
|
|
Выполнение других задач манипуляцииСтр 1 из 9Следующая ⇒ ЗАКЛЮЧЕНИЕ Показано, что Q-нейросети могут быть использованы для стратегий обучения в таких задачах, как локализация куба, хватание и, наконец, поднятие. Эти стратегии могут быть обобщают как множества начальных положений сочленений, так и множество мест нахождения кубика. Кроме того, показано, что стратегии, обученные на симуляции, применимы напрямую в реальной среде без дополнительного обучения.
РЕЗУЛЬТАТЫ: 1. Глубокое обучение с подкреплением применимо не только к видеоиграм. 2. Работа с большими пространствами состояний. Даже в задаче с 25664×64 состояниями нахождение стратегий обучения выполнима, если правильно построена структуры вознаграждения, которая способствует изучению интересных состояний. 3. Для обучения требуются больше вычислительные мощности. При малой скорости обсчёта итераций обучение заняло значительно большее время, чем ожидалось. 4. Инструменты третьих лиц полезныисохраняютмноговремени если хорошо подходят под выполняемую задачу. С другой стороны, они также огромная помеха, если ты понимаешь, что работаешь над фичами, которые тебе не нужны. Вместо хорошего готового симулятора V-REP, лучше бы я сразу создал свой с нуля и сберёг силы и время. 5. Записывайтестолькоданных, скольковозможно. Вначалеэкспериментированиязаписанонедостаточностатистики, чтосталоявным, только когдаделодошлодоотчёта. 6. Tensorflow. Лучше бы использовать хорошо зарекомендовавшую себя компьютерную библиотеку обучения, такую как Torch - по крайней мере до тех пор, пока TensorFlow не созреет (небольшое сообщество, отсутствие учебников и недостаток функционала). БУДУЩИЕИССЛЕДОВАНИЯ Переход от симуляции к физическому миру. Работа показала, что симуляция действительно может быть использована для обучения робота управлению собой. Кроме того, показано, что возможен перевод обученных на симуляции стратегий в реальный мир. Наработка таких методов перевода может радикально улучшить возможности обучения роботов.
Поднятие различных объектов В течение работы мы концентрировались на поднятии куба, чтобы упростить свою конечную задачу. Мы показали, что агент может адаптироваться к лёгким изменениям формы. Можно расширить это исследование обучением со множеством разных объектов. Наша гипотеза – будь достаточно времени на тренировку, можно обобщить наше решение на объекты похожего размера — для примера, сферы, цилиндры и пирамиды. Эти объекты могут быть затем заменены на более сложные формы.
Выполнение других задач манипуляции Определениеместоположенияобъектов, выполнениезахвата и финальное поднятие объекта может быть началом более широкого списка задач. С инструментами выполнения этих первых шагов агент может быть натренирован выполнять дополнительные задачки, такие как постановка объектов друг на друга, наливание жидкостей или размещение объектов в специальных местах.
Работа со сложными внешними средами. Еслироботыпредназначеныдляманипулированиявсложныхименяющихсяусловиях, то они должны уметь действовать с объектами вне поля их зрения без прерывания выполнения основной задачи. Будущие исследования будут направлены на работу агента в различных окружениях, и фаза пост-обучения должна быть увеличена.
Исследоватьвыгодыилирасходы использования углов сочленений Вразделе 6.4 былоупомянуто о том, что добавление углов сочленений в виде входов в нейросеть не ускоряло обучение относительно сети работающей только на основе изображений. Будущая работа может исследовать эту особенность, уменьшить размер изображений, чтобы входы с углами сочленений приобрели бОльшее значение.
Исследовать алгоритм O-Greedy В разделе 6.7.2 представлен новый алгоритм сокращения времени обучения, применимый к нейросети со входами данными только из углов сочленений. Дальнейшая работа помогла бы выяснить как O-Greedyработает при использовании изображений в качестве входных данных, и выявила бы возможность уменьшить время обучения с помощью этой техники.
