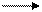|
|
Структура шин современного ПКОсобенностью современных ПК является совместное применение шин EISA, MCA, VLB, PCI, PCMCIA (CardBus) и AGP (Рис.9.3).
Шина Локальная Шина памяти кэш-памяти шина Шина PCI
 
Шина EISA или MCA
Рис. 11.3 Современный ПК с набором шин - PCI, EISA, SCSI, USB
С ростом частоты работы ЦП и изменения времени доступа к ОЗУ пропускная способность шины ISA в 8 Мбайт/сек стала тормозить работу процессора. Решение проблемы нашли в выделении канала передачи данных МП-ОЗУ в отдельную шину, построенную на базе внешнего интерфейса ЦП, и изолированную от медленной шины ISA посредством контроллера шины данных. Это повысило производительность работы центрального процессора. Все ПУ продолжали взаимодействовать с центральным процессором через системную шину. С дальнейшим ростом частоты работы ЦП тормозом в работе стало ОЗУ. Тогда ввели дополнительную высокоскоростную кэш - память, что уменьшило простои ЦП. Все ПУ продолжали работать через системную шину, но кроме ISA появились более скоростные шины EISA и MCA. По способу передачи информации интерфейсы делятся на параллельные и последовательные. Разряды данных могут передаваться в интерфейсах одновременно, т.е. параллельно. Такие интерфейсы называются параллельными, и они имеют шину данных из стольких линий, сколько разрядов передается одновременно. При передаче данных по одной линии последовательно разряд за разрядом, интерфейс называют последовательным. Кажется очевидным, что при одной и той же скорости работы линий интерфейса, пропускная способность параллельного интерфейса выше, чем у последовательного. Однако повышение производительности за счет увеличения тактовой частоты передачи и количества линий данных упирается в волновые свойства соединительных кабелей. Задержка сигналов в различных линиях не одинакова, и это особенно сказывается при увеличении длины линий, что требует для надежной передачи данных дополнительных временных и аппаратных затрат, сдерживая этим рост пропускной способности параллельного интерфейса. Кроме того, в параллельных интерфейсах с увеличением числа параллельных линий и их длины труднее реализовать компенсацию помех, наводимых за счет электрического взаимодействия линий между собой. В последовательных интерфейсах есть свои проблемы повышения производительности, но т.к. в них используется меньшее число линий, повышение пропускной способности канала связи обходится дешевле. Поэтому важным параметром интерфейсов является допустимое удаление соединяемых устройств. Оно определяется как частотными свойствами, так и помехозащищенностью используемых каналов связи. Для интерфейса, соединяющего два устройства (модуля), различаются три возможных режима обмена: дуплексный, полудуплексный и симплексный. Дуплексный режим позволяет по одному каналу связи, но имеющему две группы линий «туда» и «обратно», одновременно передавать информацию в обоих направлениях. Он может быть асимметричным, если пропускная способность в направлении «туда» и «обратно» имеет существенно различающееся значения, или симметричным. Полудуплексный режим позволяет передавать информацию по одним и тем же линиям «туда» и «обратно» поочередно в разные моменты времени, при этом интерфейс имеет средства переключения направлений канала. Симплексный (односторонний) режим предусматривает только одно направление передачи информации (во встречном направлении могут передаваться только вспомогательные сигналы интерфейса). Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также использовать различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами). Асинхронная шина не тактируется. Вместо этого обычно используется старт-стопный режим передачи и протокол "рукопожатия" (handshaking) между источником и приемником данных на шине. Эта схема позволяет гораздо проще приспособить широкое разнообразие устройств и удлинить шину без беспокойства о перекосе сигналов синхронизации и о системе синхронизации. Если может использоваться синхронная шина, то она обычно быстрее, чем асинхронная, из-за отсутствия накладных расходов на синхронизацию шины для каждой транзакции. Выбор типа шины (синхронной или асинхронной) определяет не только пропускную способность, но также непосредственно влияет на емкость системы ввода/вывода в терминах физического расстояния и количества устройств, которые могут быть подсоединены к шине. Асинхронные шины по мере изменения технологии лучше масштабируются. Шины ввода/вывода обычно асинхронные. Среди применяемых в современных ПК интерфейсов можно отметить EIDI, SCSI, SSA, USB, FireWire (IEEE 1394) и DeviceBay. Среди интерфейсов передачи данных особняком стоят порты ввода/вывода, использующиеся для подключения низкоскоростных периферийных устройств: последовательный порт (COM), параллельный порт (LPT), игровой порт и инфракрасный порт (IrDA). На определенном этапе развития компьютеров стали широко использовать мультимедиа. Сразу выявилось узкое место во взаимодействии центрального процессора и видеокарты. Потребовалась пропускная способность более 100 Мбайт/с. Имеющиеся системные шины ISA, ЕISA, МСА не удовлетворяли этим условиям. Их пропускная способность составляла от 16 до 30 Мбайт/сек. Стоит вспомнить, как развивались средства ввода/вывода. Уже к самым первым компьютерам требовалось подключить какие-то внешние устройства, в том числе для ввода и вывода на перфокарты, на магнитные ленты, нужны были принтеры, а затем диски и множество других устройств. Однако эти подключения оставались частными решениями, выполненными без соблюдения каких-либо общепринятых стандартов. Когда началось массовое производство миниЭВМ, потребовались технологии для унификации ввода/вывода, в ответ на это появилась архитектура общей шины, которая обеспечила единообразие подключения периферии, открыв, тем самым, рынок внешних устройств. В последующем, для связи с периферией была выделена отдельная специализированная шина PCI (Peripheral Connection Interface); она оказалась настолько удобной, что сохранилась до сих пор без радикальных изменений. Идеология шины PCI, из самого названия которой следует, что она служит для подключения периферии, складывалась в то время, когда сервер рассматривался как нечто изолированное. Поэтому в нее естественным образом заложена возможность подключения ограниченного количества периферийных устройств через контроллеры, соответствующие каждому типу устройства. Традиционный ввод/вывод предполагает подключение накопителей напрямую к стандартной шине PCI; для этого широко используются параллельные интерфейсы SCSI (Small Computer Systems Interface), ATA (Advanced Technology Attachment) или Fibre Channel Arbitrated Loop (FC-AL). Одновременно постепенно происходит сериализация интерфейсов; компьютерная индустрия мигрирует на Serial Attached SCSI и Serial ATA. Выход был найден с разработкой и внедрением локальных высокоскоростных шин, посредством которых можно было связаться с памятью, на этой же шине работали жесткие диски, что также повышало качество вывода графической информации. Первой такой шиной была шина VL-bus, практически повторявшая интерфейс МП i486. Затем появилась локальная шина РСI. Она была процессорно-независимой и поэтому получила наибольшее распространение для последующих типов МП. Эта шина имела частоту работы 33 МГц и при 32-х разрядных данных обеспечивала пропускную способность в 132 Мбайт/с. Системная шина ISA по-прежнему использовалась в компьютерах, что позволяло применять в новых компьютерах огромное количество ранее разработанных аппаратных и программных средств. В такой системе ввода-вывода различные ПУ подключались к разным шинам. Медленные - к ISA, а высокоскоростные - к РСI. Важнейшее отличие шины PCI от шины ISA заключается в возможности динамического конфигурирования периферийных устройств, то есть система распределяет ресурсы между периферийными