|
|
Ввод/вывод записей фиксированной длины⇐ ПредыдущаяСтр 12 из 12
Под записью фиксированной длины можно понимать размер элемента массива или структуры. int fread(void *ptr, size type, size n, FILE *stream) - чтение данных из файла. void main(void){ struct STOK record; FILE *in; in=fopen("data", "r"); int n=fread(&record, sizeof(record), 1, in); } Возвращает число считанных записей или EOF. void main(void){ float mas[100]; FILE *in; In=fopen("data", "rb"); fread(mas, sizeof(mas), 1, in); } //можно так - fread(mas, sizeof(float), 100, in);
int fwrite(void *ptr, size type, size n, FILE *stream) - запись данных в файл. Возвращает число записанных байт. fwrite(mas, sizeof(mas), 1, in);
Пример 1. Запись во временный файл и чтение из него в массив. #include <stdio.h> #include <stdlib.h> void main(void) { int array[100]; //создать временный файл FILE *tempf=tmpfile(); if(!tempf) { puts(“нельзя открыть временный файл”); exit(1); } for(int index=0; index<100; index++)//пишем в файл fwrite(array,sizeof(int),1,tempf); rewind(tempf); //указатель вернуть на начало fread(array,sizeof(int),100,tempf); rmtmp(); //закрыть и уничтожить временный файл }
Пример 2. Проверить конец файлового потока void main(void) { int buff[100]; FILE *fp; fp=fopen(“prog.txt”,”r”); if(!fp) { puts(“нельзя открыть файл”); } else { while(!feof(fp)) if(fgets(buff,100,fp)!=NULL) fputs(buff,stdout); fclose(fp); } } ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Многие задачи программирования используют динамические структуры данных. Например, организация каталога книг в библиотеке. Нельзя заранее определить количество книг, числящихся в библиотечном фонде, так как идет постоянное поступление новых книг и списание старых. Для реализации таких задач существуют различные связные списки: однонаправленные, двунаправленные; бинарные деревья и т.д.
Однонаправленные связные списки
Элементы списка называются узлами. Узел представляет собой объект, содержащий в себе указатель на другой объект того же типа и данные. Очевидным способом реализации узла является структура:
TelNum * next; //указатель на следующий элемент long telephon; // данные char name[30]; // данные };
Список представляет собой последовательность узлов, связанных указателями, содержащимися внутри узла. Простейшим списком является линейный или однонаправленный список. Признаком конца списка является значение указателя на следующий элемент равное NULL. Для работы со списком должен существовать указатель на первый элемент - заголовок списка.
Указатель заголовок
Основными операциями, производимыми со списками, являются обход, вставка и удаление узлов. Можно производить эти операции в начале списка, в середине и в конце.
Вставка узла
start
temp
temp->next = start; start = temp;
start current
temp
temp->next = current->next; current->next = temp;
a)
end temp
end->next = temp; end = temp;
Удаление узла из списка
a) первого узла start
TelNum *del = start; start = start->next; delete del;
b) В середине писка
current del
TelNum *del = current->next; current->next = del->next; delete del;
c) в конце списка
TelNum *del = end; current->next=NULL; delete del; end = current;
Алгоритмы, приведенные выше, обладают существенным недостатком - если необходимо произвести вставку или удаление ПЕРЕД заданным узлом, то так как неизвестен адрес предыдущего узла, невозможно получить доступ к указателю на удаляемый (вставляемый) узел и для его поиска надо произвести обход списка, что для больших списков неэффективно. Избежать этого позволяет двунаправленный список, который имеет два указателя: один - на последующий узел, другой - на предыдущий.