Альтернативы для Глубокого обучения с подкреплением (deepQ-learning) Q-learning хорошо подходит для задач игры в видеоигры и манипуляции роботов. В каких ещё областях этот метод может быть применён? Движение роботов в значительной степени зависит от визуальных данных, чтобы принимать решения, и решение найдено с помощью обучения с подкреплением. Можно было бы расширить существующие исследования в этой области как для 2-ногих [95] [24] [27], так и для 4х-ногих [48] с помощью глубокого Q-learning.Свёрточные нейронные сети не ограничиваются изображениями, они также хорошо себя показали при работе с видео [43] и звуком [74]. Таким образом, можно было бы изучить эффективность глубокого Q-learning, когда эти данные передаются агенту в задачу обучения с подкреплением.
КРИТИЧЕСКАЯ ОЦЕНКА Сильные стороны работы · Обобщаемость. Мы показали, что наши агенты имеют возможность обобщать во время обучения, могут адаптироваться к изменениям в форме цели и могут справляться с добавлением беспорядка, нагромождения объектов. · Сокращение времени обучения. В попытке сократить время обучения мы рассмотрели новые способы для агента изучить его среду. В разделе 6.7.2 предложен O-greedy алгоритм, который сократил время изучения успешных стратегий. Более того, используя промежуточные вознаграждения, мы поощряли агента к более успешным состояниям в короткие промежутки времени. · Симулятор руки Mico – это точная копия реальной руки. Этот инструмент может использоваться во многих других случаях благодаря возможности мгновенных движений и визуальной точности. · Пробовали многочисленные ПО симуляции. В ходе работы воспользовалисьV-REP, ещё 2мя версиями Robox для обучения наших агентов. Каждое из этих ПО симуляции успешно обучалось стратегиям действий, и при этом мы фактически показали, что наши методы распространяются на разные виртуальные среды. · Тесты как в симуляции, так и в реальном мире. Мы первыми применили 3D-моделирование в реальном мире, используя глубокое Q-обучение. Это важная веха на пути к виртуальному обучению, открывает возможности для дальнейших разработок. Слабые стороны работы · Нейро-сетевая архитектура. Помимо одного эксперимента, который мы добавили в конфигурацию робота, нейро-сетевая архитектура не менялась во время всей работы. · Потерянное время в ранних экспериментах. Мы исследовали многие сторонние симуляторы, которые могли бы точно имитировать нашего робота. Однако только после того, как мы начали экспериментировать, мы поняли, что нам не нужны большинство функций, и вместо этого они стали обузой для нашего времени обучения. · Маркировка оси X. Было бы более информативно записывать шаги по времени, а не по эпизодам. Например, сравнивая два метода с точки зрения времени обучения, один из них был более успешен чем другой, и это приводило к тому, что эпизодов у него было больше, хотя количество итераций фактически меньше. Это давало потенциально ошибочные графики. · Результаты теста. При тестировании в обученных средах агенты преуспевали между 50% и 56% случаев. Это прежде всего связано с остановкой экспериментов с самыми ранними признаками обучения, чтобы облегчить начало новых экспериментов. В идеале нам бы хотелось, чтобы каждый эксперимент работал дольше, что, возможно, улучшило скорость успеха. · Камера. Эксперименты были обобщены на разные позиции цели иразные начальные конфигурации роботов, но не были обобщены на разные положения камеры. Это важно, потому что при повторении сцены в реальном мире нельзя гарантировать, абсолютную идентичность положения камеры. · Недостаточные данные на ранних экспериментах главыс ранними экспериментами по сравнению с главой с поздними экспериментами. Что DeepMind сделал особенно хорошо в их статье – это был тест множества из 49 игр с использованием одного и тоже алгоритма, архитектуры сети и гипер-параметров, которые демонстрируют гибкость их метода. Если мы имели больше времени, мы бы последовали их примеру и применили работу к большему числу задач и форм, как описано в разделе 8.2. Zhangико. [107] безуспешнопыталисьприменитьнейросеть, натренированнуюнасимуляциидлядостиженияцелейвреальноммире. Задачу, которуюонипыталисьвыполнитьбылазначительнопроще: во-первых, онитренировалиихагентавдвумернойсимуляции (меньшепростр.конфиг.); во-вторых, они использовали руку с 3мя сочленениями по сравнению с нашей с 6ю сочленениями (ещё больше сокр. простр.