устройствами оптимальным образом и без постороннего вмешательства. С появление шины РСI стало целесообразным использовать высокоскоростные параллельные и последовательные интерфейсы ПУ (SCSI, ATA, USB). Появление шины РСI не сняло всех проблем по качественному выводу визуальной информации для 3-х мерных изображений, "живого" видео. Здесь уже требовались скорости в сотни Мбайт/сек. В 1996г. фирма Intel разработала новую шину AGP, предназначенную только для связи ОЗУ и процессора с видеокартой монитора. Эта шина обеспечивала пропускную способность в сотни Мбайт/сек. Она непосредственно связывала видеокарту с ОЗУ минуя шину РСI. Все шины систем ввода-вывода объединяются в единую транспортную среду передачи информации с помощью специальных устройств: мостов и контроллеров ввода-вывода (Chipset). Мост – устройство, применяемое для объединения шин, использующих разные или одинаковые протоколы обмена. Мост – это сложное устройство, которое осуществляет не только коммутацию каналов передачи данных, но и производит управление соответствующими шинами. В структуре компьютера, использующего шину РСI, применяются три типа мостов. Мост шины – южный мост (РСI Bridge), производящий подключение шины РСI к другим шинам, например, ISA или ЕISA. Главный мост – северный мост (Host Bridge), соединяющий шину РСI с системной шиной, кроме того, этот мост содержит контроллер ОЗУ, арбитр и схему автоконфигурации. Одноранговый мост (Peer-to-Peer) для соединения двух шин РСI между собой. Это делается для увеличения числа устройств, подключаемых к шине. Для управления шинами и обеспечения выполнения функций интерфейсов, входящих в систему ввода-вывода, применяются специальные контроллеры и схемы. К ним можно отнести контроллеры прерываний 8259А и прямого доступа к памяти 8237А, таймер 8254А, часы реального времени, буферы шин данных, дешифраторы, мультиплексоры, регистры и другие логические устройства. PCI Express По прогнозам, в ближайшие десять лет требования к пропускной способности шин ввода-вывода возрастут в 50 раз. Но традиционная архитектура параллельных шин типа PCI и AGP уже почти достигла предела своих возможностей (физический лимит для них - примерно 1 ГГц). Последовательный интерфейс PCI Express, имеющий много общего с сетевой организацией обмена данными, призван заменить шину PCI (и ее клон - AGP), исправно работающую в компьютерной технике уже более десяти лет. В то время как процессоры уже не первый год успешно движутся в направлении параллельных архитектур (SIMD-расширения, суперскалярность, конвейеризация, HyperTreading и многоядерность), шины передачи данных не менее успешно переходят на последовательные решения. Причины обеих тенденций схожи и довольно просты - необходимо сбалансированное наращивание производительности всех компонентов компьютеров, однако не всякие существующие архитектурные решения способны эффективно масштабироваться. PCI Express была разработана с расчетом на разнообразные применения - от полной замены шин PCI 2.2 или PCI-X в настольных компьютерах и серверах до использования в мобильных, встроенных и коммуникационных устройствах. Номинальной рабочей частотой шины PCI Express является 2,5 ГГц. Физическая реализация шины передачи данных - это две дифференциальные пары проводников с импедансом 50 Ом (первая пара работает на прием, вторая - на передачу), данные по которым передаются с использованием избыточного кодирования по схеме "8/10" с исправлением ошибок. Это позволяет исправлять многие простые ошибки, неизбежные на столь высоких частотах. Как и в любой сети, передаваемые данные дополнительно нарезаются небольшими кусочками - фреймами. При тактовой частоте шины 2,5 ГГц мы получим скорость 2,5 Гбит/с. С учетом выбранной схемы "8/10" выходит 250 Мбайт/с, однако многоуровневая сетевая иерархия не может не сказаться на скорости работы, и реальная производительность шины оказывается значительно ниже - всего лишь около 200 Мбайт/с в каждую