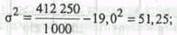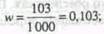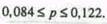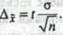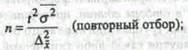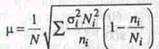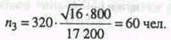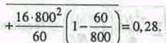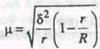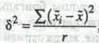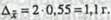|
|
Расчет средней общей (полезной) площади жилищ, приходящейся на 1 чел., и дисперсии
Продолжение
Средняя ошибка выборки составит:
Определим предельную ошибку выборки с вероятностью 0,954 (/=2):
Установим границы генеральной средней:
или
Таким образом, на основании проведенного выборочного обследования с вероятностью 0,954 можно заключить, что средний размер общей площади, приходящейся на 1 чел., в целом по городу лежит в пределах от 18,5 до 19,5 кв. м. При расчете средней ошибки собственно-случайной бесповторной выборки необходимо учитывать поправку на бесповторность отбора:
Если предположить, что представленные в табл. 8.4 данные являются результатом 5%-го бесповторного отбора (следовательно, генеральная совокупность включает 20 000 ед.), то средняя ошибка выборки будет несколько меньше:
Соответственно уменьшится и предельная ошибка выборки, что вызовет сужение границ генеральной средней. Особенно ощутимо влияние поправки на бесповторность отбора при относительно большом проценте выборки. Мы рассмотрели определение границ генеральной средней. Рассмотрим теперь, как определяются границы генеральной доли, т.е. границы доли единиц, обладающих тем или иным значением признака. Воспользуемся еще раз данными табл. 8.4 для того, чтобы определить границы доли лиц, обеспеченность жильем которых составляет менее 10 кв. м. Согласно результатам обследования, численность таких лиц составила 103 чел. Определим выборочную долю и дисперсию:
Рассчитаем среднюю ошибку выборки:
Предельнахюшнбка выборки с заданной вероятностью составит:
Определим границы генеральной доли:
или
Следовательно, с вероятностью 0,954 можно утверждать, что доля лиц, имеющих менее 10 кв. м жилья на человека, в целом по данному городу находится в пределах от 8,4 до 12,2%. Мы рассмотрели определение границ генеральной средней и генеральной доли по результатам уже проведенного выборочного наблюдения при известном объеме выборки или проценте отбора. На этапе же проектирования выборочного наблюдения именно объем выборочной совокупности и требует определения. Чем больше объем выборки, тем меньше значения средней и предельной ошибок выборочного наблюдения и, следовательно, тем уже границы генеральной средней и генеральной доли. В то же время необходимо учитывать, что большой объем выборки приводит к удорожанию обследования, увеличению сроков сбора и обработки материалов, требует привлечения дополнительного персонала и соответствующего материально-технического обеспечения. Поэтому при подготовке выборочного наблюдения необходимо определить тот минимально необ- ,300 водимый объем выборки, который обеспечит требуемую точность подученных статистических характеристик при заданном уровне вероятности. Представим формулу (8.4) следующим образом:
Отсюда можно вывести формулу для определения необходимого объема собственно-случайной повторной выборки:
Полученный на основе использования формулы (8.8) результат всегда округляется в большую сторону. Например, если необходимый объем выборки составляет 493,1 ед., то, обследовав 493 ед., мы не достигнем требуемой точности. Поэтому для достижения желаемого результата обследованием должны быть охвачены 494 ед. С другой стороны, рассчитанное значение необходимого объема выборки свободно может быть увеличено в большую сторону на несколько единиц. Если мы располагаем необходимыми ресурсами, если по причинам организационного порядка (компактность расположения единиц, фиксированная нагрузка на каждого регистратора и т.