
|
|
Вот некоторые примеры графического представления данныхИсследовательская компания ЭКРО-RG в ноябре 2005 года провела исследование петербургского рынка рекламы в периодических изданиях. В ходе исследования проводился опрос петербургских предприятий (объем выборки 100) и анализ вторичных источников информации.[108] Полученные данные представлены следующим образом.
Кроме графического представления результатов исследования применяются и другие способы их отображения. Карты восприятия – это визуальные представления взаимосвязей между конкретными фактами, темами и методиками. Информация организована так, чтобы сразу увидеть ключевые результаты.[109] Когнитивные карты – это визуальное представление взаимосвязей между конкретными фактами, темами. Информация на когнитивной карте организована так, чтобы помочь заказчику исследования ясно увидеть ключевые результаты в каждой области и их взаимосвязи. К тому же графический формат помогает понять, как отдельные мнения и отношения ведут к темам и метатемам. Как правило, к составлению когнитивной карты приступают по окончании процесса анализа данных. В целом, различные формы табличного или графического представления данных облегчают восприятие полученных данных, но не очень продвигают в деле понимания полученной информации. Например, здесь еще нельзя обнаружить типичные значения признака и т.д. Для облегчения работы с частотными распределениями, а также для обобщенного представления их характеристик обычно используются статистики (особенно две группы статистик: меры центральной тенденции и меры разброса или изменчивости). Меры центральной (средней) тенденции (МЦТ) указывают на расположение среднего (типичного) значения признака, вокруг которого сгруппированы остальные наблюдения.
Мода (Мо) – это такое значение в совокупности наблюдений, которое встречается чаще всего (например, в выборке по признаку «национальность» окажется 83% русских. Мода (мера центральной тенденции) имеет свои ограничения (в распределении могут быть две и более моды, мода чувствительна к избранному способу группировки значений переменной; моду нельзя использовать при небольшом расхождении значений: 53% проголосовали за Саркози, 47% - за противника на выборах и т.д.). Медиана (Мd) – значение, которое делит упорядоченное множество данных пополам (так, что одна половина наблюдений оказывается меньше медианы, а другая - больше). Это 50-й процентиль распределения. Медиана обычно используется для ординальных переменных, т. е. таких переменных, значения которых могут быть упорядочены от меньших к большим (медиана это как бы середина упорядоченной последовательности чисел). Среднее (среднее арифметическое) – самая большая и распространенная мера центральной тенденции. Исчисляется по формуле:
X = 1/n …Xi,
где: X1…Xi – наблюдаемые значения, n – число наблюдений, … – знак арифметической суммы. Среднее дает возможность достаточно хорошо (сжато) описывать поведения анализируемой переменной, однако представляет совокупность значений этой переменной неполно и с возможными ошибками (так, среднее значение зарплаты мало что говорит о зарплате конкретных респондентов, а средняя температура по больнице вообще не имеет смысла во врачебной практике). Естественно, если бы все значения переменной были одинаковы, то среднее абсолютно точно отразило бы поведение переменных (30 человек по 30 лет, значит, среднее = 30). Однако это встречается крайне редко, поэтому важно знать не только значения этой модели переменной, но и степень точности, качества этой модели. Вводится понятие остатка.
