
|
|
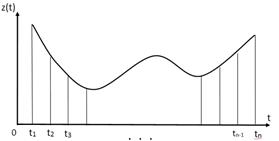
Анализ и обоснование подхода к решению задачи.Исходя из особенностей практических приложений задачи распознавания образов традиционно формулируются в 2-х (в некоторых случаях эквивалентных) постановках: - (1*) для многомерного пространства, где объекты классификации задаются одной многомерной точкой и - (2*) для многомерного пространства, где объекты задаются, как подмножества многомерных точек (многомерных измерений). Подавляющее число методов и алгоритмов распознавания образов были разработаны для решения задач классификации в первой постановке, для второго случая рассматриваются, как правило, подходы к сведению задачи к постановке (1*). Исторически, постановка (2*) рассматривалась, как задача распознавания кривых, или, в более сложном случае, плоских геометрических объектов (например букв). И так, имеем множество кривых (одна из них приведена на - рис.2), заданных, каждая, множеством двухмерных точек (или графиком - рис.2) и множество геометрических форм (рис.3), заданных на условной (пиксельной) сетке. Для решения задачи распознавания кривых чаще применяется координатный подход, для распознавания геометрических форм - пиксельный.
Рис.2 К задача распознавания Рис.3 К задаче распознавания кривых плоской формы
Для описания первой задачи классификации в форме постановки (1*), кривые (рис.2) определяются значением признака z 1, как значением z (t1),..., значение признака z n принимается, как значение z (tn). Для описания второй задачи в форме постановки (1*), значениями переменных zi есть степени заштрихованности (яркости, цветности) соответствующего пикселя. Признаки интерпретируются, как случайные величины, задача нахождения классификатора сводится к получению распределений значений признаков в классах и нахождению дискриминантной функции позволяющей разделить эти распределения [1]. Однако существуют известные препятствия на пути классического подхода: 1.Построение многомерных (а в данном случае, очень многомерных) распределений требует значительных объемов обучающих выборок и выполнения достаточно жестких предположений о виде функций распределения (например нормальность) 2.Крайне желательно применить целесообразные процедуры сокращения размерности пространства переменных 3.В общем случае, когда объекты классификации задаются в многомерном пространстве, и при этом, представлены, каждый, подмножеством многомерных точек, решение задачи классификации требует построения плотностей распределения, размерностью, на порядки большей, чем в рассмотренных выше случаях. Таким образом, в общей постановке данный подход уже не конструктивен. Рассмотрим ниже еще два возможные пути решения проблемы. Пусть в пространстве 1. Необходимо определить свертку типа 2. Пусть в исходном пространстве признаков z1…..z M описание объекта d дается подмножеством точек
Далее, рассматриваем тот случай, задачи, когда среди исходных переменных z1,…,z M возможно выделить выходную переменную. Определим новое пространство признаков x, как пространство обобщенных переменных (ОП) x1, x2,…,x М 1 полученных из переменных исходного пространства
где, для простоты, М снова обозначает размерность нового пространства обобщенных переменных x для представления объекта d. Тогда решение задачи классификации переведем в сопряженное пространству обобщенных переменных x, пространство параметров Ниже рассматривается второй из указанных путей для перевода исходной задачи в постановке (2*) к постановке (1*) построения классификатора. Возражением для применением данного похода могут быть соображения по поводу возможного нарушения гипотезы компактности и сопутствующих проблем, связанных с выбором меры близости в полученном пространстве R при решении задачи классификации. Однако риск данных проблем существует в любой задаче и обоснованность подхода подтверждается, или не подтверждается результатами классификации на проверочной и экзаменационной выборках данных. Близкий по постановке подход рассматривался в задаче диагностики нарушений работы сердечной мышцы при выделении признаков, как параметров разложения сигнала электрокардиограммы в ортогональный дискретный ряд Кравчука [3]. Другим примером использования указанного подхода в исходном пространстве Z фазовых координат являются работы [4,5] по применению методов классификации для оценки областей параметров устойчивости динамических систем. К этому же пути решения задачи принадлежит предлагаемый подход, когда при нахождения наилучшей структуры параметрического пространства характеристик объектов d предлагается использовать метод группового учета аргументов [6].
  Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  ЧТО И КАК ПИСАЛИ О МОДЕ В ЖУРНАЛАХ НАЧАЛА XX ВЕКА Первый номер журнала «Аполлон» за 1909 г. начинался, по сути, с программного заявления редакции журнала... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|
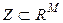 заданы обучающие подмножества
заданы обучающие подмножества 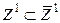 ,
,  ...,
..., 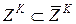 объектов
объектов 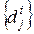 , где i - индекс класса, j - индекс объекта в классе. Каждый объект
, где i - индекс класса, j - индекс объекта в классе. Каждый объект 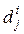 описывается в пространстве
описывается в пространстве  подмножествами
подмножествами  многомерных точек (вектор-строк) матрицы объект-свойства
многомерных точек (вектор-строк) матрицы объект-свойства 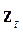 :
: 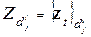 . Пусть данные в матрице объект-свойства упорядочены по классам. Обозначим
. Пусть данные в матрице объект-свойства упорядочены по классам. Обозначим  - количество объектов в k -том классе,
- количество объектов в k -том классе, 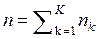 - количество объектов в матрице. Тогда
- количество объектов в матрице. Тогда 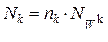 - количество точек в k-м классе, если количество точек в каждом объекте k-го класса одинаково и равно
- количество точек в k-м классе, если количество точек в каждом объекте k-го класса одинаково и равно 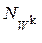 , и
, и 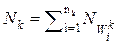 если количество точек в объектах
если количество точек в объектах  различно и равно
различно и равно  . Здесь
. Здесь 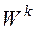 и
и 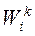 - подмножества точек в соответствующих классах и отдельных объектах класса k, соответственно. Общее количество точек (строк) в матрице данных
- подмножества точек в соответствующих классах и отдельных объектах класса k, соответственно. Общее количество точек (строк) в матрице данных 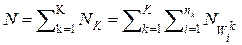 . Существенным далее есть то, что для каждого объекта
. Существенным далее есть то, что для каждого объекта 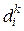 известна не одна, а некоторое подмножество точек
известна не одна, а некоторое подмножество точек 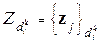 , тут
, тут 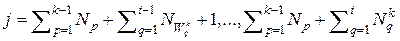 , где i - номер объекта в классе k. Существенным есть также то, что, в общем случае, области существования объектов
, где i - номер объекта в классе k. Существенным есть также то, что, в общем случае, области существования объектов  и
и 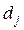 :
: 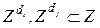 , представленные в обучении подмножествами векторов
, представленные в обучении подмножествами векторов 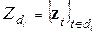 ,
,  , могут частично пересекаться, при этом указанные объекты, могут принадлежать и различным классам [2]. Тогда возможно рассматривать следующие 2 пути для сведения постановки (2*) задачи классификации к постановке (1*):
, могут частично пересекаться, при этом указанные объекты, могут принадлежать и различным классам [2]. Тогда возможно рассматривать следующие 2 пути для сведения постановки (2*) задачи классификации к постановке (1*): подмножества многомерных векторов
подмножества многомерных векторов 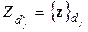 в некоторую многомерную точку
в некоторую многомерную точку 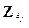 , таким образом, чтобы она однозначно определяла объект
, таким образом, чтобы она однозначно определяла объект  в своем классе
в своем классе 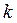 в исходном пространстве признаков z1…..z M. Определение такой свертки должно сопровождаться условиями наилучшей классификации объектов в данном классе сверток.
в исходном пространстве признаков z1…..z M. Определение такой свертки должно сопровождаться условиями наилучшей классификации объектов в данном классе сверток.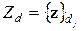 , неизвестной нам характеристики объекта fd( z1,…,z M)=0. Тогда указанных характеристик предполагается столько, сколько объектов:
, неизвестной нам характеристики объекта fd( z1,…,z M)=0. Тогда указанных характеристик предполагается столько, сколько объектов: (1)
(1)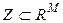 , при этом ОП x1, x2,…,x М 1 наилучшим образом представляют характеристики fd( z1,…,z M)= 0 d=1,..,n по исходным множествам точек
, при этом ОП x1, x2,…,x М 1 наилучшим образом представляют характеристики fd( z1,…,z M)= 0 d=1,..,n по исходным множествам точек 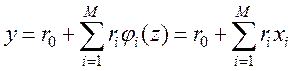 (2)
(2)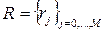 характеристик
характеристик 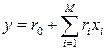 , что позволит рассматривать объекты d уже не как множества
, что позволит рассматривать объекты d уже не как множества 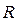 [2]. Отдельные точки rd уже однозначно определяют объекты d ввиду отсутствия полностью совпадающих подмножеств
[2]. Отдельные точки rd уже однозначно определяют объекты d ввиду отсутствия полностью совпадающих подмножеств