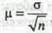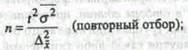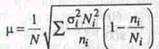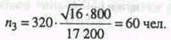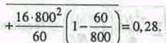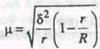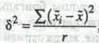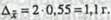|
|
Результаты выборочного обследования жилищных условий жителей городаСтр 1 из 10Следующая ⇒ Таблица 8.1 Варианты повторной выборки из генеральной совокупности
Средняя ошибка выборки представляет собой среднее квадрати-ческое отклонение выборочных средних относительно генеральной средней:
где k - число всех возможных выборок данного объема из генеральной совокупности. Определим подкоренное выражение этой формулы, т.е. дисперсию выборочных средних:
Между дисперсией выборочных средних и дисперсией изучаемо» го признака в генеральной совокупности следующая взаимосвязь:
Для нашего примера получим:
Таким образом, среднюю ошибку выборки можно представить как
При проведении выборочного наблюдения дисперсия изучаемого признака в генеральной совокупности, как правило, неизвестна. В то же время между генеральной дисперсией и средней из всех возможных выборочных дисперсий существует следующее соотношение:
В связи с тем, что на практике в большинстве случаев из генеральной совокупности в определенный момент времени производится только одна выборка, дисперсия изучаемого признака по этой выборке и используется при расчете ошибки. Учитывая, что при достаточно большом объеме выборки отношение п 1 п -1 близко 1, формула средней ошибки повторной выборки принимает следующий вид:
где д2 - дисперсия изучаемого признака по выборочной совокупности. При определении возможных границ значений характеристик генеральной совокупности рассчитывается предельная ошибка выборки, которая зависит от величины ее средней ошибки и уровня вероятности, с которым гарантируется, что генеральная средняя не выйдет за указанные границы. Согласно теореме A.M. Ляпунова, вероятность той или иной величины предельной ошибки, при достаточно большом объеме выборочной совокупности, подчиняется нормальному закону распределения и может быть определена на основе интеграла Лапласа:
Значения интеграла Лапласа при различных t приведены в приложении 1. При обобщении результатов выборочного наблюдения наиболее часто используют следующие уровни вероятности и соответствующие им значения /:
Например, если при определении предельной ошибки выборки мы используем / = 2, то с вероятностью Р = 0,954 можно утверждать, что расхождение между выборочной и генеральной средними не превысит двухкратной величины рассчитанной средней ошибки выборки. Расчет ошибок при определении границ генеральной доли, т.е. доли единиц, обладающих тем или иным вариантом изучаемого признака, основан на теореме Бернулли. Согласно этой теореме, вероятность сколь угодно малого расхождения между выборочной долей и генеральной долей при достаточно большом объеме выборки будет стремиться к единице. С учетом того, что вероятность расхождения между выборочной и генеральной долями подчиняется нормальному закону распределения, при определении предельной ошибки выборочной доли также используется функция F(t) при заданном значении (. В целом процесс подготовки и проведения выборочного наблюдения включает ряд последовательных этапов, представленных на рис.8.2. В зависимости от состава и структуры генеральной совокупности выбирается вид выборки, или способ отбора. К наиболее распространенным на практике видам относятся: • собственно-случайная (простая случайная) выборка; • механическая (систематическая) выборка;
Рис. 8.2. Этапы проведения выборочного наблюдения • типическая (стратифицированная, расслоенная) выборка; • серийная (гнездовая) выборка. Отбор единиц из генеральной совокупности может быть комбинированным, многоступенчатым и многофазным. Комбинированный отбор предполагает объединение нескольких видов выборки. Так, например, можно комбинировать типическую и серийную, серийную и собственно-случайную выборки. Ошибка такой выборки определяется ступенчатостью отбора. Многоступенчатым называется отбор, при котором из генеральной совокупности сначала извлекаются укрупненные группы, потом -более мелкие и так до тех пор, пока не будут отобраны те единицы, которые подвергаются обследованию. В отличие от многоступенчатой многофазная выборка предполагает сохранение одной и той же единицы отбора на всех этапах его проведения; при этом отобранные на каждой стадии единицы подвергаются обследованию (программа обследования на каждой последующей стадии отбора расширяется). Любой вид выборки или их комбинация предполагает использование тех или иных методов непосредственного отбора единиц (групп единиц), основанных на специальных алгоритмах, реализующих принцип случайности. Рассмотрению этих методов и посвящен раздел 8.2. 