Остаток (расхождение реальных данных и модели) дает эффектный инструмент для оценки качества модели (чем меньше остаток, тем модель лучше). Число, которое оценивает качество средней как модели, это меры разброса (дисперсия и др.). Определение среднего и медианы очень важно для более глубокого понимания особенностей полученных данных. При этом среднее является более предпочтительной мерой в силу своих математических свойств и возможности лучше оценивать среднее генеральной совокупности. Медиана более предпочительна, когда ряд данных содержит одно или несколько экстремальных значений (так называемых «выбросов», т.е. очень малых или больших значений) и когда присутствует наличие открытых в группировке данных. Например, одной из категорий группировки доходах может быть пункт «более 100 тыс. долл.». Среднюю точку определить невозможно, так как не установлена верхняя граница. Следовательно, необходимо использовать медиану, поскольку вычислить среднее сгруппированных данных невозможно. Среднее, мода и медиана дают различное распределение характеристик ряда. Распределение будет симметричным, если среднее, медиана, мода совпадают. Распределение, в котором мода меньше медианы, а медиана в свою очередь меньше среднего, скошено влево. Распределение, в котором мода больше медианы, а медиана больше среднего, скошено вправо. Это распределение имеет ряд значений с низкой частотой в нижней части. В зависимости от скошенности распределения и диапазона значений в качестве центральной тенденции выбирается или медиана, или мода. Теперь о непосредственном применении всего этого инструментария в рекламной деятельности. Часто для упрощенного представления количества мер используются разные аналитические приемы. Вот пример применения номинального уровня данных в виде представления и вычисления «совокупного» процента. Предположим, респонденты просмотрели рекламный ролик. Им дается задание поставить отметку напротив утверждения, отражающего те чувства, которые вызвал у них просмотр рекламного ролика: Было скучно. Я кое-что узнал(а), просмотрев рекламный ролик. Рекламный ролик рассчитан на таких людей, как я. Я видел такие рекламные ролики прежде. Призам, участвующим в рекламном ролике, можно верить. Рекламный ролик вызвал у меня замешательство. Я скажу своим друзьям, что этот рекламный ролик стоит посмотреть. Визуальное сопровождение прекрасно подобрано. Лицу, рекламирующему товар, можно верить. Рекламный ролик не интересен. Мне не нравятся рекламные ролики такого рода. Лицо, рекламирующее товар, вызывает раздражение. Хотел(а) бы снова увидеть этот рекламный ролик. В итоге все полученные ответы на данные вопросы можно, например, представить в виде таблицы. При этом отдельные пункты могут располагаться в порядке, представленном в анкете, или в порядке убывания процента выраженного согласия. Однако надо заметить, что здесь данные будут представлены в таком виде, что трудно оттенить основные закономерности реакции респондентов. Такие закономерности будут более ясными, если мы станем придерживаться следующего порядка действий: сначала определить, о чем данные будут говорить, затем сгруппировать утверждения в соответствии с целью представления данных (например, положительные утверждения и отдельно все отрицательные), потом дать название каждой из группировок (например, «Положительные реакции» и «Отрицательные реакции»), в конце – рассчитать совокупный процент для каждой группы суждений. Этот процент характеризует долю респондентов, выбравших, по крайней мере, один из пунктов группировки. Например, четыре утверждения (утверждение 1, утверждение 2, утверждение 3, и утверждение 4) вместе составляют некоторую группу. Согласие респондентов с этими утверждениями в представленной ниже таблице отмечено крестиками:
Совокупный процент для этой группы респондентов по сгруппированным утверждениям составляет 60%. Это означает, что 60% респондентов (3 из 5) согласны, по крайней мере, с одним из четырех утверждений. При обработке и анализе данных, полученных методом массового опроса, обычно применяются методы ранжирования, рейтингования, шкалирования, корреляции и т.д. Ранжирование – процедура установления относительной предпочтительности исследуемых объектов на основе их упорядочивания. Ранг – это показатель, характеризующий порядковый номер явления среди других; показатель порядкового места оцениваемого объекта в группе, а также места других объектов, которые имеют существенные для оценки свойства. При ранжировании расположение пунктов осуществляется в порядке предпочтения, а не по абсолютной шкале. В итоге получаются порядковые данные. Процедура ранжирования активно применяется, например, для оценки степени корреляции переменных (коэффициент ранговой корреляции Спирмена и др.). Коэффициент корреляции рассчитывается по формуле, построенной на разнице между ранжированиями. Рейтингование осуществляется с помощью научно обоснованной методики в ходе массового или экспертного социологического опроса. Рейтинг – числовой показатель популярности успехов, авторитетности групп, организаций, лиц, их политики, планов, деятельности в определенный изучаемый период; качественно-количественный индикатор, который прямо или опосредованно выражает общественно значимую оценку события, института, личности, товара и иных социальных объектов. Вот, например, какие критерии предлагает Клуб рекламодателей для составления рейтинга брэндов рекламных агентств: 1. Общеизвестность рекламного агентства в среде рекламодателей. 