
|
|
Рекуррентный аддитивно-мультипликативный многоэтапный алгоритм (РАММА) МГУАКлючевым моментом в реализации изложенного выше подхода есть задача определения единой, наилучшей для всех известных объектов полиномиальной структуры (2). Решение данной задачи целесообразно осуществить в рамках направления моделирования, известного, как метод группового учета аргументов - МГУА [6]. Существует большое количество работ, посвященных развитию, оптимизации различных алгоритмов МГУА [6]. В [2], например, предложено искать указанную выше полиномиальную структуру с помощью версии комбинаторного алгоритма МГУА, адаптированного для одновременного поиска множества моделей единой структуры. Однако такой подход возможен только для класса задач достаточно ограниченной размерности. В [2] применение комбинаторного алгоритма оправдано размерностью расширенного пространства переменных m =8 и количеством объектов моделирования - порядка 150. Для размерностей, существенно больших, необходимо предлагать версии многорядных или многоэтапных алгоритмов МГУА. В настоящей работе для реализации целесообразной версии сокращенного перебора возможных структур моделей объектов классификации предложен рекуррентный аддитивно-мультипликативный многоэтапный алгоритм МГУА. Перебираемые структуры при этом имеют вид
где, Рассмотрим основные этапы предлагаемого алгоритма 1. Предварительная обработка данных. 1.1 Формирование матрицы расширенного множества переменных. Расширение обеспечивает лучшую способность алгоритма к отражению моделируемых свойств объектов классификации. Здесь реализовано расширение исходного множества переменных 1.2 Формирование матрицы обобщенных переменных (ОП). Каждая из ОП является одним из возможных произведений уже существующих переменных расширенного множества переменных, как членов полного полинома (3) заданной максимальной степени p. Известно, что число членов такого полинома определяется (4), где m – количество аргументов (переменных)
Далее, по аналогии с [6], возможно сформировать в (р+1) системе счисления ряд чисел (обозначим его, как ряд "S"), каждое из которых будет определять вид соответствующей ОП. В отличие от [6], генерируются последовательно десятичные натуральные числа и переводятся в (р+1) систему счисления. Будем игнорировать те из них, для которых сумма цифр данного числа в десятичной системе будет более (p+1). Сформированный таким образом ряд из S чисел есть табличное отображение полинома. Действительно, каждой ОП из полинома (4), соответствует некоторый член ряда "S". В каждой ОП участвует столько сомножителей, сколько имеет разрядов соответствующее число ряда "S". Каждый сомножитель, есть исходная переменная, десятичный индекс которой есть место по порядку разряда числа ряда "S", а его степень - значение в данном разряде. 1.3. Переход к матрице центрированных переменных. Позволяет отбросить свободный член в искомой структуре, вплоть до момента ее окончательного определения. После нахождения оптимальной структуры выполняется обратный переход к исходным переменным и рассчитывается свободный член полученной модели. Центрирование осуществляется по среднему обучающей выборки в данном объекте:
2 Формирование информационной матрицы 3 Организация перебора вложенными структурами. Для генерации моделей используется дерево переборного алгоритма (рис.4). Ветви дерева соответствуют созданным ранее ОП. На каждом ряду алгоритма реализуется движение по узлам дерева слева направо и сверху вниз. Для дерева, изображенного на рис.4, соответствующим образом полинома будет набор отображенный в табл.1. Для того, чтоб двигаться по данному дереву слева направо и сверху вниз необходимо восходить по соответствующему табличному массиву снизу вверх, - сначала по рядам, сумма значений которых равна 1, потом, где равна 2 и далее (до p+1). Таблица 1 – Схема полинома