конфиг.); наконец, цель нашейманипуляциивзахватеиподнятииобъекта по существу более сложная, чем попасть по цели на плоскости. Zhangико. использовалисетьDeepMind [64] смалоймодификацией —сохранив даже ввод в виде 4х изображений в каждый момент времени. Как было описано выше,DeepMind использовали такую технику, потому что они не могли захватить полное состояние в одном кадре. SergeyLevineико. [56] [25] бились над похожимизадачами, но с небольшими заметнымиотличиями. Ихработавключалабольшойспектрзадач: вставка игрушки в куб с дырками разной формы, закручивание крышки бутылки, это некоторые из них. Задачиначиналисьизупрощённого состояния, когдаобъектужебылсхвачен, убираяоднуизсамыхсложныхчастейзадачманипулирования. Вфокусе нашей работы полный цикл задач: определение места, хватание и наконец выполнение действия, например, поднятие. SergeyLevine и ко. Выполняли их задачи с использованием физического робота PR2, который требовал ручного выдачи наград и возвращения к исходному состоянию(reset). НашизадачивыполнялисьвсимуляциирукойMico, котораяпозволяладляобучениябезучителя (unsupervisedlearning) иимелапотенциалнамногобольшегочислаитераций. PintoиGupta [78] сфокусировалисьнапредсказанииположенийдляхватания, чем на выполнении конечных манипуляций, которых достигли мы. Ктомужеиспользованиесвёрточныхнейронныхсетей, их архитектура и выходные данные значительно отличались от нашей модели. Ихсетьсодержаладополнительно 2 свёрточныхслоя, похожихнаAlexNet [49], в то время, как мы использовали архитектуру, похожую наDeepMind [64]. ОБУЧЕНИЕ С ПОДКРЕПЛЕНИЕМ [1] Агент – обучаемыйипринимающий решениясубъект, автономноисследуетоптимальное поведение с помощью попыток и ошибок взаимодействия с окружающей его средой в попытках решить проблему управления. Среда – это всё, что снаружи агента, с чем можно взаимодействовать в течение обучения. Взаданныймоментt, средаиагентнаходятся в состоянии s∈S, которое содержит всю необходимую информацию. Изэтогосостояниямогут быть произведены действия a∈A. После перехода на следующий шаг времени агент получает вознаграждение r∈R и переходит в следующее состояние. Отображение состояний в действия задается стратегией π. Стратегии могут быть детерминированными (одно и то же действие используется для определенного состояния) или вероятностными (действие выбирается путем вычерчивания выборки из распределения по действиям для данного состояния). В зависимости от задачи обучение делится на эпизоды. Эпизодичная задача управления обычно используется в моделях с конечным временем. Число моментов времени может быть сколь угодно большим, но ожидаемая награда эпизода должна сходиться До сих пор мы упоминали, что, продвигаясь к следующему шагу времени, агент получает вознаграждение. Неформально целью агента является максимизация совокупных вознаграждений, которые он получает в долгосрочной перспективе. В общем, агент хочет максимизировать ожидаемый доход, который в простейшем случае является суммой вознаграждений. Тогда, кажется, что вознаграждения, полученные сейчас, стоят того же, что и награды в будущем. Это подводит нас к концепции дисконтирования (отсрочки). Введем параметр γ, который составляет 0 ≤ γ ≤ 1, называемый ставкой отсрочки (discountrate). Это используется для определения текущей стоимости будущих вознаграждений, которые может получить агент. Добавление ставки отсрочки к нашей ожидаемой награды дает формулу общей награды:
Это уравнение говорит нам, что вознаграждение в момент k в будущем взвешивается на γk-1, что соответствует величине награды, если бы мы получили его в настоящее время. При выборе подходящего значения для γ следует проявлять большую осторожность, поскольку он часто качественно изменяет форму оптимального решения [41]. Когдаγ приближается к 0, агент становится близоруким, выбирая действия, которые максимизируют его немедленную награду, что приводит к плохой работе в долгосрочных задачах. Напротив, когда γ приближается к 1, агент становится более дальновидным, что приводит к проблеме, когда он не может отличить стратегии, которые сразу дают большую награду, и те, которые компенсируют ей в далёком будущем. Эпизодичность задачи задаётся путём определениятерминального состояния прекращения действий как специальное поглощающее состояние, которое переходит в себя и генерирует вознаграждение 0.