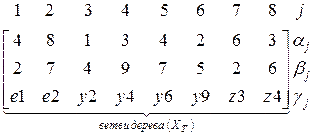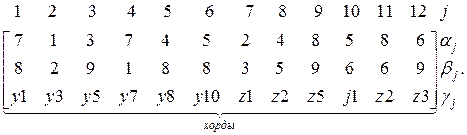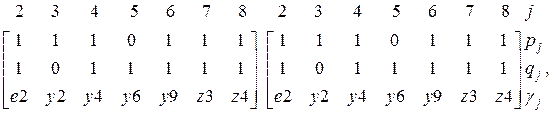|
|
МАШИННЫЕ АЛГОРИТМЫ ВЫБОРА ФУНДАМЕНТАЛЬНОГО ДЕРЕВА И ОПТИМАЛЬНОГО РАЗБИЕНИЯ ВЕТВЕЙАлгоритм выбора фундаментального дерева Обычно основные процедуры формирования исходных уравнений схемы (выбор фундаментального дерева, оптимальное разбиение ветвей, построение и преобразование матрицы сечений) реализуют на ЭВМ преобразованием структурной матрицы (§ 1.3). Так как размер этой матрицы по строкам определяется числом вершин v и по столбцам — числом ветвей l графа (υ∙ l ), причем она является сильно разреженной (коэффициент заполнения ненулевыми элементами равен 2l/υl = 2/υ), то в случае сложных схем использование полной структурной матрицы приводит к большой загрузке оперативной памяти. Среди множества возможных алгоритмов, позволяющих свести соответствующие процедуры к операциям на множествах вершин и ветвей графа, рассмотрим алгоритмы, основанные на теоретико-множественном подходе [119]. Структура графа определяется множеством его ветвей X={x1, х2,..., xl ), каждая из которых задается упорядоченной тройкой хi = (αi, βi, γi). где αi и βi — cooт-ветственно начальная и конечная вершины, а γi — код ветви х i (i=l, 2,..., l). Множество Vвершин графа представляется последовательностью v целых чисел, так что αi и βi — некоторые числа из V={1, 2,..., υ}, т. е. αi, βiЄV. Код γi содержит информацию о подмножестве, к которому относится ветвь x i и ее номера в этом подмножестве. Индекс i указывает на положение данной ветви в некоторой упорядоченной последовательности
ветвей графа. Например, у-ветвь с номером 8, направленная от вершины 23 к вершине 15 и расположенная двенадцатой в последовательности ветвей, запишется следующим образом: х12 = (23, 15, y8). Процедура формирования фундаментального дерева (ФФД) сводится к просмотру ветвей графа в установленной последовательности (иерархии) и их распределению между деревом и дополнением. Очередную ветвь вводят в дерево при условии, что она не образует контура с выбранной ранее совокупностью ветвей дерева. В результате множество X разбивают на два непересекающихся подмножества: подмножество ветвей дерева ХT и подмножество хорд XN. В промежуточной ситуации совокупность ветвей графа, отнесенных к дереву, образует некоторый (вообще несвязный) подграф (рис. 1.40,а). Множества вершин каждой его части совместно с одноэлементными множествами, содержащими не вошедшие в этот подграф вершины, образуют совокупность классов эквивалентности Vj и определяют на Множестве V соответствующие разбиения. Ясно, что ветвь x i должна быть отнесена к дереву, если и только если инцидентные ей вершины αi и βi принадлежат различным классам эквивалентности. Пусть αi В исходном положении все v классов эквивалентности содержат по одной вершине, т. е. имеем сначала полное разбиение множества вершин. Первая же рассматриваемая ветвь относится к дереву и представляет двухэлементный класс, объединяющий пару вершин, инцидентных этой дуге. В дальнейшем каждое включение ветви в дерево сопровождается объединением двух классов эквивалентности, так что при наличии в дереве q ветвей разбиение состоит из υ — q классов. Процесс формирования дерева заканчивают после того, как совокупность ветвей графа образует дерево — связный подграф, не содержащий контуров. Ему соответствует полное отношение эквивалентности, при котором множество всех вершин графа образует единственный класс. В случае, если граф схемы несвязный, конечное разбиение содержит столько же классов эквивалентности, сколько частей имеется в исходном графе, причем каждый из этих классов объединяет все вершины соответствующей части. При машинной реализации процедуры ФФД последовательные разбиения образуются идентификацией вершин на одномерном массиве, содержащем v ячеек, расположенных в той последовательности, которая принята при нумерации вершин. Так как любая вершина из данного класса может служить его представителем, то всем таким вершинам присваивается номер одной из них, который заносится в соответствующие ячейки. В исходном положении содержимое ячеек совпадает с их номерами, а в конечном — все ячейки для каждой части графа содержат одинаковые номера. При рассмотрении очередной ветви xi на массиве вершин содержимое ячеек считывается по адресам для αi и βi, в результате чего идентифицируются вершины в соответствующих классах эквивалентности, т. е. αi→ri, βi→si, где ri и s i — номера вершин, играющих роль представителей этих классов (рис. 1.40,б). При ri = si ветвь x i относится к дополнению (xi 1) все ли е-ветви вошли в дерево (е 2) все ли j-ветви вошли в дополнение (j 3) равно ли число ветвей дерева числу независимых сечений (lT=ν?). При утвердительных ответах процедура заканчивается. Наличие хотя бы одного отрицательного ответа свидетельствует о некорректности исходных данных или ошибке в операциях.
