|
|
Алгоритмические методы сглаживания временного рядаСглаживание с помощью пакета "Анализ данных" (простая скользящая средняя). Окно сглаживания равно 5
Сглаживание с помощью пакета STATISTICA
Сглаженные значения совпадают с результатами применения пакета "Анализ данных", но привязываются к средней точке окна сглаживания.
Сглаживание скользящей средней с использованием аппроксимирующего полинома (m=2, p=2, окно сглаживания L=2m+1=5)
При данном методе структура сглаженного тренда в большей степени соответствует структуре исходного ряда и уменьшаются ошибки сглаживания по сравнения с использованием простой скользящей средней.
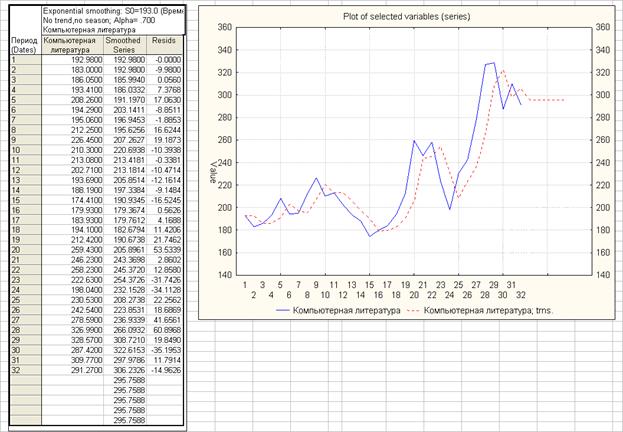
Метод экспоненциального сглаживания Сглаживание с использованием пакета "Анализ данных" ( = 0.3)
Сглаживание с использованием пакета "Анализ данных" ( = 0.3)
Если установлена опция No trend (тренд отсутствует), то выполняется простое экспоненциальное сглаживание. Если установлена опция Linear trend (линейный тренд), то применяется метод Брауна. Параметр = 1 - , где - фактор затухания, используемый в пакете "Анализ данных". Начальное сглаженное значение принимается равным начальному значению временного ряда.
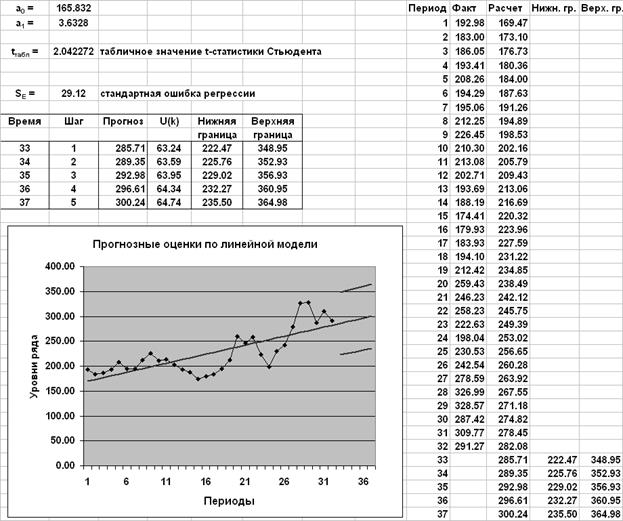
Сглаженные значения, полученные с использованием пакетов "Анализ данных" и STATISTICA, совпадают. При увеличении (уменьшении ) увеличивается значимость прошлых наблюдений, тренд становится более гладким. Адаптивный метод Брауна При краткосрочном прогнозировании наиболее важным является не тенденция развития исследуемого процесса, сложившаяся в среднем на всем периоде наблюдения, а его последние реализации. Свойство динамичности экономического процесса здесь преобладает над свойством его инерционности. Поэтому при краткосрочном прогнозировании может оказаться эффективным адаптивный метод Брауна, учитывающий неравноценность уровней временного ряда и обеспечивающий приспосабливаемость параметров модели к изменяющимся условиям. В модели Брауна расчетное значение уровня ряда в момент t вычисляется по формуле: Yр(t) = a0(t – 1) + a1(t – 1) * k, где k – количество шагов прогнозирования, используемое при построении модели (обычно k = 1). Расчетное значение сравнивается с фактическим уровнем ряда. Полученная ошибка прогноза (t) = Y(t) - Yр(t) используется для корректировки модели по формулам: a0(t) = a0(t – 1) + a1(t – 1) + (t) * (1 –l2), a1(t) = a1(t – 1) + (t) * (1 – l)2, где l – коэффициент дисконтирования данных, отражающий более высокую степень доверия к более поздним данным. Его значение должно быть в интервале от 0 до 1. Начальные оценки параметров модели можно получить по первым пяти точкам при помощи МНК. Результаты построения модели Брауна для ряда Компьютерная литература
Оценка начальных параметров модели МНК по первым пяти точкам
Результаты вычислений
При прогнозировании используется модель, построенная на последнем шаге y(32+k) = 292.93 - 6.59*k