// Пример программы работы с односвязным списком #include <stdio.h> #include <conio.h> struct TelNum; int printAllData(TelNum * start); int inputData(TelNum * n); struct TelNum { TelNum * next; long number; char name[30]; }; // Описание: печать списка int printAllData(TelNum * start){ int c=0; for(TelNum * t=start;t; t= t->next) printf("#%3.3i %7li %s\n",++c,t->number,t->name); return 0; } // Описание: ввод данных в структуру n конец ввода - ввод нуля // в первое поле. Возвращает 1 если конец ввода int inputData(TelNum * n){ printf("Номер?"); scanf("%7li",&n->number); if(!n->number) return 1; printf("Имя? "); scanf("%30s",&n->name); return 0; } void main(void){ TelNum * start = NULL; //сторож TelNum * end = start; do{ //блок добавления записей TelNum * temp = new TelNum; if(inputData(temp)) {delete temp; break; } else { if(start==NULL) { temp->next = start; start = temp; end = temp; } else { end->next=temp; end=temp; end->next=NULL; } } }while(1); printf("\nЗаписи после добавления новых:\n"); printAllData(start); getch(); do{ //блок удаления записей TelNum * deleted = start; start = start->next; delete deleted; printAllData(start); getch(); }while(start!=NULL); }
Бинарные деревья
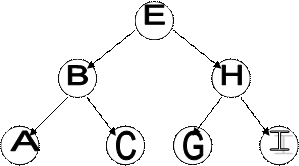
В бинарном дереве каждый узел содержит 2 указателя. Начальная точка бинарного дерева называется корневым узлом.
Корневой узел Е указывает на В и Н. Узел В является корневым узлом для левого поддерева Е, узел Н – для правого поддерева Е. За исключением самого нижнего яруса каждый узел бинарного дерева имеет одно или два поддерева. Обычно левое поддерево содержит меньшие данные, правое большие, что ускоряет поиск информации. Дерево такого типа называется деревом бинарного поиска. Поиск обычно начинается с корня. В зависимости от результата сравнения двигаются либо влево (если данные узла больше образца поиска), либо вправо (если меньше). Новые узлы всегда присоединяются к нижним вершинам, так что дерево всегда растет вниз. Чтобы распечатать бинарное дерево можно использовать алгоритм, называемый обратным ходом. Простейший алгоритм - рекурсивный. При заданном корне, программа совершает 3 шага: а) выполняет обход левого поддерева; б) печать корня; в) выполняет обход правого поддерева. Если обнаружен указатель NULL, то продвижение в направлении обхода в данном поддереве прекращается. При прямом обходе содержимое корня печатается до обхода поддеревьев. При концевом обходе содержимое корня печатается после совершения обхода двух поддеревьев.
// Пример программы работы с бинарным деревом #include <stdio.h> #include <conio.h> #include <string.h> struct TelNum; void printtreepre(TelNum *); //обход с корня дерева, левое поддерево, правое поддерево void printtreein(TelNum *); //обход с вершины правое поддерево,корень, левое поддерево void printtreepost(TelNum *); //обход с вершины левое поддерево, правое поддерево,корень int inputData(TelNum *); TelNum * addtree(TelNum *, TelNum *); struct TelNum { TelNum * left, *right; long number; char name[30]; }; // Описание: печать списка void printtreepre(TelNum * root) { if(!root) return; if(root->number) printf("номер %7li фамилия %s\n",root->number,root->name); printtreepre(root->left); printtreepre(root->right); } void printtreein(TelNum * root) { if(!root) return; if(root->number) printtreein(root->left); printf("номер %7li фамилия %s\n",root->number,root->name); printtreein(root->right); } void printtreepost(TelNum * root) { if(!root) return; if(root->number) printtreepost(root->left); printtreepost(root->right); printf("номер %7li фамилия %s\n",root->number,root->name); } // Описание: ввод данных int inputData(TelNum * n) { printf("Номер?"); scanf("%7li",&n->number); if(!n->number) return 1; printf("Имя? "); scanf("%30s",&n->name); return 0; } // Добавление узла к дереву TelNum * addtree(TelNum *root, TelNum *temp) { if(root==NULL) { //добавление узла в вершину дерева TelNum * root = new TelNum; root->number=temp->number; strcpy(root->name,temp->name); root->left=NULL; root->right=NULL; return root; } else { if(root->number>temp->number) root->left=addtree(root->left,temp); else root->right=addtree(root->right,temp); } return root; } // Поиск значения в бинарном дереве //по номеру телефона void searchtree(TelNum *root, int num) { while (root!=NULL) { if(root->number==num) { printf("номер %7li фамилия %s\n",root->number,root->name); return; } else{ if(root->number>num) root=root->left; else root=root->right; } } puts("Телефон не найден"); return; } void main(void) { TelNum * start = NULL; //сторож TelNum * temp = new TelNum;
