|
|
Взаимное отображение объектов и реляционных структурВо всех разговорах об объектно-реляционном отображении обычно и прежде всего имеется в виду обеспечение взаимно однозначного соответствия между объектами в памяти и табличными структурами базы данных на диске. Подобные решения, как правило, не имеют ничего общего с вариантами шлюза таблицы данных (Table Data Gateway) и находят ограниченное применение совместно с решениями типа шлюза записи данных (Row Data Gateway) и активной записи (Active Record), хотя все они, вероятно, окажутся востребованными в контексте преобразователя данных (Data Mapper). Отображение связей Главная проблема, которая обсуждается в этом разделе, обусловлена тем, что связи объектов и связи таблиц реализуются по-разному. Проблема имеет две стороны. Во-первых, существуют различия в способах представления связей. Объекты манипулируют связями, сохраняя ссылки в виде адресов памяти. В реляционных базах данных связь одной таблицы с другой задается путем формирования соответствующего внешнего ключа (foreign key). Во-вторых, с помощью структуры коллекции объект способен сохранить множество ссылок из одного поля на другие, тогда как правила нормализации таблиц базы данных допускают применение только однозначных ссылок. Все это приводит к расхождениям в структурах объектов и таблиц. Так, например, в объекте, представляющем сущность "заказ", совершенно естественно предусмотреть коллекцию ссылок на объекты, описывающие заказываемые товары, причем последним нет необходимости ссылаться на "родительский" объект заказа. Но в схеме базы данных все обстоит иначе: запись в таблице товаров должна содержать внешний ключ, указывающий на запись в таблице заказов, поскольку заказ не может иметь многозначного поля.
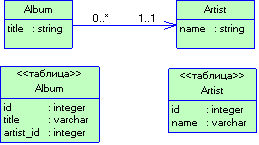
Рисунок 3.14 Пример использования паттерна Отображение внешних ключей для реализации однозначной ссылки Чтобы решить проблему различий в способах представления связей, достаточно сохранять в составе объекта идентификаторы связанных с ним объектов-записей, используя типовое решение поле идентификации (Identity Field [4]), а также обращаться к этим значениям, если требуется прямое и обратное отображение объектов и ключей таблиц базы данных. Это довольно скучно, но вовсе не так трудно, если усвоить основные приемы. При считывании информации из базы данных для перехода от идентификаторов записей к объектам используется коллекция объектов (Identity Map [4]). Связи, задаваемой внешним ключом, отвечает типовое решение отображение внешних ключей (Foreign Key Mapping [4]), устанавливающее подходящую связь одного объекта с другим (рис. 3.14). Если в коллекции объектов ключа нет, необходимо либо считать его из базы данных, либо применить вариант загрузки по требованию (Lazy Load). При сохранении информации объект фиксируется в таблице базы данных в виде записи с соответствующим ключом, а все ссылки на другие объекты, если таковые существуют, заменяются значениями полей идентификации этих объектов. Если объект способен содержать коллекцию ссылок, требуется более сложная версия отображения внешних ключей, пример которой представлен на рис. 3.15. В этом случае, чтобы отыскать все записи, содержащие идентификатор объекта-источника, необходимо выполнить дополнительный запрос (или воспользоваться решением загрузка по требованию). Для каждой считанной записи, удовлетворяющей критерию поиска, создается соответствующий объект, и ссылка на него добавляется в коллекцию. Для сохранения коллекции следует обеспечить сохранение каждого объекта в ней, гарантируя корректность значений внешних ключей. Операция может быть довольно сложной, особенно в том случае, когда приходится отслеживать динамику добавления объектов в коллекцию и их удаления. В крупных системах с подобной целью применяются подходы, основанные на метаданных (об этом речь идет несколько позже). Если объекты коллекции не используются вне контекста ее владельца, для упрощения задачи можно обратиться к типовому решению отображение зависимых объектов (Dependent Mapping).
Рисунок 3.15. Пример использования паттерна Отображение внешних ключей для реализации коллекции ссылок Совсем иная ситуация возникает, когда связь относится к категории "многие ко многим", то есть. коллекции ссылок присутствуют "с обеих сторон" связи. Примером может служить множество служащих и общий набор профессиональных качеств, отдельными из которых обладает каждый служащий. В реляционных базах данных проблема описания такой структуры преодолевается за счет создания дополнительной таблицы, содержащей пары ключей связанных сущностей (именно это предусмотрено в типовом решении отображение с помощью таблицы ассоциаций (Association Table Mapping), пример которого показан на рис. 3.16.