После этого (по достижении определённого числа итераций) агент сбрасывается в стандартное начальное состояние или состояние, выбранное из стандартного распределения начальных состояний. СВОЙСТВО МАРКОВОСТИ В системах обучения с подкреплениемнельзя ожидать, что посостоянию агент может понять всё об окружающей среде. Агент может не знать чего-то, или забыть что-то, что знал. Поэтому в идеальной системе нам нужна сигнатура состояний, которая суммирует прошлые события компактным образом, сохраняя при этом всю соответствующую информацию. Сигнатура, которая сохраняет эту информацию, называется марковским свойством состояния. Формально состояние st называется марковским, тогда и только тогда, когда: P(st+1,rt+1 | st, at) = P(st+1, rt+1 | st, at, rt, st−1, at−1, rt−1,..., r1,s0,a0) (2.3) Текущее состояние среды зависиттолькоотсостояния (посещённого) идействия (произведённого) впредыдущиймоментвремени. Т.е. будущее не зависит от прошлого, кроме как от настоящего состояния, которое сохраняет в себе все прошлые события агента.
ФУНКЦИИ ЦЕННОСТИ Когда агент входит в новое состояние, он должен знать, насколько ценно находиться в этом состоянии. Ценность состояния можно измерить двумя способами: функциями ценности-состояния и ценности-действия. Функция ценности-состояния для стратегииπесть ожидаемыйдоход, полученная начиная из состоянияs, и следуя стратегииπ затем:
где Eπ определена как ожидаемая ценность следования стратегии π. Функция ценности-действия для стратегии π есть ожидаемый доход, полученная начиная из состояния stakingactiona и следования стратегии π затем:
Фундаментальное свойство функций ценности является удовлетворение набору рекурсивных уравнений согласованности, называемыми уравнениями Беллмана:
Окончательное уравнение выражает связь между ценностью-состояния и ценностью-состояния-преемника. Это позволяет получить среднее по всем возможностям, взвешивая каждую (возможность) по вероятности её появления. Более того, можно видеть, что ценность первого состояния должна равняться вознаграждению за переход к s0 вместе со значением отсрочки для s0. Рис 2.3: Обобщённоеперечислениестратегий. ДПпредставляеттехнику начальной самозагрузки (самовытягивание, bootstrapping), которая позволяет улучшать оценки ценности для каждого состояния на основе состояния-преемника.
МЕТОДЫМОНТЕ-КАРЛО (МКМ) Все рассмотренные до сих пор методы требуют от нас полного знания об окружающей среде, чего нет в нашем проекте. Вместо этого рассмотрим методы Монте-Карло (МКМ), которые являются методами безмодели, они позволяют агенту учиться на выбранных последовательностях состояний, действий и вознаграждений, полученных непосредственно из окружающей среды. МКМ хорошоподходят в нашемслучае, т.к. не требуют предварительных знаний о динамике окружающей среды. МКМ усредняет выборки, возвращаемые из среды эпизодами по отдельности, в отличие от ДП, где данные обновляются поэтапно. Ценностью состояния является ожидаемая выгода — ожидаемое накопленное будущее приведенное вознаграждение, — получаемая начиная с данного состояния. Тогда очевидным способом оценить выгоду, основываясь на опыте, будет простое усреднение значений выгоды, полученных после того, как было пройдено данное состояние.С ростом числа наблюдений, дающих значения выгоды, среднее значение выгоды должно сходиться к ожидаемой величине. LISTING 2.1: МКМ
Поддержание достаточной уровня исследования (exploration) является проблемой для управления при помощи МКМ. Агент должен выдерживать баланс между исследованием и эксплуатацией (exploitation), чтобы добывать информацию о наградах и об окружающей среде. Он должен исследовать, рассматривая как ранее неиспользуемые действия, так и неопределенные действия, которые могут привести к отрицательным вознаграждениям. При принятии решения свою роль играют безопасность, известность награды и риск попробовать новое, для обнаружения более высокой награды. В общем, есть два подхода, которые могут быть использованы для решения проблемы баланса – методы с интегрированной оценкой ценности стратегий (on-policy) (ИМК-метод) и методы с разделенной оценкой ценности стратегий (off-policy) (пример???в книге). Методы-on-policy пытаются оценивать или улучшать стратегию непосредственно при использовании её для принятия решений. С другой стороны, методы-off-policy пытаются обучиться детерминированной стратегии [действий], которая может быть не связана со стратегией принятия решений. Одной из распространенных форм on-policy методов являются стратегии E-greedy. Это гибкая стратегия (π (s, a)> 0, ∀s ∈ S, a ∈ A (s)), где большую часть времени выбирается действие с оценённым максимальным значением-действия, однако, с вероятностьюE всё же выбирается случайное действие.
