
|
|
Метод группового учета аргументов.Перед тем, как начинать рассмотрение МГУА, было бы полезно вспомнить или узнать впервые метод наименьших квадратов — наиболее распространенный метод подстройки линейно зависимых параметров. Рассмотрим для примера МНК для трех аргументов: Пусть функция T=T(U, V, W) задана таблицей, то есть из опыта известны числа Ui, Vi, Wi, Ti (i = 1, …, n). Будем искать зависимость между этими данными в виде:
где a, b, c — неизвестные параметры. Подберем значения этих параметров так, чтобы была наименьшей сумма квадратов уклонений опытных данных Ti и теоретических Ti = aUi + bVi + cWi, то есть сумма:
Величина s является функцией трех переменных a, b, c. Необходимым и достаточным условием существования минимума этой функции является равенство нулю частных производных функции s по всем переменным, то есть:
Так как:
то система для нахождения a, b, c будет иметь вид:
Данная система решается любым стандартным методом решения систем линейных уравнений (Гаусса, Жордана, Зейделя, Крамера). Рассмотрим некоторые практические примеры нахождения приближающих функций: y= ax2+bx+g Задача подбора коэффициентов a, b, g сводится к решению общей задачи при T=y, U=x2, V=x, W=1, a=a, b=b, c=g. f(x, y) = a*sin(x)+b*cos(y)+g /x Задача подбора коэффициентов a, b, g сводится к решению общей задачи при T=f, U=sin(x), V=cos(y), W=1/x, a =a, b =b, c=g. Если мы распространим МНК на случай с m параметрами,
то путем рассуждений, аналогичных приведенным выше, получим следующую систему линейных уравнений:
где Общая схема построения алгоритмов метода группового учета аргументов (МГУА).
Рис. Селекция самого черного тюльпана при расширяющемся опытном поле (эквивалент полного перебора), и при постоянном размере поля (эквивалент селекции при сохранении свободы выбора решений F = const). Заимствование алгоритмов переработки информации у природы является одной из основных идей кибернетики. "Гипотеза селекции" утверждает, что алгоритм массовой селекции растений или животных является оптимальным алгоритмом переработки информации в сложных задачах. Через несколько поколений селекция останавливается и ее результат является оптимальным. Если чрезмерно продолжать селекцию, то наступит "инцухт" — вырождение растений. Существует оптимальное число поколений и оптимальное количество семян, отбираемых в каждом из них. Алгоритмы МГУА воспроизводят схему массовой селекции, показанной на Рис. В них есть генераторы усложняющихся из ряда в ряд комбинаций и пороговые самоотборы лучших из них. Так называемое “полное” описание объекта j=f(x1,x2,x3,...,xm), где f — некоторая элементарная функция, например степенной полином, заменяется несколькими рядами "частных" описаний: 1-ряд селекции: y1=f(x1,x2), y2=f(x1,x3),..., ys=f(xm-1,xm), 2-ряд селекции: z1=f(y1,y2), z2=f(y1,y2),..., zp=f(ys-1,ys), где s=c2, p=cs2 и т.д. Входные аргументы и промежуточные переменные сопрягаются попарно, и сложность комбинаций на каждом ряду обработки информации возрастает (как при массовой селекции), пока не будет получена единственная модель оптимальной сложности. Каждое частное описание является функцией только двух аргументов. Поэтому его коэффициенты легко определить по данным обучающей последовательности при малом числе узлов интерполяции. Исключая промежуточные переменные (если это удается), можно получить "аналог" полного описания. Из ряда в ряд селекции пропускается только некоторое количество самых регулярных переменных. Степень регулярности оценивается по величине среднеквадратичной ошибки (средней для всех выбираемых в каждом поколении переменных или для одной самой точной переменой) на отдельной проверочной последовательности данных. Иногда в качестве показателя регулярности используется коэффициент корреляции. Ряды селекции наращиваются до тех пор, пока регулярность повышается. Как только достигнут минимум ошибки, селекцию, во избежание "инцухта", следует остановить. Практически рекомендуется остановить селекцию даже несколько раньше достижения полного минимума, как только ошибка начинает падать слишком медленно. Это приводит к более простым и более достоверным уравнениям. Алгоритм с ковариациями и с квадратичными описаниями.