8.2 МЕТОДЫ (АЛГОРИТМЫ) ОТБОРА ЕДИНИЦ В ВЫБОРОЧНУЮ СОВОКУПНОСТЬ Процесс формирования выборочной совокупности основан на принципе случайности, реализация которого обеспечивается применением соответствующих методов, или алгоритмов, отбора единиц'. В простейшем варианте отбор единиц в выборочную совокупность может быть проведен методом жеребьевки. Для этого необходимо располагать достаточным количеством жребиев (фишек, карточек), соответствующих объему генеральной совокупности. Каждый жребий должен содержать информацию об отдельной единице совокупности -номер, название, фамилию лица, адрес или какой-либо другой отличительный признак. Требуемое в соответствии с установленным процентом отбора число жребиев извлекается из общей совокупности в случайном порядке. Жеребьевка является в большей степени теоретическим методом формирования выборки, так как ее техническая реализация при большом объеме генеральной совокупности затруднительна. Используемые же на практике методы отбора единиц в выборочную совокупность базируются на специальных алгоритмах, реализующих принцип случайности. Рассмотрим некоторые из них. Метод случайной сортировки включает три шага: 1. Каждой единице генеральной совокупности присваивается случайное число и, полученное с помощью процессора случайных чисел В данном случае мы не рассматриваем менее распространенные методы нс-равновероитностного, или направленного, отбора. 289 в интервале от 0 до 1 (полученные случайные числа должны в той или иной степени соответствовать закону равномерного распределения). Отметим, что генерация случайных чисел может быть произведена в Microsoft Excel (Вставка функции - Математические - Случайное число). 2. Единицы генеральной совокупности ранжируются в соответствии с полученным значением и. 3. Отбираются п первых единиц. Достоинства данного метода заключаются в простом алгоритме отбора единиц, а также в возможности формирования нескольких выборок без перекрытия. К недостатку данного метода относят наличие процедуры сортировки единиц генеральной совокупности, которая при достаточно большом ее объеме нежелательна. Метод прямой реализации предполагает следующую последовательность действий: 1. Все единицы генеральной совокупности, расположенные в случайном порядке или ранжированные по какому-либо признаку, нумеруются от 1 до N. 2. С помощью процессора случайных чисел получают п значений в интервале от 1 до N. Если первоначально случайные числа получены в интервале от 0 до 1, их необходимо умножить на N и округлить по правилам до целого значения. 3. Из сформированного списка единиц генеральной совокупности отбираются единицы, соответствующие по номеру полученным случайным числам. Отметим, что если полученные в п. 2 случайные числа ранжировать, то реализация данного алгоритма потребует только одного считывания файла единиц генеральной совокупности. Упрощенным вариантом метода прямой реализации является отбор единиц в выборочную совокупность на основе таблицы случайных чисел (см. приложение 15). Для проведения отбора могут быть использованы цифры любого столбца данной таблицы, при этом необходимо учитывать объем генеральной совокупности. Рассмотрим процедуру отбора на основе фрагмента таблицы случайных чисел. Предположим, объем генеральной совокупности составляет 70 000 ед. и требуется сформировать выборку объемом 500 ед.; тогда цифры таблицы следует перегруппировать для получения пятизначных чисел следующим образом:
Для формирования выборки мы должны взять 500 чисел в интервале от 00 001 до 70 000. Таким образом, нам следует из списка единиц генеральной совокупности отобрать единицы под номером 54 895, 35 220, 57 593 и т.д. При этом номера свыше 70 000 (75 557, 93 578 и подобные) будут проигнорированы. При проведении бесповторного отбора повторяющиеся номера следует учитывать только один раз. При повторном отборе, если тот или иной номер случайно встретится еще один или более раз, соответствующая этому номеру единица в каждом случае повторно включается в выборочную совокупность. Метод отбора-отказа включает следующие итерации: • последовательно образуют случайные числа Up у,... в соответствии с законом равномерного распределения в интервале от 0 до 1; • для первой единицы генеральной совокупности проверяется выполнение следующего неравенства:
Если данное неравенство выполняется, то первая единица включается в выборку, в противном случае - нет; • для оставшихся единиц последовательно проверяется выполнение неравенства