п.) мы вполне можем охватить больший объем, то включение в выборочную совокупность 500 или, например, 550 ед. только уменьшит значения полученных случайной и предельной ошибок. Как видно из формулы (8.8), необходимый объем выборки будет тем больше, чем выше заданный уровень вероятности и чем сильнее варьирует наблюдаемый признак. В то же время повышение допустимой предельной ошибки выборки приводит к снижению необходимого ее объема. Предположим, что в рассмотренном выше примере нас вполне устроят границы генеральной средней (средней площади, приходящейся на 1 чел.) с точностью 0,5 кв. м. Определим необходимый объем выборки:
Мы получили, что для определения с заданной точностью границ средней площади, приходящейся на 1 жителя, достаточно в порядке собственно-случайной повторной выборки обследовать 821 чел. Расчет необходимого объема выборки предполагает, что организаторы выборочного наблюдения уже на этапе его проектирования располагают по крайней мере косвенными данными о вариации изучаемых признаков. Источниками таких данных могут служить: • результаты обследования данного объекта в предшествующие периоды; • результаты обследования аналогичных объектов (жителей других населенных пунктов, предприятий других регионов и т.п.); • специально проведенное небольшое по объему выборочное обследование данного объекта, ставящее целью лишь изучение вариации наблюдаемых признаков. При определении необходимого объема выборки для определения границ генеральной доли задача оценки вариации решается значительно проще. Если дисперсия изучаемого альтернативного признака неизвестна, то можно использовать ее максимальное возможное значение:
Пример. Предприятию связи с вероятностью 0,954 необходимо определить удельный вес телефонных разговоров продолжительностью менее 1 мин. с предельной ошибкой 2%. Сколько разговоров нужно обследовать в порядке собственно-случайного повторного отбора для решения этой задачи? Для получения ответа на поставленный вопрос воспользуемся формулой (8.8) и будем ориентироваться на максимальную возможную дисперсию доли телефонных разговоров такой продолжительности. Расчет приводит к следующему результату:
Таким образом, обследованием должны быть охвачены не менее 2 500 разговоров на предмет их продолжительности. Необходимый объем собственно-случайной бесповторной выборки может быть определен по следующей формуле:
Формула (8.9) выводится из формулы (8.4) при условии расчета средней ошибки выборки с поправкой на бесповторность отбора. При определении границ генеральной доли в знаменатель этой формулы подставляется допустимая предельная ошибка доли Д. Пример. В табл. 8.4 представлены результаты 5%-го бесповторного выборочного обследования (следовательно, объем генеральной совокупности составляет 20 000 чел.). Воспользовавшись значением дисперсии, полученным на основе расчетов, произведенных в табл. 8.5, определим необходимую численность собственно-случайной бесповторной выборки для определения жилищных условий с предельной ошибкой, не превышающей 0,5 кв. м, при уровне вероятности 0,954:
Выполненный расчет показал, что для достижения заданной точности необходимо обследовать не менее 788 чел. Как и следовало ожидать, необходимая численность бесповторной выборки оказалась несколько меньше необходимой численности выборки при повторном отборе, полученной выше (821 чел.). Укажем на одну особенность формулы (8.9). При проведении вычислений объем генеральной совокупности должен быть выражен только в единицах, а не в тысячах или в миллионах единиц. Например, подставив в данную формулу общую численность населения резона, выраженную в тысячах человек, мы не получим правильного эначения необходимой численности выборки, также выраженной в тысячах человек, как это иногда бывает в других расчетах. Результат вычислений будет неверен. 