2.1.8 ОБУЧЕНИЕПРИ ПОМОЩИ ВРЕМЕННЫХ РАЗЛИЧИЙ TD-обучениеестьобъединениеспособностиучитьсячерезсамотестирование (bootstrapping) ДП, и способности обучаться напрямую из выборки взятой из среды без кППР. В отличие от МКМ, TD-методы могут не ждать конца эпизода для обновления значений функции. Вместо этого они только ждут следующего шага по времени, используя временные ошибки чтобы информировать нас насколько отличается новое значение от предыдущего предсказания. Этообновлениеимеетобщуюформу: НоваяОценка ← СтараяОценка + РазмерШага[Цель − СтараяОценка] (2.15)
ПростейшийTD-метод, известный как TD(0), определяется так: V (st) ← V(st) + α[rt+1 + γV(st+1) − V(st)] (2.16) Его безмодельная природа является преимуществомнадДП,аполностью последовательные on-line обновления – над МКМ. Этоособенноважно, когдаработать приходитсясдолгими (возможно бесконечными) эпизодами, так что любые откладывания обновлений на конец эпизода являются нежелательными. Обсудим 2 важныхTDалгоритма управления ниже.
SARSA SARSA – это on-policy алгоритм TD управления, которыйобозначает State-Action-Reward-State-Action. Егоимяпроисходитотэксперимента (s,a,r,s`,a`), вкоторымагентначинаетвсостоянии s, выполняетдействиеa, получаетнаградуr, переходит в состояние s`, и затем решает выполнить действие a`. Этотопытиспользуетсядляобновления Q(s,a) с использованием следующего уравнения: Q(st, at) ← Q(st, at) + α[r + γQ(st+1, at+1) − Q(st, at)] (2.17)
Q-LEARNING В отличие от Sarsa, Q-learning [100] – это off-policy алгоритм TD управления, который непосредственно аппроксимирует Q* независимо от применяемой стратегии. Эксперимент определяется как (s,a,r,s`), в нём агент начинает в состоянии s, выполняет действие a, получает вознаграждение r и переходит в состояние s`. Затем обновление Q(s,a) выполняется путем получения максимально возможного вознаграждения за действие от s` и применения следующего обновления: Q(st, at) ← Q(st, at) + α[r + γmaxa Q(st+1, a) − Q(st, at)] (2.18) Было доказано, что Q-learning в конечном итоге находит оптимальную стратегию для любого заданного кППР, если нет никаких ограничений на количество попыток, он пробует действие в любом состоянии. АлгоритмQ-learningприведенниже: СРАВНЕНИЕSARSAИQ-LEARNING Различие между двумя методамиSARSAи Q-learning довольно тонкое. Sarsa является on-policyметодом, что означает – он следует стратегии управления, когда предпринимает действия, которые будут использоваться для обновления Q-значений. Q-learning – этоoff-policy метод, он предполагает, что оптимальная стратегия соблюдается всегда, и поэтому выбирает наилучшее действие. Основное различие заключается в том, какие будут получены награды. Это различие хорошо иллюстрирует пример из книги Саттона и Барто – «Обучение с подкреплением» [93].
