
|
|
Распределение прогнозов общепрактикующих врачей о том, какова будет доля приемных с фондами в следующем году
Определим точку максимального расхождения между двумя распределениями ответов по АЛГОРИТМУ 2 расчёта критерия Колмогорова-Смирнова из п. 4. (см. Табл. 9). Таблица 9 Расчет максимальной разности накопленных частностей в распределениях прогнозов врачей двух групп
Максимальная выявленная между двумя накопленными эмпирическими частностями разность составляет 0,218. Ориентируясь на значение 0,218 считаем, что "эффект есть", если данный врач прогнозирует от 41 до 100% приемных с фондами в следующем году, и что "эффекта нет", если данный врач прогнозирует от 0 до 40% приемных с фондами в следующем году. Объединяем категории прогноза 1 и 2, с одной стороны, и категории прогноза 3, 4 и 5, с другой. Полученное распределение прогнозов представлено в Табл. 10. Таблица 10 Распределение прогнозов у врачей с фондами и врачей без фондов
Полученную таблицу (Табл. 10) можно использовать, проверяя разные гипотезы путем сопоставления любых двух ее ячеек. Помним, что это так называемая четырехклеточная, или четырехпольная, таблица. Условно считаем, что "эффект есть", когда прогноз попадает в категорию от 41 до 100%. Для упрощения расчетов необходимо повернуть таблицу на 90°, вращая ее по направлению часовой стрелки. Теперь можно перейти к рабочей таблице для расчета критерия φ* - углового преобразования Фишера. Таблица 11 Четырехклеточная таблица для подсчета критерия φ* Фишера для выявления различий в прогнозах двух групп общепрактикующих врачей
Сформулируем гипотезы. H0: Доля лиц, прогнозирующих распространение фондов на 41%-100% всех врачебных приемных, в группе врачей с фондами не больше, чем в группе врачей без фондов. H1: Доля лиц, прогнозирующих распространение фондов на 41%-100% всех приемных, в группе врачей с фондами больше, чем в группе врачей без фондов. Определяем величины φ1 и φ2 по Таблице XII приложения 1, Напомним, что φ1 - это всегда угол, соответствующий большей процентной доле. φ1 (57,2%) = 1,727 φ2 (36.0%) = 1,287 Теперь определим эмпирическое значение критерия φ*:
По Табл. ХШ Приложения 1 определяем, какому уровню значимости соответствует эта величина: р =0,039. По той же таблице Приложения 1 можно определить критические значения критерия φ*:
Для наглядности можем построить "ось значимости":
Ответ: H0 отвергается (р =0,039). Доля лиц, прогнозирующих распространение фондов на 41-100% всех приемных, в группе врачей, взявших фонд, превышает эту долю в группе врачей, не взявших фонда. Иными словами, врачи, уже работающие в своих приемных на отдельном бюджете, прогнозируют более широкое распространение этой практики в текущем году, чем врачи, пока еще не согласившиеся перейти на самостоятельный бюджет.