где д^ - число отобранных в выборку единиц среди первых Л; просмотренных единиц. Если для (А+1)-й единицы это неравенство выполняется, то данная единица включается в выборку, в противном случае - нет; • процедура заканчивается, когда п^ = п, т. е. когда выборка необходимого объема полностью сформирована. Этот момент вполне может наступить и до завершения полного просмотра всех единиц генеральной совокупности. Следует отметить, что данный метод основан на алгоритме последовательного извлечения единиц, не требующем ни предварительной сортировки единиц генеральной совокупности или образованных случайных чисел, ни многократного считывания исходного файла. Рассмотрим на условных примерах, как действует метод отбора-отказа и докажем, что положенный в его основу алгоритм действительно приводит к формированию выборки требуемого объема вне зависимости от значений получаемых случайных чисел. Пример. Требуется сформировать выборку объемом 100 единиц из генеральной совокупности объемом 1000 единиц, т.е. п = 100 и i N= 1000.: Предположим, на 1-м шаге для совокупности А образованное слу-, чайное число составило 0,03, тогда неравенство (8.1) выполняется, так как
и 1-я единица генеральной совокупности будет включена в совокупность выборочную. Допустим теперь, что значения последующих случайных чисел по той или иной причине также не превысили 0,1 (см. графу 1 табл. 8.2). Результаты проверки выполнения неравенства (8.2) для соответствующих единиц генеральной совокупности представлены в графах 2 и 3 табл. 8.2. На 2-м шаге из первых 2 единиц обе были включены в выборку, на 3-м шаге - из первых 3 единиц все три были включены в выборку, и так далее до 100-го шага, на котором из первых 100 единиц генеральной совокупности все 100 вошли в совокупность выборочную. Начиная со 101-го шага, числитель дроби в правой части неравенства (8.2) становится равным нулю, а следовательно, и вся дробь также равна нулю. Тогда, какими бы малыми ни были случайные числа, образованные для оставшихся 900 единиц генеральной совокупности, они не могут быть Таблица 8.2 Реализация метода отбора-отказа для совокупиости А
меньше нуля, и поэтому ни одна из этих единиц не войдет в выборочную соовокупностъ. Таким образом, в результате реализации данного метода была сформирована требуемая выборка объемом 100 единиц. Предположим теперь, что для 1-й единицы такой же по объему совокупности Б (N= 1000) образованное случайное число составило 0,91. Тогда при формировании выборки п = 100 получим:
и, следовательно, 1-я единица генеральной совокупности не будет включена в выборочную совокупность. Допустим, что последующие полученные случайные числа по той или иной причине имеют относительно большие значения (см. графу 1 табл. 8.3). Соответствующая таким значениям процедура реализации метода отбора-отказа представлена в графах 2 и 3 табл. 8.3. Таблица 8.3 Реализация метода отбора-отказа для совокупности Б
Продолжение
Итак, если допустить, что по случайным причинам для первых 900 ед. генеральной совокупности условие включения в выборку не выполнялось, то, начиная с 901-й единицы, ситуация принципиально меняется. Правая часть неравенства (8.2) становится равной 1, и 901-я единица генеральной совокупности включается в выборку при любом значении присвоенного ей случайного числа. Далее на каждом шаге числитель и знаменатель правой части неравенства пропорционально уменьшаются, и поэтому значение дроби в целом остается неизменным, т.е. постоянно равным 1. Вследствие этого, вне зависимости от полученных значений случайных чисел, оставшиеся 99 ед. генеральной совокупности войдут в выборочную совокупность и требуемый объем выборки будет обеспечен. Мы рассмотрели принцип работы метода отбора-отказа и показали, что при любых условиях положенный в его основу алгоритм приведет к формированию выборки желаемого объема. Наилучшие же результаты, безусловно, будут получены тогда, когда генерируемые случайные числа подчиняются закону равномерного распределения. Методы отбора единиц в выборочную совокупность используются при различных способах (видах) выборки, которые рассмотрены в последующих разделах. 8.3 СОБСТВЕННО-СЛУЧАЙНАЯ (ПРОСТАЯ СЛУЧАЙНАЯ) ВЫБОРКА Собственно-случайная выборка заключается в отборе единиц из генеральной совокупности в целом, без разделения ее на группы, подгруппы или серии отдельных единиц. При этом единицы отбираются в случайном порядке, не зависящем ни от последовательности расположения единиц в совокупности, ни от значений их признаков. Прежде чем производить собственно-случайный отбор, необходимо убедиться, что все без исключения единицы генеральной совокупности имеют абсолютно равные шансы попадания в выборку, в списках или перечне отсутствуют пропуски, нет игнорирования отдельных единиц и т.