Рис 2.4: Мир-сетка задачи [93] Мир-сетка, показанный на рис.2.4, является частью эпизодической задачи без отсрочки γ=1. Задача состоит в том, чтобы перейти от состояния начала S к состоянию цели G, используя действия вверх, вниз, вправо и влево, не срываясь со скалы. Агент получает вознаграждение -1 на каждой смене состояния, за исключением попадания всостояние «скала», где он получает -100, и затем отправляется обратно в начало S. Выполняя задачу, агент выбирает действие согласно E-greedy с постоянным значением E=0.1.
Рис 2.5: Результаты выполнения задачи [93]. График показывает Через короткое время Q-learning умудряется выучить оптимальную политику, которая предполагает путешествие по самому краю скалы – несмотря на то, что иногда это приводит к случайному действию, которое выталкивает агента со скалы, следуя выбору Е-greedy.И наоборот, Sarsa учитывает этот сценарий метода выбора действий, и приводит к стратегии, которая следует более длинному (подальше от скалы), но более безопасному пути. Несмотря на то, чтоQ-learning находит оптимальную стратегию, её производительность хуже, чем у SARSA, хотя оба они будут сходиться к оптимальной стратегии, если Е постепенно уменьшать до 0. АПРОКСИМАЦИЯ ФУНКЦИИ Основные проблемы обучения робота – это непрерывная среда и большая размерность пространства состояний системы (сложность растёт экспоненциально). что заставляет нас подходить к задаче нестандартно, вместо представленные данных в виде таблицы с одной записью для каждого состояния, мы нашли способ учиться обобщать опыт из предыдущих состояний на те, которые ещё не посещены раньше. Аппроксимация функции – это представление значенийVt в моменты времени t, как параметризованную функциональную форму с вектором весов θt. Здесь мы завершаем обсуждение обучения с подкреплением. Мы отсылаем читателя к книге Саттона и Барто [93] для полного обзора обучения подкрепления. ИСКУССТВЕННЫЕНЕЙРОННЫЕСЕТИ ГРАДИЕНТНЫЙСПУСК Градиентный спуск – это способ найти локальный минимум функции потерь F(w), начиная с некоторого набора значений w, итеративно приближаясь к решению в направлении обратному к градиенту (уменьшающем величину потерь), пока процесс не сойдётся к 0. Градиент указывает на увеличение F, поэтому мы берём его с обратным знаком:
где η - скорость обучения, которая определяет размер шагов, предпринимаемых для минимизации функции. При выборе скорости обучения необходима осторожность – слишком большая приведёт к расхождению, а слишком малая – к длительной сходимости.
ГЛУБОКОЕОБУЧЕНИЕ Последней тенденций является переход к глубоким нейронным сетям. Глубоким обучением [11] достигается самая современная производительность в ряде областей и задач. К таким задачам относятся визуальное распознавание [92] [51], распознавание лиц [73], распознавание звука [53] [66], обнаружение пешеходов [90] и обработка естественного языка [17]. Популярность глубокого обучения исходит из его способности изучать полезные функции непосредственно с учителем и без, избегая необходимости в громадном и трудоемком ручном выборе критериальных свойств (features). Архитектуры глубокого обучения подразделяются на три широких класса: генеративный, дискриминационный и гибридный [21]. По словам Ли Дэнга, они определяются следующим образом: · Генеративные архитектуры применяются в анализе или синтезе рисунков,характеризуют корреляционные свойства высокого порядка в наблюдаемых или видимых данных, а также характеризуют совместные статистические распределения в видимых данных и в связанных с ними классах. · Дискриминационныеархитектуры предназначены для непосредственного обеспечения различающей способности при классификации шаблонов, часто характеризуют постериорные (позднейшие) распределения классов, обусловленные видимыми данными. · Гибридные архитектуры предназначены для достижения различения с помощью результатов генеративных архитектур, посредством их лучшей оптимизации. В фокусе нашей работы– дискриминационные архитектуры глубокого обучения, в частности свёрточные нейронные сети.