8.4 МЕХАНИЧЕСКАЯ (СИСТЕМАТИЧЕСКАЯ) ВЫБОРКА Механическая выборка может быть применена в тех случаях, когда генеральная совокупность каким-либо образом упорядочена, т.е. имеется определенная последовательность в расположении единиц (табельные номера работников, списки избирателей, телефонные номера респондентов, номера домов и квартир и т.п.). Для проведения отбора желательно, чтобы все единицы также имели порядковые номера от 1 до N. Для проведения механической выборки устанавливается пропорция отбора, которая определяется соотнесением объемов выборочной и генеральной совокупностей. Так, если из совокупности в 500 000 ед. предполагается отобрать 10 000 ед., то пропорция отбора составит 1 / 50 = 1 / (500 000: 10 000). Отбор единиц осуществляется в соответствии с установленной пропорцией через равные интервалы. Например, при пропорции 1: 50 (2%-я выборка) отбирается каждая 50-я единица, при пропорции 1: 20 (5%-я выборка) - каждая 20-я единица и т.д. Интервал отбора также можно определить как частное от деления 100% на установленный процент отбора. Так, при 2%-м отборе интервал составит 50 (100%: 2%), при 4%-м отборе - 25 (100%: 4%). В тех случаях, когда результат деления получается дробным, сформировать выборку механическим способом при строгом соблюдении процента отбора не представляется возможным. Например, по этой причине нельзя сформировать 3%-ю или 6%-ю выборки. Генеральную совокупность при механическом отборе можно ранжировать или упорядочить по величине изучаемого или коррелирующего с ним признака, что позволит повысить репрезентативность выборки. Однако в этом случае возрастает опасность систематической ошибки, связанной с занижением значений изучаемого признака (если из каждого интервала регистрируется первое значение) или его завышением (если из каждого интервала регистрируется последнее значение). Поэтому целесообразно из каждого интервала отбирать центральную или одну из двух центральных единиц. При этом порядковый номер единицы, с которой начинается отбор, определяется следующим образом. Если интервал отбора обозначить как k, то номер первой отбираемой единицы будет равен (k + 1) / 2 при А-нечетном и k 1 2 или (k + 2) / 2 при А-четном. Например, при 5%-й выборке интервал отбора составит 20 единиц, тогда номер единицы, являющейся началом отбора, будет равен 20: 2 = 10 или (20 + 2): 2 = 11, т.е. отбор можно начинать с 10-й или с 11-й единицы. В первом случае в выборку попадут 10, 30, 50, 70 и с таким же интервалом последующие единицы; во втором случае попадут единицы с номерами 11,31,51,71 и т.д. Опасность систематической ошибки при механической выборке также может появиться вследствие случайного совпадения выбранного интервала и циклических закономерностей в расположении единиц генеральной совокупности. Так, при переписи населения 1989 г. в ходе 25%-го выборочного обследования семей была опасность попадания в выборку квартир только одного типа (например, только однокомнатных или только трехкомнатных), так как на лестничных площадках многих типовых домов располагаются именно по 4 квартиры. Чтобы избежать систематической ошибки, в каждом новом подъезде счетчик менял начало отбора. Для определения средней ошибки механической выборки, а также необходимой ее численности используются соответствующие формулы, применяемые при собственно-случайном бесповторном отборе, формулы (8.6) и (8.9). При этом, определив необходимую численность выборки и сопоставив ее с объемом генеральной совокупности, как правило, приходится производить соответствующее округление для получения целочисленного интервала отбора. Пример. В области зарегистрировано 6000 малых предприятий. Определим, сколько из них нужно отобрать в порядке механического отбора для определения средней численности занятых с ошибкой ±2 чел. (Р = 0,997). По результатам ранее проведенного обследования известно, что среднее квадратическое отклонение численности занятых составляет 9 чел. Произведем расчет, воспользовавшись формулой (8.9):