Рисунок 3.16 Пример использования паттерна Отображение с помощью таблицы ассоциаций для реализации связи «многие ко многим» При работе с коллекциями принято полагаться на критерий упорядочения, с учетом которого она создана. В объектно-ориентированных языках программирования обшей практикой является использование типов упорядоченных коллекций, подобных спискам и массивам. Однако задача сохранения в реляционной базе данных содержимого коллекции с произвольным критерием упорядочения остается сложной. В качестве способов ее решения можно порекомендовать использование неупорядоченных множеств или определение критерия упорядочения на этапе выполнения запроса к коллекции (последний подход связан с большими затратами). В некоторых случаях проблема обновления данных усугубляется из-за необходимости выполнять условия целостности на уровне ссылок (referential integrity). Современные СУБД позволяют откладывать (defer) проверку таких условий до завершения транзакции. Если "ваша" система такую возможность предоставляет, грех ею не воспользоваться. Если нет, система инициирует проверку после каждой операции записи. В такой ситуации вы обязаны соблюдать верный порядок прохождения операций. Не вдаваясь в детали, напомню, что один из подходов связан с построением и анализом графа, описывающего такой порядок, а другой состоит в задании жесткой схемы выполнения операций непосредственно в коде приложения. Иногда это позволяет снизить вероятность возникновения ситуаций взаимоблокировки (deadlock), для разрешения которых приходится осуществлять откат (rollback) тех или иных транзакций. Для описания связей между объектами, преобразуемых во внешние ключи, используется типовое решение поле идентификации, но далеко не все связи объектов следует фиксировать в базе данных именно таким образом. Разумеется, небольшие объекты-значения (Value Object), описывающие, скажем, диапазоны дат или денежные величины, нецелесообразно представлять в отдельных таблицах базы данных. Объект-значение уместнее отображать в виде внедренного значения (Embedded Value), то есть набора полей объекта, "владеющего" объектом-значением. При необходимости загрузки данных в память объекты-значения можно легко создавать заново, не утруждая себя использованием коллекции объектов. Сохранить объект-значение также несложно - достаточно зафиксировать значения его полей в таблице объекта-владельца. Можно пойти дальше и предложить модель группирования объектов-значений с сохранением их в таблице базы данных в виде единого поля типа крупный сериализованный объект (Serialized LOB). Аббревиатура LOB происходит от словосочетания Large OBject и означает "крупный объект"; различают крупные двоичные объекты (Binary LOBs — BLOBs) и крупные символьные объекты (Character LOBs — CLOBs). Сериализация множества объектов в виде XML-документа — очевидный способ сохранения иерархических объектных структур. В этом случае для считывания исходных объектов будет достаточно одной операции. При выполнении большого количества запросов, предполагающих поиск мелких взаимосвязанных объектов (например, для построения диаграмм или обработки счетов), производительность СУБД часто резко падает, и крупные сериализованные объекты позволяют существенно снизить загрузку системы. Недостаток такого подхода состоит в том, что в рамках "чистого" SQL сконструировать запросы к отдельным элементам сохраненной структуры не удастся. На помощь может прийти XML, позволяющий внедрить выражения формата XPath в вызовы SQL, хотя такой подход на данный момент пока не стандартизован. Крупные сериализованные объекты лучше всего применять для хранения относительно небольших групп объектов. Злоупотребление этим подходом приведет к тому, что база данных со временем будет напоминать файловую систему. Наследование Выше уже упоминались составные иерархические структуры, которые традиционно плохо отображаются средствами реляционных систем баз данных. Существует и другая разновидность иерархий, еще более усугубляющих страдания приверженцев реляционной модели: речь идет об иерархиях классов, создаваемых на основе механизма наследования (inheritance). Поскольку SQL не предоставляет стандартизованных инструментов поддержки наследования, придется вновь прибегнуть к аппарату отображения.