СВЁРТОЧНЫЕНЕЙРОСЕТИ Свёрточные нейросети (СНС) [52]: пиксели, которые находятся далеко друг от друга, обрабатываются по-разному, чем пиксели, которые находятся близко друг к другу. Одинаковые веса и смещениядля каждой свёртки означают, что нейроны на скрытом слое обнаруживают одни и те же признаки в разных местах изображения. Это подводит нас к одному из фундаментальных свойств СНС–к отображениюпризнаков (featuremap) – это отображениеодного слоя на следующий слой, что позволяет нам изучать фичи изображения, а не определять их вручную, как это было в обычных нейросетях. Часто нам хочется извлечь больше чем одну фичу из изображения, для этого требуется больше отображений признаков. При распределении весов и смещений СНСимеют меньше параметров, что позволяет ускорить обучение и построить глубокие сверточные сети. Слоиподвыборки (poolinglayer) обычно следуют за сверточными слоями и отвечают за вывод каждого из выходных данныхотображений признаков, чтобы создать итоговое отображение признаков. Эти слои подвыборкиподобны свёрточным слоям, нозадом наперёд. Свёрточная сеть обычно заканчивается как минимум одним полносвязаным слоем. В типичной сети может быть несколько уровней свёртки и подвыборки до окончательных полносвязных слоев. Как правило, более глубокие сети работают лучше, чем мелкие сети, за счет большего количества данных и повышенной сложности обучения. Уменьшение выходного уровня с размера в 4096 до 2048 фактически привело лишь к незначительному увеличению производительности [15] (без потери качества). Баланс выдерживается при выборе размера фильтра:как правило, небольшие фильтры используются для захвата очень тонких деталей изображения и сохранения пространственного разрешения, в то время как большие фильтры детали пропускают.
REINFORCEMENTLEARNING За последние несколько десятилетий обучение с подкреплением было идеальным решением для выработкистратегий управления в видеоиграх. Эти типы задач хорошо подходят обучению с подкреплением благодаря их эпизодическому характеру и структурам вознаграждения в виде игровых баллов. Более того, работа в этой области в последнее время продвигается к определению состояния только как картинки. В 1992 году обучение с подкреплением было успешно применено к программеигры в нарды - TD-gammon [96]. Очередной успех был достигнут на эмуляторе Atari-2600, сначала с линейной аппроксимацией и универсальными визуальными фичами [9], а затем с эволюционной архитектурой HyperNEAT [34].
ГЛУБОЧИЙQ-LEARNING Недавно новейшие результаты были достигнуты компанией DeepMind, которая успешно применила модели глубокого обучения к 49 играм Atari-2600, опережая все предыдущие подходы [64]. Эти агенты обучались непосредственно изRGB изображений, используя глубокие нейронные сети. Успех этого подхода сводился к новому варианту алгоритмаQ-обучения [65]. Параметризация Q проводилась с использованием сверточной нейронной сети, которая в сочетании с их подходом создает так называемую глубокую Q-сеть. Алгоритм Глубокий Q-learning, представленный ниже, использует метод, известный как повторный опыт (experiencereplay) [57]. С помощью этой методики, опыт агентов et = (st, at, rt, st+1) берётся на каждом временном шаге t и сохраняется в наборе данных D = et, et+1,..., en называемом память повторов (replaymemory). Затем обучение выполняется с использованием мини-пакетного градиентного спуска, выбирая случайным образом образцы опытаиз этой памяти повторов.
LISTING 2.4: Deep Q-learning with experience replay [65].
Память воспроизведения позволяет использовать опыт в более чем одном обновлении, что приводит к большей эффективности данных, и решает проблему переобучения, выделенную в [57]. Кроме того, случайная выборка из памяти воспроизведения прерывает корреляцию примеров опыта, чем уменьшает дисперсию обновлений. Спустя два года после успеха глубокого Q-обучения команда DeepMind представила первую массово распределенную архитектуру для глубокого обучения [70]. Эта архитектура использовалась для реализации глубокой Q-сети, описанной выше, и сумела превзойти оригинальную статью в 41 из 49 игр, причём показала ускорение обучения на порядок для большинства игр.
