|
|
Базы данных – Наместников А.М.⇐ ПредыдущаяСтр 12 из 12 1. Концепция баз данных Идея повышения степени независимости обрабатывающих программ от способов хранения и содержания хранимых данных впервые была использована в концепции баз данных путем разделения логического и физического уровней хранения данных в 1964 году в исследованиях сотрудников фирмы IBM. База данных - унифицированная совокупность хранимых и воспроизводимых данных, используемых в рамках организации. Несколько дополнительных определений базы данных: - База данных есть совокупность взаимосвязанных данных, совместно используемых несколькими приложениями и хранящимися с (минимальной) регулируемой избыточностью. - База данных состоит из всех экземпляров записей, экземпляров наборов записей и областей, которые контролируются конкретной схемой. Концепция БД:
Концепция БД предполагает наличие:
СУБД являются сложными программными системами, работающими на различных операционных платформах. Именно СУБД должна предоставить средства определения и манипулирования данными, сделав данные независимыми от прикладных программ, их использующих. В последнее время набирает обороты концепция машин баз данных, которая предполагает аппаратную реализацию некоторых процедур обработки данных.
Системой управления базами данных называется совокупность программных средств, необходимых для использования базы данных и предоставляющих разработчикам и пользователям множество различных представлений данных.
2. Модели данных Модель данных – указание множества допустимых информационных конструкций, операций над данными и множества ограничений для хранимых значений данных. Наиболее распространёнными являются модели данных: реляционная, сетевая, иерархическая. Основное различие между моделями состоит в способах представления взаимосвязей между объектами, описываемыми этими моделями. Реляционная модель данных является совокупностью отношений, из которых в результате выполнения запросов пользователей образуются новые производные отношения. ● Основа реляционной модели - отношение. Оно удобно представляется двумерной таблицей при соблюдении определенных ограничивающих условий. Таблица понятна, обозрима и привычна для человека. ● Набор отношений (таблиц) может быть использован для хранения данных об объектах реального мира и моделирования связей между ними. Модель данных. Иерархическая ● Структура данных называется иерархической, если ее схема представлена в виде дерева. Узлами дерева-схемы являются записи, дугами - иерархические связи между записями. ● Иерархические связи задают отношения между исходными и порожденными записями типа 1: М. Наивысший узел в иерархической модели называется корнем. ● Допустимыми конструкциями иерархической модели являются: Отношение; Веерное отношение - пара отношений, включающая одно основное R и одно зависимое S и связь между ними, при условии, что каждое значение зависимого отношения связано с единственным значение основного отношения; Иерархическая база данных.
● Иерархической базой данных называется множество отношений и веерных отношений, для которых выполняются ограничения: 1) Существует единственное отношение, называемое корневым, которое не является зависимым ни в одном веерном отношении. 2) Все остальные отношения являются зависимыми отношениями только в одном веерном отношении. ● Записью иерархической базы данных называется множество значений, содержащих одно значение корневого отношения и все вееры, доступные для него в соответствии со структурой иерархической базы данных.
Модель данных. Сетевая ● Основными компонентами стандартной сетевой модели являются записи и наборы данных. ● Тип записи – это структура, в которую помещаются конкретные значения данных. Каждый тип записи состоит из некоторого числа элементов данных, характеризующих свойства описываемого объекта, значения которых размещаются в экземплярах записи данного типа. В качестве связей между типами записей используются наборы данных. ● Тип набора – это поименованное отношение между типами записей. Каждому типу набора присваивается имя, что позволяет одной и той же паре типов объектов, участвовать в нескольких наборах данных. Сетевая модель данных представляется как множество отношений и веерных отношений. ● Сетевые базы данных разделяются на двухуровневые и многоуровневые сети. ● Ограничения двухуровневых сетей – каждое отношение может существовать в одной из следующих ролей: - Вне каких-либо веерных отношений; - В качестве основного отношения в любом числе веерных отношений; ● Запрещается существования в одном контексте в качестве зависимого и одновременно в качестве основного в другом контексте. ● В сетевой модели взаимосвязь M:N не может быть реализована непосредственно. Для этого используется дополнительный тип записи, с помощью которой образуется два набора данных. ● Существенное различие между сетевой и иерархической моделями данных состоит в том, что в сетевой модели каждая запись может участвовать в любом числе наборов и играть роль как владельца так и члена набора.
