|
|
Увеличение производительности ЭВМ, за счет чего?Стр 1 из 6Следующая ⇒ Увеличение производительности ЭВМ, за счет чего? А почему суперкомпьютеры считают так быстро? Вариантов ответа может быть несколько, среди которых два имеют явное преимущество: развитие элементной базы и использование новых решений в архитектуре компьютеров. Попробуем разобраться, какой из этих факторов оказывается решающим для достижения рекордной производительности. Обратимся к известным историческим фактам. На одном из первых компьютеров мира - EDSAC, появившемся в 1949 году в Кембридже и имевшем время такта 2 микросекунды (2*10-6 секунды), можно было выполнить 2*n арифметических операций за 18*n миллисекунд, то есть в среднем 100 арифметических операций в секунду. Сравним с одним вычислительным узлом современного суперкомпьютера Hewlett-Packard V2600: время такта приблизительно 1.8 наносекунды (1.8*10-9 секунд), а пиковая производительность около 77 миллиардов арифметических операций в секунду. Что же получается? Более чем за полвека производительность компьютеров выросла почти в 800миллионовраз. При этом выигрыш в быстродействии, связанный с уменьшением времени такта с 2 микросекунд до 1.8 наносекунд, составляет лишь около 1000 раз. Откуда же взялось остальное? Ответ очевиден - использование новых решений в архитектуре компьютеров. Основное место среди них занимает принцип параллельной обработки команд и данных, воплощающий идею одновременного (параллельного) выполнения нескольких действий.
Параллельные системы Итак, пути повышения производительности ВС заложены в ее архитектуре. С одной стороны это совокупность процессоров, блоков памяти, устройств ввода/вывода ну и конечно способов их соединения, т.е. коммуникационной среды. С другой стороны, это собственно действия ВС по решению некоторой задачи, а это операции над командами и данными. Вот собственно и вся основная база для проведения параллельной обработки. Параллельная обработка, воплощая идею одновременного выполнения нескольких действий, имеет несколько разновидностей: суперскалярность, конвейеризация, SIMD – расширения, Hyper Threading, многоядерность. В основном эти виды параллельной обработки интуитивно понятны, поэтому сделаем лишь небольшие пояснения. Если некое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть, пять таких же независимых устройств, способных работать одновременно, то ту же тысячу операций система из пяти устройств может выполнить уже не за тысячу, а за двести единиц времени. Аналогично система из N устройств ту же работу выполнит за 1000/N единиц времени. Подобные аналогии можно найти и в жизни: если один солдат вскопает огород за 10 часов, то рота солдат из пятидесяти человек с такими же способностями, работая одновременно, справятся с той же работой за 12 минут (параллельная обработка данных), да еще и с песнями (параллельная обработка команд). Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в форме с плавающей запятой? Целое множество мелких операций таких, как сравнение порядков, выравнивание порядков, сложение мантисс, нормализация и т.п. Процессоры первых компьютеров выполняли все эти "микрооперации" для каждой пары аргументов последовательно одна за одной до тех пор, пока не доходили до окончательного результата, и лишь после этого переходили к обработке следующей пары слагаемых. Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций. Суперскалярность. Как и в предыдущем примере, только при построении конвейера используют несколько программно-аппаратных реализаций функциональных устройств, например два или три АЛУ, три или четыре устройства выборки. Hyper Threading. Перспективное направление развитие современных микропроцессоров, основанное на многонитевой архитектуре. Основное препятствие на пути повышения производительности за счет увеличения функциональных устройств – это организация эффективной загрузки этих устройств.Если сегодняшние программные коды не в состоянии загрузить работой все функциональные устройства, то можно разрешить процессору выполнять более чем одну задачу (нить), чтобы дополнительные нити загрузили – таки все ФИУ (очень похоже на многозадачность). Многоядерность. Можно, конечно, реализовать мультипроцессирование на уровне микросхем, т.е. разместить на одном кристалле несколько процессоров (Power 4). Но если взять микропроцессор вместе с памятью как ядра системы, то несколько таких ядер на одном кристалле создадут многоядерную структуру. При этом в кристалле интегрируются функции (например, интерфейсы сетевых и телекоммуникационных систем) для выполнения которых обычно используются наборы микросхем (процессоры Motorola MPC8260, Power 4). По каким же направлениям идет реализация высокопроизводительной вычислительной техники в настоящее время? Основных направлений четыре. 1. Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и набор векторных команд - это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел. Характерным представителем данного направления является семейство векторно-конвейерных компьютеров CRAY куда входят, например, CRAY EL, CRAY J90, CRAY T90 (в марте 2000 года американская компания TERA перекупила подразделение CRAY у компании Silicon Graphics, Inc.). 2. Массивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды - вот и все. Достоинств у такой архитектуры масса: если нужна высокая производительность, то можно добавить еще процессоров, если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.п. Однако есть и решающий "минус", сводящий многие "плюсы" на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто невозможно. К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, в какой-то степени IBM SP2 и CRAY T3D/T3E, хотя в этих компьютерах влияние указанного минуса значительно ослаблено. К этому же классу можно отнести и сети компьютеров, которые все чаще рассматривают как дешевую альтернативу крайне дорогим суперкомпьютерам. 3. Параллельные компьютеры с общей памятью. Вся оперативная память таких компьютеров разделяется несколькими одинаковыми процессорами. Это снимает проблемы предыдущего класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, по чисто техническим причинам нельзя сделать большим. В данное направление входят многие современные многопроцессорные SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire. 4. Кластерные системы. Последнее направление, строго говоря, не является самостоятельным, а скорее представляет собой комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и общей для них памяти сформируем вычислительный узел. Если полученной вычислительной мощности не достаточно, то объединим несколько узлов высокоскоростными каналами. Подобную архитектуру называют кластерной, и по такому принципу построены CRAY SV1, HP Exemplar, Sun StarFire, NEC SX-5, последние модели IBM SP2 и другие. Именно это направление является в настоящее время наиболее перспективным для конструирования компьютеров с рекордными показателями производительности.
Интерфейс Интерфейс - это совокупность программных и аппаратных средств, предназначенных для передачи информации между компонентами ЭВМ и включающих в себя электронные схемы, линии, шины и сигналы адресов, данных и управления, алгоритмы передачи сигналов и правила интерпретации сигналов устройствами. Интерфейсы характеризуются следующими параметрами:
К динамическим параметрам интерфейса относится время передачи отдельного слова и блока данных с учетом продолжительности процедур подготовки и завершения передачи. Разработка систем ввода-вывода требует решения целого ряда проблем, среди которых выделим следующие:
Организация передачи данных В ЭВМ используются два основных способа организации передачи данных между памятью и периферийными устройствами: программно-управляемая передача и прямой доступ к памяти (ПДП). Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора. Например, при пересылке блока данных из периферийного устройства в оперативную память процессор должен выполнить следующую последовательность шагов:
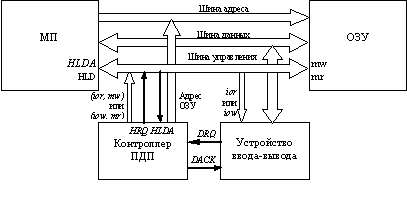
Как видно, программно-управляемый обмен ведет к нерациональному использованию мощности микропроцессора, который вынужден выполнять большое количество относительно простых операций, приостанавливая работу над основной программой. При этом действия, связанные с обращением к оперативной памяти и к периферийному устройству, обычно требуют удлиненного цикла работы микропроцессора из-за их более медленной по сравнению с микропроцессором работы, что приводит к еще более существенным потерям производительности ЭВМ. Альтернативой программно-управляемому обмену служит прямой доступ к памяти - способ быстродействующего подключения внешнего устройства, при котором оно обращается к оперативной памяти, не прерывая работы процессора. Такой обмен происходит под управлением отдельного устройства - контроллера прямого доступа к памяти (КПДП). Структура ЭВМ, имеющей в своем составе КПДП, представлена на рис. 9.2
Перед началом работы контроллер ПДП необходимо инициализировать: занести начальный адрес области ОП, с которой производится обмен, и длину передаваемого массива данных. В дальнейшем по сигналу запроса прямого доступа контроллер фактически выполняет все те действия, которые обеспечивал микропроцессор при программно-управляемой передаче. Последовательность действий КПДП при запросе на прямой доступ к памяти со стороны устройства ввода-вывода следующая:
Прямой доступ к памяти позволяет осуществлять параллельно во времени выполнение процессором программы и обмен данными между периферийным устройством и оперативной памятью. Обычно программно-управляемый обмен используется в ЭВМ для операций ввода-вывода отдельных байт (слов), которые выполняются быстрее, чем при ПДП, так как исключаются потери времени на инициализацию контроллера ПДП, а в качестве основного способа осуществления операций ввода-вывода используют ПДП. Например, в стандартной конфигурации персональной ЭВМ обмен между накопителями на магнитных дисках и оперативной памятью происходит в режиме прямого доступа.
