
|
|
Сравнение двух экспериментальных распределенийНа практике значительно чаще встречаются задачи, в которых необходимо сравнивать не теоретическое распределение с эмпирическим, а два и более эмпирических распределения между собой. Ниже будут рассмотрены типичные варианты задач, предусматривающих сравнение экспериментальных распределений (данных) и способы их решения с использованием критерия хи -квадрат. В этих задачах с помощью критерия хи -квадрат проводится оценка однородности двух и более независимых выборок и таким образом проверяется гипотеза об отсутствии различий между двумя и более эмпирическими (экспериментальными) распределениями. Исходные данные двух эмпирических распределений для сравнения между собой могут быть представлены разными способами. Наиболее простой из этих способов: так называемая «четырехпольная таблица». Она используется в тех случаях, когда в первой выборке имеются два значения (числа) и во второй выборке также два значения (числа). Критерий хи -квадрат позволяет также сравнивать между собой три, четыре и большее число эмпирических величин. Для расчетов во всех этих случаях используются различные модификации формулы Начнем изучение сравнения двух эмпирических распределений с самого простого случая – использования четырехпольной таблицы. Задача 4. Одинаков ли уровень подготовленности учащихся в двух школах, если в первой школе из 100 человек поступили в вуз 82 человека и во второй школе из 87 человек поступили в вуз 44? Решение. Условия задачи можно представить в виде четырехпольной таблицы 8.6 ячейки которой, обозначаются обычно как А, В, С и D: Таблица 5.
Согласно данным, представленным в таблице 5, в нашем случае имеется четыре эмпирические частоты, это соответственно 82, 44, 18 и 43. Для того чтобы можно было использовать формулу Из таблицы 5 следует, что 18 и 43 человека из первой и второй школ соответственно не поступили в вуз. Относительно этих величин подсчитывается величина Р. Это так называемая доля признака, или частота. В данном случае признаком явилось то, что выпускники не поступили в вуз. Величина Р подсчитывается по формуле (8.5) следующим образом:
Величина Р позволяет рассчитать «теоретические» частоты для третьей строчки таблицы 8.6, которые обозначим как Эти частоты показывают, сколько учащихся из первой и второй школ не должны были поступить в вуз. Они подсчитывается следующим образом:
Иными словами, из первой школы не должны были поступить в вуз 33 человека, а из второй 28,71. (Для большей точности вычислений по методу хи -квадрат желательно не округлять результаты вычислений, а сохранять сотые и даже тысячные значения после запятой). Исходя из вновь полученных «теоретических» частот – 33 и 28,71, мы можем произвести расчет того, сколько учащихся должны были бы теперь поступить в вуз из первой и второй школ. Обозначим эти частоты как
Перепишем полученные «теоретические» частоты в новую таблицу 6. Таблица 6.
Вычислим
В данном случае число степеней свободы v = (k -1)•(с-1) подсчитывается как произведение числа столбцов минус 1 на число строк минус 1. Иными словами, v = (2–1)•(2–1)=1, поскольку у нас 2 строки и два столбца. И в соответствии с таблицей 12 Приложения 1 находим:
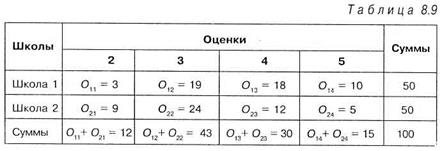
Полученная величина Решим задачу, в которой сравниваются две выборки, имеющие по четыре значения каждая. Задача 5. В двух школах района выяснялась успешность знания алгебры учащимися десятых классов. Для этого в обеих школах были случайным образом отобраны 50 учащихся и с ними проведены контрольные работы. Проверялось предположение о том, что существенной разницы в уровне знаний учащимися алгебры в двух школах не существует. Решение. Результаты контрольных работ представим сразу в виде таблицы:
В таблице 7 О 11— число учащихся первой школы, получивших оценку 2 в контрольной работе по алгебре, О 12 — число учащихся первой школы, получивших оценку 3 в контрольной работе по алгебре, О 13 — число учащихся первой школы, получивших оценку 4 в контрольной работе по алгебре и т.д. Подчеркнем, что «визуальный» анализ данных таблицы 7 показывает, что во второй школе число «двоечников» в три раза больше, чем в первой, и, наряду с этим, число «отличников» в два раза меньше, чем в первой школе. Казалось бы, можно сделать вывод о том, что вторая школа показывает существенно худшие результаты, чем первая. Однако подобные утверждения можно делать только на основе статистической обработки экспериментальных данных. В общем случае для подобных задач подсчет эмпирического значения хи -квадрат осуществляется по формуле:
Подставим данные нашего примера в формулу, получим:
Число степеней свободы в данном случае равно v = (k -1)• (с -1) = (2 - 1) • (4 - 1) = 3. По таблице 12 Приложения 1 находим:
Полученные различия попали в зону незначимости. Иными словами следует принять нулевую гипотезу
Замечание. Число переменных в сравниваемых выборках может быть достаточно большим. В этом случае целесообразно использовать специальный прием группировки значений по интервалам. Число интервалов удобнее всего получать, используя таблицу 8. Таблица 8.
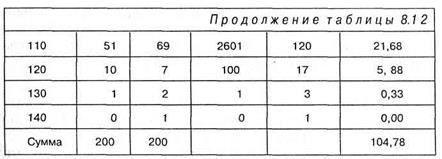
Рассмотрим задачу, в которой сравниваются две выборки, и в которых значений переменных столь много, что предыдущие способы сравнения оказываются трудновыполнимыми. Задача 6. Психолог сравнивает два эмпирических распределения, в каждом из которых было обследовано 200 человек по тесту интеллекта. Вопрос: различаются ли между собой эти два распределения? Решение. Представим эмпирические данные в виде таблицы 8.12, в которой приведены также предварительные расчеты, необходимые для получения
Для случая равенства числа испытуемых в первой и второй выборках расчет производится по формуле (8.8):
Где f 1 частоты первого распределения, а f 2 — частоты второго. N — число элементов в каждой выборке. В нашем случае в каждой из выборок оно равно 200. Произведем расчет по формуле (8.8), основываясь на результатах таблицы 8.12:
В данном случае число степеней свободы v = (k - 1 ) ·(с -1 ) = (9 - 1) · (2 - 1) = 8, где k - число интервалов разбиения, а с- число столбцов. В соответствии с таблицей 12 Приложения 1 находим:
Полученные различия попали в зону неопределенности. Психолог может, как принять, так и отклонить гипотезу Рассмотрим еще одну аналогичную задачу, в которой число значений в каждой из выборок различно. В этом случае используют другую формулу расчета. Задача 7. Психолог сравнивает два эмпирических распределения, в каждом из которых было обследовано по тесту интеллекта разное количество испытуемых. Вопрос - различаются ли между собой эти два распределения? Решение. Представим эмпирические данные сразу в виде таблицы 8.13, отметив при этом, что число градаций IQ увеличилось, в отличие от таблицы 8.12, до 150.
В таблице 8.13 произведены предварительные расчеты, необходимые для вычисления эмпирического значения критерия xu -квадрат при условии разного числа испытуемых в первой и второй выборках. В этом случае расчет производится по формуле (8.9):
Где
В данном случае число степеней свободы v = (k – 1) ·(с – 1) = (10 – 1) · (2 – 1) = 9, где k - число интервалов разбиения, а с - число столбцов. В соответствии с таблицей 12 Приложения 1 находим:
Полученная величина эмпирического значения хи -квадрат попала в зону значимости. Иными словами, следует принять гипотезу
  ЧТО ПРОИСХОДИТ ВО ВЗРОСЛОЙ ЖИЗНИ? Если вы все еще «неправильно» связаны с матерью, вы избегаете отделения и независимого взрослого существования...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
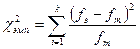 , что позволяет существенно облегчить процесс вычисления.
, что позволяет существенно облегчить процесс вычисления. .
.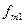 и
и  .
.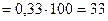
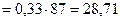
 для первой и
для первой и 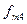 для второй школ, получим соответственно:
для второй школ, получим соответственно: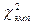 , из величин табл. 5 вычитаются величины табл. 6:
, из величин табл. 5 вычитаются величины табл. 6:
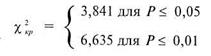