сторону. Впрочем, даже это на 50% больше, чем теоретическая пропускная способность шины PCI. Но это далеко не предел: PCI Express позволяет объединять в шину нескольких независимых линий передачи данных. Стандартом предусмотрено использование 1, 2, 4, 8, 16 и 32 линий - передаваемые данные поровну распределяются между ними по схеме "первый байт на первую линию, второй - на вторую,..., n-й байт на n-ю линию, n+1-й снова на первую, n+2 снова на вторую" и так далее. Это не параллельная передача данных и даже не увеличение разрядности шины (поскольку все передающиеся по линиям данные передаются абсолютно независимо и асинхронно) - это именно объединение нескольких независимых линий. Причем передача по нескольким линиям никак не влияет на работу остальных слоев "пирамиды" и реализуется сугубо на "нижнем", физическом уровне. Именно этим достигается прекрасная масштабируемость PCI Express, позволяющая организовывать шины с максимальной пропускной способностью до 32x200=6,4 Гбайт/с в одном направлении, под стать лучшим параллельным шинам сегодняшнего дня. PCI Express относится к шинам класса "точка-точка", то есть одна шина может соединять только два устройства (в отличие от PCI, где на общую шину "вешались" все PCI-слоты компьютера), поэтому для организации подключения более чем одного устройства в топологию организуемой PCI Express, как и в Ethernet-решениях на базе витой пары или устройствах USB, придется вставлять хабы и свитчи, распределяющие сигнал по нескольким шинам. Это тоже одно из главных отличий PCI Express от прежних параллельных шин. Чипсет В настоящее время управление потоками передаваемых данных производится с помощью мостов и контроллеров, входящих в ChipSet. Именно ChipSet определяет основные особенности архитектуры компьютера и, соответственно, достигаемый уровень производительности в условиях, когда лимитирующим фактором становится не процессор, а его окружение – память и система ввода-вывода. В плане практической реализации шина PCI Express представляет собой целый аппаратный комплекс, затрагивающий северный и южный мосты чипсета, коммутатор и оконечные устройства. Новым термином здесь является коммутатор (switch), заменяющий одну шину со многими подключениями коммутируемой технологией.
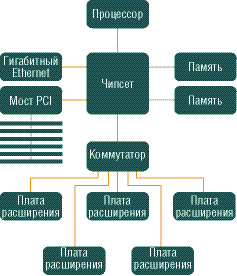
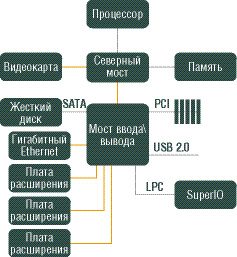
Коммутатор обеспечивает одноранговую связь между различными оконечными устройствами, то есть снижает нагрузку на мост. Поддерживаются несколько виртуальных каналов на один физический. Примерные схемы внедрения PCI Express в настольный компьютер и сервер представлены на следующем рисунке.
В "десктопных" системах PCI Express 16x в первую очередь вытеснит AGP 8x в качестве "графической шины", соединяющей видеокарту и северный мост чипсета. Затем на PCI Express пересадят многие интегрированные устройства - гигабитный сетевой и RAID-контроллеры. К обычным PCI-слотам добавят PCI Express x1. В качестве межчипсетной шины (соединяющей мосты чипсета) PCI Express будет выступать вместе со старыми шинами (VIA VLink, SiS MuTIOL) - некоторые производители чипсетов пока не желают отказываться от своих проприетарных шин. №8. Основные характеристики канала связи Основные характеристики канала связи (рис. 5.2) – пропускная способность и достоверность передачи данных. Пропускная способность канала оценивается предельным числом бит данных, передаваемых по каналу за единицу времени, и измеряется в бит/с (с-1). Достоверность передачи данных характеризуется вероятностью искажения бита, которая для каналов связи без дополнительных средств защиты от ошибок составляет, как правило, 10-4 – 10-6. Основная причина искажений – воздействие помех на линию связи и, отчасти, наличие шумов в АПД. Помехи носят импульсный характер и имеют тенденцию к группированию – образованию пачек помех, искажающих сразу группу соседних бит в передаваемых данных. Линии связи. Для передачи данных используются линии связи различных типов: проводные (воздушные), кабельные, радиорелейные, волоконно-оптические и радиоканалы наземной и спутниковой связи. Кабельные линии состоят из скрученных пар проводов или коаксиальных кабелей. Основные характеристики линий связи – полоса частот, удельная стоимость и помехоустойчивость. Полоса частот