Буферизация и кэширование Под буфером обычно понимается некоторая область памяти для запоминания информации при обмене данных между двумя устройствами, двумя процессами или процессом и устройством. Обмен информацией между двумя процессами относится к области кооперации процессов, и мы подробно рассмотрели его организацию в соответствующей лекции. Здесь нас будет интересовать использование буферов в том случае, когда одним из участников обмена является внешнее устройство. Существует три причины, приводящие к использованию буферов в базовой подсистеме ввода-вывода.
Под словом кэш (cache – «наличные»), этимологию которого мы не будем здесь рассматривать, обычно понимают область быстрой памяти, содержащую копию данных, расположенных где-либо в более медленной памяти, предназначенную для ускорения работы вычислительной системы. Мы с вами сталкивались с этим понятием при рассмотрении иерархии памяти. В базовой подсистеме ввода-вывода не следует смешивать два понятия, буферизацию и кэширование, хотя зачастую для выполнения этих функций отводится одна и та же область памяти. Буфер часто содержит единственный набор данных, существующий в системе, в то время как кэш по определению содержит копию данных, существующих где-нибудь еще. Например, буфер, используемый базовой подсистемой для копирования данных из пользовательского пространства процесса при выводе на диск, может в свою очередь применяться как кэш для этих данных, если операции модификации и повторного чтения данного блока выполняются достаточно часто. Функции буферизации и кэширования не обязательно должны быть локализованы в базовой подсистеме ввода-вывода. Они могут быть частично реализованы в драйверах и даже в контроллерах устройств, скрытно по отношению к базовой подсистеме.
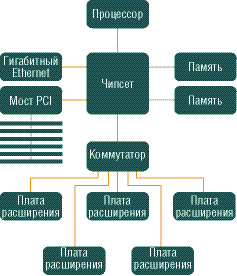
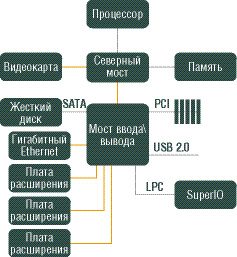
PCI Express По прогнозам, в ближайшие десять лет требования к пропускной способности шин ввода-вывода возрастут в 50 раз. Но традиционная архитектура параллельных шин типа PCI и AGP уже почти достигла предела своих возможностей (физический лимит для них - примерно 1 ГГц). Последовательный интерфейс PCI Express, имеющий много общего с сетевой организацией обмена данными, призван заменить шину PCI (и ее клон - AGP), исправно работающую в компьютерной технике уже более десяти лет. В то время как процессоры уже не первый год успешно движутся в направлении параллельных архитектур (SIMD-расширения, суперскалярность, конвейеризация, HyperTreading и многоядерность), шины передачи данных не менее успешно переходят на последовательные решения. Причины обеих тенденций схожи и довольно просты - необходимо сбалансированное наращивание производительности всех компонентов компьютеров, однако не всякие существующие архитектурные решения способны эффективно масштабироваться. PCI Express была разработана с расчетом на разнообразные применения - от полной замены шин PCI 2.2 или PCI-X в настольных компьютерах и серверах до использования в мобильных, встроенных и коммуникационных устройствах. Номинальной рабочей частотой шины PCI Express является 2,5 ГГц. Физическая реализация шины передачи данных - это две дифференциальные пары проводников с импедансом 