В этом алгоритме используются частные описания, представленные в следующих формулах: yi=a0+a1xi+a2xj+a3xixj; yk=a0+a1xi+a2xj+a3xixj+a4xi2+a5xj2. Сложность модели увеличивается от ряда к ряду селекции как по числу учитываемых аргументов, так и по степени. Степень полного описания быстро растет. На первом ряду — квадратичные описания, на втором — четвертой степени, на третьем — восьмой и т. д. В связи с этим минимум критерия селекции находится быстро, но не совсем точно. Кроме того, имеется опасность потери существенного аргумента, особенно на первых рядах селекции (в случае отсутствия протекции). Специальные теоремы теории МГУА определяют условия, при которых результат селекции не отличается от результата полного перебора моделей. Для того чтобы степень полного уравнения повышалась с каждым рядом селекции на единицу, достаточно рассматривать все аргументы и их ковариации как обобщенные аргументы и пользоваться составленными для них линейными описаниями. Метод предельных упрощений. В МПУ предполагается, что разделяющая функция задается заранее в виде линейного (самого простого) полинома, а процесс обучения состоит в конструировании такого пространства минимальной размерности, в котором заранее заданная наиболее простая разделяющая функция безошибочно разделяет обучающую последовательность. МПУ назван так потому, что в нем строится самое простое решающее правило в пространстве небольшой размерности, т. е. в простом пространстве. Пусть на некотором множестве объектов V заданы два подмножества V*1 и V*2, определяющих собой образы на обучающей последовательности V. Рассмотрим i-е свойство объектов, такое, что некоторые объекты обучающей последовательности этим свойством обладают, а другие — нет. Пусть заданным свойством обладают объекты, образующие подмножество V1i, а объекты подмножества V2i этим свойством не обладают. Тогда i-е свойство называют признаком первого типа относительно образа V*1, если выполняются соотношения
и признаком второго типа, если выполняются
Если же выполняются соотношения
то i-е свойство считается признаком первого типа относительно образа V*2, а если выполняются
то это же свойство объявляется признаком второго типа относительно образа V*2. Если свойство не обладает ни одной из приведенных особенностей, то оно вообще не относится к признакам и не участвует в формировании пространства. Одинаковые признаки — это два признака xi и xj, порождающие подмножества V1j, V2j, V1i, V2i, такие, что V1j= V1i и V2j= V2i. (ф. 5) Доказано утверждение, смысл которого заключается в том, что если пространство конструировать из однотипных, но неодинаковых признаков, то в конце концов будет построено такое пространство, в котором обучающая последовательность будет безошибочно разделена на два образа линейным, т. е. самым простым, решающим правилом. Метод предельных упрощений состоит в том, что в процессе обучения последовательно проверяются всевозможные свойства объектов и из них выбираются только такие, которые обладают хотя бы одной из особенностей, определяемых соотношениями (ф. 1), (ф. 4). Такой отбор однотипных, но неодинаковых признаков продолжается до тех пор, пока при некотором значении размерности пространства не наступит безошибочное линейное разделение образов на обучающей последовательности. В зависимости от того, из признаков какого типа строится пространство, в качестве разделяющей плоскости выбирается плоскость, описываемая уравнением
либо уравнением
Каждый объект относится к одному из образов в зависимости от того, по какую сторону относительно плоскости находится соответствующий этому объекту вектор в пространстве признаков размерности n.