С учетом полученного необходимого объема выборки (177 предприятий) определим интервал отбора: 6 000:177=33,9. Определенный таким способом интервал всегда округляется в меньшую сторону, так как "Р" округлении в большую сторону произведенная выборка не Достигнет рассчитанного по формуле необходимого объема. Следовательно, в нашем примере из общего регистра малых предприятий необходимо отбирать каждое 33-е предприятие. При этом процент отбора составит 3,03% (100%: 33). 8.5 ТИПИЧЕСКАЯ (СТРАТИФИЦИРОВАННАЯ) ВЫБОРКА Типический отбор целесообразно использовать в тех случаях, когда все единицы генеральной совокупности объединены в несколько крупных типических групп. Такие группы также называют стратами, или слоями, в связи с чем типический отбор также называют стратифицированным, или расслоенным. При обследовании населения в качестве типических групп могут быть выбраны области, районы, социальные, возрастные или образовательные группы, при обследовании предприятий - отрасли или подотрасли, формы собственности и т.п. Рассматривать генеральную совокупность в разрезе нескольких крупных групп единиц имеет смысл только в том случае, если средние значения изучаемых признаков по группам существенно различаются. Например, с большой уверенностью можно предположить, что доходы населения крупного города будут в среднем выше доходов населения, проживающего в сельской местности; численность работников промышленного предприятия в среднем будет выше численности работников торгового или сельскохозяйственного предприятия; средний возраст студентов будет значительно ниже среднего возраста занятого населения, и тем более пенсионеров. В то же время нет никакого смысла при выделении типических групп ориентироваться на признак, не связанный или очень слабо связанный с изучаемым. Например, при изучении доходов населения вряд ли улучшению результатов выборочного обследования будет способствовать деление населения на группы на основе первой буквы фамилии, так как маловероятно, что доходы людей, чья фамилия начинается с букв в интервале от А до К, будут существенно выше или ниже доходов лиц, носящих фамилию, начинающуюся с букв в интервале Л-Я. Отбор единиц в выборочную совокупность из каждой типической группы осуществляется собственно-случайным или механическим способом. Поскольку в выборочную совокупность в той или иной пропорции обязательно попадают представители всех групп, типизация генеральной совокупности позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. В то же время в выделенных типических группах обследуются далеко не все единицы, а только включенные в выборку. Следовательно, на величину по- пученной ошибки будет влиять различие между единицами внутри этих групп, т.е. внутригрупповая вариация. Поэтому ошибка типической выборки будет определяться величиной не общей дисперсии, а только ее части - средней из внутригрупповых дисперсий. Отбор единиц в типическую выборку может быть организован либо пропорционально объему типических групп, либо пропорционально внутригрупповой вариации (дифференциации) признака. При типической выборке, пропорциональной объему типических групп, число единиц, подлежащих отбору из каждой группы, определяется следующим образом:
где Ni, - объем (-и группы; ni, - объем выборки из»'-й группы. Пример. Общая численность населения области составляет 1 млн чел., в том числе городского - 600 тыс. чел. и сельского - 400 тыс. чел. Если в ходе выборочного наблюдения планируется обследовать '50 тыс. жителей, то эта численность должна быть поделена пропорционально объему типических групп: городское население - Пг = 50 000————— = 30 000 чел.; • 1000000 сельское население - п„ = 50 000———— = 20 000 чел. с 1000000 Процесс формирования данной выборки представлен на рис. 8.3. Средняя ошибка типической выборки определяется по формулам:
где сигма в2 - средняя из dнутригрупповых дисперсий.