2. Принадлежность рекламного агентства к своим профессиональным ассоциациям. Призы и профессиональные достижения, полученные рекламным агентством на профессиональных конкурсах. 3. Предпринимательская деловитость рекламного агентства и творческое отношение к поставленной задаче. Бухгалтерская точность (или, наоборот, небрежность). 4. Партнерство или жесткость во взаимоотношениях. Способность признать свои ошибки и искать возможности компромиссных решений. 5. Спектр востребованных рекламных услуг – то, что рекламодатели у этого рекламопроизводителя чаще всего приобретают (а не то, что он на самом деле декларирует). 6. Количество клиентов рекламного агентства в выборке. Реальный спектр его деловых связей. 7. Репутация. Рекомендации данного рекламного агентства в среде рекламодателей. 8. Наличие сертификатов от органов власти или от органов государственного регулирования рекламного рынка. 9. Конфликтность на рынке… 10. Уникальность технологической базы – ресурсы. Эксклюзивное положение на рынке за счет наличия кадров или реального оборудования, или программного обеспечения.[110] В электоральных социологических исследованиях различают два основных типа рейтинговых замеров: 1) простой, при котором для получения информации используется только один критерий. В одной из книг данный метод называется «укол», предполагающий исчисление рейтингового веса и построение рангового ряда на базе данных, полученных в результате ответа респондента только на один вопрос («Если бы выборы состоялись в ближайшее воскресенье, то за кого бы Вы проголосовали?»).[111] Рейтинговый вес рассчитывается по формуле:
где: 2) сложный, при котором респонденту задается целая серия взаимосвязанных вопросов («За кого бы Вы проголосовали, если бы выборы состоялись в ближайшее воскресенье?» и «За кого бы Вы не проголосовали ни при каких обстоятельствах?»). Рейтинг рассчитывается по формуле:
где: Индекс – специфическая конструкция, образованная путем комбинации индикаторов. Зачастую конструирование индекса является единственным средством формирования нового понятия на эмпирическом уровне знаний или замены неточного понятия теоретического уровня на более точное. Построение индекса можно рассматривать как способ получения значений такого признака, который не поддается непосредственному измерению с помощью индикаторов. «Экономисты часто используют индексы розничных цен, отражающие динамику стоимости жизни. При этом разные товарные группы, например, имеющие неодинаковое значение в потребительском бюджете, – как, скажем, хлеб и деликатесы – учитываются с разными весовыми коэффициентами. Но и в этом случае индекс остается несовершенным типом шкалы: эмпирическая информация здесь используется лишь для шкалирования различий между субъектами (или другими единицами анализа), но не для шкалирования различий между пунктами-ответами (эмпирическими индикаторами)».[113] Одним из современных и достаточно эффективных средств изучения целых массивов социальной информации являются сводные индексы различного рода, которые искусственно конструируются на основе определенной обработки эмпирических данных. «По своей методологической природе любой сконструированный индекс – величина, искусственно полученная в результате обработки ряда эмпирических данных. В принципе такой индекс может служить показателем состояния или тенденции изменения изучаемого материала («массового сознания») как некоего целостного образования… на основе опросных массивов для различных исследовательских целей могут строиться индексы настроений, оценок, установок и пр. – в зависимости от набора и способа сопоставления интегрируемых данных».[114] Как отмечает Ю.А. Левада, частные индексы строятся по данным определенных вопросов следующим образом: из числа (процента) позитивных ответов вычитается число негативных ответов, к полученному результату для удобства расчетов (устранения отрицательных величин) добавляется 100. Так создаются индексы настроения, терпения, отношения к реформам и др. Обобщенные индексы (например, оценок положения в стране, собственного положения респондента, ожиданий на будущее) вычисляются аналогичным образом по средним значениям ряда выделенных показателей. Сводный индекс социальных настроений для каждого момента измерения может быть получен в результате суммирования показателей обобщенных индексов. Например, большую известность приобрел «индекс потребительских настроений». Индекс потребительских настроений был разработан в США в середине XX столетия. «ИПН строится на основе систематических социологических опросов населения. Вопросов может быть задано много, но для построения индекса используются ответы на пять основных: 1) Как изменилось материальное положение вашей семьи за последние шесть месяцев? 