50 Ом (первая пара работает на прием, вторая - на передачу), данные по которым передаются с использованием избыточного кодирования по схеме "8/10" с исправлением ошибок. Это позволяет исправлять многие простые ошибки, неизбежные на столь высоких частотах. Как и в любой сети, передаваемые данные дополнительно нарезаются небольшими кусочками - фреймами. При тактовой частоте шины 2,5 ГГц мы получим скорость 2,5 Гбит/с. С учетом выбранной схемы "8/10" выходит 250 Мбайт/с, однако многоуровневая сетевая иерархия не может не сказаться на скорости работы, и реальная производительность шины оказывается значительно ниже - всего лишь около 200 Мбайт/с в каждую сторону. Впрочем, даже это на 50% больше, чем теоретическая пропускная способность шины PCI. Но это далеко не предел: PCI Express позволяет объединять в шину нескольких независимых линий передачи данных. Стандартом предусмотрено использование 1, 2, 4, 8, 16 и 32 линий - передаваемые данные поровну распределяются между ними по схеме "первый байт на первую линию, второй - на вторую,..., n-й байт на n-ю линию, n+1-й снова на первую, n+2 снова на вторую" и так далее. Это не параллельная передача данных и даже не увеличение разрядности шины (поскольку все передающиеся по линиям данные передаются абсолютно независимо и асинхронно) - это именно объединение нескольких независимых линий. Причем передача по нескольким линиям никак не влияет на работу остальных слоев "пирамиды" и реализуется сугубо на "нижнем", физическом уровне. Именно этим достигается прекрасная масштабируемость PCI Express, позволяющая организовывать шины с максимальной пропускной способностью до 32x200=6,4 Гбайт/с в одном направлении, под стать лучшим параллельным шинам сегодняшнего дня. PCI Express относится к шинам класса "точка-точка", то есть одна шина может соединять только два устройства (в отличие от PCI, где на общую шину "вешались" все PCI-слоты компьютера), поэтому для организации подключения более чем одного устройства в топологию организуемой PCI Express, как и в Ethernet-решениях на базе витой пары или устройствах USB, придется вставлять хабы и свитчи, распределяющие сигнал по нескольким шинам. Это тоже одно из главных отличий PCI Express от прежних параллельных шин. Чипсет В настоящее время управление потоками передаваемых данных производится с помощью мостов и контроллеров, входящих в ChipSet. Именно ChipSet определяет основные особенности архитектуры компьютера и, соответственно, достигаемый уровень производительности в условиях, когда лимитирующим фактором становится не процессор, а его окружение – память и система ввода-вывода. В плане практической реализации шина PCI Express представляет собой целый аппаратный комплекс, затрагивающий северный и южный мосты чипсета, коммутатор и оконечные устройства. Новым термином здесь является коммутатор (switch), заменяющий одну шину со многими подключениями коммутируемой технологией.
Коммутатор обеспечивает одноранговую связь между различными оконечными устройствами, то есть снижает нагрузку на мост. Поддерживаются несколько виртуальных каналов на один физический. Примерные схемы внедрения PCI Express в настольный компьютер и сервер представлены на следующем рисунке.
