|
|
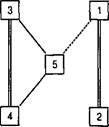
АНАЛИЗ КОРРЕЛЯЦИОННЫХ МАТРИЦКорреляционная матрица. Часто корреляционный анализ включает в себя изучение связей не двух, а множества переменных, измеренных в количественной шкале на одной выборке. В этом случае вычисляются корреляции для каждой пары из этого множества переменных. Вычисления обычно проводятся на компьютере, а результатом является корреляционная матрица. Корреляционная матрица (СоггеШ'юп Ма1пх) — это результат вычисления корреляций одного типа для каждой пары из множества Р переменных, измеренных в количественной шкале на одной выборке. ПРИМЕР_________________________________________________________________________ Предположим, изучаются связи между 5 переменными (у1, у2,..., у5; Р= 5), измеренными на выборке численностью N=: 30 человек. Ниже приведена таблица исходных данных и корреляционная матрица. Исходные данные: Корреляционная матрица: Корреляционная матрица является квадратной: число строк и столбцов равно числу переменных. Она симметрична относительно главной диагонали, так как корреляция хс у равна корреляции у с х. На ее главной диагонали располагаются единицы, так как корреляция признака с самим собой равна единице. Следовательно, анализу подлежат не все элементы корреляционной матрицы, а те, которые находятся выше или ниже главной диагонали. Количество коэффициентов корреляции, подлежащих анализу при изучении связей ^признаков определяется формулой: Р(Р-1)/2. В приведенном выше примере количество таких коэффициентов корреляции 5(5 — 1)/2 = 10. Основная задача анализа корреляционной матрицы — выявление структуры взаимосвязей множества признаков. При этом возможен визуальный анализ корреляционных плеяд — графического изображения структуры статистически значимых связей, если таких связей не очень много (до 10—15). Другой способ — применение многомерных методов: множественного регрессионного, факторного или кластерного анализа (см. раздел «Многомерные методы...»). Применяя факторный или кластерный анализ, можно выделить группировки переменных, которые теснее связаны друг с другом, чем с другими переменными. Весьма эффективно и сочетание этих методов, например, если признаков много и они не однородны. Сравнение корреляций — дополнительная задача анализа корреляционной матрицы, имеющая два варианта. Если необходимо сравнение корреляций в одной из строк корреляционной матрицы (для одной из переменных), применяется метод сравнения для зависимых выборок (с. 148—149). При сравнении одноименных корреляций, вычисленных для разных выборок, применяется метод сравнения для независимых выборок (с. 147—148). Методы сравнения корреляций в диагоналях корреляционной матрицы (для оценки стационарности случайного процесса) и сравнения нескольких корреляционных матриц, полученных для разных выборок (на предмет их однородности), являются трудоемкими и выходят за рамки данной книги. Познакомиться с этими методами можно по книге Г. В. Суходольского[14]. Проблема статистической значимости корреляций. Проблема заключается в том, что процедура статистической проверки гипотезы предполагает однократное испытание, проведенное на одной выборке. Если один и тот же метод применяется многократно, пусть даже и в отношении различных переменных, то увеличивается вероятность получить результат чисто случайно. В общем случае, если мы повторяем один и тот же метод проверки гипотезы к раз в отношении разных переменных или выборок, то при установленной величине а мы гарантированно получим подтверждение гипотезы в ахк числе случаев. Предположим, анализируется корреляционная матрица для 15 переменных, то есть вычислено 15(15—1)/2 = 105 коэффициентов корреляции. Для проверки гипотез установлен уровень а = 0,05. Проверяя гипотезу 105 раз, мы пять раз (!) получим ее подтверждение независимо оттого, существует ли связь на самом деле. Зная это и получив, скажем, 15 «статистически достоверных» коэффициентов корреляции, сможем ли мы сказать, какие из них получены случайно, а какие — отражают реальную связь? Строго говоря, для принятия статистического решения необходимо уменьшить уровень а во столько раз, сколько гипотез проверяется. Но вряд