
|
|
Проблемы методов структурной идентификацииОбратим внимание на множитель (
Чем сложнее модель тем более корректируется расчетное значение критерия в сторону уменьшения (то есть ухудшения) препятствуя включению аргумента в модель. Таким образом мы видим что даже классичский ШАМР уже использовал определенную форму штрафа за сложность модели. Правда его влияние при больших n незначительно и практически не влияет на структуру модели. Другие проблемы ШАМР 1. Для конкретных условий шума в данных (в Х и У) соотношение 2. известный недостаток теории стат. гипотез: только результат по введению аргумента (не принятию H0) в ней считается достоверным. Результаты по принятию H0 в обще-то ничего не гарантирует. Применяется такая хитрозделанная формулировка – принятие гипотезы H0 не противоречит исходным данным. = это приблизительно так как если бы у вас во дворе се8одня ночью убили дворника и обвинили в этом меня только на том основаниии что я спал дома один и некому подтвердить мое алиби. Так ведь еще в эту ночь 200 тыс киевлян спали одни – однако от этого вывод не меняется – гипотеза об обвинении в убичтве принимается на том основании что она не притиворечит исходны. данным. – Так накопайте другие данные – или лучше смените алгоритм - но как часто бвыает в жизни – лень и пользуются тем что имеют. 3. Кроме того, уменьшая И магическое число
4. Адекватность (статистическая значимость) получен. уравнения регрессии Для проверки значимости уравнения регрессии “в целом” используется критерий Фишера: если
Необходимо помнить, что доверительная оценка отклонения эмпирической линии регрессии от теоретической резко ухудшается по мере удаления от среднего зна чения По сути это значит что заранее признается неработоспособность модели на новых свежих данных если они по сути не повторяют старые!!!!! И этот аргумент у нас будет одним из главных в критике, потому что если в алгоритме нет серьезных механизмов настройки структуры модели то она будет беспомощна в реальных условиях применения на живых данных
Ниже мы рассмотрим механизмы штрафов (критерии) которые более чувствительно и обоснованно реагируют на усложнение модели Критерии с явным штрафом за сложность модели (продолжение) И так постулируем следующие части алгоритма структурно-параметрического синтеза. 1.Генератор структур -(он может быть более или менее удачным, то есть более или менее удачно решить выбор пути неполного перебора структур (если перебор полный то это самый простой алгоритм генерации) 2. Механизм расчета параметров (МНК, ЗЛП, град. Процедуры) 3. Критерии выбора структуры (внешние критерии) Будем сейчас вести речь о самом интересном – критериях отбора структур. 1 Пусть известна Наиболее подходящий критерий для выбора структуры оптимальной сложности при условии известности Критерий Маллоуза Критерий Маллоуза оказываеся дает при этом несмещенную оценку ошибки прогнозирования , Но надо знать дисп шума 2. Пусть известно распределение шума Когда известно распределение шума Для нахождения параметров Тогда для поиска оптимальной структуры
где В частном случае нормального шума он принимает вид критерия Маллоуза. При этом на практике он применяется в упрощенном виде
Этот вариант формулы называют критерием Акаике-Маллоуза Данный критерий существенно ограничивает рост сложности модели наличием аддитивного члена 2s. Однако проблема применения состоит в том, что в практических задачах функция распределения шума да часто и его дисперсия неизвестны. А что тогда делать? Используют тогда менее обоснованные но практически неплохо работающие критерии 3. Байесовский информационный критерий (критерий Шварца):
4. Также популярен критерий финальной ошибки предсказания Акаике применяемый при неизвестном характере шума и корректирующий остаточную сумму квадратов ошибки
Критерии с использованием штрафа за сложность в неявном виде и с порождением новых выборок 1. Бутстреп – предполагается что раз данные n точек появились у нас в віборке то у них равная вероятность появления в віборке - отсюда алгоритм получения подобных выборок -имитационное моделирование исходной выборки с помощью равномерного распределения - ключевой момент если некоторая точка реализовалась она возвращается в множество генерации (т.о. получаем выборки размером n с возможным количеством повторения некоторых точек) 2. Критерий "скользящего контроля", "усредненный критерий регулярности", или "джекнайф"-складной нож: Используется при крайне малом количестве точек (когда точек просто маловато используют разбиения выборки по МГУА -- ниже)
  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 ) в формуле МST и попадающий в числитель в статистике Фишера (*)
) в формуле МST и попадающий в числитель в статистике Фишера (*) и
и 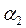 - свое "с точки зрения наиболее точного прогноза на свежих точках или более общо - с точки зрения " внешнего критерия " который мы определяем как "истина для нас " - в то время как сам алгоритм ШР опирается лишь на точность текущей обуч выборки и значение
- свое "с точки зрения наиболее точного прогноза на свежих точках или более общо - с точки зрения " внешнего критерия " который мы определяем как "истина для нас " - в то время как сам алгоритм ШР опирается лишь на точность текущей обуч выборки и значение  (увелич порог качества аргумента) мы не тоько увеличиваем вероятность правильного отвержения ложного аргумента 1-
(увелич порог качества аргумента) мы не тоько увеличиваем вероятность правильного отвержения ложного аргумента 1-  то уравнение регрессии адекватно (статистически значимо) описывает результаты эксперимента при (
то уравнение регрессии адекватно (статистически значимо) описывает результаты эксперимента при ( ) - процентном уровне значимости. Отношение (полной
) - процентном уровне значимости. Отношение (полной  и остаточной
и остаточной  дисперсий)
дисперсий)  показывает, во сколько раз уравнение регрессии аппроксимирует предсказывает результаты опыта лучше, чем среднее
показывает, во сколько раз уравнение регрессии аппроксимирует предсказывает результаты опыта лучше, чем среднее  , где k – сумма числа входных переменных плюс свободный член.
, где k – сумма числа входных переменных плюс свободный член. . В частности, по этой причине опасна экстраполяция эмпирической регрессионной зависимости за пределы интервала входных переменных
. В частности, по этой причине опасна экстраполяция эмпирической регрессионной зависимости за пределы интервала входных переменных  , для которого она получена
, для которого она получена дисперсия шума
дисперсия шума где RSS – квадрат нормы невязки у,
где RSS – квадрат нормы невязки у, 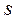 - сложность модели (для лин модели -количество расч параметров).
- сложность модели (для лин модели -количество расч параметров).
 предполагаетсяч использование метода наибольшего правдоподобия. Как известно, для этого надо найти такие
предполагаетсяч использование метода наибольшего правдоподобия. Как известно, для этого надо найти такие  при каждом варианте структуры
при каждом варианте структуры  .
.
 - максимизированное значение функции правдоподобия модели.
- максимизированное значение функции правдоподобия модели.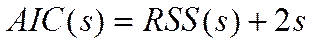



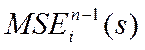 - значение критерия MSEi при синтезе модели на n-1 точке - то есть при выброшеной из выборки i- той точке при данном s. Когда s определено - считаем параметры на полной выборке.
- значение критерия MSEi при синтезе модели на n-1 точке - то есть при выброшеной из выборки i- той точке при данном s. Когда s определено - считаем параметры на полной выборке.