do{ //блок добавления записей if(inputData(temp)) {delete temp; break; } else start=addtree(start,temp); }while(1); printtreepre(start); //ebcahgi getch(); printtreein(start); //ighebca getch(); printtreepost(start); //acbighe getch(); int num; puts("Введите номер телефона"); scanf("%d",&num); searchtree(begin,num); }
РАЗМЕЩЕНИЕ ДАННЫХ В ПАМЯТИ
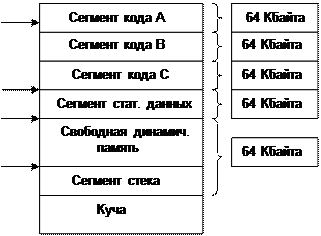
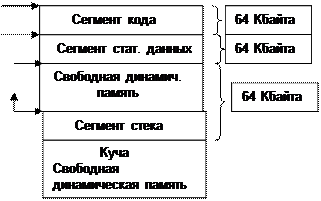
Данные могут храниться в регистрах процессора, в области статической памяти, в области организованной как стек и в динамической памяти. Статическая память - данные размещаются в ней после компиляции и хранятся до конца. В стеке - временно. Размещением данных управляет программист. Адрес любого участка памяти состоит из смещения и сегмента. Это 16-ти разрядные числа. Полный адрес получается: сегмент * 16 + смещение. Существует 4 специальных регистра для хранения адресов сегмента CS, DS, SS, ES. Для оптимизации управления памятью имеется 6 моделей памяти. Динамическая память "куча" используется в зависимости от выбранной модели памяти. Различают "ближнюю кучу" - неиспользованную часть сегмента стека и "дальнюю кучу" - оставшаяся свободная память машины. В начале блока выделяемой памяти записывается его размер. Он затем используется при удалении.
МОДЕЛИ ПАМЯТИ
C++ поддерживает 6 моделей памяти: tiny, small, medium, compact, large, huge. Для каждой модели различается количество сегментов отведенных под код программы и данных. Рассмотрим эти модели. 1. Крошечная модель tiny CS,DS,SS
SP
2. Малая модель small
DS,SS
SP
3. Средняя модель medium
CS
DS,SS
SP
4. Компактная модель Compact
DS
SS
SP
5.Большая модель large
CS
DS
SS
SP
6. Гигантская модель huge
CS
DS
SS
SP
Организация процессора I8086 накладывает ограничения на размер статистической памяти программы - размер кодов функций и размер статических данных. Размер данных не более 64 Кб в одном сегменте, т.к. размер адресуемой памяти ПЭВМ равен 1 Мб. Существует 2 варианта построения программы: А) весь исходный текст компилируется сразу; Б) программа собирается из нескольких фрагментов (модулей), которые компилируются отдельно. В любом таком модуле свои сегмент данных и сегмент кода. Объединение сегментов может происходить по-разному – в зависимости от используемого метода настройки сегментных регистров CS и DS. Может быть так, что независимо от количества модулей настройка CS,DS выполняется только однажды - тогда размер кода < 64 Кбайт. Размер кода или данных ограничен адресной памятью (1 Мбайт). tiny 64 Кб всего small 64 Кб кода и 64 Кб данные medium 1Мб код, 64 Кб данные compact 64 Кб код, 1Мб данные large 1Мб код, 1Мб данные huge тоже что large, но размер статических данных может превышать 64 Кб. В huge для статистических данных выделяют более 1 сегмента. Распределение данных по сегментам и управление перехода от сегмента к сегменту берет на себя компилятор. Для каждого модуля можно выделить более одного сегмента статических данных. ES - дополнительный сегмент регистр в любой модели памяти. int far array [30000]; char far a [70000]; - ошибка более 64кб. char huge b[70000]; -верно. Для "малых" моделей все указатели типа near, для больших - far. Для указателей на функции near для tiny, small,compact, far в остальных. DS для near указывает на данные, CS -для near указывает на функции. Размер кода тоже не может превышать 64кб. Для любого модуля заводится свой сегмент кода. Общий размер памяти выделяется для хранения кода не более 1 Мб для medium, large, huge. Если все функции в одном файле, то все указатели типа near. Если несколько модулей, но они не обращаются друг к другу, тоже самое. Но если есть обращения функций одного модуля к функциям другого, они должны быть описаны как far функции. void near fn (int arg); fn (1); SP: смещение адреса SP + 2: arg.
