
|
|
Выполнение в пакете STATISTICAВыполнить проверку гипотезы самостоятельно. Воспользоваться операциями со столбцами или процедурой Observed versus expected (наблюдаемые частоты против ожидаемых). 5. Проверка гипотезы о независимости признаков (таблица сопряженности признаков) Предположим, имеется большая совокупность объектов, каждый из которых обладает двумя признаками А и В; признак А имеет m уровней: A 1,..., Am, а признак В – k уровней: B 1,..., Bk. Пусть уровень Аi встречается с вероятностью P (Ai),а уровень Bj - c вероятностью P (Bj). Признаки А и В независимы, если
т.е. вероятность встретить комбинацию Ai Bj равна произведению вероятностей. Пусть признаки определены на n объектах, случайно извлеченных из совокупности; nij - число объектов, имеющих комбинацию Ai Bj,
всего (m - 1) + (k - 1); их оценки:
(в обозначениях точка означает суммирование по соответствующему индексу), и статистика (7.6) принимает вид
Если гипотеза Н верна, то по теореме Фишера f = mk - 1- (m -1)-(k -1) = (m -1)(k - 1). Поэтому, если
то гипотезу о независимости признаков следует отклонить. Ясно, что по (7.11) - (7.12) можно проверять независимость двух случайных величин, разбив диапазоны их значений на m и k частей. Пример 7.4. Данные, собранные по ряду школ, относительно физических недостатков школьников (P 1, P 2, P 3 - признак А) и дефектов речи (S 1, S 2, S 3 - признак В) приведены в табл. 7.4. В табл. 7.5 даны частоты. Таблица 7.4 Исходные данные
Для проверки гипотезы о независимости этих двух признаков вычислим статистику (7.11):
Это значит, что при независимых признаках вероятность получить значение такое же, как в опыте или большее, меньше 0,001, и потому гипотезу о независимости следует отклонить. Выполнение в пакете STATISTICA Образуем таблицу с двумя столбцами (P и S) и 217 строками и назовем ее Defects.sta (это действие опускаем, если данные уже есть в компьютере). Работаем в модуле Basic Statistics and Tables: Analysis ® Tables and banners - в окне Specify Table, в поле Analysis: Crosstabulation tables кнопка Specify Table - отбираем признаки: list 1: P, list 2: S - OK - OK - в окне Crosstabulation Tables Results (результаты таблиц сопряженности) отмечаем (потребуем определить) Expected frequencies (ожидаемые или теоретические частоты) и Pearson Chi-Square ® Review Summary tables. Таблица 7.5 Таблица частот
Наблюдаем две таблицы: таблицу частот Summary Frequency Table и Expected Frequencies; в верхней части последней указано значение Chi-square статистики (7.11), число степеней свободы df и уровень значимости р (вероятность в (7.12)). Поскольку значение р мало, гипотеза о независимости речевых и физических дефектов отклоняется. Замечание 1. Если бы исходные признаки Х, Y,... были не символьными, а числовыми, нужно было бы сначала их классифицировать: разбить диапазон значений на части, и для каждой ввести свой символ (например, х 1, х 2,..., y 1, y 2,...) введением дополнительных столбцов и использованием операции Recode ... (кнопка Vars или Edit ® Variables). Замечание 2. Если бы исходными данными являлась таблица частот, то анализ можно было провести в модуле Log - Linear Analysis (как в п.6).   ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 , (7.10)
, (7.10) . По совокупности наблюдений {n ij } (таблица m ´ k) требуется проверить гипотезу Н о независимости признаков А и В. Задача сводится к случаю с неизвестными параметрами; ими являются вероятности
. По совокупности наблюдений {n ij } (таблица m ´ k) требуется проверить гипотезу Н о независимости признаков А и В. Задача сводится к случаю с неизвестными параметрами; ими являются вероятности ,
, ,
, 
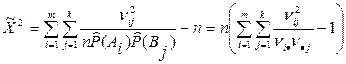 . (7.11)
. (7.11) асимптотически распределена по закону хи-квадрат с числом степеней свободы
асимптотически распределена по закону хи-квадрат с числом степеней свободы , (7.12)
, (7.12) .
.