В "десктопных" системах PCI Express 16x в первую очередь вытеснит AGP 8x в качестве "графической шины", соединяющей видеокарту и северный мост чипсета. Затем на PCI Express пересадят многие интегрированные устройства - гигабитный сетевой и RAID-контроллеры. К обычным PCI-слотам добавят PCI Express x1. В качестве межчипсетной шины (соединяющей мосты чипсета) PCI Express будет выступать вместе со старыми шинами (VIA VLink, SiS MuTIOL) - некоторые производители чипсетов пока не желают отказываться от своих проприетарных шин. №8. Основные характеристики канала связи Основные характеристики канала связи (рис. 5.2) – пропускная способность и достоверность передачи данных. Пропускная способность канала оценивается предельным числом бит данных, передаваемых по каналу за единицу времени, и измеряется в бит/с (с-1). Достоверность передачи данных характеризуется вероятностью искажения бита, которая для каналов связи без дополнительных средств защиты от ошибок составляет, как правило, 10-4 – 10-6. Основная причина искажений – воздействие помех на линию связи и, отчасти, наличие шумов в АПД. Помехи носят импульсный характер и имеют тенденцию к группированию – образованию пачек помех, искажающих сразу группу соседних бит в передаваемых данных. Линии связи. Для передачи данных используются линии связи различных типов: проводные (воздушные), кабельные, радиорелейные, волоконно-оптические и радиоканалы наземной и спутниковой связи. Кабельные линии состоят из скрученных пар проводов или коаксиальных кабелей. Основные характеристики линий связи – полоса частот, удельная стоимость и помехоустойчивость. Полоса частот
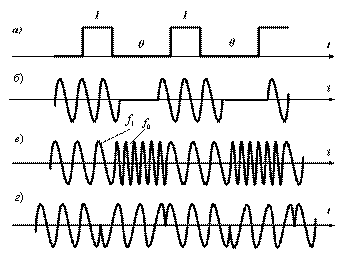
Рис. 5.4. Последовательность двоичных сигналов Пропускная способность канала. Пропускная способность канала зависит от полосычастот линии связи и отношения мощностей сигнала и шума. Максимальная пропускная способность канала, настроенного на основе линии с полосой частот F и отношением сигнал-шум Р с/ Р ш, составляет (бит в секунду) Значение (1+ Р с/ Рш) определяет число уровней сигнала, которое может быть воспринято приемником. Так, если отношение Р с/ Р ш>3, то единичный сигнал может переносить четыре значения, т. е. При передаче данных широко используются двоичные сигналы, принимающие значения 0 и 1. Временная диаграмма последовательности таких сигналов, передаваемых по линии связи, изображена на рис. 5.4, где сверху указаны значения, переносимые сигналом. Минимальная длительность такта, с которым могут передавался сигналы по каналу с полосой частот F, равна Это выражение определяет пропускную способность двоичного канала. Величина в квадратных скобках определяет долю двоичных символов, которые передаются по каналу с частотой 2 F без искажений. Если помехи отсутствуют, вероятность искажения символа Наиболее распространенный тип капала – телефонный с полосой пропускания 3,1 кГц и диапазоном частот от f Н =0,3 кГц до f Н = 3,4 кГц. Коммутируемый телефонный канал обеспечивает скорость передачи данных С=1200 бит/с, а некоммутируемый – до 9600 бит/с. Эффективность использования канала связи для передачи данных принято характеризовать удельной пропускной способностью Стандартизированы следующие скорости передачи данных по каналам связи: 200, 300, 600, 1200, 2400, 4800, 9600, 12000, 24000, 48000 и 96000 бит/с. Каналы с пропускной способностью до 300 бит/с называются низкоскоростными, от 600 до 4800 бит/с – среднескоростными и с большей пропускной способность – высокоскоростными.
Способы передачи данных. Для передачи данных по каналам с различными характеристиками используются разные способы, обещающие максимальное использование свойств каналов для повышения скорости и достоверности передачи данных при умеренной стоимости аппаратуры. Данные первоначально предоставляются последовательностью прямоугольных импульсов (рис. 5.4). Для их передачи без искажения требуется полоса частот от нуля до бесконечности. Реальные каналы имеют конечную полосу частот, с которой необходимо согласовать передаваемые сигналы. Согласование обеспечивается, во-первых, путем модуляции – переноса сигнала на заданную полосу частот и, во-вторых, путем кодирования – преобразовании данных в вид, позволяющий обнаруживать и исправлять ошибки, возникающие из-за помех в канале связи. При использовании высокочастотных проводных и кабельных линий, полоса частот которых начинается примерно от нуля, сигналы можно передавать в их естественном виде – без модуляции (в первичной полосе частот). Каналы, работающие без модуляции, называются телеграфными и обеспечивают передачу данных со скоростью, как правило, 50-200 бит/с.