Коллективы решающих правил. Для рационального использования особенностей различных алгоритмов при решении задач распознавания возможно объединить различные по характеру алгоритмы распознавания в коллективы, формирующие классификационное решение на основе правил, принятых в теории коллективных решений. Пусть в некоторой ситуации Х принимается решение S. Тогда S=R(X), где R—алгоритм принятия решения в ситуации X. Предположим, что существует L различных алгоритмов решения задачи, т. е. Sl=Rl(X), l=1, 2,..., L, где Sl—решение, полученное алгоритмом Rl. Будем называть множество алгоритмов {R}={R1, R2,..., Ri.} коллективом алгоритмов решения задачи (коллективом решающих правил), если на множестве решений Sl в любой ситуации Х определено решающее правило F, т. е. S=F(S1, S2,..., SL, X). Алгоритмы Rl принято называть членами коллектива, Sl — решением l-го члена коллектива, а S — коллективным решением. Функция F определяет способ обобщения индивидуальных решений в решения коллектива S. Поэтому синтез функции F, или способ обобщения, является центральным моментом в организации коллектива. Принятие коллективного решения может быть использовано при решении различных задач. Так, в задаче управления под ситуацией понимается ситуация среды и целей управления, а под решением — самоуправление, приводящее объект в целевое состояние. В задачах прогноза Х — исходное, а S — прогнозируемое состояние. В задачах распознавания ситуацией Х является описание объекта X, т. е. его изображение, а решением S — номер образа, к которому принадлежит наблюдаемое изображение. Индивидуальное и коллективное решения в задаче распознавания состоят в отнесении некоторого изображения к одному из образов. Наиболее интересными коллективами распознающих алгоритмов являются такие, в которых существует зависимость веса каждого решающего правила Rl от распознаваемого изображения. Например, вес решающего правила Rl может определяеться соотношением
где Bl — область компетентности решающего правила Rl. Веса решающих правил выбираются так, что
для всех возможных значений X. Соотношение (ф. 1) означает, что решение коллектива определяется решением того решающего правила Ri, области компетентности которого принадлежит изображение объекта X. Такой подход представляет собой двухуровневую процедуру распознавания. На первом уровне определяется принадлежность изображения той или иной области компетентности, а уже на втором — вступает в силу решающее правило, компетентность которого максимальна в найденной области. Решение этого правила отождествляется с решением всего коллектива. Основным этапом в такой организации коллективного решения является обучение распознаванию областей компетентности. Практически постановкой этой задачи различаются правила организации решения коллектива. Области компетентности можно искать, используя вероятностные свойства правил коллектива, можно применить гипотезу компактности и считать, что одинаковым правилам должны соответствовать компактные области, которые можно выделить алгоритмами самообучения. В процессе обучения сначала выделяются компактные множества и соответствующие им области, а затем в каждой из этих областей восстанавливается свое решающее правило. В перцептроне каждый A-элемент может интерпретироваться как член коллектива. В процессе обучения все A-элементы приобретают веса, в соответствии с которыми эти A-элементы участвуют в коллективном решении. Особенность каждого A-элемента состоит в том, что он действует в некотором подпространстве исходного пространства, характер которого определяется связями между S- и A-элементами. Решение, получаемое на выходе перцептрона, можно интерпретировать как средневзвешенное решение коллектива, состоящего из всех A-элементов.   ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  ЧТО ПРОИСХОДИТ ВО ВЗРОСЛОЙ ЖИЗНИ? Если вы все еще «неправильно» связаны с матерью, вы избегаете отделения и независимого взрослого существования...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 (ф. 1)
(ф. 1) (ф. 2)
(ф. 2) (ф. 3)
(ф. 3)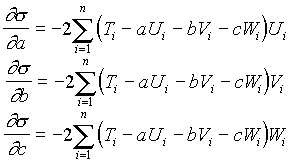 (ф. 4)
(ф. 4) (ф. 5)
(ф. 5) (ф. 6)
(ф. 6) (ф. 7)
(ф. 7)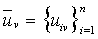 .
.
 и
и  (ф. 1)
(ф. 1) (ф. 2)
(ф. 2) и
и  (ф. 3)
(ф. 3) (ф. 4)
(ф. 4) (ф. 6)
(ф. 6) (ф. 7)
(ф. 7) (ф. 1)
(ф. 1)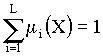 (ф. 2)
(ф. 2)