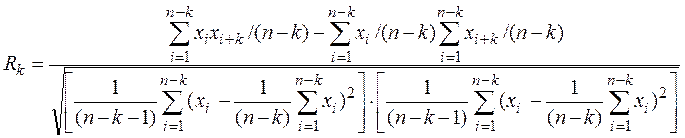|
|
Попробуем представить основные уровни экосферы разумно ограничив размерность моделирования. Определение.– экосфера это экологическая оболочка Земли, как совокупность объектов и свойств, создающих условия для развития биологических систем. Пространственно включает в себя слои атсмосферы, гидросферу, часть литосферы и распространенную в них биосферу., И так объект - срез ограниченной размерности экосферы Представим его как Декомпозицию( иерархическую функциональную модель) по уровням трофики (уровням преобразования материи и энергии) С большой долей упрощения такую модеь можно представить следующим образом раст О2 среда гумус
Учитывая приращения и скорости приращений переменных данную экологическую систему можно представить как двух уровневую систему трофических процессов с перекрестными связями – обычно ур типа Х-Ж Обозначим х(t)- численность добычи, у(t)- численность популяции хищника. Модели, которыми описывают данную систему
Логика уравнений: - в первом ур. понятно, почему скорость роста популяции пропорц. ее численности – больше пап и мам – быстрее темп размножения.при этом. Жертвы,: обладают неограниченным источником питания (ограниченным лишь квадратичным членом моделирующим ограничение по плотности заселения территории) - Популяция хищников увеличивается лишь за счёт поедания ими жертв-сами по себе они вымирают. Поэтому чем больше популяция хищника тем больше коннкуренция у них за жервы – поэтому первый член второгоу равнения со знаком -. а вот со вторым слагаемым как? Если бы в первом ур. просто было (–у)-то понятно чем больше хищника тем медленнеее темп роста популяции жертвы – но причем здесь –аху (во втором +вху) Дело в том что произведение ху пропорионально вероятности встречи хищника и жертвы и только тогда хищник имеет возможность сьесть жертву – поэтому наличие здесь –ху это более точно чем просто –у. Третий член ограничмивает рост популяций в связи с перенаселенностью территории собственной популяцией 2. Для описания таких систем применяли и более простые варианты моделей – модель Брауна и Гордона
В заключение - вспомним
Типичная схема имитационной модели: Рис. 1 Схема имитационной модели Здесь МОЭП - мат-ое описание процесса и алгоритм его решения АИВВ - алгоритм имитации внешних воздействий АОР - алгоритм обработки результатов АРИЭ - Алгоритм расчета и управления имитационным експериментом
О вер моделировании отдельная лекция
О ИМ – некорр перевода 4л ------ Следующий столбец 2
Выше мы связали (интуитивно) в моделях уровней, что должно быть на входах процессов, что должно быть выходными процессами уровня. Таким образом мы зашли в компетенцию второго столбца Анализа. Действительно роль Дек. - произвести целесообразное разбиение на вертикальные уровни иерархии (ВД) и получить разбиение на каждом горизонтальном уровне (ГД) – то есть получить исходные кирпичи из Когда (умозрительные) разбиения для объекта произведены возможно строить модели на каждом уровне и затем увязывать уровни в рамках целостной модели объекта. Т.о. в результате мы считаем что для наждого уровня определен список переменных с помощью которых возможно описать ф-ние данного уровня. Соответственно данные разбиения должны сопровождать таблицы данных называемые обычно матрицами объект=свойства. это и есть входные данные для выполнения задач столбца ПСА и столбца СИНТЕЗ. Как я уже говорил, задачи стлбца ПСА удобно рассматривать на примере моделей прогноза. Поэтому перед рассмотрением аглоритмов ПСА целесообразно подробнее познакомится со спецификой задач моделирования прогнозирующих моделей. Наиболее часто уравнения прогноза записывают в одной из следующих форм Уn+1=f(yn,yn-1,...,yn-k) (1) или уn+1=f(y n/0-k, x 1.n/0-k,..., x m.n/0-k) (2)
следуюшие проблемы: как мы говорили 1. Если моделируется не одно уравнение прогноза, а система уранений на данном горизонтальном уровне
x1.+1=f(x 1.0-k, x 2.0-k,... x m.0-k) x2.+1=f(x 1.0-k, x 2.0-k,... x m.0-k ........................................... xm.+1=f(x 1.0-k, x 2.0-k,... x m.0-k (*) то возникает необходимость определения, что из (*) доказуемо необходимо моделировать – то есть найти список экзогенных переменных обьекта - решение можно получить ести решенызадачи ПСА №2. – все связи от переменной это єкзогенная переменная 2.составление и иссл первичных статистических ПССв графы ПСС и как следствие 3. Списки переменных на входе алгоритма моделирования – этим мы оптимизируем задачу структ- парам синтеза, уменьшая список на входе алгоритма мод-я и уменьшая время реш задачи, увеличивая адекватность моделей. Как именно решать вопрос направления связи - об этом отдельный раздел нашого курса … ………………………….. Первая форма Для (1)