ли это целесообразно, так как непредсказуемым образом увеличивается вероятность проигнорировать реально существующую связь (допустить ошибку II рода). Одна только корреляционная матрица не является достаточным основанием для статистических выводов относительно входящих в нее отдельных коэффициентов корреляций! Можно указать лишь один действительно убедительный способ решения этой проблемы: разделить выборку случайным образом на две части и принимать во внимание только те корреляции, которые статистически значимы в обеих частях выборки. Альтернативой может являться использование многомерных методов (факторного, кластерного или множественного регрессионного анализа) — для выделения и последующей интерпретации групп статистически значимо связанных переменных. Проблема пропущенных значений. Если в данных есть пропущенные значения, то возможны два варианта расчета корреляционной матрицы: а) построчное удаление значений (Ехс1иёе сазез НзМве); б) попарное удаление значений (Ехс1и<1е савев ра1т8е). При построчном удалении наблюдений с пропусками удаляется вся строка для объекта (испытуемого), который имеет хотя бы одно пропущенное значение по одной из переменных. Этот способ приводит к «правильной» корреляционной матрице в том смысле, что все коэффициенты вычислены по одному и тому же множеству объектов. Однако если пропущенные значения распределены случайным образом в переменных, то данный метод может привести к тому, что в рассматриваемом множестве данных не останется ни одного объекта (в каждой строке встретится, по крайней мере, одно пропущенное значение). Чтобы избежать подобной ситуации, используют другой способ, называемый попарным удалением. В этом способе учитываются только пропуски в каждой выбранной паре столбцов-переменных и игнорируются пропуски в других переменных. Корреляция для пары переменных вычисляется по тем объектам, где нет пропусков. Во многих ситуациях, особенно когда число пропусков относительно мало, скажем 10%, и пропуски распределены достаточно хаотично, этот метод не приводит к серьезным ошибкам. Однако иногда это не так. Например, в систематическом смещении (сдвиге) оценки может «скрываться» систематическое расположение пропусков, являющееся причиной различия коэффициентов корреляции, построенных по разным подмножествам (например — для разных подгрупп объектов). Другая проблема, связанная с корреляционной матрицей, вычисленной при попарном удалении пропусков, возникает при использовании этой матрицы в других видах анализа (например, в множественном регрессионном или факторном анализе). В них предполагается, что используется «правильная» корреляционная матрица с определенным уровнем состоятельности и «соответствия» различных коэффициентов. Использование матрицы с «плохими» (смещенными) оценками при Если попарное исключение пропущенных данных не приводит к какому- либо систематическому сдвигу средних значений и дисперсий (стандартных отклонений), то эти статистики будут похожи на аналогичные показатели, вычисленные при построчном способе удаления пропусков. Если наблюдается значительное различие, то есть основание предполагать наличие сдвига в оценках. Например, если среднее (или стандартное отклонение) значений переменной А, которое использовалось при вычислении ее корреляции с переменной В, намного меньше среднего (или стандартного отклонения) тех же значений переменной А, которые использовались при вычислении ее корреляции с переменной С, то имеются все основания ожидать, что эти две корреляции {А—В и /4-0 основаны на разных подмножествах данных. В корреляциях будет сдвиг, вызванный неслучайным расположением пропусков в значениях переменных. Анализ корреляционных плеяд. После решения проблемы статистической значимости элементов корреляционной матрицы статистически значимые корреляции можно представить графически в виде корреляционной плеяды или плеяд. Корреляционная плеяда — это фигура, состоящая из вершин и соединяющих их линий. Вершины соответствуют признакам и обозначаются обычно цифрами — номерами переменных. Линии соответствуют статистически достоверным связям и графически выражают знак, а иногда — и р-уровень значимости связи.
