|
|
Где должны функционировать уровниНа протяжении этой, и последующих лекций речь идет о логических слоях, т.е. о расчленении системы на отдельные части. Подобное разделение полезно даже тогда, когда все слои функционируют на одной машине. Впрочем, существуют ситуации, где различия в поведении системы могут быть обусловлены принципами ее физической организации. В большинстве случаев существует только два варианта размещения и выполнения компонентов корпоративных приложений - на персональном компьютере и на сервере. Зачастую самым простым является функционирование кода всех слоев системы на сервере. Это становится возможным, например, при использовании HTML-интерфейса, воспроизводимого Web-обозревателем. Основным преимуществом сосредоточения всех частей приложения в одном месте является то, что при этом максимально упрощаются процедуры исправления ошибок и обновления версий. В этом случае не приходится беспокоиться о внесении соответствующих изменений на всех компьютерах, об их совместимости с другими приложениями и синхронизации с серверными компонентами. Общие аргументы в пользу размещения каких-либо слоев на компьютере клиента состоят в повышении быстроты реагирования (responsiveness) приложения и в обеспечении возможности локальной работы. Чтобы код сервера смог отреагировать на действия, предпринимаемые пользователем на клиентской машине, требуется определенное время. А если пользователю необходимо быстро опробовать несколько вариантов и немедленно увидеть результат, продолжительность сетевого обмена становится серьезным препятствием. Помимо того, приложению требуется сетевое соединение как таковое. Может быть, в обозримом будущем так и случится, но что делать жителям какой-нибудь Тмутаракани, которые не желают ждать, пока кто-то из операторов беспроводной связи удосужится обеспечить "покрытие" их Богом забытого селения. А поддержка возможностей локального функционирования выдвигает особые требования, но боюсь, что они выбиваются из контекста этой книги. Приняв к сведению все приведенные соображения, можно исследовать альтернативы, рассматривая слой за слоем. Слой источника данных лучше всегда располагать на сервере. Исключение составляет случай, когда функции сервера дублируются в коде "очень толстого" клиента для обеспечения средств локального функционирования системы. При этом предполагается, что изменения, вносимые в раздельные источники данных на клиентской машине и на сервере, подлежат синхронизации посредством механизма репликации. Однако, это уже тема для другого курса. Решение о том, где должен функционировать слой представления, большей частью зависит от предпочтений в выборе типа пользовательского интерфейса. Применение интерфейса толстого клиента автоматически влечет за собой необходимость размещения слоя представления на клиентской машине. Использование Web-интерфейса означает, что логика представления сосредоточена на сервере. Существуют и исключения, например удаленное управление клиентским программным обеспечением (таким, как Х-сервер в UNIX) с запуском Web-сервера на настольном компьютере, но они редки. Если речь идет о создании системы типа "поставщик-потребитель" ("business to customer" — В2С), у вас просто нет выбора. К серверу может подключиться любой, и вы вряд ли будете мириться с потерей посетителя только из-за того, что он использует какоето экзотическое программное или аппаратное обеспечение. Поэтому целесообразно все функции сконцентрировать на сервере, а клиенту передавать материал в формате HTML, полностью готовый для воспроизведения с помощью Web-обозревателя. Подобное архитектурное решение ограничено в том, что реализация самой незначительной логики пользовательского интерфейса требует обращения к серверу, а это не может не сказаться на быстроте реагирования приложения. Уменьшить зависимость от сервера можно за счет применения фрагментов кода на языках сценариев Web-обозревателя (подобных JavaScript) и загружаемых аплетов, но подобные меры снижают уровень совместимости обозревателей и вызывают другие проблемы. Чем более "чист" код HTML, тем проще жизнь. Вряд ли ваша жизнь будет простой даже в том случае, если каждый из настольных компьютеров вашей компании настроен, как утверждает начальник отдела информационных технологий, "максимально тщательно". Необходимость поддержки клиентского программного обеспечения в актуальном состоянии и требование исключить даже малую вероятность его несовместимости с другими программами - это серьезные проблемы, которые проявляются и в тривиальных ситуациях. Основной