void far ff(int arg); ff(2); SP: смещение адреса SP + 2: сегмент SP + 4: arg.
huge fn - настройка регистра DS на сегмент статических данных того модуля, которому принадлежит функция. Для far функции значения DS меняется. Для совместной компляции нескольких модулей создается файл-проект. Проект создается через пункт меню Project - проект, где указываются все компилируемые файлы. Для этого используется подпункт меню: Open Project -> Insert - добавить модуль Delete - удалить модуль
СПИСОК ЛИТЕРАТУРЫ
1. М. Уэйт, С. Прайт, Д. Мартин. Язык СИ. - М.: "Мир", 1988 г. 2. Кеpниган Б., Ритчи Д. Язык пpогpаммиpования Си. - М.: Финансы и статистика, 1992г. 3. Кузнецов С.Д. Турбо Си. - М.: Малип, 1992г. 4. П. Киммел Borland C++ 5.0. – C-П.: «BHV-Cанкт Питербург», 1997 год. 5. Цимбал А.А.,Майоров А.Г., Козодаев М.А. Turbo C++: язык и его применение. – М.: «Джен Ай Лтд», 1993 г.
СОДЕРЖАНИЕ 1. ОБЗОР ЯЗЫКОВ ПРОГРАММИРОВАНИЯ.. 2 1.1. Pascal 2 1.2. Си. 2 2. ЭТАПЫ СОЗДАНИЯ ПРОГРАММЫ... 3 3. СТРУКТУРА ПРОГРАММЫ НА ЯЗЫКЕ СИ.. 3 3.1. Внутренняя структура программы.. 4 3.2. Пример программы на СИ.. 5 4. БАЗОВЫЕ ЭЛЕМЕНТЫ ЯЗЫКА СИ.. 5 5. ДАННЫЕ В ПРОГРАММЕ НА СИ.. 6 5.1. Константы.. 6 5.2. Базовые стандартные типы.. 8 6. ОПЕРАЦИИ ЯЗЫКА СИ.. 10 6.1. Арифметические операции. 10 6.2. Операции отношения. 11 6.3. Логические операции. 12 6.4. Операции с разрядами. 12 6.5. Операции сдвига. 13 6.6. Операция условия?: 13 6.7. Преобразование типов. 14 6.8. Операции приведения. 14 6.9. Дополнительные операции присваивания. 15 7. ОПЕРАТОРЫ ЯЗЫКА СИ.. 15 8. СТАНДАРТНЫЕ ФУНКЦИИ ВВОДА И ВЫВОДА.. 25 8.1. Модификаторы спецификаций преобразования. 26 9. ВВОД/ВЫВОД В ПОТОК С++. 28 9.1. Форматирование вывода. 29 10. Заключительная программа. 29 11. МАССИВЫ... 30 11.1. Одномерные массивы.. 30 11.1.1. Стандартные алгоритмы работы с одномерными массивами. 32 11.1.2. Инициализация одномерных массивов. 31 11.2. Многомерные массивы.. 33 11.2.1. Инициализация многомерных массивов. 33 12. ФУНКЦИИ.. 34 12.1. Cоздание и использование пользовательских функций. 34 12.2. Аргументы функции. 35 12.3. Возвращение значения функцией. 36 12.4. Inline-функции. 36 12.5. Значение формальных параметров функции по умолчанию.. 37 12.6. Перегрузка функций. 38 13. КЛАССЫ ПАМЯТИ И ОБЛАСТЬ ДЕЙСТВИЯ.. 39 13.1. Глобальные переменные. 40 13.2. Локальные переменные. 41 14. ПРЕПРОЦЕССОР ЯЗЫКА СИ.. 42 14.1. Подстановка имен. 43 14.2. Включение файлов. 