3. Диаграммы «сущность-связь» Типичной формой документирования информационной модели предметной области являются диа граммы "сущность-связь" (ER-диаграммы). ER-диаграмма позволяет графически представить все элементы информационной модели согласно простым, интуитивно понятным, но строго определенным правилам - нотациям. Сущность на ER-диаграмме представляется прямоугольником с именем в верхней части. Домены назначаются аналитиками и фиксируются в специальном документе - словаре данных. На стадиях разработки логической и физической моделей реляционной базы данных домены уточняются в сущностях на ER-диаграмме. Проектировщик базы данных должен тщательным образом изучить домены каждого атрибута с точки зрения их реализуемости в СУБД, с участием аналитиков внести в них изменения, если условие реализуемости не выполняется. При определении доменов проектировщик руководствуется следующим: - для реализации реляционной базы данных требуется использовать реляционную СУБД, например Oracle; - в большинстве реляционных СУБД в качестве языка манипулирования и описания данных используется диалект SQL, поддерживающий определенные стандарты, например ANSI SQL-92. Отношение (связь) сущностей на ER-диаграмме изображается линией, соединяющей эти сущности. Степень связи изображается с помощью символа *, указывающего на то, что в связи участвует много (N) экземпляров сущности, и одинарной горизонтальной чертой, указывающей на то, что в связи участвует один экземпляр сущности. Необязательный класс принадлежности изображается с помощью кружочка на линии отношения рядом с сущностью, обязательный класс принадлежности - с помощью вертикальной черты на линии отношения рядом с сущностью. Как правило, отношения на ER-диаграммах именуются с обеих сторон. Супертипы и подтипы, так же как и сущности, обозначаются на ER-диаграмме с помощью прямоугольников. Отношения между ними изображаются с помощью "вилки", имеющей в точке ветвления полукруг. Подтипы содержат только атрибуты, характерные для выделенных категорий.
4. Реляционные операции Классическая реляционная модель данных предусматривает использование восьми реляционных операций: объединение, пересечение, разность, декартово произведение, деление, проекция, соединение и выбор. Важно: Операции выполняются над отношением в целом, а не над отдельным кортежем отношения! Степень отношения - число входящих в него атрибутов или мощность схемы отношения. Мощность отношения есть число входящих кортежей или кардинальное число отношения. Два отношения называются совместными, если они имеют совместные схемы (совпадают схемы отношений и домены соответствующих атрибутов). Объединение отношений Пусть Qa, Qb, Qc - множество кортежей отношений А, B, С соответственно. Операция объединения выполняется над двумя совместными отношениями A и B. Результатом операции объединения является отношение C, которое включает в себя все кортежи отношения А и кортежи отношения B, отличные от кортежей отношения A. Таким образом, объединение отношений можно представить с помощью теоретико-множественной операции объединения: Пересечение отношений Операция пересечения выполняется над двумя совместными отношениями А и В. Результатом операции пересечения является отношение С, которое включает в себя кортежи отношения А, полностью совпадающие с кортежами отношения В. Таким образом, пересечение отношений можно представить с помощью теоретико-множественной операции пересечения: Разность отношений Операция разности выполняется над двумя совместными отношениями А и В. Результатом операции разности является отношение С, которое включает в себя кортежи отношения А, отличные от кортежей отношения В. Таким образом, разность отношений можно представить с помощью теоретико-множественной операции разности: Декартово произведение отношений Операция декартова произведения выполняется над двумя произвольными отношениями А и В. Результатом операции декартова произведения является отношение С, степень которого равна сумме степеней исходных отношений, а мощность - произведению мощностей исходных отношений. Таким образом, декартово произведение отношений можно представить с помощью декартова произведения множеств: Проекция отношения Операция проекции выполняется над одним отношением А. Результатом выполнения операции проекции над отношением А является отношение С, которое включает в себя все кортежи отношения А, но только с теми атрибутами, на которые выполняется проекция. Операцию проекции отношения можно представить следующим образом:
Деление отношений Операция деления выполняется над двумя отношениями А и В, где А - отношение-делимое, а B - отношение-делитель. При этом атрибуты B должны являться подмножеством атрибутов A. Результатом выполнения операции деления является отношение С, которое включает в себя атрибуты отношения А, отличные от атрибутов отношения В, и только те кортежи, декартовы произведения которых с отношением В дают отношение А:
Выбор из отношения Операция выбора (селекции) выполняется над одним отношением А. Результатом выполнения операции выбора является отношение С, которое включает в себя кортежи отношения А, удовлетворяющие заданному условию (критерию выбора). Операция выбора из отношения может быть представлена следующим образом:
где σ - обозначает операцию выбора, F - критерий выбора на множестве атрибутов в форме логического выражения, образованного с помощью определенных операндов (константы, имена атрибутов, арифметические операции сравнения, логические операции). Соединение отношений Операция q- соединения выполняется над двумя отношениями А и В. Результатом выполнения операции -соединения является отношение С, которое включает в себя все кортежи со всеми атрибутами исходных отношений А и В, удовлетворяющими заданному условию. В каждом отношении выделяется атрибут, по которому выполняется соединение. Операция соединения отношений может быть представлена следующим образом:
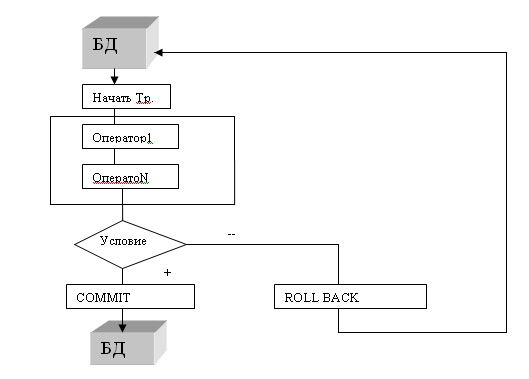
где n - степень отношения Q_a; ѳ - арифметический оператор сравнения; i, j - номера атрибутов в Q_a и Q_b соответственно, по которым выполняется соединение. 5. Понятие функциональной зависимости в данных Любое априорное знание об ограничениях предметной области, накладываемых на взаимосвязи между данными и значения данных, и знания об их свойствах и взаимоотношениях между ними может сыграть важную роль. Формализация таких априорных знаний о свойствах данных предметной области базы данных нашла свое отражение в концепции функциональной зависимости данных, т.е. ограничений на возможные взаимосвязи между данными, которые могут быть текущими значениями схемы отношений. Кортежи отношений могут представлять экземпляры сущности предметной области или фиксировать их взаимосвязь. Но даже если эти кортежи определены правильно, т.е. отвечают схеме отношения и выбраны из допустимых доменов, не всякий из них может быть текущим значением некоторого отношения. Пример: возраст человека редко бывает более 120 лет, или один и тот же пилот не может одновременно выполнять два различных рейса. Определение функции не накладывает никаких ограничений на множество аргументов и множество значений функции, кроме их существования и наличия соответствия между их элементами. Поскольку функциональную зависимость можно задать таблично, а таблица есть форма представления отношения, то становится очевидной связь между функциональной зависимостью и отношением. Отношение может задавать функциональную зависимость. Важной задачей при выявлении функциональных зависимостей на атрибутах отношения, которое по определению является множеством, является выяснение, какой из атрибутов выступает как аргумент, а какой - как значение ФЗ. Наиболее подходящими кандидатами в аргументы ФЗ являются возможные ключи, так как кортежи представляют экземпляры сущности, которые идентифицируются значениями атрибутов своего ключа. Нестрого говоря, функциональная зависимость имеет место на отношении, когда значения кортежа на одном множестве атрибутов однозначным образом определяют значения кортежа на другом множестве атрибутов. Для получения формального (строгого) определения наличия ФЗ в отношении нужно обратиться к реляционным операциям. Если семантика предметной области базы данных сложна, то проверить кортежи на принадлежность к ФЗ достаточно сложно. Сложно вообще установить наличие самой функциональной зависимости, отвечающей природе рассматриваемых данных. С помощью такого формального метода можно выявить ФЗ, которые не являются реальными и носят случайный характер. Проектировщику реляционных баз данных следует знать о таком методе проверки наличия ФЗ, но при проектировании новой базы данных его применение малоэффективно. Он может быть полезен при реинжиниринге существующей базы данных. Основные классы функциональных зависимостей Анализ связей между сущностями в предметных областях позволяет выделить различные классы функциональных зависимостей. Значения атрибутов могут зависеть от ключа по-разному. Различают классы полных и частичных ФЗ. ФЗ может быть частичной, когда значение неключевого атрибута зависит от значений некоторых атрибутов составного ключа, и полной, когда значения неключевого атрибута зависят от значений всех атрибутов составного ключа. Если неключевой атрибут зависит от части составного ключа, то говорят о частичной ФЗ. Выявление определенных функциональных зависимостей в отношениях базы данных позволяет преобразовать их с целью исключения избыточности и повышения надежности данных. Формирование схем отношений путем разбиения исходных