Корреляционная плеяда может отражать все статистически значимые связи корреляционной матрицы (иногда называется корреляционным графом) или только их содержательно выделенную часть (например, соответствующую одному фактору по результатам факторного анализа). Корреляционный граф и его родственные связи, достоверность которых была установлена в судебном порядке
Построение корреляционной плеяды начинают с выделения в корреляционной матрице статистически значимых корреляций (иногда — разным цветом в зависимости от р-уровня значимости). Затем для строк (столбцов) матрицы, содержащих статистически значимые корреляции, подсчитывается их количество. Построение плеяды начинают с переменной, имеющей наибольшее число значимых связей, постепенно добавляя в рисунок другие переменные — по мере убывания числа связей и связывая их линиями, соответствующими связям между ними. ОБРАБОТКА НА КОМПЬЮТЕРЕ Графики двумерного рассеивания. Выбираем СгарЬз... > 8саМег...-8нпр1е. Нажимаем ОеПпе. В появляющемся окне назначаем осям переменные: выделяем слева одну переменную, нажимаем > напротив «X Ах1§» (Ось X), выделяем другую переменную, нажимаем > напротив «У Ах1§». Нажимаем ОК. Получаем график рассеивания назначенных переменных. Вычисление симметричной корреляционной матрицы. (По умолчанию 5Р88 вычисляет полную корреляционную матрицу.) Выбираем Апа1уге > СоггеЫе > В|уапа*е... В открывшемся окне диалога выделяем интересующие переменные в левой части и переносим их в правую часть при помощи кнопки > (переменных должно быть как минимум две). По умолчанию стоит флажок Реагвоп (корреляция /--Пирсона). Если интересует корреляция г-Спирмена или х-Кендалла, необходимо поставить соответствующие флажки внизу. Если в данных есть пропуски, то по умолчанию программа учтет их путем попарного удаления (ехс1ис!е сазез ра1пу|$е). Если необходимо учесть их путем построчного удаления (объектов с пропусками), то нажимаем Ор*10п§... > (ЕхсМе са§е§ Н§Ы§е) > Сопйпие... Нажимаем ОК. В появившейся таблице строки и столбцы соответствуют выделенным ранее переменным. В ячейке на пересечении строки и столбца, соответствующих интересующим нас переменным, видим три числа: верхнее соответствует коэффициенту корреляции, нижнее — численности выборки ДО, среднее — /^-уровню значимости для ненаправленных альтернатив (Зщ. (2-ЫМ)). Вычисление несимметричной корреляционной матрицы. Если есть необходимость вычислить корреляции не всех, а только двух групп переменных, то необходимо создание командного файла (ЗуЩах). Например, есть 5 переменных с именами: VI, у2, уЗ, у4, у5. Задача — вычислить корреляции у1 с остальными переменными из этого набора, обрабатывая пропуски путем попарного удаления. □ Выбираем РНе > > 8уп1ах. В открывшемся окне набираем текст: согге1аЬ1опз Vа^^аЫез VI М1Ы1 V2 V3 V4. (Количество переменных до и после слова тЫл — не ограничено). □ Если необходима обработка пропусков путем построчного удаления, то: согге1аЬ1оп5 Vа^^аЫе8 VI ч2 чЪ V4 V5 /пйззз-пд Из^мхзе. □ Если надо вычислить корреляцию г-Спирмена (с попарным удалением), то: попраг согг VI м 11:11 V2 V3 V4 V5. □ Для вычисления корреляций т-Кендалла добавляем к первой — вторую строку: попраг согг VI и 11:11 V2 V3 V4 V5 /рг1п1: кепйа11. □ Для вычисления и г-Спирмена, и т-Кендалла с построчным удалением: попраг согг VI иК:11 V2 V3 V4 V5 /пиззз-пд ИзЬм1зе /рг1П(: ЬоЫг. Заметьте, что вся команда обязательно должна заканчиваться точкой. Для выполнения команды нажимаем Кип > АН. Программа выдаст результат — таблицу корреляций переменных. Строки будут соответствовать именам переменных, указанных в команде до слова а столбцы — именам переменных, указанных после слова М1Ы1. Вычисление частной корреляции. Выбираем Апа!уге > СоггеЫе > Раг11а1... В открывшемся окне диалога переносим интересующие переменные из левой части в правую верхнюю (УапаЫез:) при помощи верхней кнопки > (переменных должно быть как минимум две). Затем при помощи нижней кнопки > из правой части в левую нижнюю часть (Соп1го1Пп§ Гог:) переносим переменную, значения которой хотим фиксировать. Нажимаем ОК. Получаем таблицу, аналогичную таблице парных корреляций, но верхнее число в каждой ячейке — значение частной корреляции соответствующих двух переменных при фиксированном значении указанной третьей переменной. Нижнее число — /ьуровень значимости, а посередине — число степеней свободы. Глава 11   Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|