
|
|
II. Сущность и этапы корреляционно-регрессионного анализа (КРА). ⇐ ПредыдущаяСтр 4 из 4 Корреляционно-регрессионный анализ дает количественную оценку наличия и направления взаимосвязей, характеризует силу и форму влияния одних факторов на другие. Задачи регрессионного анализа: выявить наличие зависимости, установить форму связи и дать оценку абсолютной зависимости результата от фактора. Они решаются с помощью обработки массового потока информации и определения коэффициентов: регрессии и эластичности. Задача корреляционного анализа: измерить тесноту связи между признаками. Решается с помощью определения коэффициентов: корреляции и детерминации. Этапы корреляционно-регрессионного анализа. 1. Постановка задачи и предварительное установление причинно-следственных связей. 2. Отбор наиболее существенных признаков и сбор фактического материала. 3. Выбор показателей для оценки взаимосвязей и установление формы связи. а) С помощью группировки данных определяется, какие показатели брать для расчета характеристик взаимосвязи. б) С помощью построения графика зависимости определяется форма связи. 4. Расчет числовых характеристик и их экономический анализ. А) Однофакторный корреляционно-регрессионный анализ (на примере парной корреляции линейной регрессии). Для выявления связи между признаками строится аналитическая таблица или корреляционная матрица:
fij – количество сочетаний значений х и у (частоты). Если fij расположены в таблице беспорядочно, то связь между признаками отсутствует. Если образуется какое-либо характерное сочетание fij – связь имеет место. Пример: Если частоты в таблице концентрируются около одной из двух диагоналей – связь линейная. Наглядным изображением корреляционной зависимости служит корреляционное поле (график), где на оси х откладываются значения факторного признака, оси у – результативного. По расположению и концентрации точек судят о наличии и форме связи. у у
…................. ….......... ….. ………………….. ….. ……………. … ………………………
а) линейная связь б) связь отсутствует В случае парной линейной зависимости строится регрессионная модель: ух = а ± bх, где (1) ± – характеризует направление связи ((–) – обратную, (+) – прямую); ух – значение признака результата; х – значение признака фактора; а – свободный член уравнения; b – коэффициент регрессии. Коэффициент регрессии характеризует меру абсолютной зависимости результативного признака от факторного. Он имеет те же единицы измерения, что и признак результат и показывает, как изменяется признак результат при изменении факторного признака на единицу.
Параметры уравнения регрессии (а и b) находятся методом наименьших квадратов на основе решения системы уравнений (линейного):
Σху = а х Σх + b х Σх2 Относительную характеристику регрессионной зависимости дает коэффициент эластичности:
х̅ ̅ – среднее значение факторного признака; у̅ ̅ – среднее значение результативного признака. Этот показатель характеризует среднее изменение результативного признака (в %) при изменении факторного на 1%. Количественная оценка тесноты связи производится с помощью коэффициента парной корреляции (в нашем случае линейной):
δх – среднее квадратическое отклонение факторного признака; δу – среднее квадратическое отклонение результативного признака;
Коэффициент корреляции принимает значения от –1 до 1. Если rух = 0 – линейная связь отсутствует; если | rух | = 1 – связь полная (функциональная); если | rух | < 0,3 – связь слабая; если | rух | – 0,3 … 0,7 – связь средняя; если | rух | – 0,7 … 0,99 – связь сильная или тесная. Для анализа относительной величины связи определяется коэффициент детерминации: D = r2 х 100% (4) Он показывает, сколько % вариации результативного признака обусловлено влиянием факторного. Определение параметров корреляционно-регрессионной зависимости предполагает оценку надежности (значимости) коэффициента корреляции. С этой целью определяют: 1) t-критерий (критерий Стьюдента):
(n – 2) – число степеней свободы при заданном уровне значимости α и объёме выборки n. 2) Фактическое значение t-кр сравнивается с табличным (для α = 0,1; 0,01 или 0,05). Если фактическое значение t-кр превосходит табличное, то коэффициент корреляции значим (связь реальна). Б) Множественный корреляционно-регрессионный анализ (на примере линейной регрессии). При проведении этого анализа определяется перечень независимых переменных (факторных признаков), включаемых в уравнение регрессии. Далее производится отбор наиболее значимых переменных и решается вопрос о форме уравнения (форме связи). Уравнение линейной множественной регрессии: ух = а ± b1х1 ± b2х2 ± … ± bnхn, где (6) ух – значение признака результата, обусловленное влиянием нескольких признаков факторов; х1, х2,…, хn – значения факторных признаков; b1, b2, …, bn – коэффициенты регрессии, каждый из которых показывает на сколько единиц изменится результативный признак в связи с изменением соответствующего факторного признака на единицу при условии постоянства остальных значений х. Для множественной регрессии определяются частные коэффициенты эластичности:
bi – коэффициент регрессии при соответствующем факторном признаке. Этот коэффициент характеризует, на сколько процентов изменится результативный признак при изменении факторного на 1% при фиксированном значении остальных факторов. Для оценки тесноты связи между результативным и факторными признаками определяют коэффициент множественной корреляции (в нашем случае линейный):
δ2ост – остаточная дисперсия, характеризующая вариацию результативного признака за счет факторов, не включенных в уравнение множественной регрессии; σ2 – общая дисперсия фактических данных результативного признака; δ2 – дисперсия теоретических значений результативного признака, рассчитанная по уравнению множественной регрессии. Этот коэффициент изменяется от – 1 до 1 и имеет туже интерпретацию, что и парный коэффициент регрессии. Чем он ближе к 1, тем связь более существенна. Для анализа тесноты связи между факторным и результативным признаками при фиксированном значении других факторных признаков определяются частные коэффициенты корреляции. Пример: Частный коэффициент корреляции между признаками х1 и у, при исключении влияния признака х2 определяется:
r – парные коэффициенты корреляции между соответствующими признаками, определённые по формуле парного линейного коэффициента корреляции (формула 3). Для характеристики тесноты связи между одним факторным и результативным признаком определяют парные коэффициенты корреляции (как при однофакторном). Они сводятся в корреляционную матрицу:
Если парный коэффициент корреляции между факторными признаками больше 0,8, то взаимосвязь между ними мультиколлинеарна. Для получения адекватной модели регрессии необходимо устранить мультиколлениарность, т.е. исключить из неё факторные признаки, имеющие между собой тесную взаимосвязь. Для определения факторов, в развитии которых заложены наиболее крупные резервы увеличения результативного признака определяют β-коэффициенты.