АЛГОРИТМ Расчет критерия φ* 1. Определить те значения признака, которые будут критерием для разделения испытуемых на тех, у кого "есть эффект" и тех, у кого "нет эффекта". Если признак измерен количественно, использовать критерий λдля поиска оптимальной точки разделения. 2. Начертить четырехклеточную таблицу из двух столбцов и двух строк. Первый столбец - "есть эффект"; второй столбец - "нет эффекта"; первая строка сверху - 1 группа (выборка); вторая строка - 2 группа (выборка). 3. Подсчитать количество испытуемых в первой группе, у которых "есть эффект», и занести это число в левую верхнюю ячейку таблицы. 4. Подсчитать количество испытуемых в первой выборке, у которых "нет эффекта", и занести это число в правую верхнюю ячейку таблицы. Подсчитать сумму по двум верхним ячейкам. Она должна совпадать с количеством испытуемых в первой группе. 5. Подсчитать количество испытуемых во второй группе, у которых "есть эффект", и занести это число в левую нижнюю ячейку таблицы. 6. Подсчитать количество испытуемых во второй выборке, у которых "нет эффекта", и занести это число в правую нижнюю ячейку таблицы. Подсчитать сумму по двум нижним ячейкам. Она должна совпадать с количеством испытуемых во второй группе (выборке). 7. Определить процентные доли испытуемых, у которых "есть эффект", путем отнесения их количества к общему количеству испытуемых в данной группе (выборке). Записать полученные процентные доли соответственно в левой верхней и левой нижней ячейках таблицы в скобках, чтобы не перепутать их с абсолютными значениями. 8. Проверить, не равняется ли одна из сопоставляемых процентных долей нулю. Если это так, попробовать изменить это, сдвинув точку разделения групп в ту или иную сторону. Если это невозможно или нежелательно, отказаться от критерия φ* и использовать критерий χ2. 9. Определить по Табл. XII Приложения 1 величины углов φ для каждой из сопоставляемых процентных долей. 10. Подсчитать эмпирическое значение φ* по формуле:
где: φ1 - угол, соответствующий большей процентной доле; φ2 - угол, соответствующий меньшей процентной доле; n1 - количество наблюдений в выборке 1; n2 - количество наблюдений в выборке 2. 11. Сопоставить полученное значение φ* с критическими значениями: φ* < 1,64 (р≤0,05) и φ*≤2,31 (р < 0,01). Если φ*эмп > φ*кр., Н0 отвергается. При необходимости определить точный уровень значимости полученного φ*эмп по Табл. XIII Приложения 1.
Алгоритм j*-критерия Фишера (Excel) 1. Пусть исследуемое свойство в первой выборке отмечено у m 1 респондентов, во второй выборке ‒ у m 2 респондентов. Обозначим n1 – объем первой выборки, n2 – объем второй выборки. 2. Строкам столбца А таблицы Excel присваиваются названия: «m 1», «m 2», «n 1», «n 2», «а 1», «а 2», «фи1», «фи2», «ФИ», «Н». В строки столбца В таблицы Excel заносятся численные значения «m 1», «m 2», «n 1», «n 2», соответствующие строкам столбца А1 таблицы Excel. 1. В строках столбца В таблицы Excel («а1», «а2», «фи1», «фи2», «ФИ») проводятся вычисления по формулам: а 1 = m 1/ n1; а 2 = m 2/ n2; фи1 =2*ASIN(КОРЕНЬ(a 1)); фи2 =2*ASIN(КОРЕНЬ(a 2)); ФИ =ABS(фи1 – фи2)*КОРЕНЬ(n1 * n2 /(n1 + n2)). 2. Вычисленное значение ФИ является основанием для статистического вывода. Если ФИ < 1,29, то принимается гипотеза Н 0. Если 1,29 ≤ ФИ < 1,64, то принимается гипотеза Н 1(p ≤ 0,10). Если 1,64 ≤ ФИ < 2,31, то принимается гипотеза Н 1(p ≤ 0,05). Если 2,31 ≤ ФИ, то принимается гипотеза Н 1 (p ≤ 0,01). Пример использования φ*-критерия Фишера (Excel) У 27 девушек и 22 юношей измерили уровень мотивации к из- беганию неудач. Высокий уровень выявлен у 16 девушек и у 11 юношей. Есть ли статистически значимые различия долей девушек от юношей, имеющих высокий уровень мотивации к избеганию неудач
Число юношей с высоким уровнем мотивации Всего девушек Всего юношей =В1/В3 =В2/В4 =2*ASIN(КОРЕНЬ(B5) =2*ASIN(КОРЕНЬ(B6)
=ABS(B7-B8)*КОРЕНЬ(B3*B4/(B3+B4))
Статистический вывод. Так как ФИ < 1,29, то принимается гипотеза Н 0. Содержательный вывод. Нет статистически значимых отличий процентов девушек (59%) и юношей (50%) с высоким уровнем мотивации к избеганию неудач
Биноминальный критерий m.   ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Живите по правилу: МАЛО ЛИ ЧТО НА СВЕТЕ СУЩЕСТВУЕТ? Я неслучайно подчеркиваю, что место в голове ограничено, а информации вокруг много, и что ваше право... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|



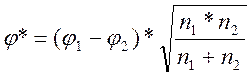
 Число девушек с высоким уровнем мотивации
Число девушек с высоким уровнем мотивации