повод для применения интерфейсов толстого клиента - сложность задач и невозможность создания полноценных полезных приложений иной архитектуры. Однако популярность Web-интерфейсов неуклонно растет, а потребность в использовании толстых клиентов, напротив, снижается. Могу сказать одно: пользуйтесь Web-интерфейсами, если можете, и обращайтесь к средствам толстого клиента, если без них никак не обойтись. А как быть с кодом бизнес-логики? Его можно активизировать или целиком на сервере, или полностью в контексте клиентской части, или используя смешанный стиль. И вновь вариант "все на сервере" наиболее привлекателен с точки зрения удобства сопровождения системы. Передача каких-либо бизнес-функций клиенту может быть обусловлена только, скажем, необходимостью повышения быстроты реагирования интерфейса системы или потребностью в средствах поддержки локального функционирования. Если в рамках клиента необходимо выполнять какие-либо функции логики предметной области, прежде всего уместно рассмотреть возможность поручения клиенту всех таких функций. Подобный вариант очень похож на выбор интерфейса толстого клиента. Запуск Web-сервера на клиентской машине ненамного повысит быстроту реагирования приложения, хотя даст возможность использовать его в локальном режиме. Где бы ни находился код бизнес-логики, его следует сохранять в отдельных модулях, не связанных со слоем представления, используя одно из типовых решений - сценарий транзакции (Transaction Script) или модель предметной области (Domain Model). Передача клиенту всего кода бизнес-логики сопровождается - и это уже отмечалось - усложнением процедур обновления системы. Расщепление множества бизнес-функций между сервером и клиентом выглядит как наихудшее решение, поскольку в общем случае затрудняет идентификацию того или иного фрагмента логики. Основная причина, побуждающая применять подобную архитектуру, может состоять в том, что клиенту необходимо владеть только какой-то частью бизнес-логики. Главное - изолировать эту порцию кода в отдельном модуле, не зависящем от других частей системы. Это даст возможность активизировать код и на компьютере клиента, и на сервере, если такая потребность возникнет позже. Такой подход, разумеется, требует дополнительных усилий, но они оправданны. После выбора узлов обработки необходимо попытаться обеспечить выполнение всего кода, относящегося к каждому отдельному узлу, в рамках единого процесса, функционирующего либо на одном узле, либо в пределах кластера из нескольких узлов. Не стоит делить слои по разрозненным процессам, если в этом нет насущной необходимости. В противном случае вам придется иметь дело с решениями типа интерфейса удаленного доступа (Remote Facade) и объекта переноса данных (Data Transfer Object), а это чревато потерей производительности и повышением сложности. Важно помнить, что подобные вещи относятся к числу тех, которые часто называют катализаторами сложности (complexity boosters): это распределенная обработка, многопоточные вычисления, сочетание радикально различных концепций (например, "объектной ориентации" и "реляционной модели"), межплатформенное взаимодействие и обеспечение предельно высокого уровня быстродействия. Решение любой из названных задач сопряжено с большими затратами. Конечно, иногда приходится их нести, но это должно рассматриваться как исключение, а не правило. Базовые типовые решения Паттерт Layer Supertype Domain Model (супертип слоя). Тип, выполняющий роль суперкласса для всех классов своего слоя. Довольно часто одни и те же методы дублируются во всех объектах слоя. Чтобы избежать повторений, все общее поведение можно вынести в супертип слоя. Принцип действия Концепция супертипа слоя, а следовательно, и само типовое решение крайне просты. Все, что от вас требуется, — это создать суперкласс для всех объектов слоя (например, класс Domainobject, являющийся суперклассом для всех объектов домена в модели предметной области). После этого в созданный суперкласс может быть вынесено все общее поведение наподобие сохранения и обработки полей идентифи-кации. Если в рассматриваемом слое приложения находятся объекты нескольких различных типов, может понадобиться создать несколько супертипов слоя. Назначение Супертип слоя используется тогда, когда все объекты соответствующего слоя имеют некоторые общие свойства или поведение. Поскольку в моих приложениях объекты слоевимеют множество общих черт, применение супертипа вполне может войти в привычку. Паттерн Separated Interface Отделенный интерфейс (Separated