Рис. 4 – Дерево переборного алгоритма Для первого и всех последующих уровней дерева в алгоритме введены степени свободы (F1 и F2), которые определяют максимальное количество лучших, по внешнему критерию, узлов на данном уровне, от которых продолжается поиск. Параметр F определяет количество моделей которые отбираем в процессе выполнения алгоритма. Для каждой из сгенерированных структур: 3.1 Из полученной ранее полной матрицы Обозначив матрицу
Тогда обратную ей матрицу
3.2 Рассчитываем параметры моделей (коэффициенты при ОП в оцениваемой структуре) для каждого объекта на обучающей подвыборке (8)
Количество формируемых структур ограничивается степенями свободы на каждом уровне. Поиск оптимальных моделей (ОП) не продолжается далее по ветке, если её узел не улучшил структуру. Для полученной структуры рассчитывается критерий селекции и его значение сравнивается со значением критерия худшей структуры из F уже сохраненных в буфере (худшей из лучших). Если сравнение в пользу новой структуры - она замещает в буфере ранее отобранный вариант. В программной реализации применено две целесообразные формы внешнего критерия: 1.Критерий селекции [2], который базируется на значениях относительных нормированных среднеквадратических ошибок
2.Предлагается рассчитывать критерий селекции, который базируется на значениях дисперсий (12). Поскольку, конечной целью работы является именно классификация, то логичной есть оценка качества искомой структуры с точки зрения ее разделяющей способности. Такой критерий селекции представляет собой отношение суммы дисперсий внутри классов к значению дисперсии между центрами классов. Пусть Rj - множество точек r i в пространстве параметров моделей объектов классификации Rm, принадлежащих классу j, j=1,..,K, i=1,...,nj а
С учетом покоординатной дисперсии для m координат (p=1,...,m, где m - размерность пространства Rm ), понимая под нормой эвклидово расстояние между i -той точкой q -того кластера и его центром, выражение для нормы будет иметь вид (13), а (12) примет вид (14). Здесь для удобства, введено переобозначение: текущий номер класса q перенесли, как верхний индекс.
4.Лучшая структура (и мультипликативная, и аддитивная составляющие) определяются минимумом критерия селекции или «наращивание» структуры происходит до тех пор, пока критерий селекции будет улучшаться более, чем на некоторую минимальную заданную величину (предельное значение улучшения модели). После определения критерия селекции новая структура сравнивается с худшей из сохраненных в буфере и, при сравнении в пользу новой, замещает ее. Для окончательно отобранных моделей выполняется расчет свободных членов полинома (15).
Выводы Мы расмотрели подход к распознаванию объектов, заданных подмножествами строк матрицы объект-свойства. Подход предполагает построение процедур распознавания в пространстве параметров наилучшей структуры моделей объектов классификации, что позволяет перевести задачу в многомерное пространство, где каждый объект представлен точкой в пространстве параметров своей модели. Для нахождении такой структуры разработан рекуррентный аддитивно-мультипликативный многоэтапный алгоритм МГУА. Для увеличения точности искомых моделей предусмотрено расширение исходного множества переменных. Для организации передвижения по проверяемым структурам образуется дерево переборного алгоритма с использованием вложенных структур. Организованная последовательность вложенных структур позволила использовать подход [9] и применить для расчета параметров моделей рекуррентные формулы метода «окаймления», что существенно увеличило быстродействие алгоритма. Применено два варианта внешнего критерия алгоритма: критерий селекции [2], основанный на значениях относительных нормированных среднеквадратических ошибок для модели и предложен критерий селекции основанный на значениях внутриклассовой