п. Следует также установить четкие границы генеральной совокупности таким образом, чтобы включение или невключение в нее отдельных единиц не вызывало сомнений. Так, например, при обследовании торговых предприятий необходимо указать, включит ли генеральная совокупность торговые павильоны, коммерческие палатки, передвижные торговые точки и прочие подобные объекты; при обследовании студентов важно определить, будут ли приняты во внимание студенты-заочники, экстерны, учащиеся в магистратуре, лица, находящиеся в академическом отпуске, и т.п. После проведения отбора с использованием какого-либо алгоритма, реализующего принцип случайности (некоторые из которых были рассмотрены в разделе 8.2), или на основе таблицы случайных чисел, необходимо определить границы генеральных характеристик. Для этого рассчитываются средняя и предельная ошибки выборки. Средняя ошибка повторной собственно-случайной выборки определяется по формуле
С учетом выбранного уровня вероятности и соответствующего ему значения t предельная ошибка выборки составит:
Тогда можно утверждать, что при заданной вероятности генеральная средняя будет находиться в следующих границах: (8.5)
Пример. Предположим, в результате выборочного обследования жилищных условий жителей города, осуществленного на основе собственно-случайной повторной выборки, получен следующий ряд распределения (табл. 8.4). Таблица 8.4 Таблица 8.6J Результаты обследования работников предприятия
Рассчитаем среднюю из внутригрупповых дисперсий:
Определим среднюю и предельную ошибки выборки (с вероятностью 0,954):,,
Рассчитаем выборочную среднюю:
В результате проведенных расчетов с вероятностью 0,954 можно сделать вывод, что среднее число дней временной нетрудоспособности одного работника в целом по предприятию находится в пределах: 14,6-0,58 ^х<, 14,6+0,58. При определении необходимого объема типической выборки в рассмотренных выше формулах (8.11) и (8.12) общую дисперсию на-блкэдаемого признака необходимо заменить на среднюю из внутригрупповых дисперсий. Тоща данные формулы примут следующий вид:
(бесповторный отбор). Предположим, в рассмотренном выше примере нам необходимо определить среднее число дней временной нетрудоспособности одного работника с предельной ошибкой 0,5 дня. Учитывая величину Полученной ранее средней из внутригрупповых дисперсий определим необходимый объем типической выборки при условии бесповторного отбора:
Таким образом мы получили, что при заданных условиях для достижения требуемой точности необходимо обследовать выборочным методом не менее 421 чел. Распределим эту численность на три цеха рассматриваемого предприятия пропорционально их размерам:
Расчеты показывают, что в 1 -м цехе необходимо обследовать 132 чел., во 2-м цехе - 184 чел. и в 3-м цехе - 105 чел. Мы рассмотрели типический отбор, пропорциональный объему типических групп. Второй вариант формирования типической выборки заключается в отборе единиц, пропорциональном вариации признака в типических группах. Логика такого отбора заключается в следующем: если внутри какой-либо типической группы наблюдаемый поизнак варьирует слабо, то для определения границ генеральных характеристик из данной группы достаточно обследовать относительно небольшое число единиц; при сильной же вариации признака объем выборки должен быть соответственно увеличен. При выборке, пропорциональной вариации признака, число наблюдений по каждой группе рассчитывается по формуле:
где О, - среднее квадратическое отклонение признака в i-й группе. Средняя ошибка такого отбора определяется следующим образом:
(повторный отбор);
(бесповторный отбор). (8.17) Отбор, пропорциональный вариации признака, дает лучшие результаты, однако на практике его применение затруднено из-за трудности получения сведений о вариации до проведения выборочного наблюдения. Воспользуемся данными, приведенными в табл. 8.6, для иллюстрации этого способа выборочного наблюдения. Пример. Используя имеющиеся значения внутригрупповых дисперсий, определим необходимый объем выборки по каждому цеху, пропорциональный вариации изучаемого признака, при условии, что в целом выборка составляет 10%, или 320 чел.:
С учетом полученных значений рассчитаем среднюю ошибку выборки:
