|
|
Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной —UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты. Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования. Для индивидуальных пользователей это еще больше добавило забот по согласованию документов, выполненных в разных системах кодирования, с программными средствами, но это надо понимать как трудности переходного периода. Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста. Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF. В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом). Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит. В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр: Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста. Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16). Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт. На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode. Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
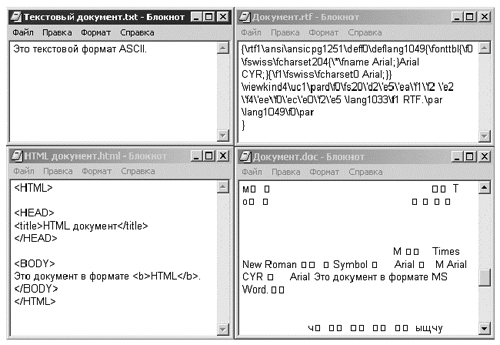
Итак, мы выяснили, каким образом кодируются символы. Нетрудно понять, что описанный способ не позволяет указать размер символа, шрифт и прочие особенности его начертания — для этого требуется дополнительная информация. Правила кодирования приемов оформления текста существенным образом зависят от выбранного формата файла. Покажем это на примере некоторых наиболее распространенных типов файлов (см. также рис. 1).
Рис. 1
1. Простейшие текстовые документы в формате ASCII. В них сохраняется только текст, поэтому никакие элементы оформления невозможны. Достоинством является компактность и универсальность, благодаря которым формат по-прежнему продолжает использоваться (техническая информация, электронная почта). 2. Документы в формате Unicode. По сравнению с предыдущим, формат позволяет одновременно использовать не два, а произвольное количество языков. Объем файла удваивается. На рис. 1 не приведен, поскольку при отображении по виду не отличается от документа ASCII. 3. HTML-документы, или, как их часто не совсем точно называют в обиходе, web-страницы. Для организации редактирования содержат специальную управляющую разметку, заключенную в угловые скобки (проще говоря, знаки “<” и “>”) и записанную в текстовом виде. Благодаря разметке программное обеспечение получает возможность отобразить текст в соответствующем оформлении (например, слово “HTML” из текста на рис. 1 будет напечатано жирным шрифтом). 4. Документы в формате RTF (Rich Text Format). По принципу хранения во многом схожи с предыдущим форматом, только для выделения разметки используются другие знаки. Обратите внимание на интересную деталь: русские буквы сохраняются в виде шестнадцатеричных кодов (приведенная на рис. 2 последовательность d2 e5 ea f1 f2 образует русское слово “Текст”; полная исходная строка — “Текст в формате RTF”, причем пробелы и латинское ее окончание не преобразуются). 5. Документы MS Word. Фактически не являются в полном смысле слова текстовыми файлами, поскольку сведения о разметке и прочую служебную информацию хранят не в текстовом, а в бинарном виде. На рис. 1 отчетливо видно, что, помимо собственно текста “Это документ в формате MS Word”, имеются нетекстовые фрагменты (пустое место, “квадратики”, отображающие неспособность ПО преобразовывать коды в символы текста и, наконец, бессмысленные сочетания букв типа “ыщчу”). Внимательное рассмотрение вертикальной полосы прокрутки показывает, что файл самый большой из всех и собственно текст его единственного предложения является очень незначительной частью информации. Таким образом, оказывается, что существует два аспекта представления текстовой информации — кодирование собственно символов и информации об оформлении текста; первая задача имеет более универсальное решение, вторая же, напротив, сильно зависит от программного обеспечения, которое работает с текстом.
  Что вызывает тренды на фондовых и товарных рынках Объяснение теории грузового поезда Первые 17 лет моих рыночных исследований сводились к попыткам вычислить, когда этот...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|