2) Как, по-вашему, изменится материальное положение семьи в предстоящие шесть месяцев? 3) Как вы считаете, следующие 12 месяцев для экономики страны будут хорошим или плохим временем? 4) Следующие пять лет будут хорошим или плохим временем для экономики страны? 5) Сейчас в целом хорошее или плохое время для того, чтобы делать крупные покупки для дома? …Индекс потребительских настроений одновременно учитывает динамику всех частных составляющих. Его отдельными компонентами являются индекс текущего состояния экономики (ИТС), исчисляемый простым усреднением ответов на первый и пятый из вышеперечисленных вопросов, и индекс экономических ожиданий (ИЭО), являющийся усредненным вариантом ответов на второй, третий и четвертый вопросы. Таким образом, ИПН и составляющие его индексы агрегируют в себе простыми и понятными даже неспециалисту методами частные мнения самостоятельно действующих на потребительском рынке людей. Это делает ИПН независимым показателем, характеризующим динамику экономического развития страны».[115] В социологических исследованиях в последнее время часто (особенно в политической рекламе) используют показатель «индекс социальных настроений». С его помощью дается сводная оценка динамики общественных настроений. Индекс социальных настроений – «наиболее общий показатель массовых настроений общества. Его регулярные измерения ведутся с 1988 г., когда он был построен по результатам данных по набору вопросов, задающихся в Мониторинге ВЦИОМ с начала 1990-х годов. Он позволяет, с одной стороны, оценить динамику состояния общества и, с другой – опосредовано отслеживать влияние массового сознания на развитие страны. Методология построения этого показателя исходит из следующей предпосылки: частные мнения людей о различных сторонах своей жизни, отношение к экономическим и социальным событиям, которые происходят вокруг них и действующими лицами которых они являются, формируют обобщенную оценку восприятия социально-экономической и политической действительности. Эта сводная оценка. В свою очередь, является базовой предпосылкой индивидуальных действий отдельных людей… ИСН строится по данным опросов общественного мнения путем простой и очевидной процедуры обобщения результатов ответов респондентов на серию вопросов (всего используется девять вопросов). Все вопросы, используемые для построения индекса, нацелены на выделение положительных и отрицательных оценок (или направлений их изменения) с тем. Чтобы их последовательный ряд мог дать наилучшее представление о динамике этого показателя. При построении ИСН внимание уделяется следующим моментам: 1) как люди оценивают материальное положение своих семей; 2) как респонденты оценивают экономическое и политическое положение страны в целом; 3) что они думают о будущем развитии страны; 4) социально-психологическому состоянию людей, их настроению. Приведенные ниже индексы построены по ряду показателей, получаемых в регулярных опросах по программе «Мониторинг» (каждые два месяца опрашивается по 2400 чел.). Чтобы избежать отрицательных чисел, к разности между позитивными и негативными показателями добавляется 100. Поэтому значения индексов менее 100 означают преобладание негативных оценок, более 100 – преобладание позитивных оценок.[116]   Что будет с Землей, если ось ее сместится на 6666 км? Что будет с Землей? - задался я вопросом...  Что делает отдел по эксплуатации и сопровождению ИС? Отвечает за сохранность данных (расписания копирования, копирование и пр.)...  Конфликты в семейной жизни. Как это изменить? Редкий брак и взаимоотношения существуют без конфликтов и напряженности. Через это проходят все...  ЧТО ПРОИСХОДИТ, КОГДА МЫ ССОРИМСЯ Не понимая различий, существующих между мужчинами и женщинами, очень легко довести дело до ссоры... Не нашли то, что искали? Воспользуйтесь поиском гугл на сайте:
|





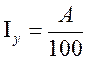
 – индекс «укол», А – количество респондентов, избравших один и тот же предмет замера, 100 – условная величина, введенная формула для перехода к индексному выражению полученного процентного веса.
– индекс «укол», А – количество респондентов, избравших один и тот же предмет замера, 100 – условная величина, введенная формула для перехода к индексному выражению полученного процентного веса.
 – индекс «весы», А(1) – число респондентов, сделавших положительный выбор;
– индекс «весы», А(1) – число респондентов, сделавших положительный выбор;  (2) – число респондентов, сделавших отрицательный выбор; 100 – условная величина, введенная в формулу для перехода к индексному выражению полученных процентных весов.[112]
(2) – число респондентов, сделавших отрицательный выбор; 100 – условная величина, введенная в формулу для перехода к индексному выражению полученных процентных весов.[112]