В данном случае средняя, а следовательно, и предельная ошибки будут несколько меньше, что отразится и на границах генеральной средней. 8.6 СЕРИЙНАЯ ВЫБОРКА Сущность серийной выборки заключается в собственно-случайном либо механическом отборе групп единиц (серий), внутри которых производится сплошное обследование. Единицей отбора при этой выборке является группа или серия, а не отдельная единица генеральной совокупности, как это имело место в рассматриваемых ранее выборках. Данный способ отбора удобен в тех случаях, когда единицы генеральной совокупности изначально объединены в небольшие более или менее равновеликие группы или серии. В качестве таких серий могут выступать упаковки с определенным количеством готовой продукции, партии товара, студенческие группы, бригады и другие подобные объединения. Например, в Великобритании серийный отбор используется в обследованиях населения, когда серией являются домохозяйства, объединенные общим почтовым индексом. В случайном порядке производится выборка индексов, и под обследование попадают все домохозяйства, имеющие индекс попавших в выборочную совокупность почтовых отделений. В отдельных случаях серийная выборка имеет не столько методологические, сколько организационные преимущества перед другими способами формирования выборочной совокупности. Например, Управление маркетинга и регионального развития Московского государственного университета экономики, статистики и информатики периодически проводит обследования школьников Москвы. С организационной точки зрения достаточно сложно опрашивать отдельных учеников из разных классов. Значительно проще из общего списка всех классов всех школ округа сформировать выборку классов, а внутри отобранных классов провести 100%-е обследование учащихся. В связи с тем что при серийном отборе внутри отобранных групп обследуются все без исключения единицы, внутригрупповая вариа-; ция признака не отразится на ошибках выборочного наблюдения. В то же время обследуются не все группы, а только попавшие в выборку. Следовательно, на ошибках получаемых характеристик отразятся различия между группами, которые определяются межгрупповой дисперсией. Поэтому средняя ошибка серийной выборки рассчитывается по формулам
(повторный отбор);
(бесповторный отбор), (8.19) где r - число отобранных серий; R - общее число серий. Межгрупповую дисперсию при равновеликих группах вычисляют следующим образом:
где х^ - средняя 1-й серии; х - общая средняя по всей выборочной совокупности. Пример. Предположим, партия готовой продукции предприятия упакована в 200 коробок по 50 изделий в каждой. В целях контроля соблюдения параметров технологического процесса проведена 5%-я серийная выборка, в ходе которой отбиралась каждая 20-я коробка. Все изделия, находящиеся в отобранных упаковках, были подвергнуты сплошному обследованию, заключавшемуся в определении их точного веса. Полученные результаты представлены в табл. 8.7. Таблица 8.7 Результаты выборочного обследования готовой продукции
С вероятностью 0,954 требуется определить границы среднего веса изделия во всей партии. На основе приведенных в таблице внутригрупповых средних определим средний вес изделия по выборочной совокупности:
С учетом полученной средней рассчитаем межгрупповую дисперсию:
Рассчитаем среднюю и предельную ошибки выборки: -i^na
Определим границы генеральной средней: 999,8-1,1 <x<999,8+l,l. На основе результатов проведенных расчетов с вероятностью 0,954 можно утверждать, что средний вес изделия в целом по всей партии продукции находится в пределах от 998,7 г до 1000,9 г. Для определения необходимого объема серийной выборки при заданной предельной ошибке используются следующие формулы:
(повторный отбор); (8.21)
(бесповторный отбор). (8.22) Предположим, в рассмотренном выше примере необходимо определить границы среднего веса изделия с предельной ошибкой +-0,5 г. Используя полученные выше данные о вариации веса, определим, сколько коробок с изделиями нужно обследовать в порядке бесповторной серийной выборки, чтобы получить результат с заданной точностью и при выбранном уровне вероятности:
Выполненный расчет позволяет заключить, что для получения границ генеральной средней с заданной точностью необходимо обследовать не менее 18 коробок с изделиями, отобранных собственно-случайным или механическим способом. 8.7 ПРАКТИКА ПРИМЕНЕНИЯ ВЫБОРОЧНОГО НАБЛЮДЕНИЯ В СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ ИССЛЕДОВАНИЯХ В настоящее время выборочное наблюдение находит достаточно широкое применение в обследованиях промышленных и сельскохозяйственных предприятий, изучении цен на потребительском рынке, в обследованиях бюджетов и занятости населения'. Выборочный метод является важнейшим источником информации в маркетинговых и социологических исследованиях, в контроле качества продукции; разработаны методологические подходы к применению выборочного наблюдения в аудите. Остановимся на рассмотрении некоторых из указанных областей применения выборки. При статистическом наблюдении за деятельностью предприятий в качестве основы выборки используются данные, содержащиеся в Едином государственном регистре предприятий и