Рис. 5.5. Канал с модуляцией
Когда канал имеет резко ограниченную полосу частот, как, например, радиоканал, передача сигналов должна выполняться в этой полосе и перенос сигнала в заданную полосу производится посредством модуляции по схеме, изображенной на рис. 5.5. В этом случае между оконечным оборудованием данных, работающим с двоичными сигналами, и каналом устанавливается modem – модулятор и демодулятор. Модулятор перемещает спектр первичного сигнала в окрестность несущей частоты f 0. Демодулятор выполняет над сигналом обратное преобразование, формируя из модулированного сигнала импульсный двоичный сигнал.
Рис. 5.6. Способы модуляции
Способы модуляции подразделяются на аналоговые и дискретные. К аналоговым относятся амплитудная, частотная и фазовая модуляция (рис. 5.6). При амплитудной (рис. 5.6, б) производится модуляция амплитуды несущей частоты первичным сигналом (рис. 5.6, а). При частотной модуляции (рис. 5.6, в) значения 0 и 1 двоичного сигнала передаются сигналами с различной частотой – f 0 и f 1. При фазовой модуляции (рис. 5.6, г) значениям сигнала 0 и 1 соответствуют сигналы частоты f 0 с разной фазой. Дискретные способы модуляции применяются для преобразования аналоговых сигналов, например речевых, в цифровые. Для этих целей наиболее широко используются амплитудно-импульсная, кодово-импульсная и времяимпульсная модуляция. Кодирование передаваемых данных производится в основном для повышения помехоустойчивости данных. Так, первичные коды символов могут быть представлены в помехозащищенной форме – с использованием кодов Хемминга, обеспечивающих обнаружение и исправление ошибок в передаваемых данных. В последнее время функция повышения достоверности передаваемых данных возлагается на оконечное оборудование данных и обеспечивается за счет введения информационной избыточности в передаваемые сообщения.
Аппаратура передачи данных. Основное назначение АПД – преобразование сигналов, поступающих с оконечного оборудования, для передачи их в полосе частот канала связи и обратное преобразование сигналов, поступающих из канала. При работе с телеграфным каналом, сигналы по которому передаются без модуляции (в первичной полосе частот), указанные функции реализуются устройством преобразования телеграфных сигналов, а при работе с телефонным и высокочастотным каналом – модемом. Основные элементы модулятора и демодулятора представлены на рис. 5.7. В рассматриваемом случае передача данных в канал производится синхронно с частотой, соответствующей скорости работы канала, например с частотой 1200 Гц. Сигналы синхронизации S Т формируются в модуляторе тактовым генератором ТГ. По каждому сигналу синхронизации S T в блок модуляции БМ вводится двоичный сигнал Т, представляющий собой бит данных. Несущая частота формируется генератором ГНЧ. Модулированный сигнал поступает на полосовой фильтр ПФ, ограничивающий полосу частот сигнала в соответствии с нижней и верхней границей полосы канала. Затем сигнал с заданной полосой частот передается по каналу в демодулятор, проходит через полосовой фильтр, выделяющий заданную полосу частот, и поступает в блок демодуляции. №31. Суперскалярная архитектура процессора. Процессоры, имеющие в своем составе более одного конвейера, называются суперскалярными. Смысл суперскалярной обработки - наличие в аппаратуре средств, позволяющих одновременно выполнять две и более скалярных операций, т.е. команд обработки пары чисел. В самом деле, суть этого метода довольно проста: имеется в виду дублирование устройств процессора. Так например, Pentium имеет два конвейера выполнения команд (Рис. 11.4). При этом существуют различные способы реализации суперскалярной обработки. Первый способ чаще всего применяется в RISC-процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша команд) несвязанных команд и параллельном запуске их на исполнение. Обычно процессор выполняет две несвязанные команды одновременно, как например, в процессорах DEC серии Alpha. Этот метод хорош тем, что он "прозрачен" для программиста - составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства. Второй способ реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует не связанные операции в пакеты, содержимое которых строго соответствует структуре процессора. Например, если процессо   ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  ЧТО ПРОИСХОДИТ ВО ВЗРОСЛОЙ ЖИЗНИ? Если вы все еще «неправильно» связаны с матерью, вы избегаете отделения и независимого взрослого существования...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