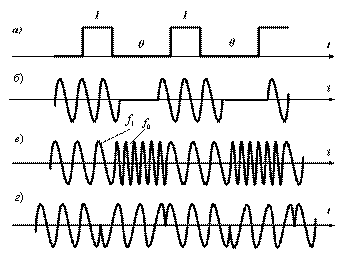
Рис. 5.4. Последовательность двоичных сигналов Пропускная способность канала. Пропускная способность канала зависит от полосычастот линии связи и отношения мощностей сигнала и шума. Максимальная пропускная способность канала, настроенного на основе линии с полосой частот F и отношением сигнал-шум Р с/ Р ш, составляет (бит в секунду) Значение (1+ Р с/ Рш) определяет число уровней сигнала, которое может быть воспринято приемником. Так, если отношение Р с/ Р ш>3, то единичный сигнал может переносить четыре значения, т. е. При передаче данных широко используются двоичные сигналы, принимающие значения 0 и 1. Временная диаграмма последовательности таких сигналов, передаваемых по линии связи, изображена на рис. 5.4, где сверху указаны значения, переносимые сигналом. Минимальная длительность такта, с которым могут передавался сигналы по каналу с полосой частот F, равна Это выражение определяет пропускную способность двоичного канала. Величина в квадратных скобках определяет долю двоичных символов, которые передаются по каналу с частотой 2 F без искажений. Если помехи отсутствуют, вероятность искажения символа Наиболее распространенный тип капала – телефонный с полосой пропускания 3,1 кГц и диапазоном частот от f Н =0,3 кГц до f Н = 3,4 кГц. Коммутируемый телефонный канал обеспечивает скорость передачи данных С=1200 бит/с, а некоммутируемый – до 9600 бит/с. Эффективность использования канала связи для передачи данных принято характеризовать удельной пропускной способностью Стандартизированы следующие скорости передачи данных по каналам связи: 200, 300, 600, 1200, 2400, 4800, 9600, 12000, 24000, 48000 и 96000 бит/с. Каналы с пропускной способностью до 300 бит/с называются низкоскоростными, от 600 до 4800 бит/с – среднескоростными и с большей пропускной способность – высокоскоростными.
Способы передачи данных. Для передачи данных по каналам с различными характеристиками используются разные способы, обещающие максимальное использование свойств каналов для повышения скорости и достоверности передачи данных при умеренной стоимости аппаратуры. Данные первоначально предоставляются последовательностью прямоугольных импульсов (рис. 5.4). Для их передачи без искажения требуется полоса частот от нуля до бесконечности. Реальные каналы имеют конечную полосу частот, с которой необходимо согласовать передаваемые сигналы. Согласование обеспечивается, во-первых, путем модуляции – переноса сигнала на заданную полосу частот и, во-вторых, путем кодирования – преобразовании данных в вид, позволяющий обнаруживать и исправлять ошибки, возникающие из-за помех в канале связи. При использовании высокочастотных проводных и кабельных линий, полоса частот которых начинается примерно от нуля, сигналы можно передавать в их естественном виде – без модуляции (в первичной полосе частот). Каналы, работающие без модуляции, называются телеграфными и обеспечивают передачу данных со скоростью, как правило, 50-200 бит/с.
Рис. 5.5. Канал с модуляцией
Когда канал имеет резко ограниченную полосу частот, как, например, радиоканал, передача сигналов должна выполняться в этой полосе и перенос сигнала в заданную полосу производится посредством модуляции по схеме, изображенной на рис. 5.5. В этом случае между оконечным оборудованием данных, работающим с двоичными сигналами, и каналом устанавливается modem – модулятор и демодулятор. Модулятор перемещает спектр первичного сигнала в окрестность несущей частоты f 0. Демодулятор выполняет над сигналом обратное преобразование, формируя из модулированного сигнала импульсный двоичный сигнал.