Где
β-коэффициент показывает какой фактор оказывает наибольшее влияние на результативный признак. Для определения доли влияния анализируемого фактора от суммарного влияния всех факторов на результат определяют ∆-коэффициенты:
R2 – коэффициент множественной детерминации. Множественный коэффициент детерминации: D = R2 х 100% (10) Он показывает, какая часть вариации результативного признака зависит от влияния включенных в модель факторных признаков. Для определения степени влияния одного факторного признака на результативный определяют частные коэффициенты детерминации (формула 4). Оценка значимости коэффициента множественной корреляции осуществляется на основе F-критерия (критерия Фишера). Фактическое значение Fкр определяется по формуле:
m – общее количество признаков (параметров уравнения); n – объем выборки. Фактическое значение Fкр сравнивается с табличным, которое находится с учетом заданного уровня значимости α (для α = 0,01 или 0,05) и числа степеней свободы k1 = m – 1 и k2 = n – m. Если фактическое значение больше фактического корреляция признаётся существенной.
III. Непараметрические методы оценки связей. Методы оценки тесноты связи подразделяются на параметрические и непараметрические. Параметрические методы основаны на использовании количественных характеристик признака: средних, дисперсии и других (корреляционный анализ). Непараметрические методы позволяют измерять связь между качественными признаками. Пример: а) зависимость между профессией и здоровьем; б) зависимость успеваемости студентов заочников от работы их по специальности. Непараметрические методы анализа. 1. При определении тесноты связи между двумя альтернативными признаками, представленными группами с противоположными характеристиками (хороший, плохой; успевающий, не успевающий и т.п.) определяются коэффициенты контингенции и ассоциации. Для их расчёта используется таблица «четырех полей»:
a, b, c, d – частоты сочетаний пар качественных признаков. 1) Коэффициент ассоциации.
2) Коэффициент контингенции.
Эти коэффициенты изменяются от – 1 до 1. Чем ближе их значение к 1, тем сильнее связаны между собой изучаемые признаки. Связь считается подтвержденной, если Ка ≥ 0,5, а Кк ≥ 0,3. 2. При определении тесноты связи между качественными признаками, состоящими из более двух групп определяются коэффициенты К. Пирсона и А.А. Чупрова. С этой целью строится таблица сопряжённости.
fух – частоты сочетания признаков х и у; nх – сумма частот строки; nу – сумма частот столбца; nух – сумма частот сочетаний х и у. 1) Коэффициент взаимной сопряженности К. Пирсона.
φ2 = Σ zi – 1, где zi – значение расчётного показателя, определённого по i-й строке.
nу1 nу2 nу3
nу1 nу2 nу3
nу1 nу2 nу3 2) Коэффициент взаимной сопряженности Чупрова.
k1 – число групп по строкам; k2 – число групп по колонкам. Эти коэффициенты изменяются от 0 до 1. Чем они ближе к 1, тем связь теснее. 3. Метод ранговых оценок. Заключается в ранжировании (упорядочении) объектов изучения в порядке возрастания или убывания их количественных или качественных характеристик. При этом каждому значению признака х и у присваивается соответствующий ранг. Ранг – это порядковый номер значения ранжированного признака. По упорядоченным данным определяются показатели тесноты связи: 1) Коэффициент корреляции рангов Спирмена (английский экономист).
di2 – квадрат разности рангов значения х – Rх и значения у – Rу; n – число наблюдений (число пар рангов). Этот коэффициент принимает значения от 0 до ± 1. Чем он ближе к 1, тем выше связь. 2) Коэффициент корреляции рангов Кендалла.
n – число пар значений признаков х и у; S – сумма разностей между числом последовательностей (Р) и числом инверсий (Q) по признаку У. Расчет коэффициента выполняется в следующей последовательности: 1. Значения Х ранжируются в порядке возрастания или убывания их количественных или качественных характеристик. 2. Значения У располагаются в порядке соответствия значениям Х и ранжируются. 3. Для каждого ранга У определяется число следующих за ним рангов, превышающих его величину. Эти числа суммируются, определяя значение Р. 4. Для каждого ранга У определяется число следующих за ним рангов, меньше его величины. Суммируя эти числа, получаем значение Q.