Interface). Предполагает размещение интерфейса и его реализации в разных пакетах. По мере разработки системы может возникнуть желание улучшить структуру последней, уменьшая количество зависимостей между ее частями. Управлять зависимостями значительно удобнее, если классы будут сгруппированы в несколько пакетов. Выполнив группировку, вы сможете установить правила, определяющие, могут ли классы одного пакет обращаться к классам другого пакета, например правило, согласно которому классы слоя домена не должны вызывать методы классов слоя представления. Несмотря на это, клиенту может понадобиться осуществить вызовы методов, противоречащие общей структуре зависимостей. В таком случае имеет смысл воспользоваться типовым решением отделенный интерфейс, определив интерфейс в одном пакете, а реализовав в другом. Таким образом, клиент, которому нужно установить связь с интерфейсом, будет оставаться полностью независимым от его реализации. Принцип действия Суть данного типового решения очень проста. Оно основано на том, что реализация зависит от своего интерфейса, но не наоборот. Это значит, что интерфейс и его реализацию можно разместить в разных пакетах, причем пакет, содержащий реализацию, будет зависеть от пакета, содержащего интерфейс. Все другие пакеты приложения могут зависеть от пакета, содержащего интерфейс, и при этом никак не зависеть от пакета, содержащего реализацию. Разумеется, чтобы подобное приложение заработало во время выполнения, интерфейс должен иметь некоторую реализацию. Для этого можно воспользоваться отдельным пакетом, который будет связывать интерфейс и реализацию во время компиляции, или же связать их во время настройки приложения. Интерфейс можно поместить в пакет клиента или же в отдельный пакет. Если реализация имеет только одного клиента или все клиенты реализации находятся в одном пакете, интерфейс может быть размещен прямо в пакете клиента. В связи с этим нелишне задуматься о том, отвечают ли разработчики клиентского пакета за определение интерфейса? Размещение интерфейса в пакете клиента указывает на то, что данный пакет будет принимать обращения от всех пакетов, содержащих реализацию этого интерфейса. Таким образом, если у вас есть несколько клиентских пакетов, интерфейс лучше поместить в отдельный пакет (см. рис. 3.1). Это рекомендуется делать и тогда, когда определение интерфейса не входит в обязанности разработчиков клиентского пакета (например, когда определением интерфейса занимаются разработчики его реализации).
Рисунок 3.1 Размещение интерфейса в отдельном пакете Помимо всего прочего, разработчику отделенного интерфейса необходимо выбрать, какими средствами языка программирования следует воспользоваться для описания интерфейса Складывается впечатление, что при использовании языков наподобие Java и С#, содержащих специальные интерфейсные конструкции, проще всего применить ключевое слово interface. Как ни странно, это далеко не всегда удачный выбор. Часто в качестве интерфейса лучше использовать абстрактный класс, чтобы допустить наличие общего, но необязательного поведения. Наиболее неприятным моментом в использовании отделенного интерфейса является создание экземпляра реализации. Как правило, чтобы создать экземпляр реализации, объект должен "знать" о классе последней. Зачастую в качестве такого объекта применяют отдельный объект-фабрику (factory object), интерфейс которого также реализован в виде отделенного интерфейса. Разумеется, объект-фабрика должен зависеть от реализации интерфейса, поэтому для обеспечения наиболее "безболезненной" связи применяют дополнительный модуль. Последний не только обеспечивает отсутствие зависимостей, но и позволяет отложить принятие решения о выборе класса реализации до момента настройки системы. В качестве более простой альтернативы дополнительному модулю можно предложить использование еще одного пакета, знающего и об интерфейсе и о реализации, который будет создавать экземпляры нужных объектов во время запуска системы. В этом случае экземпляры всех объектов, использующих отделенный интерфейс, или же соответствующих объектов-фабрик могут быть созданы в момент запуска приложения. Назначени е Отделенный интерфейс применяется для того, чтобы избежать возникновения зависимостей между двумя частями системы. Наиболее часто подобная необходимость возникает в описанных ниже ситуациях.
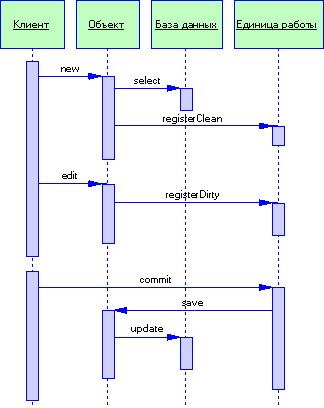
Паттерн Lazy Load Загрузка по требованию (Lazy Load) Объект, который не содержит все требующиеся данные, однако может загрузить их в случае необходимости.