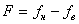 определяет диапазон частот
определяет диапазон частот  , где f н и f в – нижняя и верхняя граница частот, эффективно передаваемых по линии. Полоса частот зависит от типа линии и ее протяженности. Проводные линии связи имеют полосу частот примерно 10 кГц, кабельные – 102 кГц, коаксиальные – 102 МГц, радиорелейные – 103 МГц и волоконно-оптические – 102 МГц. Для передачи данных используется коротковолновая радиосвязь с диапазоном частот от 3 до 30 МГц. Удельная стоимость линии определяется затратами на создание линии протяженностью 1 км. Для передачи данных на небольшие расстояния используются в основном низкочастотные проводные линии, на большие расстояния – высокочастотные линии: коаксиальные кабели, волоконно-оптические и радиорелейные линии. Радиосвязь применяется для организации как местной, так и дальней связи. Помехоустойчивость линии зависит от мощности помех, создаваемых в линии внешней средой или возникающих из-за шумов в самой линии. Наименее помехоустойчивыми являются радиолинии, хорошей помехоустойчивостью обладают кабельные липни и отличной – волоконно-оптические линии, не восприимчивые к электромагнитному излучению.
, где f н и f в – нижняя и верхняя граница частот, эффективно передаваемых по линии. Полоса частот зависит от типа линии и ее протяженности. Проводные линии связи имеют полосу частот примерно 10 кГц, кабельные – 102 кГц, коаксиальные – 102 МГц, радиорелейные – 103 МГц и волоконно-оптические – 102 МГц. Для передачи данных используется коротковолновая радиосвязь с диапазоном частот от 3 до 30 МГц. Удельная стоимость линии определяется затратами на создание линии протяженностью 1 км. Для передачи данных на небольшие расстояния используются в основном низкочастотные проводные линии, на большие расстояния – высокочастотные линии: коаксиальные кабели, волоконно-оптические и радиорелейные линии. Радиосвязь применяется для организации как местной, так и дальней связи. Помехоустойчивость линии зависит от мощности помех, создаваемых в линии внешней средой или возникающих из-за шумов в самой линии. Наименее помехоустойчивыми являются радиолинии, хорошей помехоустойчивостью обладают кабельные липни и отличной – волоконно-оптические линии, не восприимчивые к электромагнитному излучению.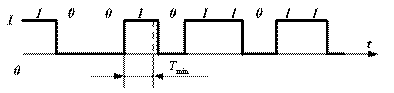
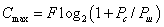 (4.1)
(4.1)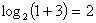 бита информации.
бита информации. . Если вероятность искажения символов 0 и 1 из-за помех одинакова и равна р, то число двоичных символов, которые можно безошибочно передать по каналу в секунду,
. Если вероятность искажения символов 0 и 1 из-за помех одинакова и равна р, то число двоичных символов, которые можно безошибочно передать по каналу в секунду,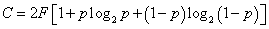 (4.2)
(4.2)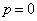 и пропускная способность
и пропускная способность 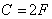 ; если вероятность искажения р =0,5, то пропускная способность С =0. Если по каналу передается сообщение длиной n двоичных символом, то вероятность появления в нем точно l ошибок
; если вероятность искажения р =0,5, то пропускная способность С =0. Если по каналу передается сообщение длиной n двоичных символом, то вероятность появления в нем точно l ошибок 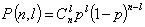 , среднее число ошибок
, среднее число ошибок 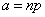 и среднее квадратическое отклонение
и среднее квадратическое отклонение 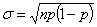 .
.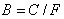 , т. е. пропускной способностью на 1 Гц полосы частот канала. Для коммутируемых телефонных каналов удельная пропускная способность не превышает 0,4 бит/(с × Гц), а для некоммутируемых составляет, как правило. 3–5 бит/(с × Гц).
, т. е. пропускной способностью на 1 Гц полосы частот канала. Для коммутируемых телефонных каналов удельная пропускная способность не превышает 0,4 бит/(с × Гц), а для некоммутируемых составляет, как правило. 3–5 бит/(с × Гц).