Рис. 5.6. Способы модуляции
Способы модуляции подразделяются на аналоговые и дискретные. К аналоговым относятся амплитудная, частотная и фазовая модуляция (рис. 5.6). При амплитудной (рис. 5.6, б) производится модуляция амплитуды несущей частоты первичным сигналом (рис. 5.6, а). При частотной модуляции (рис. 5.6, в) значения 0 и 1 двоичного сигнала передаются сигналами с различной частотой – f 0 и f 1. При фазовой модуляции (рис. 5.6, г) значениям сигнала 0 и 1 соответствуют сигналы частоты f 0 с разной фазой. Дискретные способы модуляции применяются для преобразования аналоговых сигналов, например речевых, в цифровые. Для этих целей наиболее широко используются амплитудно-импульсная, кодово-импульсная и времяимпульсная модуляция. Кодирование передаваемых данных производится в основном для повышения помехоустойчивости данных. Так, первичные коды символов могут быть представлены в помехозащищенной форме – с использованием кодов Хемминга, обеспечивающих обнаружение и исправление ошибок в передаваемых данных. В последнее время функция повышения достоверности передаваемых данных возлагается на оконечное оборудование данных и обеспечивается за счет введения информационной избыточности в передаваемые сообщения.
Аппаратура передачи данных. Основное назначение АПД – преобразование сигналов, поступающих с оконечного оборудования, для передачи их в полосе частот канала связи и обратное преобразование сигналов, поступающих из канала. При работе с телеграфным каналом, сигналы по которому передаются без модуляции (в первичной полосе частот), указанные функции реализуются устройством преобразования телеграфных сигналов, а при работе с телефонным и высокочастотным каналом – модемом. Основные элементы модулятора и демодулятора представлены на рис. 5.7. В рассматриваемом случае передача данных в канал производится синхронно с частотой, соответствующей скорости работы канала, например с частотой 1200 Гц. Сигналы синхронизации S Т формируются в модуляторе тактовым генератором ТГ. По каждому сигналу синхронизации S T в блок модуляции БМ вводится двоичный сигнал Т, представляющий собой бит данных. Несущая частота формируется генератором ГНЧ. Модулированный сигнал поступает на полосовой фильтр ПФ, ограничивающий полосу частот сигнала в соответствии с нижней и верхней границей полосы канала. Затем сигнал с заданной полосой частот передается по каналу в демодулятор, проходит через полосовой фильтр, выделяющий заданную полосу частот, и поступает в блок демодуляции. №31. Суперскалярная архитектура процессора. Процессоры, имеющие в своем составе более одного конвейера, называются суперскалярными. Смысл суперскалярной обработки - наличие в аппаратуре средств, позволяющих одновременно выполнять две и более скалярных операций, т.е. команд обработки пары чисел. В самом деле, суть этого метода довольно проста: имеется в виду дублирование устройств процессора. Так например, Pentium имеет два конвейера выполнения команд (Рис. 11.4). При этом существуют различные способы реализации суперскалярной обработки. Первый способ чаще всего применяется в RISC-процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша команд) несвязанных команд и параллельном запуске их на исполнение. Обычно процессор выполняет две несвязанные команды одновременно, как например, в процессорах DEC серии Alpha. Этот метод хорош тем, что он "прозрачен" для программиста - составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства. Второй способ реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует не связанные операции в пакеты, содержимое которых строго соответствует структуре процессора. Например, если процессор содержит функционально независимые устройства сложения, умножения, сдвига и деления, то максимум, что компилятор может "уложить" в один пакет - это четыре разнотипные операции: сложение, умножение, сдвиг и деление. Сформированные пакеты операций преобразуются компилятором в командные слова. Функции стадии С1 (выборка команд а также тезис – один конвейер хорошо, а два лучше) позволяют реализовать структуру с двойным конвейером.