Рисунок 3.17 Паттерн Наследование с одной таблицей предусматривает сохранение значений атрибутов всех классов иерархии в одной таблице
Рисунок 3.18 Паттерн Наследование таблиц для каждого конкретного класса предусматривает использование отдельных таблиц для каждого конкретного класса иерархии
Рисунок 3.19 Паттерн Наследование таблиц для каждого класса предусматривает использование отдельных таблиц для каждого класса иерархии
Существует три основных варианта представления структуры наследования: "одна таблица для всех классов иерархии" (наследование с одной таблицей (Single Table Inheritance) - рис. 3.18; "таблица для каждого конкретного класса" (наследование с таблицами для каждого конкретного класса (Concrete Table Inheritance) - рис. 3.19; "таблица для каждого класса" (наследование с таблицами для каждого класса (Class Table Inheritance) - рис. 3.20. Возможен компромисс между необходимостью дублирования элементов данных и потребностью в ускорении доступа к ним. Решение наследование с таблицами для каждого класса - самый простой и прямолинейный вариант соответствия между классами и таблицами базы данных, но для загрузки информации об отдельном объекте в этом случае приходится осуществлять несколько операций соединения (join), что обычно сопряжено со снижением производительности системы. Решение наследование с таблицами для каждого конкретного класса позволяет обойти соединения, предоставляя возможность считывания всех данных об объекте из единственной таблицы, но существенно препятствует внесению изменений. При любой модификации базового класса нельзя забывать о необходимости соответствующего преобразования всех таблиц дочерних классов (и кода, обеспечивающего корректное отображение). Изменение самой иерархической структуры способно вызвать еще более серьезные проблемы. Помимо того, отсутствие таблицы для базового класса может усложнить управление ключами. Что касается наследования с одной таблицей, то самым большим недостатком этого решения является нерациональное расходование дискового пространства, поскольку каждая запись таблицы содержит поля для атрибутов всех созданных дочерних классов и многие из этих полей остаются пустыми. (Впрочем, некоторые СУБД "умеют" осуществлять сжатие неиспользуемых областей.) Большой размер записи приводит и к замедлению ее загрузки. Преимущество же наследования с одной таблицей заключается в том, что все данные, относящиеся к любому классу, сосредоточены в одном месте, а это значительно упрощает возможность внесения изменений и позволяет избежать операций соединения. Три упомянутых решения не являются взаимоисключающими - их вполне можно сочетать в рамках одной и той же иерархии классов: например, информацию о наиболее важных классах уместно объединить посредством наследования с одной таблицей, а для других классов воспользоваться решением наследование с таблицами для каждого класса. Разумеется, совмещение решений повышает сложность их применения. Среди названных способов отображения иерархии наследования трудно выделить какой-либо один. Как и при использовании всех других типовых решений, необходимо принять во внимание конкретные обстоятельства и требования. Реализация отображения Отображение объектов в реляционные структуры, по существу, сводится к одной из трех общих ситуаций:
В простейшем случае, когда схема создается самостоятельно, а бизнес-логика отличается умеренной сложностью, оправдан подход, основанный на сценарии транзакции (Transaction Script) или модуле таблицы (Table Module); таблицы могут создаваться с помощью традиционных инструментов проектирования баз данных. Для исключения кода SQL из бизнес-логики применяется шлюз записи данных (Row Data Gateway,) или шлюз таблицы данных (Table Data Gateway). Используя модель предметной области (Domain Model), остерегайтесь структурировать приложение с оглядкой на схему базы данных и больше заботьтесь об упрощении бизнес-логики. Воспринимайте базу данных только как инструмент сохранения содержимого объектов. Наибольший уровень гибкости взаимного отображения объектов и реляционных структур обеспечивает преобразователь данных (Data Mapper), но это типовое решение отличается повышенной сложностью. Если структура базы данных изоморфна модели предметной области, можно воспользоваться активной записью (Active Record). Хотя первоочередное построение модели представляет собой удобный способ восприятия предметной области, этот вариант действий правомерен только тогда, когда он реализуется в течение короткого итеративного цикла. Провести шесть месяцев за построением модели предметной области, не предусматривающей применения базы данных, а затем в один момент прийти к заключению о том, что сохранять кое-какую информацию все-таки было бы неплохо, не только несерьезно, но и весьма рискованно. Опасность заключается в том, что, если проект продемонстрирует изъяны на уровне производительности, исправить положение будет непросто. Каждую полуторамесячную или даже более краткую итерацию разработки модели и приложения следует сопровождать принятием решений, касающихся уточнения и расширения схемы базы данных. В этом случае у вас всегда будет самая свежая информация о том, как интерфейс взаимодействия приложения с базой данных ведет себя на практике. Итак, решая любую частную задачу, в первую очередь необходимо думать о модели предметной области, не забывая немедленно интегрировать каждую ее часть в базу данных. Если схема базы данных создана загодя, в вашем распоряжении примерно те же альтернативы, но процесс несколько отличается. Если бизнес-логика проста, ее слой располагается "поверх" создаваемых классов шлюза записи данных или шлюза таблицы данных, имитирующих функции базы данных. При повышении уровня сложности бизнес-логики приходится прибегать к помощи модели предметной области, дополненной преобразователем данных, который должен обеспечить сохранение содержимого объектов приложения в существующей базе данных. Использование метаданных Наличие в тексте приложения повторяющихся фрагментов кода - признак его плохо продуманной структуры. Общие функции можно вынести "за скобки", например средствами наследования и делегирования - одними из главных механизмов объектно-ориентированного программирования, но существует и более изощренный подход, связанный с отображением метаданных (Metadata Mapping). Типовое решение отображение метаданных основано на вынесении функций отображения в файл метаданных, задающий соответствие между столбцами таблиц базы данных и полями объектов. Наличие метаданных позволяет не повторять код отображения и заново генерировать его по мере необходимости. Даже пустяковый фрагмент метаданных, подобный приведенному ниже, способен весьма выразительно сообщить большой объем информации.