отношений по их атрибутам с учетом функциональных зависимостей является одним из способов создания хороших схем реляционных баз данных. Анализ связей между сущностями в предметных областях позволяет определить, наряду с частичной и полной ФЗ, еще несколько классов ФЗ. Одним из таких классов является класс транзитивных ФЗ. Семантическая связь между атрибутами отношения может носить неоднозначный характер, это порождает существование класса многозначных зависимостей (MV-зависимостей). Многозначная зависимость может быть следующих типов: 1:N (один ко многим), M:1 (многие к одному) и M:N (многие ко многим). Разделение установленных функциональных зависимостей по различным отношениям может привести к нарушению принципа замкнутости реляционных операций, потере некоторых существующих кортежей или появлению мнимых кортежей. Поэтому есть необходимость выделения еще одного класса функциональных зависимостей - класса зависимостей по соединению (J-зависимостей). Этот класс ФЗ требует от ФЗ наличия свойства восстанавливаемости по своим проекциям с помощью естественного соединения. Аксиомы вывода функциональных зависимостей Для каждой базы данных на множестве ее отношений можно рассмотреть все возможные, допустимые в семантическом смысле функциональные зависимости. Для каждого отношения существует вполне определенное множество ФЗ между его атрибутами. На практике число рассматриваемых атрибутов и ФЗ конечно (!). Поскольку ФЗ являются высказываниями об атрибутах сущностей предметной области, то над ними могут быть определены операции, позволяющие логически получать одну зависимость из другой (или устанавливать между ними эквивалентность). Это позволяет определить для данной схемы базы данных базовый набор ФЗ, из которого может быть выведено все множество ФЗ, присущих этой схеме. Данное утверждение является важной конструктивной идеей в теории проектирования реляционных баз данных. 6. Нормализация отношений. 1НФ, 2НФ, 3НФ Нормализация отношений информационной модели предметной области является механизмом создания логической модели реляционной базы данных. С математической точки зрения задача построения как информационной модели предметной области, так и логической модели реляционной базы данных является результатом решения следующих комбинаторных задач: - группировка атрибутов в отношении предметной области; - распределение атрибутов по отношениям базы данных. Перечень наиболее важных требований при нормализации: - Первичные ключи отношений должны быть минимальными (требование минимальности первичных ключей). - Число отношений базы данных должно по возможности давать наименьшую избыточность данных (требование надежности данных). - Число отношений базы данных не должно приводить к потере производительности системы (требование производительности системы). - Данные не должны быть противоречивыми, т.е. при выполнении операций включения, удаления и обновления данных их потенциальная противоречивость должна быть сведена к минимуму (требования непротиворечивости данных). - Схема отношений базы данных должна быть устойчивой, способной адаптироваться к изменениям при ее расширении дополнительными атрибутами (требование гибкости структуры БД). - Разброс времени реакции на различные запросы к базе данных не должен быть большим (требование производительности системы). - Данные должны правильно отражать состояние предметной области базы данных в каждый конкретный момент времени (требование актуальности данных). Многие из требований находятся в противоречии друг к другу: Требование производительности находится в противоречии к требованию гибкости. Требование минимизировать число отношений в базе данных находится в противоречии к требованию надежности данных. Процесс устранения потенциальной противоречивости и избыточности данных в отношениях реляционной базы данных называется нормализацией исходных схем отношений. Нормализация отношений заключается в выполнении декомпозиции или синтеза отношений, назначении ключей отношений в соответствии с определенными правилами, гарантирующими целостность отношений базы данных. Таким образом, нормализация отношений является методом удаления из отношения ФЗ, которые приводят к аномалиям модификации данных. Нормализация отношений помогает проектировать реляционную базу данных, которая не содержит избыточных данных и гарантирует их целостность. Первая нормальная форма Отношение находится в первой нормальной форме (1НФ), если все атрибуты отношения являются простыми (требование атомарности атрибутов в реляционной модели), т.