С1 С2 С3 С4 С5
Рис. 11.4 Двойной конвейер из пяти стадий
Можно и дальше наращивать число конвейеров, но это значительно осложнило бы аппаратную часть. Вместо этого было предложено использовать один конвейер с большим количеством функциональных блоков (Pentium II – суперскалярный процессор).
С4
С1 С2 С3 С5
Рис 11.5 Суперскалярный процессор с пятью функциональными блоками До сих пор мы с вами рассматривали возможности увеличения производительности вычислительной системы на основе параллелизма на уровне команд. При этом к системе предъявлялись следующие требования:
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров. К тому же, как мы уже отмечали, кроме параллелизма на уровне команд существует параллелизм на уровне данных, реализация этого вида параллелизма требует применения многопроцессорной архитектуры.
№63. Параллельная обработка данных. Пути повышения производительности ВС заложены в ее архитектуре. С одной стороны это совокупность процессоров, блоков памяти, устройств ввода/вывода ну и конечно способов их соединения, т.е. коммуникационной среды. С другой стороны, это собственно действия ВС по решению некоторой задачи, а это операции над командами и данными. Вот собственно и вся основная база для проведения параллельной обработки. Параллельная обработка, воплощая идею одновременного выполнения нескольких действий, имеет несколько разновидностей: суперскалярность, конвейеризация, SIMD – расширения, Hyper Threading, многоядерность. В основном эти виды параллельной обработки интуитивно понятны, поэтому сделаем лишь небольшие пояснения. Если некое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть, пять таких же независимых устройств, способных работать одновременно, то ту же тысячу операций система из пяти устройств может выполнить уже не за тысячу, а за двести единиц времени. Аналогично система из N устройств ту же работу выполнит за 1000/N единиц времени. Подобные аналогии можно найти и в жизни: если один солдат вскопает огород за 10 часов, то рота солдат из пятидесяти человек с такими же способностями, работая одновременно, справятся с той же работой за 12 минут (параллельная обработка данных), да еще и с песнями (параллельная обработка команд). Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в форме с плавающей запятой? Целое множество мелких операций таких, как сравнение порядков, выравнивание порядков, сложение мантисс, нормализация и т.п. Процессоры первых компьютеров выполняли все эти "микрооперации" для каждой пары аргументов последовательно одна за одной до тех пор, пока не доходили до окончательного результата, и лишь после этого переходили к обработке следующей пары слагаемых. Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций. Суперскалярность. Как и в предыдущем примере, только при построении конвейера используют несколько программно-аппаратных реализаций функциональных устройств, например два или три АЛУ, три или четыре устройства выборки. Hyper Threading. Перспективное направление развитие современных микропроцессоров, основанное на многонитевой архитектуре. Основное препятствие на пути повышения производительности за счет увеличения функциональных устройств – это организация эффективной загрузки этих устройств.Если сегодняшние программные коды не в состоянии загрузить работой все функциональные устройства, то можно разрешить процессору выполнять более чем одну задачу (нить), чтобы дополнительные нити загрузили – таки все ФИУ (очень похоже на многозадачность). Многоядерность. Можно, конечно, реализовать мультипроцессирование на уровне микросхем, т.е. разместить на одном кристалле несколько процессоров (Power 4). Но если взять микропроцессор вместе с памятью как ядра системы, то несколько таких ядер на одном кристалле создадут многоядерную структуру. При этом в кристалле интегрируются функции (например, интерфейсы сетевых и телекоммуникационных систем) для выполнения которых обычно используются наборы микросхем (процессоры Motorola MPC8260, Power 4). Реализация высокопроизводительной вычислительной техники в настоящее время идёт по четырем основным направлениям. 1. Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и набор векторных команд - это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел. Характерным представителем данного направления является семейство векторно-конвейерных   Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|

 (AGP)
(AGP)



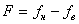 определяет диапазон частот
определяет диапазон частот 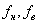 , где f н и f в – нижняя и верхняя граница частот, эффективно передаваемых по линии. Полоса частот зависит от типа линии и ее протяженности. Проводные линии связи имеют полосу частот примерно 10 кГц, кабельные – 102 кГц, коаксиальные – 102 МГц, радиорелейные – 103 МГц и волоконно-оптические – 102 МГц. Для передачи данных используется коротковолновая радиосвязь с диапазоном частот от 3 до 30 МГц. Удельная стоимость линии определяется затратами на создание линии протяженностью 1 км. Для передачи данных на небольшие расстояния используются в основном низкочастотные проводные линии, на большие расстояния – высокочастотные линии: коаксиальные кабели, волоконно-оптические и радиорелейные линии. Радиосвязь применяется для организации как местной, так и дальней связи. Помехоустойчивость линии зависит от мощности помех, создаваемых в линии внешней средой или возникающих из-за шумов в самой линии. Наименее помехоустойчивыми являются радиолинии, хорошей помехоустойчивостью обладают кабельные липни и отличной – волоконно-оптические линии, не восприимчивые к электромагнитному излучению.