<class name = ‘Person’ tableName = ‘Person’> <attr name=’id’ field=’person_id’> <attr name=’lastName’ field=’last_name> </class>
С помощью этой информации вам удастся определить операции считывания и записи данных, автоматического формирования любых SQL-выражений, поддержки множественных связей и т.п. Вот почему модель метаданных находит широкое применение в коммерческих инструментальных средствах отображения объектов и реляционных структур. Отображение метаданных предлагает все необходимое для конструирования запросов в терминах прикладных объектов. Типовое решение объект запроса (Query Object) позволяет создавать запросы на основе объектов и данных в памяти, не требуя знаний SQL и деталей реляционной схемы, и применять инструменты отображения метаданных для трансляции таких выражений в соответствующие конструкции SQL. Воспользуйтесь этими решениями на наиболее ранних стадиях проекта, и вам удастся применить одну из форм хранилища (Repository,), полностью скрывающего базу данных от взгляда извне. Любые запросы к базе данных могут трактоваться как объекты запроса в контексте хранилища: в этой ситуации разработчику приложения неведомо, откуда извлекаются объекты - из памяти или из базы данных. Решение хранилище весьма удачно сочетается с богатыми моделями предметной области (Domain Model). Соединение с базой данных В большинстве случаев приложение взаимодействует с базой данных при посредничестве некоторого объекта соединения (connection). Прежде чем выполнять команды и запросы к базе данных, соединение обычно необходимо открыть. Объект соединения должен пребывать в открытом состоянии на протяжении всего сеанса работы с базой данных. По завершении обслуживания запроса возвращается объект типа множество записей (Record Set). Некоторые интерфейсы позволяют манипулировать полученным множеством записей даже после закрытия соединения, а некоторые требуют наличия активного соединения. Если действия выполняются в рамках транзакции, последняя, как правило, ограничена контекстом определенного соединения, которое должно оставаться открытым, как минимум, до завершения транзакции. Во многих средах открытие выделенного соединения сопряжено с расходованием строго ограниченных ресурсов, поэтому применение находят так называемые пулы соединений (connection pools). В этом случае приложение не открывает и закрывает соединение, а запрашивает его из пула и освобождает, когда оно больше не требуется. Сегодня поддержка пула соединений обеспечивается большинством вычислительных платформ, поэтому потребность в самостоятельной реализации подобной структуры возникает редко. Если все-таки вам приходится этим заниматься, прежде всего выясните, действительно ли применение пула повышает производительность системы. Нередко среда способна обеспечить более быстрое создание нового соединения, нежели повторное использование соединения из пула. Платформы, поддерживающие механизм пула соединений, часто скрывают последний посредством дополнительных интерфейсов, так что операции создания нового объекта соединения и выделения объекта из пула для разработчика прикладной системы выглядят совершенно идентично. Аналогично, закрытие соединения в реальности может означать возврат соединения в общий пул, доступный для других процессов. Подобная инкапсуляция, безусловно, является положительным решением. Ниже будут употребляться термины "открытие" и "закрытие", но имейте в виду, что в конкретной ситуации они могут означать соответственно "захват" соединения из пула и его "освобождение" с возвращением в пул. Неважно, как создаются соединения, но ими необходимо надлежащим образом управлять. Поскольку, как уже отмечалось, речь в данном случае идет о дорогостоящих вычислительных ресурсах, соединения следует закрывать сразу по завершении их использования. Помимо того, если применяется аппарат транзакций, необходимо гарантировать, что каждая команда внутри определенной транзакции активизируется при посредничестве одного и того же объекта соединения. Наиболее общая рекомендация такова: следует запросить объект соединения явно, используя вызов, обращенный к пулу или диспетчеру соединений, а затем ссылаться на этот объект