организаций, который ведется Государственным комитетом Российской Федерации по статистике, в регистрах ряда других ведомств, в частности, налоговых органов. В большей степени методы выборочного наблюдения используются для изучения деятельности малых предприятий, при этом наблюдаются как стоимостные экономические показатели (объем производства, продаж, инвестиций), так и показатели деловой активности (оценка текущего состояния предприятия, спрос на продукцию, прогноз на ближайшую перспективу). Обследование проводится ежеквартально по форме федерального государственного статистического наблюдения № ПМ «Сведения об основных показателях деятельности малого предприятия». Объектом наблюдения является совокупность субъектов малого предпринимательства или малых предприятий, классификационные признаки которых определены в законодательном порядке. Обследование малых предприятий проводится на основе много-мерной типической (расслоенной) выборки, при этом расслоение генеральной совокупности осуществляется по следующим признакам: • по территории (79 слоев); • по отраслям (63 слоя); • по формам собственности (4 слоя); • по объему выручки (5 слоев). Общий объем выборочной совокупности не превышает 20% совокупности генеральной. Одной из проблем при проведении выборочного наблюдения является проблема так называемых неответов, когда попавшая в выборку единица (респондент) по тем или иным причинам не отвечает на часть вопросов или даже на все вопросы, представленные в формуляре. Эта проблема проявляется и при наблюдении за деятельностью малых предприятий. Вся совокупность неответивших респондентов делится на три группы: • предприятия, прекратившие иди приостановившие свою деятельность; • предприятия, ведущие финансово-хозяйственную деятельность; • предприятия, по которым нет объективной информации, функционируют они или нет. Первая группа предприятий исключается из выборочной совокупности. Для восстановления данных по предприятиям второй группы применяется метод перевзвешивания: неответившему предприятию присваивается значение изучаемого показателя, соответствующее его среднему значению по слою (группе), к которому это предприятие принадлежит. Для восстановления данных по предприятиям третьей группы используется метод заполнения случайным подборам в классах замещения (random hot deck within classes): неответившему предприятию присваиваются значения наблюдаемых признаков, взятых у предприятия-донора. Предприятие-донор выбирается в случайном порядке из предприятий, входящих в соответствующий класс замещения (отрасль экономики). Одной из конечных задач проведения выборочного наблюдения, в том числе и наблюдения за деятельностью малых предприятий, является получение (оценка) суммарных значений наблюдаемых признаков по всей генеральной совокупности - общей выручки, общего объема производства, общего объема инвестиций и т.д. Для решения этой задачи применяется метод прямого пересчета. Сущность этого метода заключается в умножении среднего значения признака, полученного в результате выборочного наблюдения, на объем генеральной совокупности. При выборочном наблюдении за деятельностью малых предприятий методом прямого пересчета получают суммарные значения наблюдаемых признаков по всем выделенным слоям. Основные задачи выборочного обследования бюджетов домашних хозяйств состоят в получении статистических данных о распределении населения по уровню материального благосостояния, данные об уровне бедности и потребления продуктов питания. На основе результатов наблюдения определяют весовые коэффициенты для расчета индекса потребительских цен и получают необходимые данные для составления счетов сектора домашних хозяйств в системе национальных счетов. Генеральная совокупность объединяет все типы домашних хозяйств, за исключением коллективных (больницы, дома-интернаты, школы-интернаты, монастыри и т.п.). Обследование проводится в каждом регионе РФ на основе двухступенчатой случайной выборки с использованием процедуры расслоения на каждой из ступеней отбора. На первой ступени проводится территориальное расслоение населения по месту проживания, т.е. население делится на городское и сельское. На второй ступени каждый слой делится на несколько подслоев по следующим признакам: • по размеру домохозяйства, т.е. числу его членов (7 слоев - 1 чел., 2 чел.,..., 7 и более чел.); • по принадлежности жилого помещения (2 слоя - государственное и частное); • по типу жил   Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Система охраняемых территорий в США Изучение особо охраняемых природных территорий(ООПТ) США представляет особый интерес по многим причинам...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|