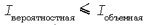|
|
Алфавитный (объемный) подход к измерению информацииПомимо описанного выше вероятностного подхода к измерению информации, состоящего в подсчете неопределенности исходов того или иного события, существует и другой. Его часто называют объемным, и он заключается в определении количества информации в каждом из знаков дискретного сообщения с последующим подсчетом количества этих знаков в сообщении. Пусть сообщение кодируется с помощью некоторого набора знаков. Заметим, что если для данного набора установлен порядок следования знаков, то он называется алфавитом. Наиболее сложной частью работы при объемном измерении информации является определение количества информации, содержащейся в каждом отдельном символе: остальная часть процедуры весьма проста. Для определения информации в одном символе алфавита можно также использовать вероятностные методы, поскольку появление конкретного знака в конкретном месте текста есть явление случайное. Самый простой метод подсчета заключается в следующем. Пусть алфавит, с помощью которого записываются все сообщения, состоит из M символов. Для простоты предположим, что все они появляются в тексте с одинаковой вероятностью (конечно, это грубая модель3, но зато очень простая). Тогда в рассматриваемой постановке применима формула Хартли для вычисления информации об одном из исходов события (о появлении любого символа алфавита): I = log2 M Поскольку все символы “равноправны”, естественно, что объем информации в каждом из них одинаков. Следовательно, остается полученное значение I умножить на количество символов в сообщении, и мы получим общий объем информации в нем. Напомним читателям, что осмысленность сообщения в описанной процедуре нигде не требуется, напротив, именно при отсутствии смысла предположение о равновероятном появлении всех символов выполняется лучше всего! Можно показать, что при любом варианте кодирования
(чем экономичнее способ кодирования, тем меньше разница между этими величинами — см. пример 4, приведенный ниже). Пример 3. Определить информацию, которую несет в себе 1-й символ в кодировках ASCII и Unicode. В алфавите ASCII предусмотрено 256 различных символов, т.е. M = 256, а I = log2 256 = 8 бит = 1 байт В современной кодировке Unicode заложено гораздо большее количество символов. В ней определено 256 алфавитных страниц по 256 символов в каждой. Предполагая для простоты, что все символы используются, получим, что I = log2 (256 * 256) = 8 + 8 = 16 бит = 2 байта
Пример 4. Текст, сохраненный в коде ASCII, состоит исключительно из арифметических примеров, которые записаны с помощью 10 цифр от 0 до 9, 4 знаков арифметических операций, знака равенства и некоторого служебного кода, разделяющего примеры между собой. Сравните количество информации, которое несет один символ такого текста, применяя вероятностный и алфавитный подходы.
Легко подсчитать, что всего рассматриваемый в задаче текст состоит из N = 16 различных символов. Следовательно, по формуле Хартли Iвероятностная = log2 16 = 4 бита В то же время, согласно вычислениям примера 3, для символа ASCII Iалфавитная = 8 бит Двукратный избыток при кодировании символов связан с тем, что далеко не все коды ASCII оказываются в нашем тексте востребованными. В то же время несложно построить вариант специализированной 4-битной кодировки для конкретной задачи4, для которого Iвероятностная и Iалфавитная окажутся равными. В порядке подведения итогов сравним вероятностный и алфавитный подходы. Первый подход позволяет вычислить предельное (минимально возможное) теоретическое значение количества информации, которое несет сообщение о данном исходе события. Второй — каково количество информации на практике с учетом конкретной выбранной кодировки. Очевидно, что первая величина есть однозначная характеристика рассматриваемого события, тогда как вторая зависит еще и от способа кодирования: в “идеальном” случае обе величины совпадают, однако на практике используемый метод кодирования может иметь ту или иную степень избыточности. С рассмотренной точки зрения вероятностный подход имеет преимущество. Но, с другой стороны, алфавитный способ заметно проще и с некоторых позиций (например, для подсчета требуемого количества памяти) полезнее. Бит, будучи минимально возможной порцией информации в компьютере, довольно маленькая единица измерения. Поэтому на практике чаще всего используется другая единица, которая называется 1 байт = 8 бит. С точки зрения устройства компьютера байт замечателен тем, что является минимальной адресуемой информацией в компьютере, иначе говоря, считать из памяти часть байта невозможно. В современных компьютерах все устройства памяти имеют байтовую структуру, а внешние устройства также обмениваются информацией байтами или кратными ему порциями. Как следствие все типы данных (числа, символы и др.) представляются в компьютере величинами, кратными байту. Примечание. Даже логические переменные, для каждой из которых, казалось бы, достаточно 1 бита, обычно занимают в оперативной памяти полный байт (или иногда ради единообразия даже несколько байт, например, LongBool в Паскале). С целью получения шкалы для измерения объемов информации в широких пределах от байта с помощью стандартных приставок образуется целая система более крупных производных единиц: 1 килобайт = 1024 байта 1 мегабайт = 1024 килобайта 1 гигабайт = 1024 мегабайта и т.д. В отличие от общепринятой системы производных единиц (широко используемой, например, в физике) при пересчете применяется множитель 1024, а не 1000. Причина заключается в двоичном характере представления информации в компьютере: 1024 = 210, и, следовательно, лучше подходит к измерению двоичной информации. Научившись измерять количество информации, можно ставить вопрос, как быстро она передается. Величину, которая равна количеству информации, передаваемому за единицу времени, принято называть скоростью передачи информации. Очевидно, что если за время t по каналу связи передано количество информации I, то скорость передачи вычисляется как отношение I / t. Скорость передачи данных нельзя сделать сколь угодно большой; ее предельная максимальная величина имеет специальное название — пропускная способность канала связи. Данная характеристика определяется устройством канала и, что не так очевидно, способом передачи сигналов по нему. Иными словами, для разных способов представления данных одна и та же линия связи может иметь разную пропускную способность. К.Шеннон в созданной им теории информации доказал, что достигнуть при передаче пропускной способности линии можно всегда и путем к этому является повышение эффективности кодирования. Более того, даже при наличии в канале шумов любого уровня всегда можно закодировать сообщение таким образом, чтобы не происходило потери информации. Обе величины — скорость передачи и пропускная способность — по определению измеряются в одних и тех же единицах, являющихся отношением единиц информации и времени: бит/с, байт/с, Кб/с и т.д.
  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  Что вызывает тренды на фондовых и товарных рынках Объяснение теории грузового поезда Первые 17 лет моих рыночных исследований сводились к попыткам вычислить, когда этот... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|