44 14.3. Условная компиляция. 44 15. УКАЗАТЕЛИ.. 45 15.1. Операция косвенной адресации *. 45 15.2. Описание указателей. 45 15.3. Использование указателей для связи функций. 46 15.4. Указатели на одномерные массивы.. 46 15.5. Указатели на многомерные массивы.. 47 15.6. Операции над указателями. 48 15.7. Передача массива в качестве аргумента в функцию.. 49 15.8. Указатель на void *. 50 16. СИМВОЛЬНЫЕ СТРОКИ И ФУНКЦИИ НАД СТРОКАМИ.. 50 16.1. Массивы символьных строк. 51 16.2. Массивы указателей. 51 16.3. Указатель как возвращаемое значение функции. 52 16.4. Передача указателя как аргумента функции. 52 16.5. Функции, работающие со строками. 52 16.6. Стандартные библиотечные функции. 52 16.7. Преобразование символьных строк. 53 17. ССЫЛКИ.. 54 18. АРГУМЕНТЫ КОМАНДНОЙ СТРОКИ.. 55 19. ПРОИЗВОДНЫЕ ТИПЫ ДАННЫХ.. 56 19.1. Структуры.. 56 19.1.1. Массивы структур. 57 19.1.2. Вложенные структуры.. 58 19.1.3. Указатели на структуры.. 58 19.1.4. Операции над структурами. 58 19.1.5. Передача структуры в функцию.. 58 19.2. Объединения. 60 19.3. Синоним имени типа. 60 19.4. Определение именнованных констант. 61 19.5. Перечисления. 61 19.6. Битовые поля. 61 20. ДИНАМИЧЕСКОЕ ВЫДЕЛЕНИЕ ПАМЯТИ.. 62 20.1. Операция new и delete в С++. 65 20.2. Операция new с массивами. 65 20.3. Инициализаторы с операцией new.. 65 20.4. Проблемы, возникающие при использовании динамичски распределяемой памяти. 66 21. ФАЙЛ.. 68 21.1. Открытие файла fopen() 68 21.2. Закрытие файла fclose() 68 21.3. Функции ввода/вывода одного символа fgetc(), fputc() 68 21.4. Функции форматированного ввода/вывода в файл. 69 21.5. Функции ввода/вывода строки символов в файл. 69 21.6. Функции управления указателем в файле. 70 21.7. Ввод/вывод записей фиксированной длины.. 70 22. ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ.. 71 22.1. Однонаправленные связные списки. 71 22.1.1. Вставка узла. 71 22.1.2. Удаление узла из списка. 72 22.2. Бинарные деревья. 74 23. РАЗМЕЩЕНИЕ ДАННЫХ В ПАМЯТИ.. 77 24. МОДЕЛИ ПАМЯТИ.. 77 25. СПИСОК ЛИТЕРАТУРЫ... 80   Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 struct TelNum {
struct TelNum {
 a) в начало списка
a) в начало списка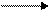
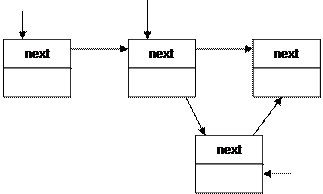 b) в середину списка
b) в середину списка
 в конец списка
в конец списка

 current end
current end

 CS
CS
 CS
CS