То есть прогнозирующая модель -это механизм прогноза буд. значениу по прошлым значениям. В случае (1) – это прогн значения ряда по его же прошлым значениям. Покажем, тесную связь (алгоритмическую) между статической задачей моделирования и задачей мод-я модели прогноза У=f(X) Yn+1 =f(Yn,n-k) ,УУ…У У+1,У0 У-1…У-К У+1,У0 У-1…У-К
Ось так алгоритмічно споріднені задачі моделювання статичних і прогнозних моделей.
Формула
де Деталізуючи виборочні
або розрахунок через незміщену дисперсію -
Вид автокореляційної функции тісно пов'язаний зі виглядом самого ряду. АКФ для "білого шуму" (стаціонарний випадк. часовий ряд), при k > 0, також утворює стаціонарний часовий ряд із середнім значенням 0.
Якщо є періодичність у графіку АКФ то і в початковому ряду також присутні періодичності на відповідних періодах, але !!!!!!!!!! на графіку вихідного ряду ці періодичності можуть бути не видно, - вони можуть бути завуальовані – - присутністю тренда, - іншими періодичностями або - великою дисперсією випадкової компоненти
Розглянемо приклади автокореляційної функції:
с
Проте нерідкі випадки, коли залишки (випадкова компонента h) можуть виявитися автокоррелірованнимі, наприклад, з наступних причин:
  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  Что способствует осуществлению желаний? Стопроцентная, непоколебимая уверенность в своем... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
 жв
жв 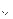 3 ур среды
3 ур среды

 растения
растения  пр. гния
пр. гния 
 всегда заст объяснять логику ур-й
всегда заст объяснять логику ур-й Это так называемая модель Вольтерры двух зацепленных уравнений.
Это так называемая модель Вольтерры двух зацепленных уравнений. 


 Решение по Д. в практической исследовательской задаче связана как правило с огромным объемом перебора структур и с привлечением затем для выбора варианта либо экспертных оценок либо имитационного эксперимента ИМ.
Решение по Д. в практической исследовательской задаче связана как правило с огромным объемом перебора структур и с привлечением затем для выбора варианта либо экспертных оценок либо имитационного эксперимента ИМ. которых на каждом уровне будем лепить модели данного уровня.
которых на каждом уровне будем лепить модели данного уровня.








 У Х
У Х  У
У 
 Як визначити заздалегідь, які запізнювання перспективні для введення в модель прогнозу уn+1=f(yn,yn-1,...,yn-k) (що дуже бажано для адекватності та хороших прогнозуючих властивостей)
Як визначити заздалегідь, які запізнювання перспективні для введення в модель прогнозу уn+1=f(yn,yn-1,...,yn-k) (що дуже бажано для адекватності та хороших прогнозуючих властивостей)

 - виборочні коварації та виборочні оцінки дисперсії відповідних рядів. Индекс зсуву може и запізнюватися и упереджати але так як це один и той же ряд то АКФ – ФУНКЦІЯ парна – симметрична відносно k
- виборочні коварації та виборочні оцінки дисперсії відповідних рядів. Индекс зсуву може и запізнюватися и упереджати але так як це один и той же ряд то АКФ – ФУНКЦІЯ парна – симметрична відносно k одержуємо формулу для
одержуємо формулу для і накінець якщо повністю розкрити формулу через значення ряду то маємо розрахунок через зміщену дисперсію -
і накінець якщо повністю розкрити формулу через значення ряду то маємо розрахунок через зміщену дисперсію -