, где f н и f в – нижняя и верхняя граница частот, эффективно передаваемых по линии. Полоса частот зависит от типа линии и ее протяженности. Проводные линии связи имеют полосу частот примерно 10 кГц, кабельные – 102 кГц, коаксиальные – 102 МГц, радиорелейные – 103 МГц и волоконно-оптические – 102 МГц. Для передачи данных используется коротковолновая радиосвязь с диапазоном частот от 3 до 30 МГц. Удельная стоимость линии определяется затратами на создание линии протяженностью 1 км. Для передачи данных на небольшие расстояния используются в основном низкочастотные проводные линии, на большие расстояния – высокочастотные линии: коаксиальные кабели, волоконно-оптические и радиорелейные линии. Радиосвязь применяется для организации как местной, так и дальней связи. Помехоустойчивость линии зависит от мощности помех, создаваемых в линии внешней средой или возникающих из-за шумов в самой линии. Наименее помехоустойчивыми являются радиолинии, хорошей помехоустойчивостью обладают кабельные липни и отличной – волоконно-оптические линии, не восприимчивые к электромагнитному излучению.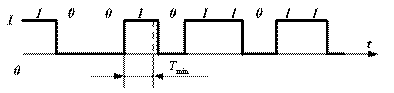
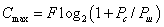 (4.1)
(4.1) бита информации.
бита информации. . Если вероятность искажения символов 0 и 1 из-за помех одинакова и равна р, то число двоичных символов, которые можно безошибочно передать по каналу в секунду,
. Если вероятность искажения символов 0 и 1 из-за помех одинакова и равна р, то число двоичных символов, которые можно безошибочно передать по каналу в секунду,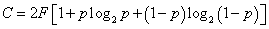 (4.2)
(4.2)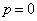 и пропускная способность
и пропускная способность 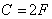 ; если вероятность искажения р =0,5, то пропускная способность С =0. Если по каналу передается сообщение длиной n двоичных символом, то вероятность появления в нем точно l ошибок
; если вероятность искажения р =0,5, то пропускная способность С =0. Если по каналу передается сообщение длиной n двоичных символом, то вероятность появления в нем точно l ошибок 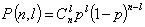 , среднее число ошибок
, среднее число ошибок 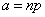 и среднее квадратическое отклонение
и среднее квадратическое отклонение 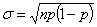 .
.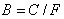 , т. е. пропускной способностью на 1 Гц полосы частот канала. Для коммутируемых телефонных каналов удельная пропускная способность не превышает 0,4 бит/(с × Гц), а для некоммутируемых составляет, как правило. 3–5 бит/(с × Гц).
, т. е. пропускной способностью на 1 Гц полосы частот канала. Для коммутируемых телефонных каналов удельная пропускная способность не превышает 0,4 бит/(с × Гц), а для некоммутируемых составляет, как правило. 3–5 бит/(с × Гц).