Анализ остатков и прогноз а) Проверка гипотезы о равенстве нулю математического ожидания уровней ряда остатков Расчетное значение t-критерия определяется по формуле:
где ср - среднее значение уровней ряда остатков (по модулю); S - стандартная ошибка регрессии; N – число уровней ряда. Гипотеза о равенстве нулю математического ожидания ряда остатков отклоняется, если t > t табл при заданном уровне значимости a и числе степеней свободы N - 2.
б) Проверка гипотезы о случайности остатков Проверка случайности уровней ряда остатков проводится на основе критерия поворотных точек kп. В соответствии с ним каждый уровень ряда (кроме первого и последнего) сравнивается с двумя рядом стоящими. Если он больше или меньше их, то эта точка считается поворотной. В случайном ряду чисел должно выполняться неравенство:
в) Проверка независимости уровней ряда остатков При проверке независимости уровней ряда остатков (отсутствия автокорреляции) проверяется гипотеза об отсутствии в нем систематической составляющей с помощью d-критерия Дарбина – Уотсона. Его величина вычисляется по формуле:
Если значение d превышает 2, то оно заменяется на 4 – d. Вычисленная величина критерия сравнивается с двумя табличными уровнями: нижним d1 и верхним d2. Если d находится в интервале от нуля до d1, то уровни остатков сильно автокоррелированы и модель неадекватна. Если значение d попадает в интервал от d2 до 2, то уровни ряда являются независимыми. Если значение d находится в интервале от d1 до d2, то необходимо применить другой критерий - первый коэффициент автокорреляции r1. При выполнении условия | r1 | > rтабл присутствие в остаточном ряду существенной автокорреляции подтверждается.
г) Проверка гипотезы о нормальном распределении остатков Соответствие ряда остатков нормальному закону распределения определим при помощи критерия R/S = (max - min): S, где max – максимальный уровень остатка; min – минимальный уровень остатка; S – стандартное отклонение уровней ряда остатков. Если значение R/S–критерия попадает в интервал (2,7 ¸ 3,7), то для уровня значимости 0,05 свойство нормальности распределения ряда остатков подтверждается. При использовании пакета STATISTICA соответствие ряда остатков нормальному закону распределения может проверяться с помощью теста Колмогорова – Смирнова
Если вычисленная статистика D (расхождение между теоретическим и выборочным законами распределения) значима, то строка имеет красный цвет и гипотеза о том, что анализируемые данные имеют нормальный закон распределения, должна быть отвергнута. В данном случае с вероятностью более 20% отклонение выборочного закона распределения от нормального обусловлено случайными факторами. д) Средняя ошибка аппроксимации Для характеристики точности модели подсчитывается средняя ошибка аппроксимации. Если она менее 5%, точность модели считается высокой; если находится в интервале от 5% до 10% - хорошей; если находится в интервале от 10% до 15% - приемлемой; если более 15% - недостаточной.