е. не имеют компонентов. Домен атрибута должен состоять из неделимых значений и не может включать в себя множество значений из более элементарных доменов. Вторая нормальная форма Атрибут отношения считается ключевым если он является элементом какого-либо ключа отношения. В противном случае атрибут будет считаться неключевым атрибутом. Отношение находится во второй нормальной форме, если оно находится в 1НФ, и все неключевые атрибуты отношения функционально полно зависят от составного ключа отношения. Иными словами, 2НФ требует, чтобы отношение не содержало частичных ФЗ. Третья нормальная форма Отношение находится в третьей нормальной форме (3НФ), если оно находится во 2НФ, и все неключевые атрибуты отношения зависят только от первичного ключа. Иными словами, 3НФ требует, чтобы отношение не содержало транзитивных ФЗ неключевых атрибутов от ключа. Возможна следующая проблема: Наличие транзитивной зависимости 7. Модель транзакции. Свойства транзакции В стандарте SQL определена следующая модель транзакции: 1. транзакция начинается с первого SQL -оператора; 2. последующие SQL -операторы составляют тело транзакции; 3. оператор COMMIT выполняется в случае успешного завершения обработки информации, объединенной в транзакцию; его выполнение фиксирует изменения, внесенные в базу данных текущей транзакцией; 4. оператор ROLLBACK (откат транзакции) прерывает выполнение транзакции и осуществляет отмену изменений, проведенных в ходе выполнения транзакции.
Любая из транзакций должна обладать четырьмя основными свойствами: - атомарности — это свойство означает: либо транзакция выполняется полностью, либо не выполняется совсем; - согласованности — это свойство гарантирует, что транзакция не нарушает согласованность данных; - изолированности — это свойство обеспечивает такую изолированность одной транзакции от другой, что промежуточные результаты незавершенной транзакции не доступны другой транзакции; - долговечности — это свойство гарантирует, что результаты зафиксированной транзакции не могут быть потеряны ни при каких обстоятельствах. Журнализация Возможность реализации транзакций предполагает способность системы сохранять промежуточные состояния базы данных, необходимые для отката транзакций. Сохранение требуемых состояний осуществляется посредством специального механизма, который называется журналом транзакций. Журнал транзакций — важнейшая часть СУБД — используется не только с целью обеспечения работы механизма транзакций. Он предназначен для поддержки одного из основных требований к СУБД: надежности хранения данных во внешней памяти. Для восстановления БД нужно располагать некоторой дополнительной информацией, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД. Журнал — это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: - так называемые мягкие сбои, характеризуемые внезапной потерей содержимого оперативной памяти, наступающие в результате внезапной остановки работы компьютера (например, аварийное выключение питания); - жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя); аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции. Если произошел мягкий сбой и содержимое буферов утрачено, для проведения восстановления базы данных необходимо иметь некоторое согласованное состояние журнала и базы данных во внешней памяти. При мягком сбое во внешней памяти основной части БД могут наблюдаться нежелательные ситуации двух типов: - присутствие объектов, модифицированных транзакциями, не закончившимися к моменту сбоя; - отсутствие объектов, модифицированных транзакциями, которые к моменту сбоя успешно завершились, но по причине использования буферов оперативной памяти не были помещены во внешнюю память. Во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций, и которое не содержало бы никаких следов незаконченных транзакций. Для восстановления после мягкого сбоя необходимо: • произвести откат незавершенных транзакций; • повторно воспроизвести те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Для восстановления БД после жесткого сбоя журнала изменений базы данных явно недостаточно. Основой восстановления последнего согласованного состояния базы данных после жесткого сбоя является журнал и архивная копия БД. Архивная копия — это полная копия БД к моменту начала заполнения журнала. 8. Проблемы многопользовательских систем. Блокировки В многопользовательских системах несколько одновременно работающих пользователей инициируют параллельные транзакции. При параллельной обработке транзакций возникает ряд проблем. Для того чтобы получить корректно работающую транзакцию, недостаточно написать ряд правильно составленных операторов манипулирования данными. При обработке правильно составленных операторов манипулирования данными транзакций возникают ситуации, которые могут привести к получению неправильного результата из-за взаимных помех среди некоторых транзакций, вызванных бесконтрольным чередованием операций из двух правильных транзакций. 1. Проблема потерянных результатов обновления.