Алгоритм оптимального разбиения взаимно определенных ветвей Компонентные уравнения взаимоопределенных ветвей могут быть выражены как для токов, так и для напряжений, поэтому имеется некоторая свобода в распределении таких ветвей между подмножествами у и z. Это обстоятельство используют для дальнейшего сокращения координатного базиса оптимальным разбиением ay-ветвей, максимизирующим число образующихся вырожденных координат. Как видно из соотношения (1.172), каждая новая y-ветвь увеличивает число вырожденных координат μ на единицу, а объединение двух частей (е, у) -графа уменьшает эту величину на два. Таким образом, к y-ветвям следует относить прежде всего те до-ветви, которые не связывают отдельных частей (е, у) -графа. Ветви, объединяющие какие-либо две части (е, у) -графа, целесообразно относить к у-ветвям, если их число не меньше двух. В исходной последовательности ветвей графа до-ветви размещаются между подмножествами у и е. После применения процедуры ФФД к (е, у) -ветвям приходим к промежуточному разбиению на множестве вершин графа, при котором классы эквивалентности объединяют вершины соответствующих частей (е, у) -графа. Очевидно, ω-ветвь xjдолжна быть отнесена к y-ветвям в двух случаях: 1) если инцидентные ей вершины принадлежат к одному и тому же классу эквивалентности, т. е. αj, 2) если вершины принадлежат различным классам αj Процедуру ОР начинают с идентификации вершин всех до-ветвей в соответствии с разбиением множества V, которое образовалось после просмотра всех (е, у)- ветвей в процедуре ФФД. Для этого номера вершин αj и βj до-ветвей (j=1,..., lω) заменяют по схеме рис. 1.40,б содержимым соответствующих ячеек (представителями классов разбиения) массива вершин графа, т. е. осуществляется преобразование αj→rj; βj→sj (j=1, 2,..., lω). Сравнивая числа rj и s j, при rj=sj ветвь x j относят к y-ветвям (хj После такого упорядочения и исключения ветвей, которые перенесены к множеству y-ветвей, получаем модифицированный массив до-ветвей. На нем сравнивают до-ветви и при обнаружении первой же пары, отвечающей второму из приведенных условий, идентифицируют массив вершин (rj=sj). Затем процедуру ОР повторяют до тех пор, пока после очередного сравнения не будет обнаружено ни одной пары ветвей, идентифицированные вершины которых соответственно совпадают. В результате получаем разбиение ω-ветвей, исходный массив которых представляется в новой последовательности: сначала располагаются y-ветви, выделенные процедурой ОР, а за ними следуют остальные ω-ветви, которые относятся к z-ветвям. Преобразованные коды ω-ветвей заносятся в память и при необходимости выводятся на печать.
Алгоритм определения матрицы сечений Каждое сечение разбивает множество V вершин графа на два подмножества [108]. Одно из них V0k, называемое нижней областью, объединяет вершины, которые фундаментальное дерево связывает с начальной вершиной ветви k-го сечения. Другое подмножество V1k, называемое верхней областью, объединяет вершины, которые фундаментальное дерево связывает с конечной вершиной ветви k-го сечения (рис. 1.41). Очевидно, вершины инцидентной хорды должны принадлежать разным частям данного сечения, т. е. хорда xj = (αj, βj) инцидентна сечению k, если αi Это положение используют для получения подмножеств хорд, инцидентных сечениям k=1, 2,..., ν, причем совокупность таких подмножеств для всех сечений полностью определяет матрицу сечений π для хорд. Процедура определения матрицы сечений (ОМС) для данного k начинается с разбиения множества вершин V на подмножества V0k и V1k, в качестве представителей которых принимают соответственно числа 0 и 1. Предварительно в ячейку αk массива вершин графа заносят нуль, а в остальные ячейки — единицы, и на этом массиве поочередно считываются значения для вершин всех ветвей дерева, кроме k-й. ветви. Идентифицированные значения (ρj, qj) вершин (αj, βj) ветви дерева x j принимают значения 0 или 1. Если их сумма по модулю два ρj
вa процедуру повторяют до тех пор, пока очередной просмотр уже не изменяет разбиения на массиве вершин графа (признаком окончания разбиения вершин на нижнюю и верхнюю область является значение ω = 0). Следующий этап ОМС сводится к поочередному рассмотрению хорд и идентификации их вершин аj→ρj и βj→qj в соответствии с разбиением, полученным на предыдущем этапе. Очевидно, хорда x j инцидентна k-му сечению, если ρj ≠qj, причем она совпадает по направлению с сечением при ρj=0 и противоположна ему при ρj=1. По этим признакам код γj заносится в список инцидентных хорд с соответствующим знаком. Процедуру ОМС повторяют для всех сечений (k=l, 2,..., ν), причем каждый раз предварительно восстанавливается массив вершин (во все ячейки заносятся единицы). Признаком окончания этой процедуры является выполнение равенства k=v. Полученные в результате множества xh хорд, инцидентных сечениям k=l, 2,..., ν, позволяют построить матрицу сечений я (если она требуется). Для этого достаточно в k-й строке прямоугольной матрицы размера (ν∙σ) поставить ±1 в столбцах для хорд из xkс соответствующим знаком.
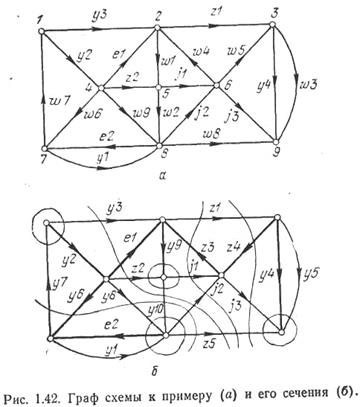
Пример формирования сокращенного координатного базиса Объединение процедур ФФД и ОР с процедурой ОМС составляет машинный алгоритм формирования сокращенного координатного базиса. В качестве примера рассмотрим граф (рис. 1.42,а), ветви которого xi=(αi, βi, γi) заданы в соответствии с установленной иерархией многомерным массивом
Идентификацию вершин при последовательном рассмотрении (е, у) -ветвей в процедуре ФД и соответствующие разбиения на массиве вершин графа представим следующим образом:
При i=l'=6 процедура ФФД прерывается и последнее разбиение используется для идентификации вершин ω-ветвей. Преобразование массива ω-ветвей в соответствии с процедурой ОР имеет вид