Рис. 8.3. Процесс формирования типической выборки, пропорциональной объему типических групп Рассмотрим данный вариант типической выборки на условном примере. Пример. 10%-й бесповторный типический отбор работников предприятия, пропорциональный размерам цехов, проведенный с целью оценки потерь из-за временной нетрудоспособности, привел к следующим результатам (табл. 8.6). Таблица 8.6J Результаты обследования работников предприятия
Рассчитаем среднюю из внутригрупповых дисперсий:
Определим среднюю и предельную ошибки выборки (с вероятностью 0,954):,,
Рассчитаем выборочную среднюю:
В результате проведенных расчетов с вероятностью 0,954 можно сделать вывод, что среднее число дней временной нетрудоспособности одного работника в целом по предприятию находится в пределах: 14,6-0,58 ^х<, 14,6+0,58. При определении необходимого объема типической выборки в рассмотренных выше формулах (8.11) и (8.12) общую дисперсию на-блкэдаемого признака необходимо заменить на среднюю из внутригрупповых дисперсий. Тоща данные формулы примут следующий вид:
(бесповторный отбор). Предположим, в рассмотренном выше примере нам необходимо определить среднее число дней временной нетрудоспособности одного работника с предельной ошибкой 0,5 дня. Учитывая величину Полученной ранее средней из внутригрупповых дисперсий определим необходимый объем типической выборки при условии бесповторного отбора:
Таким образом мы получили, что при заданных условиях для достижения требуемой точности необходимо обследовать выборочным методом не менее 421 чел. Распределим эту численность на три цеха рассматриваемого предприятия пропорционально их размерам:
Расчеты показывают, что в 1 -м цехе необходимо обследовать 132 чел., во 2-м цехе - 184 чел. и в 3-м цехе - 105 чел. Мы рассмотрели типический отбор, пропорциональный объему типических групп. Второй вариант формирования типической выборки заключается в отборе единиц, пропорциональном вариации признака в типических группах. Логика такого отбора заключается в следующем: если внутри какой-либо типической группы наблюдаемый поизнак варьирует слабо, то для определения границ генеральных характеристик из данной группы достаточно обследовать относительно небольшое число единиц; при сильной же вариации признака объем выборки должен быть соответственно увеличен. При выборке, пропорциональной вариации признака, число наблюдений по каждой группе рассчитывается по формуле:
где О, - среднее квадратическое отклонение признака в i-й группе. Средняя ошибка такого отбора определяется следующим образом:
(повторный отбор);
(бесповторный отбор). (8.17) Отбор, пропорциональный вариации признака, дает лучшие результаты, однако на практике его применение затруднено из-за трудности получения сведений о вариации до проведения выборочного наблюдения. Воспользуемся данными, приведенными в табл. 8.6, для иллюстрации этого способа выборочного наблюдения. Пример. Используя имеющиеся значения внутригрупповых дисперсий, определим необходимый объем выборки по каждому цеху, пропорциональный вариации изучаемого признака, при условии, что в целом выборка составляет 10%, или 320 чел.:
С учетом полученных значений рассчитаем среднюю ошибку выборки:
В данном случае средняя, а следовательно, и предельная ошибки будут несколько меньше, что отразится и на границах генеральной средней. 8.6 СЕРИЙНАЯ ВЫБОРКА Сущность серийной выборки заключается в собственно-случайном либо механическом отборе групп единиц (серий), внутри которых производится сплошное обследование. Единицей отбора при этой выборке является группа или серия, а не отдельная единица генеральной совокупности, как это имело место в рассматриваемых ранее выборках. Данный способ отбора удобен в тех случаях, когда единицы генеральной совокупности изначально объединены в небольшие более или менее равновеликие группы или серии. В качестве таких серий могут выступать упаковки с определенным количеством готовой продукции, партии товара, студенческие группы, бригады и другие подобные объединения. Например, в Великобритании серийный отбор используется в обследованиях населения, когда серией являются домохозяйства, объединенные общим почтовым индексом. В случайном порядке производится выборка индексов, и под обследование попадают все домохозяйства, имеющие индекс попавших в выборочную совокупность почтовых отделений. В отдельных случаях серийная выборка имеет не столько методологические, сколько организационные преимущества перед другими способами формирования выборочной совокупности. Например, Управление маркетинга и регионального