в каждой команде, адресуемой к базе данных; по окончании использования объект необходимо закрыть. Но как поручиться, что ссылки на объект соединения присутствуют везде, где необходимо, и не забыть закрыть соединение по окончании работы. Решение первой части проблемы состоит в передаче объекта соединения в любую команду в виде явно задаваемого параметра. К сожалению, при этом может оказаться, что объект соединения не будет передан единственному методу, расположенному в стеке вызовов на несколько уровней ниже, а присутствует во всевозможных вызовах методов. В этой ситуации целесообразно вспомнить о реестре (Registry). Поскольку вам наверняка не хочется, чтобы соединением пользовались несколько вычислительных потоков, необходимо применять вариант реестра уровня одного потока. Даже если вы не так забывчивы, как я, то и в этом случае согласитесь, что требование явного закрытия соединений довольно обременительно, поскольку его слишком легко оставить без внимания, что, разумеется, недопустимо. Соединение нельзя закрывать и после выполнения каждой команды, так как первая же попытка сделать подобное внутри транзакции приведет к ее откату. Оперативная память, как и соединения, относится к числу ресурсов, которые надлежит возвращать системе сразу по завершении их использования. В современных средах разработки управление памятью и функции сборки мусора осуществляются автоматически. Поэтому один из способов закрытия соединения состоит в том, чтобы довериться сборщику мусора. При таком подходе соединение закрывается, если в ходе сборки мусора утилизируются объект соединения как таковой и все объекты, которые на него ссылаются. Удобно то, что здесь применяется та же хорошо знакомая схема управления памятью. Однако есть и проблема: соединение закрывается только тогда, когда сборщик мусора действительно утилизирует память, а это может произойти гораздо позже, чем исчезнет последняя ссылка, адресующая объект соединения, т.е. в ожидании закрытия он проведет немало времени. Возникнет подобная проблема или нет, во многом определяется особенностями среды разработки, которой вы пользуетесь. Если рассуждать в более широком смысле, я не стал бы слишком полагаться на механизм сборки мусора. Другие схемы - даже с принудительным закрытием соединений - кажутся более надежными. Впрочем, сборку мусора можно считать своего рода страхвочным вариантом: как говорится, лучше позже, чем никогда. Поскольку соединения логически тяготеют к транзакциям, удобная стратегия управления ими состоит в трактовке соединения как неотъемлемого "атрибута" транзакции: оно открывается в начале транзакции и закрывается по завершении операций фиксации или отката. Транзакции известно, с каким соединением она взаимодействует, и потому вы можете сосредоточиться на транзакции, более не заботясь о соединении как таковом. Поскольку завершение транзакции обычно имеет более "видимый" эффект, чем завершение соединения, вы вряд ли забудете ее зафиксировать (а если и забудете, то, поверьте мне, быстро об этом вспомните). Один из вариантов совместного управления транзакциями и соединениями демонстрируется в типовом решении единица работы (Unit Of Work). Если речь идет о выполнении операций вне транзакций (например, о чтении заведомо неизменяемых данных), для каждой операции можно использовать "свежий" объект соединения. Совладать с любыми проблемами, касающимися использования объектов соединений с короткими периодами существования, поможет схема организации пула соединений. При необходимости обработки данных в автономном режиме в контексте множества записей можно открыть соединение для загрузки информации в структуру данных, закрыть его и приступить к обработке. По завершении следует открыть новое соединение, активизировать транзакцию и сохранить результаты в базе данных. Если действовать по такой схеме, придется позаботиться о синхронизации данных с той информацией, которая изменялась другими транзакциями в период обработки содержимого множества записей. Особенности процедур управления соединениями во многом обусловлены параметрами конкретных среды разработки и приложения   Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|