и межклассовой дисперсий в пространстве моделей объектов классификации. В результате, осуществленный переход в параметрическое пространство моделей заданных объектов позволяет применять затем весь набор разработанных в настоящее время методов многомерной классификации. ---------------------------------------------------------------- перед пса -Мы теперь владеем МГУА - сравнительно надежным и эффекивным аппаратом моделирования, его возможно будет обратить на нужды анализа – причинно-следственного анализа, учтя если будет необходимо, нелинейный характер связей между переменными
Мы достаточно полно рассмотрели различные задачи моделирования (более полно мы это сделаем в конце курса в обзорном варианте) а теперь вспомним что перед любой задачей оделирования необходим (более полно в обзорном варианте мы о убедится что причинноследстенные связи действительно направленыв сторону моделируемого выхода.Иначе получаемые модели могут оказатся лишенными физического смысла. ПСА
Вернемся к нашей таблице иэтапов моделирования и подробноее распишем первый (декомпозиция) и второй (ПСА) этапы. Затем рассмотрим одно из приложений ПСА к решению задачи классификации Напомним что в этой таблице мы приводим этапы (по столбцам) решения задачи моделирования - мы рассмотриваем те п роцедуры что стоят между неформальной постановкой проблемы и окончательным мат решением задачи моделирования.   Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
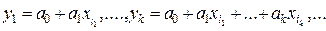 и образуют последовательно усложняющиеся описания, к каждому из (F) которых, на каждом k-том этапе, добавляется лучшая, по внешнему критерию, обобщенная переменная (ОП)
и образуют последовательно усложняющиеся описания, к каждому из (F) которых, на каждом k-том этапе, добавляется лучшая, по внешнему критерию, обобщенная переменная (ОП)  , генерируемая, как член полного полинома вида
, генерируемая, как член полного полинома вида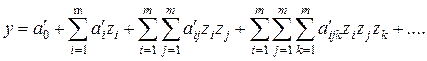 (3)
(3)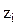 - переменные расширенного множества исходных переменных.
- переменные расширенного множества исходных переменных.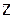 дополнительными переменными
дополнительными переменными  ,
, 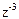 ,
,  . Обозначим далее, для простоты, переменные из расширенного множества, снова через
. Обозначим далее, для простоты, переменные из расширенного множества, снова через 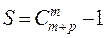 (4)
(4) ,
,  (5)
(5)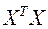 максимального размера для каждого объекта. Этап позволяет избежать повторных расчетов при формировании исходных данных для нахождения параметров каждой новой структуры.
максимального размера для каждого объекта. Этап позволяет избежать повторных расчетов при формировании исходных данных для нахождения параметров каждой новой структуры.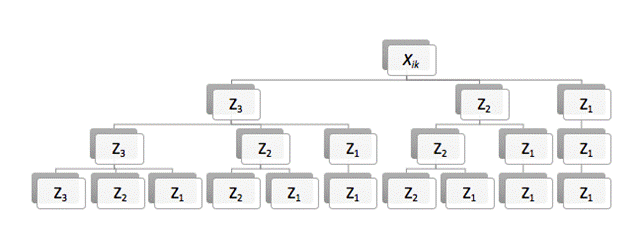
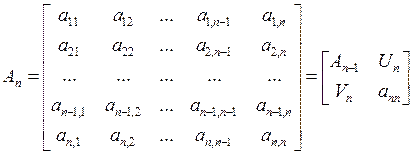 ; (6)
; (6) ищем:
ищем: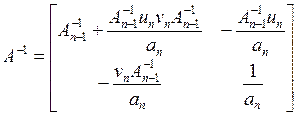 ; (7)
; (7) (8)
(8) и
и  для данной структуры моделей. Рассчитывается значение критерия (9), где
для данной структуры моделей. Рассчитывается значение критерия (9), где  – вес ошибок обучения,
– вес ошибок обучения,  – вес несогласованности ошибок, а
– вес несогласованности ошибок, а  – веса соответствующих классов.
– веса соответствующих классов. ; (9)
; (9)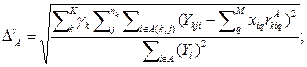 (10)
(10)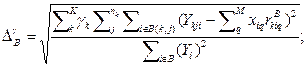 (11)
(11)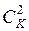 - количество сочетаний из К по 2, тогда введем критерий в виде:
- количество сочетаний из К по 2, тогда введем критерий в виде: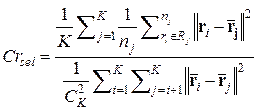 (12)
(12) (13)
(13)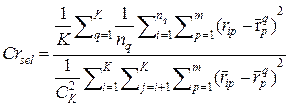 (14)
(14)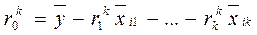 ; (15)
; (15)