СИМУЛЯЦИЯ РОБОТА Видеалемыбы хотеливыучитьроботанасимуляции, аиспользоватьвреальноммире. Напрактикеэтооказалосьсложнее, т.к. различия в модели и реальном роботе суммируются на каждой итерации, и даже маленькая неточность может привести к большому расхождению алгоритма в жизни. Это вынуждает нас использовать короткий горизонт предсказаний и очень аккуратную симуляцию. Перевод поведения из симуляции в реальный мир проще, когда выполняются широкие жесты рукой в малом пространстве состояний, в то время, как высоко динамичные задачи или системы вызывают проблемы. *** Исследованияпоказали, чтосимуляцииболеевероятностны, чемработареальнойсистемы [71] и, к тому же, сами симуляции должны быть хорошо изучены, чтобы сделать переход было значительно проще [88].
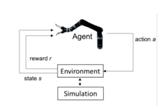
ПОСТАНОВКА ЗАДАЧИ ОБУЧЕНИЯ С ПОДКРЕПЛЕНИЕМ В конечном счете, мы хотим, чтобы наш агент успешно манипулировал данным объектом посредством повторных проб и ошибок со средой. Мы моделируем эту задачу на основе метода обучения с подкреплением. . Агент – рукаробота, всёостальноевместессимуляцией - среда. Средаменяетконфигурациюмирапосредствамкоммуникациис симуляцией и выдачинаградсогласно действиям руки — а именно нейросети, руководящей рукой. Вмоментtагентдолженрассмотретьконфигурациюst и произвести соответствующее действие. Средаисимуляцияотразятэтодействиекакизменениеконфигурациинаst+1. Этаконфигурациявместеснаградойrпередаются агенту, затемпроцесс повторяется. Процесспродолжаетсяпокакубнебудетуспешноподнят или заданное число попыток не выйдет. Мыверим, чтоэтотпроцессявляется Марковским, потомучтознанияопредыдущихпозицияхидействияхруки не помогают намподнятьобъект, толькотекущаяпозицияидействиерукииспользуются. Более того, мы верим, что этот процесс является эпизодическим (существуют конечные эпизоды от начального положения до конечного)в силу существования конечной конфигурации («объект поднят») или выхода за максимальное число итераций (нужно, чтобы избежать нахождения агента в конфигурациях, далёких от конечной).
ПРОМЕЖУТОЧНЫЕНАГРАДЫ Показав достаточным количеством успешных эпизодов, что наша свёрточная сеть может выучивать стратегии для выполнения задач, можно теперь перейти к проблеме исследования состояний. В нашем большом пространстве состояний можно посетить только небольшую часть из нихза реалистичное время. Из полностью вертикальной стартовой позиции, используя случайные действия, вероятность схватить куб у агента невероятно низка. Нужна более прогрессивная схема вознаграждения, чтобы агент исследовал интересные состояния, которые приводят к высоким вознаграждениям. Обучение симуляцией позволяет динамически перемещать цель и получать её позиции.Эта информация используется при исследовании агентом состояний вокруг целевой области. Одним из способов использования информации о позиции является предоставление промежуточных вознаграждений на основании его расстояния до куба. Учитывая, что мы можем рассчитать расстояние как:
Тривиальная линейная награда, которую мог бы получать агент: reward = 1 – distance (5.2) Проблема заключается в различениипозиций, близких к цели, разными наградах, полученных между двумя, и 2 одинаково разных положения вдали от цели одинаковы. В идеальном случае разница между наградами двух разных позиций, далеких от цели, должна быть очень схожей, в то время как вознаграждение между двумя разными позициями, которые близки к цели, должно быть значительно больше, чем далеких. Хорошим кандидатомявляется обратная экспоненциальная функция: reward = e−γ distance (5.3) гдеγесть коэффициент убывания (decayrate).
Рис.5.6: Начальная поз
ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры... Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом... Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право... ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 (2.2)
(2.2) (2.6)
(2.6) (2.7)
(2.7) (2.8)
(2.8) (2.14)
(2.14)

 (2.20)
(2.20)
 (5.1)
(5.1)