Исходные данные и результаты расчетов
Анализ остатков для линейной модели: а) ср = 0, S = 29.12, t = 0. Гипотеза о равенстве нулю математического ожидания ряда остатков не отклоняется. б) Число поворотных точек kп = 12 < 15. Гипотеза о случайном характере ряда остатков не подтверждается. в) Расчетная величина критерия Дарбина-Уотсона d = 0,54. Гипотеза об отсутствии автокорреляции остатков отклоняется. г) Размах ряда остатков R/S = (max - min): S = 3.93 не попадает в интервал (2,7 ¸ 3,7), однако тест Колмогорова-Смирнова не опровергает гипотезу о нормальном распределении остатков. д) Средняя ошибка аппроксимации равна 10,58% (приемлемая точность модели).
Анализ остатков для экспоненциальной модели: а) ср = 1.70, S = 28.09, t = 0.34. Гипотеза о равенстве нулю математического ожидания ряда остатков не отклоняется. б) Число поворотных точек kп = 13 < 15. Гипотеза о случайном характере ряда остатков не подтверждается. в) Расчетная величина критерия Дарбина-Уотсона d = 0,57. Гипотеза об отсутствии автокорреляции остатков отклоняется. г) Размах ряда остатков R/S = (max - min): S = 4.04 не попадает в интервал (2,7 ¸ 3,7), однако тест Колмогорова-Смирнова не опровергает гипотезу о нормальном распределении остатков. д) Средняя ошибка аппроксимации равна 9.86% (хорошая точность модели).
Анализ остатков для модели Брауна: а) ср = 0.68, S = 24.99, t = 0.15. Гипотеза о равенстве нулю математического ожидания ряда остатков не отклоняется. б) Число поворотных точек kп = 20 > 15. Гипотеза о случайном характере ряда остатков подтверждается. в) Расчетная величина критерия Дарбина-Уотсона d = 1.97. Гипотеза об отсутствии автокорреляции остатков не отклоняется. г) Размах ряда остатков R/S = (max - min): S = 4.66 не попадает в интервал (2,7 ¸ 3,7), однако тест Колмогорова-Смирнова не опровергает гипотезу о нормальном распределении остатков. д) Средняя ошибка аппроксимации равна 7.81% (хорошая точность модели).
Анализ остатков для регрессионной модели: а) ср = 0, S = 31.45, t = 0. Гипотеза о равенстве нулю математического ожидания ряда остатков не отклоняется. б) Число поворотных точек kп = 12 < 15. Гипотеза о случайном характере ряда остатков не подтверждается. в) Расчетная величина критерия Дарбина-Уотсона d = 0.48. Гипотеза об отсутствии автокорреляции остатков отклоняется. г) Размах ряда остатков R/S = (max - min): S = 3.73 не попадает в интервал (2,7 ¸ 3,7), однако тест Колмогорова-Смирнова не опровергает гипотезу о нормальном распределении остатков. д) Средняя ошибка аппроксимации равна 11.44% (приемлемая точность модели).
Результаты анализа остатков для различных моделей:
Для линейной, экспоненциальной и регрессионной моделей не соблюдаются предпосылки МНК, они могут использоваться лишь для предварительного прогноза анализируемого показателя. Модель Брауна может применяться для краткосрочного прогноза динамики средней цены анализируемой литературы, если есть основания ориентироваться на последние наблюдения.
Прогноз по линейной модели Точечный прогноз на k шагов вперед получается путем подстановки в модель параметра t = N+1, …, N+k. Доверительный интервал прогноза: · верхняя граница равна Yр(N + k) + U(k), · нижняя граница равна Yр(N + k) – U(k). Величина U(k) вычисляется по формуле:
где S – стандартная ошибка регрессии; tтабл – табличное значение t-статистики Стьюдента.
Прогноз по экспоненциальной модели Прогноз по экспоненциальной модели вычисляется сначала для линеаризованного уравнения регрессии
Ln Y = 5.1541 + 0.015*t
Далее путем потенцирования определяются прогнозные оценки по исходным значениям временного ряда.
Прогноз по модели Брауна
Прогноз по регрессионной модели Сначала рассчитываются прогнозные значения Уровня потребительских цен (по линейному тренду):
Далее прогнозные значения Уровня потребительских цен используются для расчета прогноза средних цен книг по разделу Компьютерная литература.