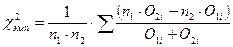 .
.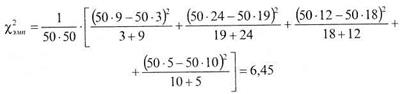


 о сходстве или о том, что уровень знания учащимися алгебры в двух разных школах статистически значимо не отличается между собой. Выше, при простом визуальном анализе экспериментальных данных мы высказывали предположение, что во второй школе успеваемость учащихся по алгебре существенно хуже, чем в первой, однако, критерий хи -квадрат показал, что это далеко не так.
о сходстве или о том, что уровень знания учащимися алгебры в двух разных школах статистически значимо не отличается между собой. Выше, при простом визуальном анализе экспериментальных данных мы высказывали предположение, что во второй школе успеваемость учащихся по алгебре существенно хуже, чем в первой, однако, критерий хи -квадрат показал, что это далеко не так.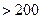


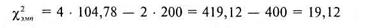
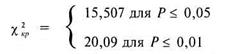



 частоты первого распределения, а
частоты первого распределения, а 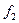 — частоты второго. N — сумма числа элементов в первой n1 и второй п2 выборках. В нашем случае оно равно 177 = 124 + 53, а сумма уже подсчитана в нижней строчке последнего столбца таблицы 8.13. Осталось произвести расчет по формуле (8.9.)
— частоты второго. N — сумма числа элементов в первой n1 и второй п2 выборках. В нашем случае оно равно 177 = 124 + 53, а сумма уже подсчитана в нижней строчке последнего столбца таблицы 8.13. Осталось произвести расчет по формуле (8.9.)
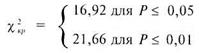

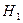 о том, что распределения уровней интеллекта в двух неравных по численности выборках статистически значимо отличаются между собой.
о том, что распределения уровней интеллекта в двух неравных по численности выборках статистически значимо отличаются между собой.