Рисунок 3.2. Загрузка данных по требованию (пример)
Загрузку данных в оперативную память следует организовать таким образом, чтобы при загрузке интересующего вас объекта из базы данных автоматически извлекались и другие связанные с ним объекты. Это значительно облегчает жизнь разработчика, которому в противном случае пришлось бы прописывать загрузку всех связанных объектов вручную. К сожалению, подобный процесс может принять устрашающие формы, если загрузка одного объекта повлечет за собой загрузку огромного количества связанных с ним объектов - крайне нежелательная ситуация, особенно когда вам были нужны только несколько конкретных записей. Типовое решение загрузка по требованию прерывает процесс загрузки, оставляя соответствующую метку в структуре объектов. Это позволяет загрузить необходимые данные только тогда, когда они действительно понадобятся. Принцип действия Существует несколько способов реализации загрузки по Самый простой из них - инициализация по требованию. Основная идея данного подхода заключается в том, что при каждой попытке доступа к полювыполняется проверка, не содержит ли оно значение NULL. ЕСЛИ поле содержит NULL, метод доступа загружает значение поля и лишь затем его возвращает. Это может быть реализовано только в том случае, если поле является самоинкапсулированным, т.е. если доступ к такому полю осуществляется только п средством get-метода (даже в пределах самого класса). Использовать значение NULL В качестве признака незагруженного поля очень удобно. Исключение составляют лишь те ситуации, когда NULL является допустимым значением загруженного поля. Назначение Принимая решение об использовании загрузки по требованию, необходимо обдумать следующее: сколько данных требуется извлекать при загрузке одного объекта и сколько обращений к базе данных для этого понадобится. Бессмысленно использовать загрузку по требованию, чтобы извлечь значение поля, хранящегося в той же строке, что и остальное содержимое объекта; в большинстве случаев загрузка данных за одно обращение не приведет к дополнительным расходам, даже если речь идет о полях большого размера. Вообще говоря, о применении загрузки по требованию следует думать только в том случае, когда доступ к значению поля требует дополнительного обращения к базе данных. В плане производительности использование загрузки по требованию влияет на то, в какой момент времени будут получены необходимые данные. Зачастую все данные удобно извлекать посредством одного обращения к базе данных, в частности если это соответствует одному взаимодействию с пользовательским интерфейсом. Таким образом, к загрузке по требованию лучше всего обращаться тогда, когда для извлечения дополнительных данных необходимо отдельное обращение к базе данных и когда извлекаемые данные не используются вместе с основным объектом. Применение загрузки по требованию существенно усложняет приложение, поэтому я стараюсь прибегать к ней только тогда, когда без нее действительно не обойтись. Паттерн Record Set Множество записей (Record Set). Представление табличных данных в оперативной памяти. На протяжении последних 20 лет основным способом долгосрочного хранения данных являются таблицы реляционных баз данных. Наличие горячей поддержки со стороны больших и малых производителей баз данных, а также стандартного (в принципе) языка запросов привело к тому, что практически каждая новая разработка опирается на реляционные данные. На гребне успеха реляционных баз данных рынок программного обеспечения пополнился массой инфраструктур, предназначенных для быстрого построения пользовательских интерфейсов. Все эти инфраструктуры основываются на использовании реляционных данных и предоставляют наборы элементов управления, которые значительно облегчают просмотр и манипулирование данными, не требуя написания громоздкого кода. К сожалению, подобные средства имеют один существенный недостаток. Предоставляя возможность легкого отображения и выполнения простых обновлений, они не содержатнормальных элементов, в которые можно было быпоместить бизнес-логику. Наличие каких-либо правил проверки, помимо простейших "правильны ли данные?", а также любых бизнес-правил и вычислений здесь просто не предусмотрено. Разработчикам не остается ничего иного, как помещать подобную логику в базу данных в виде хранимых процедур или же внедрять ее прямо в код пользовательского интерфейса. Типовое решение множество записей значительно облегчает жизнь разработчиков, предоставляя структуру данных, которая хранится в оперативной памяти и в точности напоминает результат выполнения SQL-запроса, однако может быть сгенерирована и использована другими частями системы. Принцип действия Обычно множество записей не приходится конструировать самому. Как правило, подобные классы прилагаются к используемой программной платформе. В качестве примера можно привести объекты DataSet библиотеки ADO.NET и объекты RowSet библиотеки JDBС. Первой ключевой особенностью множества записей является то, что его структура в точности копирует результат выполнения запроса к базе данных. Это значит, что вы можете использовать классический