В результате получим разбиение с перекодировкой ω-ветвей и соответствующей перестановкой в исходной последовательности:
С учетом полученного разбиения ω-ветвей завершается процедура ФД:

 Таким образом, совместное применение процедур ФФД и ОР дает разбиение множества ветвей графа на подмножества ветвей дерева и хорд: Таким образом, совместное применение процедур ФФД и ОР дает разбиение множества ветвей графа на подмножества ветвей дерева и хорд:
Эти подмножества являются исходными для процедуры ОМС. Для сечения, определяемого ветвью дерева e1, имеем (k= 1)

Идентифицируя вершины хорд в соответствии с полученным разбиением массива вершин графа, получаем

Отсюда имеем множество инцидентных данному сечению хорд х1N={+у3, —y10, +z2, + z5, +j2}. Аналогично можно определить множества инцидентных хорд и для остальных сечений. На рис. 1.42,б ветви дерева отмечены жирными линиями. Особенность изложенного алгоритма состоит в том, что процесс формирования сокращенного координатного базиса сводится к операциям идентификации и сравнения на массивах ветвей и вершин графа, благодаря чему загрузка оперативной памяти составляет величину, равную примерно 2l ячеек. В то же время для размещения в памяти машины структурной матрицы потребовалось бы υl ячеек, т. е. больше в υ/2 раз. Для сложных схем это соотношение может быть значительным. Лекция 17.   Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  Что делать, если нет взаимности? А теперь спустимся с небес на землю. Приземлились? Продолжаем разговор... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|

 Vr, βi
Vr, βi  qj = 1, то на массиве вершин в ячейки для αj и βj заносятся нули. После просмотра всех ветвей дере
qj = 1, то на массиве вершин в ячейки для αj и βj заносятся нули. После просмотра всех ветвей дере