4. Множественный коэффициент ранговой корреляции – коэффициент Конкордации. Рассчитывается для определения тесноты связи между произвольным числом ранжированных признаков.
m – число анализируемых признаков; n – число наблюдений; S – отклонение суммы квадратов рангов от средней квадратов рангов:
Ri – ранг i-го значения признака.
Литература: 1. Теория статистики /Под ред. Проф. Р.А. Шмойловой /2-е изд. –М.: Финансы и статистика, 2001 2. Практикум по теории статистики. /Под ред.проф. Р.А.Шмойловой М.: Финансы и статистика, 2001 3. Громыко Г.Л. Теория статистики: практикум – СМ.:ИНФРА, 2001 4. Елисеева И.И. Козбашев М.М. Общая теория статистики. – М.: Финансы и статистика, 1998 5. Общая теория статистики. /Под ред. Спирина А.А., Башиной О.Э. –М.: Финансы и статистика, 1995Теория статистики /Под ред. Г.Л. Громыко/ – М.:ИНФРА-М, 2000.
Контрольные вопросы.
1. Статистика как наука. История статистики, ее задачи в условиях рыночной экономики. Органы государственной статистики РФ. 2. Предмет статистической науки. Основные категории статистики. 3. Метод статистики. Основные стадии экономико-статистического исследования. 4. Статистическое наблюдение и этапы его проведения. Требования к статистическому наблюдению. 5. Формы, виды и способы статистического наблюдения. 6. Сводка статистических данных. Систематизация информации: классификации, группировки, номенклатуры. 7. Метод группировки статистических данных. Виды группировок. 8. Правила образования групп и интервалов в группах при построении группировки по количественному признаку. 9. Ряды распределения и их характеристики. 10. Понятие абсолютной величины. Виды абсолютных величин, единицы измерения. 11. Понятие относительной величины. Виды относительных величин, формы выражения. 12. Средние величины. Общие принципы их применения. Группы средних величин. 13. Степенные средние, область применения в статистике. Порядок выбора формы средней величины. 14. Структурные средние. Виды, методика расчета, область применения в статистике. 15. Показатели вариации. 16. Ряды динамики, их классификация. Правила построения. 17. Показатели динамического ряда. 18. Методы определения основной тенденции динамики. Определение основной тенденции динамики методом аналитического выравнивания. 19. Понятие структуры и основные направления ее исследования. Частные и обобщающие показатели структурных сдвигов. 20. Показатели концентрации и централизации. 21. Индексы: понятие, классификация, применение в статистике. 22. Индексный метод анализа (мультипликативная двухфакторная индексная модель). 23. Индексный анализ средних значений. 24. Понятие о статистических взаимосвязях, их виды. 25. Корреляционно-регрессионный анализ и его задачи. Однофакторный корреляционно-регрессионный анализ. 26. Многофакторный корреляционно-регрессионный анализ. 27. Непараметрические методы исследования взаимосвязей. Коэффициенты корреляции рангов. 28. Выборочное наблюдение в статистике и этапы его проведения. Основные характеристики выборочного наблюдения. 29. Способы формирования выборочной совокупности. 30. Ошибки выборочного наблюдения.
  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|


 …. х ……............. х
…. х ……............. х Σ у = аn + b х Σх
Σ у = аn + b х Σх , где (2)
, где (2) , где (3)
, где (3) – среднее значение произведения факторного и результативного признака.
– среднее значение произведения факторного и результативного признака. , где (5)
, где (5)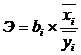 , где (7)
, где (7) – среднее значение соответствующего факторного признака;
– среднее значение соответствующего факторного признака; , где (8)
, где (8) , где (9)
, где (9)

 ,
, - среднее квадратическое отклонение i-го факторного признака;
- среднее квадратическое отклонение i-го факторного признака; - коэффициент регрессии i-го факторного признака.
- коэффициент регрессии i-го факторного признака. ,
, - показатель силы влияния соответствующего фактора на результат;
- показатель силы влияния соответствующего фактора на результат; - парный коэффициент корреляции i-го факторного признака;
- парный коэффициент корреляции i-го факторного признака; , где (11)
, где (11) (12)
(12) (13)
(13)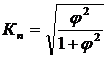 , где (14)
, где (14) (f1ух)2 (f2ух)2 (f3ух)2
(f1ух)2 (f2ух)2 (f3ух)2

 z1 = + +: nх1;
z1 = + +: nх1; , где (15)
, где (15) , где (16)
, где (16) , где (17)
, где (17) , где (18)
, где (18) , где (19)
, где (19)