Результат операции обновления, выполненной транзакцией А1, будет утерян, поскольку в момент времени t 4 она не будет учтена, и потому будет отменена операцией обновления, выполненной транзакцией А2. Что бы исключить такую ситуацию требуется, чтобы до завершения транзакции А1 никакая другая транзакция не могла изменять объект P. Отсутствие потерянных изменений является минимальным требованием к СУБД в области синхронизации параллельно выполняемых транзакций 2. Проблема несогласованных данных Данная проблема появляется, если помощью некоторой транзакции осуществляется извлечение (обновление) некоторого объекта, который в данный момент обновляется другой транзакцией, но это обновление еще не закончено. В таком случае в первой транзакции будут принимать участие данные, которые больше не существуют.
Транзакция А1 изменяет объект базы данных Р. Параллельно с этим транзакция А2, читая объект Р, видит, что он изменился, а значит нарушена целостность его транзакции. Произошло это потому, что транзакция А1 смогла изменить кортеж с данными, который прочитала транзакция А2. Поскольку операция изменения еще не завершена, транзакция А2 видит несогласованные данные. Чтобы избежать ситуации чтения несогласованных данных до завершения транзакции А1, изменившей объект Р, никакая другая транзакция не должна читать объект Р. 3. Проблема несовместимого анализа Возникает тогда, когда, например, транзакция А1 осуществляет вычисление некоторой статистической величины, скажем, среднего значения, а транзакция А2 выполняет обновление кортежа РЗ, который еще только будет использован транзакцией А1. Причем транзакция А1 не зависит от транзакции А2, так как транзакция А2 выполнила все обновления до того, как транзакция А1 извлекла кортеж РЗ
Для того, чтобы избежать подобных проблем, в СУБД должны использоваться какие-либо методы регулирования совместного выполнения транзакций. Эти методы должны опираться на следующие правила: - в ходе выполнения транзакции пользователь видит только согласованные данные; - результаты параллельно выполняемых транзакций должны быть такими же, как если бы вначале выполнялась одна транзакция, а потом — вторая. Реализация этих методов управления транзакциями в многопользовательской СУБД опирается на такие важные понятия, как: - сериализация транзакций и - сериальный план выполнения смеси транзакций. Блокировка Под сериализацией параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций — это такой план, который приводит к сериализации транзакций. Наиболее распространенным механизмом сериализации транзакций, который используется коммерческими СУБД, является механизм блокировок, или, иначе, механизм синхронизационных захватов, позволяющий разрешить описанные проблемы. Данная методика предполагает блокировку в течение некоторой транзакции тех объектов, которые на протяжении этой транзакции должны оставаться неизменными. Эффект блокировки состоит в том, чтобы заблокировать доступ к этому объекту со стороны других транзакций, а значит, предотвратить непредсказуемое изменение этого объекта. Различают два типа блокировок: Х-блокировка — блокировка без взаимного доступа (монопольная блокировка); S-блокировка — с взаимным доступом.   Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  ЧТО ПРОИСХОДИТ ВО ВЗРОСЛОЙ ЖИЗНИ? Если вы все еще «неправильно» связаны с матерью, вы избегаете отделения и независимого взрослого существования...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|










 не позволяет связать значения Y и Х, если не существует значения А, связанного со значением Y. Это затрудняет вставку и обновление данных, которые необходимо выполнить сразу для пары связей, а в случае удаления данных приводит к потере связи.
не позволяет связать значения Y и Х, если не существует значения А, связанного со значением Y. Это затрудняет вставку и обновление данных, которые необходимо выполнить сразу для пары связей, а в случае удаления данных приводит к потере связи.