развития Московского государственного университета экономики, статистики и информатики периодически проводит обследования школьников Москвы. С организационной точки зрения достаточно сложно опрашивать отдельных учеников из разных классов. Значительно проще из общего списка всех классов всех школ округа сформировать выборку классов, а внутри отобранных классов провести 100%-е обследование учащихся. В связи с тем что при серийном отборе внутри отобранных групп обследуются все без исключения единицы, внутригрупповая вариа-; ция признака не отразится на ошибках выборочного наблюдения. В то же время обследуются не все группы, а только попавшие в выборку. Следовательно, на ошибках получаемых характеристик отразятся различия между группами, которые определяются межгрупповой дисперсией. Поэтому средняя ошибка серийной выборки рассчитывается по формулам
(повторный отбор);
(бесповторный отбор), (8.19) где r - число отобранных серий; R - общее число серий. Межгрупповую дисперсию при равновеликих группах вычисляют следующим образом:
где х^ - средняя 1-й серии; х - общая средняя по всей выборочной совокупности. Пример. Предположим, партия готовой продукции предприятия упакована в 200 коробок по 50 изделий в каждой. В целях контроля соблюдения параметров технологического процесса проведена 5%-я серийная выборка, в ходе которой отбиралась каждая 20-я коробка. Все изделия, находящиеся в отобранных упаковках, были подвергнуты сплошному обследованию, заключавшемуся в определении их точного веса. Полученные результаты представлены в табл. 8.7. Таблица 8.7 Результаты выборочного обследования готовой продукции
С вероятностью 0,954 требуется определить границы среднего веса изделия во всей партии. На основе приведенных в таблице внутригрупповых средних определим средний вес изделия по выборочной совокупности:
С учетом полученной средней рассчитаем межгрупповую дисперсию:
Рассчитаем среднюю и предельную ошибки выборки: -i^na
Определим границы генеральной средней: 999,8-1,1 <x<999,8+l,l. На основе результатов проведенных расчетов с вероятностью 0,954 можно утверждать, что средний вес изделия в целом по всей партии продукции находится в пределах от 998,7 г до 1000,9 г. Для определения необходимого объема серийной выборки при заданной предельной ошибке используются следующие формулы:
(повторный отбор); (8.21)
(бесповторный отбор). (8.22) Предположим, в рассмотренном выше примере необходимо определить границы среднего веса изделия с предельной ошибкой +-0,5 г. Используя полученные выше данные о вариации веса, определим, сколько коробок с изделиями нужно обследовать в порядке бесповторной серийной выборки, чтобы получить результат с заданной точностью и при выбранном уровне вероятности:
Выполненный расчет позволяет заключить, что для получения границ генеральной средней с заданной точностью необходимо обследовать не менее 18 коробок с изделиями, отобранных собственно-случайным или механическим способом. 8.7 ПРАКТИКА ПРИМЕНЕНИЯ ВЫБОРОЧНОГО НАБЛЮДЕНИЯ В СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ ИССЛЕДОВАНИЯХ В настоящее время выборочное наблюдение находит достаточно широкое применение в обследованиях промышленных и сельскохозяйственных предприятий, изучении цен на потребительском рынке, в обследованиях бюджетов и занятости населения'. Выборочный метод является важнейшим источником информации в маркетинговых и социологических исследованиях, в контроле качества продукции; разработаны методологические подходы к применению выборочного наблюдения в аудите. Остановимся на рассмотрении некоторых из указанных областей применения выборки. При статистическом наблюдении за деятельностью предприятий в качестве основы выборки используются данные, содержащиеся в Едином государственном регистре предприятий и организаций, который ведется Государственным комитетом Российской Федерации по статистике, в регистрах ряда других ведомств, в частности, налоговых органов. В большей степени методы выборочного наблюдения используются для изучения деятельности малых предприятий, при этом наблюдаются как стоимостные экономические показатели (объем производства, продаж, инвестиций), так и показатели деловой активности (оценка текущего состояния предприятия, спрос на продукцию, прогноз на ближайшую перспективу). Обследование проводится ежеквартально по форме федерального государственного статистического наблюдения № ПМ «Сведения об основных показателях деятельности малого предприятия». Объектом наблюдения является совокупность субъектов малого предпринимательства или малых