двухуровневый подход выполнения запроса и помещения данных прямо в соответствующие элементы пользовательского интерфейса с теми же преимуществами, которые предоставляют подобные двухуровневые средства. Вторая ключевая особенность заключается в том, что вы можете создать собственное множество записей или же использовать множество записей, полученное в результате выполнения запроса к базе данных, и легко манипулировать им в коде логики домена. Несмотря на наличие готовых классов для реализации множества записей, их можно создать и самому. Однако следует отметить, что данное типовое решение имеет смысл только при наличии средств пользовательского интерфейса, предназначенных для отображения и считывания данных, которые также приходится создавать самостоятельно. В любом случае в качестве хорошего примера реализации множества записей можно назвать построение списка коллекций, весьма распространенное в динамически типизированных языках сценариев. При работе с множеством записей очень важно, чтобы последнее было легко отсоединить от источника данных. Это позволяет передавать множество записей по сети, не беспокоясь о наличии соединения с базой данных. Необходимость отсоединения приводит к очевидной проблеме: как выполнять обновление множества записей? Все больше и больше платформ реализуют множество заиписей в виде единицы работы (Unit of Work,), благодаря чему все изменения множества записей могут быть внесены в отсоединенном режиме и затем зафиксированы в базе данных. Явный интерфейс Большинство реализаций множества записей используют неявный интерфейс (implicit interface). В этом случае, чтобы извлечь из множества записей требующиеся сведения, необходимо вызвать универсальный метод с аргументом, указывающим на то, какое поленам нужно. Например, чтобы получить сведения о пассажире, забронировавшем билет науказанный авиарейс, необходимо воспользоваться выражением наподобие aReserva- tion ["passenger"]. Применение явного интерфейса требует реализации отдельного класса Reservation с конкретными методами и атрибутами, а извлечение сведений о пассажире выполняется с помощью выражений типа aReservation. passenger. Неявные интерфейсы обладают чрезвычайной гибкостью. Универсальное множество записей может быть использовано для любых видов данных, что избавляет от необходимости написания нового класса при определении каждого нового типа множества записей. Несмотря на подобные преимущества, неявные интерфейсы являются весьма спорным решением. Как узнать, какое слово нужно использовать для того, чтобы добраться к сведениям о пассажире, забронировавшем билет, - "passenger" ("пассажир"), "guest" ("клиент") или, может быть, "flyer" ("летящий")? Единственное, что можно сделать, - это "прочесать" весь исходный код приложения в поисках мест, где создаются и используются объекты бронирования. Если же у меня есть явный интерфейс, мы можем открыть определение класса Reservation и посмотреть, какое свойство нужно. Данная проблема еще более критична для статически типизированных языков программирования. Чтобы узнать фамилию пассажира, забронировавшего билет, придется прибегнуть к выражению вида
((Person) aReservation["passenger"]).lastNameж
Поскольку компилятор утрачивает всю информацию о типах, для извлечения нужных сведений тип данных приходится указывать вручную. В отличие от этого, явный интерфейс сохраняет информацию о типе, поэтому для извлечения фамилии пассажира можно воспользоваться гораздо более простым выражением:
aReservation.passenger.lastName.
В библиотеке ADO.NET возможность применения явного интерфейса обеспечивают строго типизированные объекты DataSet - сгенерированные классы, которые предоставляют явный иполностью типизированный интерфейс к множеству записей. Поскольку объект DataSet может содержать в себе множество таблиц и отношений, в которых они находятся, строго типизированные объекты DataSet включают в себя свойства, использующие информацию об отношениях между таблицами. Генерация классов DataSet выполняется на основе определений схем XML (XML Schema Definition — XSD). Паттерн Unit of Work Единица работы (Unit of Work). Содержит список объектов, охватываемых бизнес-транзакцией, координирует запись изменений в базу данных и разрешает проблемы параллелизма. Извлекая данные из базы данных или записывая в нее обновления, необходимо отслеживать, что именно было изменено; в противном случае сделанные изменения не будут сохранены в базе данных. Точно так же созданные объекты необходимо вставлять, а удаленные - уничтожать. Разумеется, изменения в базу данных можно вносить при каждом изменении содержимого объектной модели, однако это неизбежно выльется в гигантское количество мелких обращений к базе данных, что значительно снизит производительность. Более того, транзакция должна оставаться открытой на протяжении всего сеанса взаимодействия с базой данных, что никак не применимо к реальной бизнес-транзакции, охватывающей множество запросов. Наконец, вам придется отслеживать считываемые объекты для того, чтобы не допустить несогласованности данных. Типовое решение единица работы позволяет контролировать все