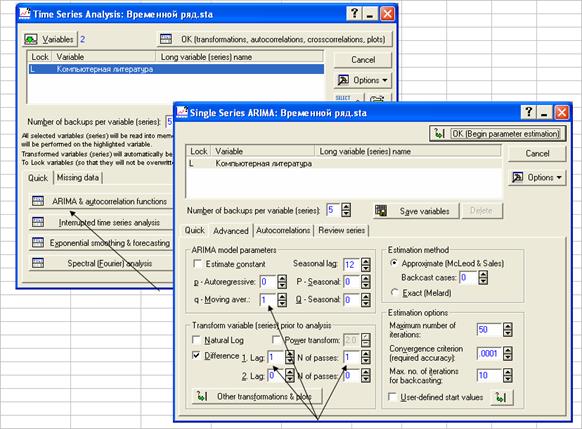
Модели ARIMA Построение наиболее популярных моделей ARIMA
p=0, d=1, q=1
Модель содержит незначимый параметр q(1) и далее не рассматривается.
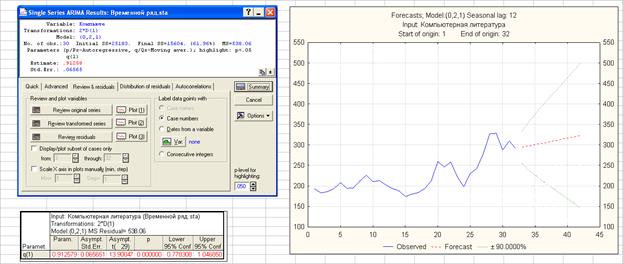
p=0, d=2, q=1
Модель ARIMA(0, 2, 1) не содержит незначимых параметров. Стандартная ошибка прогноза на 1 шаг для модели ARIMA(0, 2, 1) равна 23.20 против 30.97 для линейной модели. При увеличении горизонта прогноза преимущество имеет линейная модель. Стандартная ошибка прогноза на 5 шагов для модели ARIMA(0, 2, 1) равна 61.27 против 31.70 для линейной модели.
p=0, d=1, q=2
Модель содержит незначимые параметры q(1) и q(2), поэтому далее не рассматривается.
p=0, d=2, q=2
Модель содержит незначимый параметр q(2) и далее не рассматривается.
p=1, d=1, q=0
Модель содержит незначимый параметр p(1) и далее не рассматривается.
p=2, d=1, q=0
Модель содержит незначимые параметры p(1), p(2) и не рассматривается. p=1, d=2, q=0
По точности прогноза модель ARIMA (1, 2, 0) уступает модели ARIMA (0, 2, 1). Стандартная ошибка прогноза на 1 шаг равна 26.50 против 23.20 для модели ARIMA (0, 2, 1) и резко возрастает с увеличением горизонта прогноза.
p=1, d=1, q=1
Модель ARIMA (1, 1, 1) не содержит незначимых параметров. По точности прогноза модель ARIMA (1, 1, 1) превосходит все рассмотренные ранее модели ARIMA. Стандартная ошибка прогноза на 1 шаг равна 21.36 против 23.20 для модели ARIMA (0, 2, 1) и 30.97 - для линейной модели.
p=1, d=2, q=1
Модель ARIMA (1, 2, 1) содержит незначимый параметр p(1), поэтому далее не рассматривается. Вывод: По точности кратковременного прогноза (на 1 - 2 шага) полученные модели ARIMA конкурентоспособны по сравнению с линейной и другими рассмотренными ранее моделями временных рядов. Их целесообразно использовать, когда есть основания считать более значимыми последние наблюдения временного ряда. Из 9 рассмотренных моделей ARIMA лучшей является модель ARIMA (1, 1, 1). Она не содержат незначимых параметров, ей соответствует наименьшее по сравнению с другими рассмотренными моделями значение стандартной ошибки прогноза 1-го шага: 21.36 против 23.20 для модели ARIMA (0, 2, 1) и 30.97 - для линейной модели.   Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|