предприятий, классификационные признаки которых определены в законодательном порядке. Обследование малых предприятий проводится на основе много-мерной типической (расслоенной) выборки, при этом расслоение генеральной совокупности осуществляется по следующим признакам: • по территории (79 слоев); • по отраслям (63 слоя); • по формам собственности (4 слоя); • по объему выручки (5 слоев). Общий объем выборочной совокупности не превышает 20% совокупности генеральной. Одной из проблем при проведении выборочного наблюдения является проблема так называемых неответов, когда попавшая в выборку единица (респондент) по тем или иным причинам не отвечает на часть вопросов или даже на все вопросы, представленные в формуляре. Эта проблема проявляется и при наблюдении за деятельностью малых предприятий. Вся совокупность неответивших респондентов делится на три группы: • предприятия, прекратившие иди приостановившие свою деятельность; • предприятия, ведущие финансово-хозяйственную деятельность; • предприятия, по которым нет объективной информации, функционируют они или нет. Первая группа предприятий исключается из выборочной совокупности. Для восстановления данных по предприятиям второй группы применяется метод перевзвешивания: неответившему предприятию присваивается значение изучаемого показателя, соответствующее его среднему значению по слою (группе), к которому это предприятие принадлежит. Для восстановления данных по предприятиям третьей группы используется метод заполнения случайным подборам в классах замещения (random hot deck within classes): неответившему предприятию присваиваются значения наблюдаемых признаков, взятых у предприятия-донора. Предприятие-донор выбирается в случайном порядке из предприятий, входящих в соответствующий класс замещения (отрасль экономики). Одной из конечных задач проведения выборочного наблюдения, в том числе и наблюдения за деятельностью малых предприятий, является получение (оценка) суммарных значений наблюдаемых признаков по всей генеральной совокупности - общей выручки, общего объема производства, общего объема инвестиций и т.д. Для решения этой задачи применяется метод прямого пересчета. Сущность этого метода заключается в умножении среднего значения признака, полученного в результате выборочного наблюдения, на объем генеральной совокупности. При выборочном наблюдении за деятельностью малых предприятий методом прямого пересчета получают суммарные значения наблюдаемых признаков по всем выделенным слоям. Основные задачи выборочного обследования бюджетов домашних хозяйств состоят в получении статистических данных о распределении населения по уровню материального благосостояния, данные об уровне бедности и потребления продуктов питания. На основе результатов наблюдения определяют весовые коэффициенты для расчета индекса потребительских цен и получают необходимые данные для составления счетов сектора домашних хозяйств в системе национальных счетов. Генеральная совокупность объединяет все типы домашних хозяйств, за исключением коллективных (больницы, дома-интернаты, школы-интернаты, монастыри и т.п.). Обследование проводится в каждом регионе РФ на основе двухступенчатой случайной выборки с использованием процедуры расслоения на каждой из ступеней отбора. На первой ступени проводится территориальное расслоение населения по месту проживания, т.е. население делится на городское и сельское. На второй ступени каждый слой делится на несколько подслоев по следующим признакам: • по размеру домохозяйства, т.е. числу его членов (7 слоев - 1 чел., 2 чел.,..., 7 и более чел.); • по принадлежности жилого помещения (2 слоя - государственное и частное); • по типу жилого помещения (3 слоя - отдельная квартира, коммунальная квартира или общежитие, съемное жилье); • по наличию (отсутствию) в пользовании земельного участка (2 слоя). При распространении итогов выборочного наблюдения бюджетов домохозяйств на генеральную совокупность применяется метод взвешивания, при этом используются данные микропереписи населения 1994 г. о распределении домохозяйств по составу. Каждому обследованному домохозяйству k-ro видау-го слоя присваивается статистический вес, характеризующий распространение данного вида домохозяйств в генеральной совокупности. Веса определяются по следующей формуле:
удельный вес числа членов домашних хозяйств k-ro вида j-ro слоя в общей численности населения, обследованного в рамках микропереписи 1994 г.;
численность населенияу-го слоя по данным текущей статистики;
©2015- 2026 zdamsam.ru Размещенные материалы защищены законодательством РФ.
|