действия, выполняемые в рамках бизнес-транзакции, которые так или иначе связаны с базой данных. По завершении всех действий оно определяет окончательные результаты работы, которые и будут внесены в базу данных. Принцип действия Базы данных нужны для того, чтобы вносить в них изменения: добавлять новые объекты или же удалять или обновлять уже существующие. Единица работы - это объект, который отслеживает все подобные действия. Как только вы начинаете делать что-нибудь, что может затронуть содержимое базы данных, вы создаете единицу работы, которая должна контролировать все выполняемые изменения. Каждый раз, создавая, изменяя или удаляя объект, вы сообщаете об этом единице работы. Кроме того, следует сообщать, какие объекты были считаны из базы данных, чтобы не допустить их несогласованности. Когда вы решаете зафиксировать сделанные изменения, единица работы определяет, что ей нужно сделать. Она сама открывает транзакцию, выполняет всю необходимую проверку на наличие параллельных операций (с помощью пессимистической автономной блокировки (Pessimistic Offline Lock [4]) или оптимистической автономной блокировки (Optimistic Offline Lock [4])) и записывает изменения в базу данных. Разработчики приложений никогда явно не вызывают методы, выполняющие обновления базы данных. Таким образом, им не приходится отслеживать, что было изменено, или беспокоитьсяо том, в каком порядке необходимо выполнить нужные действия, чтобы не нарушить целостность на уровне ссылок, - единица работы сделает это за них. Разумеется, чтобы единица работы действительно вела себя подобным образом, ей должно быть известно, за какими объектами необходимо следить. Об этом ей может сообщить оператор, выполняющий изменение объекта, или же сам объект. Назначение Основным назначением единицы работы является отслеживании действий, выполняемых над объектами домена, для дальнейшей синхронизации данных, хранящихся в оперативной памяти, с содержимым базы данных. Если вся работа выполняется в рамках системной транзакции, следует беспокоиться только о тех объектах, которые вы изменяете. Конечно же, для этого лучше воспользоваться единицей работы, однако существуют и другие решения.
Рисунок 3.3 Регистрация изменяемого объекта Пожалуй, наиболее простая альтернатива - явно сохранять объект после каждого изменения. Недостатком этого подхода является необходимость большого количества обращений к базе данных; например, если на протяжении выполнения одного метода объект был изменен трижды, вам придется выполнять три обращения к базе данных, вместо того чтобы ограничиться одним обращением по окончании всех изменений. Во избежание многократных обращений к базе данных запись всех изменений можно отложить до окончания работы. В этом случае вам придется отслеживать все изменения, которые были внесены в содержимое объектов. Для реализации подобной стратегии в код можно ввести дополнительны переменные, однако учтите: если переменных слишком много, они становятся неуправляемыми. Переменные хорошо использовать со сценарием транзакции, но они совсем не подходят для модели предметной области. Вместо того чтобы хранить измененные объекты в переменных, для каждого объекта можно создать флаг, который будет указывать на состояние объекта - изменен или не изменен. В этом случае по окончании транзакции необходимо отобрать все измененные объекты и записать их содержимое в базу данных. Удобство этого метода зависит от того, насколько просто находить измененные объекты. Если все объекты находятся в одной иерархии, вы можете последовательно просмотреть всю иерархию и записать в базу данных все обнаруженные изменения. В свою очередь, более общие структуры объектов, в частности модель предметной области, просматривать гораздо труднее. Огромным преимуществом единицы работы является то, что она хранит все данные об изменениях в одном месте. Поэтому вам не придется запоминать море информации, что-бы не упустить из виду все изменения объектов. Особенность.NET реализации В.NET для реализации единицы работы используется объект DataSet, лежащий в основе отсоединенной модели доступа к данным. Последнее обстоятельство немного отличает его от остальных разновидностей шаблона. В среде.NET данные загружаются из базы данных в объект DataSet, дальнейшие изменения которого происходят в автономном режиме. Объект DataSet состоит из таблиц (объекты DataTable), которые, в свою очередь, состоят из столбцов (объекты DataColumn) и строк (объекты DataRow). Таким образом, объект DataSet представляет собой "зеркальную" копию множества данных, полученного в результате выполнения одного или нескольких SQL-запросов. У каждой строки DataRow есть версии (Current, Original, Proposed) и состояния (Unchanged, Added, Deleted, Modified). Наличие последних, а также тот факт, что объектная модель DataSet в точности повторяет структуру базы данных, значительно упрощает запись изменений обратно в базу данных.   ЧТО ПРОИСХОДИТ ВО ВЗРОСЛОЙ ЖИЗНИ? Если вы все еще «неправильно» связаны с матерью, вы избегаете отделения и независимого взрослого существования...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|