {расчет памяти необходимой для таблицы} if(k>MaxAvail)or(k>65520) then failure(1); {проверка на возможность размещения таблицы в одном сегменте кучи } getmem(p,k); {выделение необходимой памяти для таблицы} for k:=1 to size1+size2-1 do P^[k]:= x; {заполнение таблицы элементом х} end; Pt:=v; end;
Procedure destroy; {процедура уничтожения таблицы } var k: longint; begin with Prep(Pt)^ do begin k:= longint(size1)*longint(size2)*sizeof(_Elem); freemem(p,k); {освобождение памяти от таблицы} size1:=0;size2:=0;p:= nil; l1:=_Ind1(1); h1:=_ind1(0); l2:=_Ind2(1); h2:=_ind2(0); end; dispose(Prep(pt)) {освобождение памяти от всей структуры}; Pt:=nil; end;
function Get; {процедура просмотра элемента (i1,i2)} var k: word; begin with Prep(Pt)^ do begin if (i1<l1) or (i1>h1) or (i2<l2) or (i2>h2) then failure(3); {проверка индексов} k:= (ord(i1)-ord(l1))*size2 + (ord(i2)-ord(l2))*size1; {расчет местоположения элемента} Get:= P^[k]; {возвращение элемента} end; end; procedure Put; {процедура записи элемента} var k: word; begin with Prep(Pt)^ do begin if (i1<l1) or (i1>h1) or (i2<l2) or (i2<h2) then failure(4); {проверка индексов} k:= (ord(i1)-ord(l1))*size2 + (ord(i2)-ord(l2))*size1; {расчет местоположения элемента в массиве} P^[k]:= x; {запись в массив} end; end; Function GetLow1; {возвращает начальный индекс строки } begin GetLow1:=PRep(Pt)^.l1; end; Function GetLow2; begin GetLow2:=PRep(Pt)^.l2; end; Function GetHigh2; begin GetHigh2:=PRep(Pt)^.h2; end; Function GetHigh1; begin GetHigh1:=PRep(Pt)^.h1; end; end. begin end.
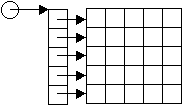
Данный модуль предоставляет следующую организацию таблицы скрытую от пользователя: создается динамический одномерный массив, в котором будут храниться элементы таблицы, затем создается запись, в полях которой хранятся все параметры таблицы, а также указатель на динамический массив, затем создается указатель на саму запись. Схематично это показано на следующем рисунке: Примечание: указанную выше программу можно существенно улучшить, введя иную организации массива в памяти (благодаря более интенсивной работе с указателями).
  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|





 . С другой стороны J0(x)»
. С другой стороны J0(x)»  (-1)k((x/2)2k/(k!)2).
(-1)k((x/2)2k/(k!)2).

 .
.
 f1(D)= 0 ‘(’
f1(D)= 0 ‘(’ x=’(’Þ f1(w)+1
x=’(’Þ f1(w)+1